Autopublish c apidocs #38
Merged
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
…tion (microsoft#12990) Recent change in CUDA EP microsoft#12814 makes hipify extremely slow and breaks the building. This PR fixes it by c The onnxruntime/contrib_ops/rocm/bert/attention.h is checkout-ed from the version before microsoft#12814 and manually hipify-ed. Slightly extend amd_hipify.py to allow wildcard file match and exclude all `tensorrt_fused_multihead_attention/*` files from hipify
**Description**: Remove the `settings.json` line in gitignore. **Motivation and Context** Having `settings.json` tracked in git has created annoying diffs when it is modified locally. This PR removes the entry in gitignore but maintains the `settings.json` in the repo so that we have a good default.
…ls-version-bug-fix downgrade setuptools
**Description**: Change qdq debugger test oracle instead of testing a threshold, which occasionally fails, we just test the loss value is present.
…icrosoft#11762) **Description**: Describe your changes. XNNPACK takes pthreadpool as its internal threadpool implemtation, it couples calculation and parallelization. Thus it's impossible to leverage ORT's threadpool (EIGEN/OPENMP based). So we enabled pthreadpool in XNNPACK EP in this PR. Case 1: Pthreadpool coexist with ORT-threadpool simply Expriments setup hardware:RedMi8A with 8 cores, ARMv7 The two threadpool has the same pool size form 1 to 8. Two models: mobilenet_v2 and mobilenet_egetppu. we can see the picture below and draw a conclusion, latency are even higher from 5 threads or more. 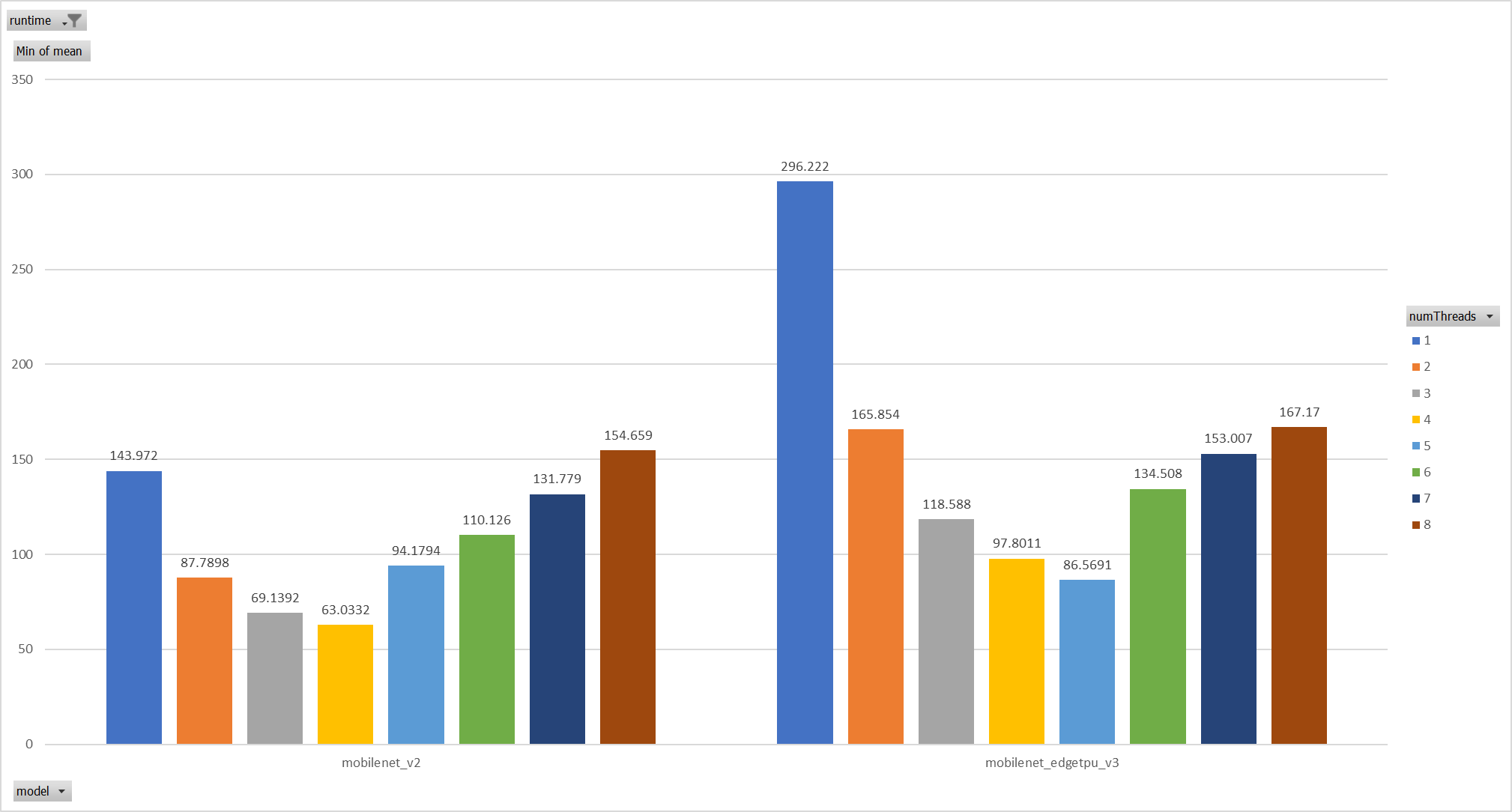 Case 2: For the reason of performance regression with 5 more threads, ORT-threads are spinning on CPU and diddn't realease it after computation finished. It's equivalent of creating 5x2 threads for parallelization while we have only 8 cpu cores. So I mannuly disabled spinning after ort-threadpool finished and enabled it when enter ort-threadpool. The result is quite normal now. 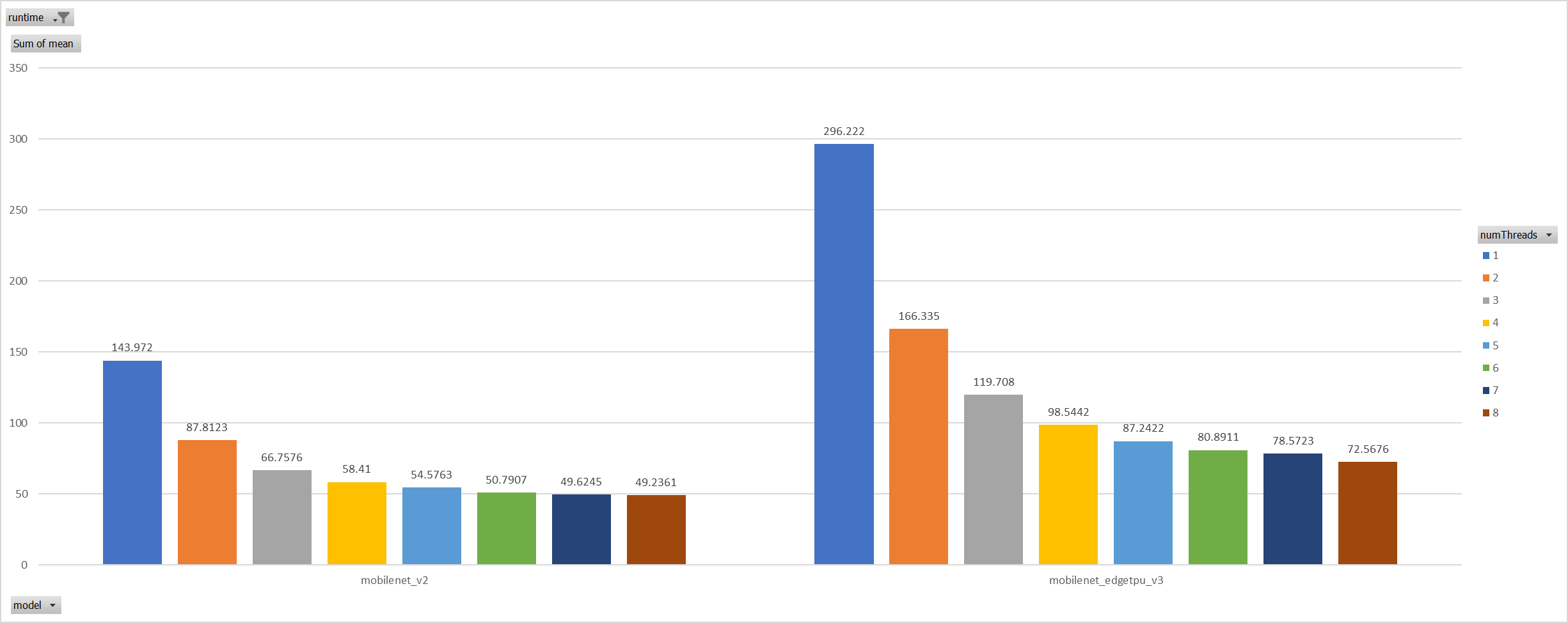 Case 3: Even we achieved a reasonable results with disabling spinning, Will ORT-threadpool still impact performance of pthreadpool? we have expriment setting up as: Setting ORT-threadpool size (intra_thread_num) as 1, and only pthreadpool created. Attention that, almost a third of ops are running by CPU EP. we are surprisingly find that disabling ort-threadpool is even better in performance than creating two threadpool. 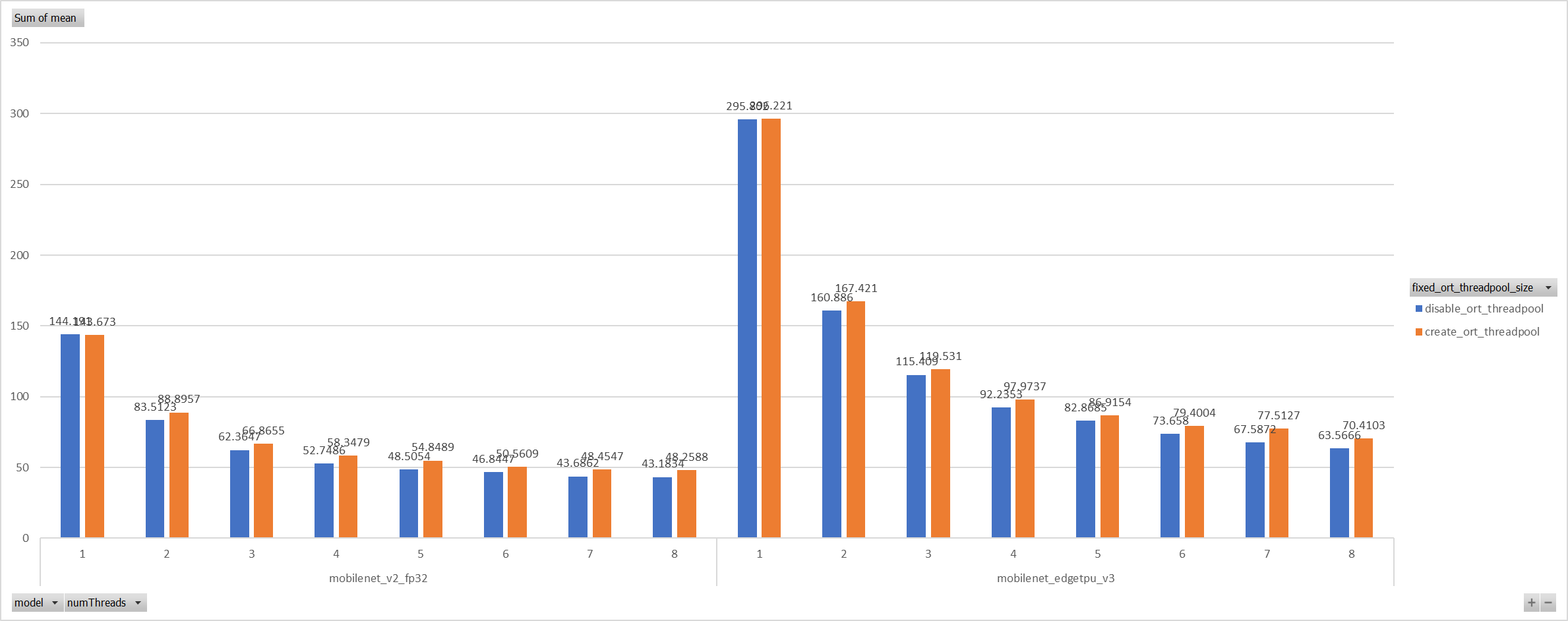 Case 4: Use a unified threadpool between CPU ep and XNNPACK ep. It's the fastest among all. But if we take the similar workload partition strategy as ORT-threadpool, it could be faster. 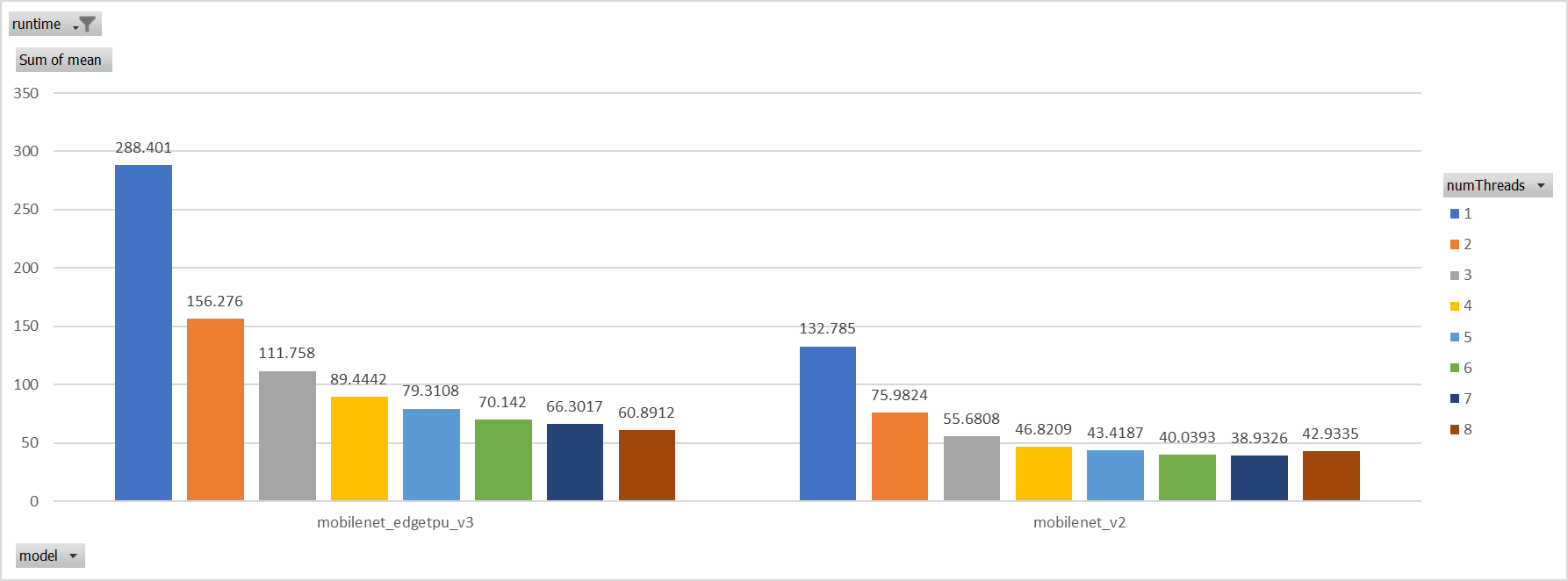 **Motivation and Context** - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. Co-authored-by: Jicheng Wen <jicwen@microsoft.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This allow us quickly launch a microbench session by, for example: ```bash python gemm_test.py T N float16 256 256 65536 ``` So that we can quickly see which one is the fastest.
) **Description**: Describe your changes. Related PR: microsoft#12803 microsoft#12817 microsoft#12821 Add skip layernorm to kernel explorer for profiling. **Motivation and Context** - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here.
**Description**: symbolic_registry is deprecated in torch.onnx. This PR removes its usage. Fixes microsoft#13008
…nel def hashes (microsoft#12791) # Motivation Currently, ORT minimal builds use kernel def hashes to map from nodes to kernels to execute when loading the model. As the kernel def hashes must be known ahead of time, this works for statically registered kernels. This works well for the CPU EP. For this approach to work, the kernel def hashes must also be known at ORT format model conversion time, which means the EP with statically registered kernels must also be enabled then. This is not an issue for the always-available CPU EP. However, we do not want to require that any EP which statically registers kernels is always available too. Consequently, we explore another approach to match nodes to kernels that does not rely on kernel def hashes. An added benefit of this is the possibility of moving away from kernel def hashes completely, which would eliminate the maintenance burden of keeping the hashes stable. # Approach In a full build, ORT uses some information from the ONNX op schema to match a node to a kernel. We want to avoid including the ONNX op schema in a minimal build to reduce binary size. Essentially, we take the necessary information from the ONNX op schema and make it available in a minimal build. We decouple the ONNX op schema from the kernel matching logic. The kernel matching logic instead relies on per-op information which can either be obtained from the ONNX op schema or another source. This per-op information must be available in a minimal build when there are no ONNX op schemas. We put it in the ORT format model. Existing uses of kernel def hashes to look up kernels are replaced with the updated kernel matching logic. We no longer store kernel def hashes in the ORT format model’s session state and runtime optimization representations. We no longer keep the logic to generate and ensure stability of kernel def hashes.
…Tests (microsoft#13016) Since CUDA EP became a shared library, most of internal functions are not accessible from `onnxruntime_test_all`, we need a new mechanism to write CUDA EP-specific tests. To this end, this PR introduces a general infra and an example test for deferred release in CUDA EP. When adding this test, we also found the current deferred release will cause error when pinned CPU buffer is not allocated by BFCArena, and this PR also makes a small fix (see changes in rocm_execution_provider.cc and cuda_execution_provider.cc). This PR also fixes a deferred release bug found by new tests.
…rosoft#13019) **Description**: Describe your changes. As title. Added unit test for the case. **Motivation and Context** - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. Fix issue microsoft#12979
Move Linux GPU CI pipeline to T4
…soft#13024) This enables developers inspecting into the benchmark session much easier.
1. add node test data to current model tests 2. support opset version to filter tests. 3. remove old filter based on onnx version. To avoid confusion, ONLY support opset version filter in onnxruntime_test_all 4. support read onnx test data from absolute path on Windows.
…ft#12618) **Description**: Describe your changes. As title. The purpose of this pr is to eliminate as much of repetitive shape inference code in nnapi ep shaper struct. For ops (mainly require composed operations) : -BatchNorm -Reshape -Squeeze (in one case of gemm operator) -BatchMatMul still contains some shape calculation impl/logic. Dynamic shape functions are not touched yet. **Motivation and Context** - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. Clean up redundant code as cpu shape inference impl for NNAPI EP. Get rid of the shape inference code in NNAPI EP by using the static shape info in output NodeArg.
microsoft#13015) **Update engine hash id generator with model name/model content/metadata** **Description**: * Updated engine id generator, which use model name/model inputs & outputs/env metadata (instead of model path) to generate hash * New bridged API were introduced in order to enable id generator in the TRTEP utility **Motivation and Context** - Why is this change required? What problem does it solve? To fix this [issue](triton-inference-server/server#4587) caused by id generator using model path How to use: * Call [TRTGenerateMetaDefId(const GraphViewer& graph_viewer, HashValue& model_hash)](https://github.com/microsoft/onnxruntime/blob/0fcce74a565478b4c83fac5a3230e9786bb53ab3/onnxruntime/core/providers/tensorrt/tensorrt_execution_provider.cc#L715) to generate hash id for TRT engine cache How to test: * On WIndows, run: * .\onnxruntime_test_all.exe --gtest_filter=TensorrtExecutionProviderTest.TRTMetadefIdGeneratorUsingModelHashing * .\onnxruntime_test_all.exe --gtest_filter=TensorrtExecutionProviderTest.TRTSubgraphIdGeneratorUsingModelHashing **Appendix** * [Existing engine id generator that uses model path](https://github.com/microsoft/onnxruntime/blob/main/onnxruntime/core/framework/execution_provider.cc#L112-L182)
**Description**: Fixes bug in `tools/quantization/operators/split.py` which would make `quantized_input_names == []`
**Description**: This fix the bug where per_channel quantization isn't working when axis == 0
**Description**: I added a warning in microsoft#10831 a week ago, but it's noisy for onnxruntime_test_all.exe because very few tests explicitly specify the providers they use, relying on implicit CPU, which makes it harder to see actual errors in the output. So reduce this noise (that is, if no EP's were explicitly provided, display no warning). Sample output spew: ``` 2022-09-20 20:08:50.6299388 [W:onnxruntime:NchwcOptimizerTests, session_state.cc:1030 onnxruntime::VerifyEachNodeIsAssignedToAnEp] Some nodes were not assigned to the preferred execution providers which may or may not have an negative impact on performance. e.g. ORT explicitly assigns shape related ops to CPU to improve perf. ``` **Motivation and Context** - *Why is this change required? What problem does it solve?* Test output noise makes it harder to debug real failures. - *If it fixes an open issue, please link to the issue here.* NA
…t#12811) Added a check for tensor validation on the input - this change fixes the quiet abort WASM takes when processing a non tensor data in "OrtGetTensorData" **Motivation and Context** At the current status when we try to process non-tensor data through OrtGetTensorData and exception is thrown which results in a quiet abort from WASM (assuming WASM was built without exception handling). I added a check in the C API to catch this case and output a meaningful message to the user [example_error_github_12622.zip](https://github.com/microsoft/onnxruntime/files/9464328/example_error_github_12622.zip)
### Description binraries ==> binaries ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
### Description <!-- Describe your changes. --> Add special case handling for exclusive + reverse where axis has dim value of 1. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? microsoft#13165
* Change block dimension type to Int from Ints. * In response to feedback that the block dimension corresponds to the reduction dimension of the consuming matrix multiplication. There is always only 1 reduction dimension.
…t#13210) ### Description <!-- Describe your changes. --> As title. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> Uint8 type might be required for some model used in sample application. To match supported data types for onnxruntime-react-native for Android. Co-authored-by: rachguo <rachguo@rachguos-Mac-mini.local> Co-authored-by: rachguo <rachguo@rachguos-Mini.attlocal.net>
Add BART into transformer support, specificalyy for `BartForConditionalGeneration` **Motivation and Context** - fixes microsoft#11210 Currently, the custom op beam search is not working in nightly, this PR should be run with a [custom commit](microsoft@10f3d46)
…sistency (microsoft#13215) ### Description Deprecate CustomOpApi and refactor dependencies for exception safety and eliminate memory leaks. Refactor API classes for clear ownership and semantics. Introduce `InitProviderOrtApi()` ### Motivation and Context Make public API better and safer. Special note about `Ort::Unowned`. The class suffers from the following problems: 1. It is not able to hold const pointers to the underlying C objects. This forces users to `const_cast` and circumvent constness of the returned object. The user is now able to call mutating interfaces on the object which violates invariants and may be a thread-safety issue. It also enables to take ownership of the pointer and destroy it unintentionally (see examples below). 2. The objects that are unowned cannot be copied and that makes coding inconvenient and at times unsafe. 3. It directly inherits from the type it `unowns`. All of the above creates great conditions for inadvertent unowned object mutations and destructions. Consider the following examples of object slicing, one of them is from a real customer issue and the other one I accidentally coded myself (and I am supposed to know how this works). None of the below can be solved by aftermarket patches and can be hard to diagnose. #### Example 1 slicing of argument ```cpp void SlicingOnArgument(Ort::Value& value) { // This will take possession of the input and if the argument // is Ort::Unowned<Ort::Value> it would again double free the ptr // regardless if it was const or not since we cast it away. Ort::Value output_values[] = {std::move(value)}; } void main() { const OrtValue* ptr = nullptr; // some value does not matter Ort::Unowned<Ort::Value> unowned{const_cast<OrtValue*>(ptr)}; // onowned is destroyed when the call returns. SlicingOnArgument(unowned); } ``` #### Example 2 slicing of return value ```cpp // The return will be sliced to Ort::Value that would own and relase (double free the ptr) Ort::Value SlicingOnReturn() { const OrtValue* ptr = nullptr; // some value does not matter Ort::Unowned<Ort::Value> unowned{const_cast<OrtValue*>(ptr)}; return unowned; } ```
Fix warnings and enable dev mode for ROCm CI: * Fix ROCm headers complaining "This file is deprecated. Use the header file from ..." * Disable warning signed and unsigned compare for kernel explorer * Fix unused and nondiscard warnings * Enable dev mode for ROCm CI * Walkaround error "unknown warning option '-Wno-nonnull-compare'" in kernel explorer by using '-Wno-unknown-warning-option' to ignore the unknown option * Fix error "unused parameter 'mask'" * Fix warning "instantiation of variable 'onnxruntime::rocm::Consts<float>::One' required here, but no definition is available", etc. Fixed by using C++17's inline (implied by constexpr) static initialization. * Remove unused variable * Add the missing `override` specifier
### Description Increase MacOS pipeline timeout to 5 hours ### Motivation and Context It blocks Release pipeline
### Description Address build failures after Public API refactoring ### Motivation and Context Make pipelines health.
Increase iOS packaging pipeline timeout to 300 minutes.
### Description <!-- Describe your changes. --> fix some typo in docs ### Motivation and Context singed vs signed succeding vs succeeding fileter vs filter kernal vs kernel libary vs library
### Description
Re-architect DML EP to allow ORT L2/L3 transformers. This change
includes:
- During ORT graph partitioning, DML EP will only set the
dmlExecutionProvider to all eligible nodes.
- Moved DML specific operator transformer as L2 transformer
- Introduced a new DMLGraphFusionTransformer, applicable only for DML
EP, which is responsible to
- partition the graph
- fuse each partition into a IDMLCompiledOperator
- register the kernel for each partition
### Motivation and Context
- Why is this change required? What problem does it solve?
It enables ORT L2/L3 transformers for DML EP, which will increase the
perf of Transformer-based models.
- If it fixes an open issue, please link to the issue here. N/A
Co-authored-by: Sumit Agarwal <sumitagarwal@microsoft.com>
**Description**: 1. Share scalar constant for same data type, value and shape. 2. Fix the order of Graph resolve context clear and CleanUnusedInitializersAndNodeArgs(). **Share initializer for those who hold same value in same type and shape, currently only handle scalar value or 1-D single value array.** The transformation itself did not bring much impact on memory/perf, instead is helpful to simplify the graph, making it easier for common subexpression eliminations (CSE). Imagine graphs like this:  Add is NOT shared as inputs of Clip after CSE transformation because, all Add's second constant input are different NodeArg*, so if we change all constant initializer share the same NodeArg*, then only one Add will be preserved after CSE transformation. There are few other similar cases in one of 1P deberta models. E2E measurement on 1P DEBERTA model, we see an increase from SamplesPerSec=562.041593991271 to 568.0106130440271, 1.07% gains. **Fix the order of Graph resolve context clear and CleanUnusedInitializersAndNodeArgs().** Graph resolve context will be cleared every time by end of Graph.Resolve(), one of the thing to be cleared is the "inputs_and_initializers" who hold string_view of all initializers. While CleanUnusedInitializersAndNodeArgs removed some initializers, so some strings that is referenced by string_view in "inputs_and_initializers" remain to be there BUT in an invalid state. **Motivation and Context** - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here.
{kind=link}
### Description - Fix Abseil::InlinedVector inlined storage visualization - Fix typo in protobuf natvis. - Add basic gsl.natvis ### Motivation and Context Debugging is hard.
…options. (microsoft#13238) Add onnxruntime_BUILD_UNIT_TESTS=OFF definition to iOS package build options. The `--skip_tests` option is already specified.
…icrosoft#13241) clang-tidy says "Do not implicitly decay an array into a pointer; consider using gsl::array_view or an explicit cast instead" It is a false positive scattering around all our codebase when using helper macros. It is becuase for function with 4 char name, say `main`, the type of __FUNCTION__ and __PRETTY_FUNCTION__ is `char [5]`.
### Description <!-- Describe your changes. --> 1. Update ROCm pipeline and MIGraphX pipeline to ROCm5.3 ROCm pipeline run ortmodule test one time and disable it : https://dev.azure.com/onnxruntime/onnxruntime/_build/results?buildId=777794&view=logs&j=48b14a85-ff1a-5ca4-53fa-8ea420d27feb&t=9c199f35-fc50-565d-6c65-5162c9bb1b04 2. Add `workspace: clean: all `. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
### Description Use Path filter and fake workflow to skip windows GPU check if there's only changes in doc. Refs: https://docs.github.com/en/repositories/configuring-branches-and-merges-in-your-repository/defining-the-mergeability-of-pull-requests/troubleshooting-required-status-checks#handling-skipped-but-required-checks The fake github yaml is generated by code. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> ###verifications:### In this PR: since the win-gpu-ci-pipeline.yml and .github are updated, so the real Windows GPU workflows are always triggered. in microsoft#13256 To avoid update win-gpu-ci-pipleline.yml, I added the path filter in devops page. the fake win GPU workflows triggered, and the real workflows are skipped.
### Description <!-- Describe your changes. --> ### Motivation and Context The timeout issues increased
This PR has two fixes: - pytorch/pytorch#85636 change the behavior of register_custom_op_symbolic to only register the symbolic function at a single version. For ORTModule we need to pass the op_set version when calling it. - Since torch_1.13 the signature of einsum is changed to have a new argument, need to change our custom op symbolic registry code accordingly. Without the fixes, ORTModule will not work with the nightly torch, and the new torch version will be released.
) **Description**: Add qkv_hidden_size support in CUDA Attention Layer implementation. Changes include: - Modify UT to test GPU and CPU implementation - Add overload for CUDA kernel `AddBiasTransposeQKV` to support scenario where V_HIDDEN_SIZE != QK_HIDDEN_SIZE - Update variable names from `head_size` to `qkv_head_sizes[0]` or `qkv_head_sizes[2]` - Modify function definitions to allow communication of `qkv_hidden_sizes` or `qkv_head_sizes` Note that this feature is not supported in Rocm EP or quantized attention right now. **Motivation and Context** - Why is this change required? What problem does it solve? The current CUDA implementation of attention layer doesn't support the parameter qkv_hidden_size added in the CPU implementation in PR [8039](microsoft#8039) - If it fixes an open issue, please link to the issue here. Co-authored-by: Peter Mcaughan <petermca@microsoft.com>
…osoft#13266) ### Description To construct test name, replace whitespace to underscore and remove parentheses ### Motivation and Context gtest name only accepts '_' and alphanumeric
### Description Implemented gradient of sin as a function op. ### Motivation and Context Sin gradient currently implemented as cpu op which could hurt performance. ### Testing built ORT from source: `./build.sh --config RelWithDebInfo --enable_training --use_cuda --cuda_home /usr/local/cuda --cudnn_home /usr/local/cuda --build_wheel --parallel --skip_tests` tested SinGrad implementation: `cd build/Linux/RelWithDebInfo/ && ./onnxruntime_test_all --gtest_filter=GradientCheckerTest.SinGrad` Co-authored-by: Prathik Rao <prathikrao@microsoft.com> Co-authored-by: Baiju Meswani <bmeswani@microsoft.com>
### Description Implemented gradient of cos as per the function below.  ### Motivation and Context Cos gradient required for [huggingface's diffusers library](https://github.com/huggingface/diffusers) ### Testing built ORT from source: `./build.sh --config RelWithDebInfo --enable_training --use_cuda --cuda_home /usr/local/cuda --cudnn_home /usr/local/cuda --build_wheel --parallel --skip_tests` tested CosGrad implementation: `cd build/Linux/RelWithDebInfo/ && ./onnxruntime_test_all --gtest_filter=GradientCheckerTest.CosGrad` Co-authored-by: Prathik Rao <prathikrao@microsoft.com>
{kind=link}
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
No description provided.