Fixed test failures #7
Merged
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
…ests ## What changes were proposed in this pull request? Lots of our tests don't properly shutdown everything they create, and end up leaking lots of threads. For example, `TaskSetManagerSuite` doesn't stop the extra `TaskScheduler` and `DAGScheduler` it creates. There are a couple more instances, eg. in `DAGSchedulerSuite`. This PR adds the possibility to print out the not properly stopped thread list after a test suite executed. The format is the following: ``` ===== FINISHED o.a.s.scheduler.DAGSchedulerSuite: 'task end event should have updated accumulators (SPARK-20342)' ===== ... ===== Global thread whitelist loaded with name /thread_whitelist from classpath: rpc-client.*, rpc-server.*, shuffle-client.*, shuffle-server.*' ===== ScalaTest-run: ===== THREADS NOT STOPPED PROPERLY ===== ScalaTest-run: dag-scheduler-event-loop ScalaTest-run: globalEventExecutor-2-5 ScalaTest-run: ===== END OF THREAD DUMP ===== ScalaTest-run: ===== EITHER PUT THREAD NAME INTO THE WHITELIST FILE OR SHUT IT DOWN PROPERLY ===== ``` With the help of this leaking threads has been identified in TaskSetManagerSuite. My intention is to hunt down and fix such bugs in later PRs. ## How was this patch tested? Manual: TaskSetManagerSuite test executed and found out where are the leaking threads. Automated: Pass the Jenkins. Author: Gabor Somogyi <gabor.g.somogyi@gmail.com> Closes apache#19893 from gaborgsomogyi/SPARK-16139.
## What changes were proposed in this pull request? RFormula should use VectorSizeHint & OneHotEncoderEstimator in its pipeline to avoid using the deprecated OneHotEncoder & to ensure the model produced can be used in streaming. ## How was this patch tested? Unit tests. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Bago Amirbekian <bago@databricks.com> Closes apache#20229 from MrBago/rFormula.
## What changes were proposed in this pull request? * If there is any error while trying to assign the jira, prompt again * Filter out the "Apache Spark" choice * allow arbitrary user ids to be entered ## How was this patch tested? Couldn't really test the error case, just some testing of similar-ish code in python shell. Haven't run a merge yet. Author: Imran Rashid <irashid@cloudera.com> Closes apache#20236 from squito/SPARK-23044.
…til.NoSuchElementException
## What changes were proposed in this pull request?
The following SQL involving scalar correlated query returns a map exception.
``` SQL
SELECT t1a
FROM t1
WHERE t1a = (SELECT count(*)
FROM t2
WHERE t2c = t1c
HAVING count(*) >= 1)
```
``` SQL
key not found: ExprId(278,786682bb-41f9-4bd5-a397-928272cc8e4e)
java.util.NoSuchElementException: key not found: ExprId(278,786682bb-41f9-4bd5-a397-928272cc8e4e)
at scala.collection.MapLike$class.default(MapLike.scala:228)
at scala.collection.AbstractMap.default(Map.scala:59)
at scala.collection.MapLike$class.apply(MapLike.scala:141)
at scala.collection.AbstractMap.apply(Map.scala:59)
at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$.org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$evalSubqueryOnZeroTups(subquery.scala:378)
at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$$anonfun$org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$constructLeftJoins$1.apply(subquery.scala:430)
at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$$anonfun$org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$constructLeftJoins$1.apply(subquery.scala:426)
```
In this case, after evaluating the HAVING clause "count(*) > 1" statically
against the binding of aggregtation result on empty input, we determine
that this query will not have a the count bug. We should simply return
the evalSubqueryOnZeroTups with empty value.
(Please fill in changes proposed in this fix)
## How was this patch tested?
A new test was added in the Subquery bucket.
Author: Dilip Biswal <dbiswal@us.ibm.com>
Closes apache#20283 from dilipbiswal/scalar-count-defect.
## What changes were proposed in this pull request? There are already quite a few integration tests using window frames, but the unit tests coverage is not ideal. In this PR the already existing tests are reorganized, extended and where gaps found additional cases added. ## How was this patch tested? Automated: Pass the Jenkins. Author: Gabor Somogyi <gabor.g.somogyi@gmail.com> Closes apache#20019 from gaborgsomogyi/SPARK-22361.
…th fix to continuous Kafka data reader ## What changes were proposed in this pull request? The Kafka reader is now interruptible and can close itself. ## How was this patch tested? I locally ran one of the ContinuousKafkaSourceSuite tests in a tight loop. Before the fix, my machine ran out of open file descriptors a few iterations in; now it works fine. Author: Jose Torres <jose@databricks.com> Closes apache#20253 from jose-torres/fix-data-reader.
This reverts commit 66217da.
## What changes were proposed in this pull request? The first commit added a new test, and the second refactored the class the test was in. The automatic merge put the test in the wrong place. ## How was this patch tested? - Author: Jose Torres <jose@databricks.com> Closes apache#20289 from jose-torres/fix.
…a sources ## What changes were proposed in this pull request? After [SPARK-20682](apache#19651), Apache Spark 2.3 is able to read ORC files with Unicode schema. Previously, it raises `org.apache.spark.sql.catalyst.parser.ParseException`. This PR adds a Unicode schema test for CSV/JSON/ORC/Parquet file-based data sources. Note that TEXT data source only has [a single column with a fixed name 'value'](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/text/TextFileFormat.scala#L71). ## How was this patch tested? Pass the newly added test case. Author: Dongjoon Hyun <dongjoon@apache.org> Closes apache#20266 from dongjoon-hyun/SPARK-23072.
## What changes were proposed in this pull request? Make the default behavior of EXCEPT (i.e. EXCEPT DISTINCT) more explicit in the documentation, and call out the change in behavior from 1.x. Author: Henry Robinson <henry@cloudera.com> Closes apache#20254 from henryr/spark-23062.
## What changes were proposed in this pull request? ORC filter push-down is disabled by default from the beginning, [SPARK-2883](apache@aa31e43#diff-41ef65b9ef5b518f77e2a03559893f4dR149 ). Now, Apache Spark starts to depend on Apache ORC 1.4.1. For Apache Spark 2.3, this PR turns on ORC filter push-down by default like Parquet ([SPARK-9207](https://issues.apache.org/jira/browse/SPARK-21783)) as a part of [SPARK-20901](https://issues.apache.org/jira/browse/SPARK-20901), "Feature parity for ORC with Parquet". ## How was this patch tested? Pass the existing tests. Author: Dongjoon Hyun <dongjoon@apache.org> Closes apache#20265 from dongjoon-hyun/SPARK-21783.
## What changes were proposed in this pull request? Previously, PR apache#19201 fix the problem of non-converging constraints. After that PR apache#19149 improve the loop and constraints is inferred only once. So the problem of non-converging constraints is gone. However, the case below will fail. ``` spark.range(5).write.saveAsTable("t") val t = spark.read.table("t") val left = t.withColumn("xid", $"id" + lit(1)).as("x") val right = t.withColumnRenamed("id", "xid").as("y") val df = left.join(right, "xid").filter("id = 3").toDF() checkAnswer(df, Row(4, 3)) ``` Because `aliasMap` replace all the aliased child. See the test case in PR for details. This PR is to fix this bug by removing useless code for preventing non-converging constraints. It can be also fixed with apache#20270, but this is much simpler and clean up the code. ## How was this patch tested? Unit test Author: Wang Gengliang <ltnwgl@gmail.com> Closes apache#20278 from gengliangwang/FixConstraintSimple.
…cher ## What changes were proposed in this pull request? Temporarily ignoring flaky test `SparkLauncherSuite.testInProcessLauncher` to de-flake the builds. This should be re-enabled when SPARK-23020 is merged. ## How was this patch tested? N/A (Test Only Change) Author: Sameer Agarwal <sameerag@apache.org> Closes apache#20291 from sameeragarwal/disable-test-2.
## What changes were proposed in this pull request? Continuous processing tasks will fail on any attempt number greater than 0. ContinuousExecution will catch these failures and restart globally from the last recorded checkpoints. ## How was this patch tested? unit test Author: Jose Torres <jose@databricks.com> Closes apache#20225 from jose-torres/no-retry.
… processing query. ## What changes were proposed in this pull request? Keep the run ID static, using a different ID for the epoch coordinator to avoid cross-execution message contamination. ## How was this patch tested? new and existing unit tests Author: Jose Torres <jose@databricks.com> Closes apache#20282 from jose-torres/fix-runid.
…rrowColumnVector ## What changes were proposed in this pull request? This PR changes usage of `MapVector` in Spark codebase to use `NullableMapVector`. `MapVector` is an internal Arrow class that is not supposed to be used directly. We should use `NullableMapVector` instead. ## How was this patch tested? Existing test. Author: Li Jin <ice.xelloss@gmail.com> Closes apache#20239 from icexelloss/arrow-map-vector.
## What changes were proposed in this pull request? This PR proposes to actually run the doctests in `ml/image.py`. ## How was this patch tested? doctests in `python/pyspark/ml/image.py`. Author: hyukjinkwon <gurwls223@gmail.com> Closes apache#20294 from HyukjinKwon/trigger-image.
## What changes were proposed in this pull request? Fixed some typos found in ML scaladocs ## How was this patch tested? NA Author: Bryan Cutler <cutlerb@gmail.com> Closes apache#20300 from BryanCutler/ml-doc-typos-MINOR.
## What changes were proposed in this pull request? - Added `InterfaceStability.Evolving` annotations - Improved docs. ## How was this patch tested? Existing tests. Author: Tathagata Das <tathagata.das1565@gmail.com> Closes apache#20286 from tdas/SPARK-23119.
## What changes were proposed in this pull request? Added documentation for stream-stream joins     ## How was this patch tested? N/a Author: Tathagata Das <tathagata.das1565@gmail.com> Closes apache#20255 from tdas/join-docs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
## What changes were proposed in this pull request? Structured streaming is now able to read files with space in file name (previously it would skip the file and output a warning) ## How was this patch tested? Added new unit test. Author: Xiayun Sun <xiayunsun@gmail.com> Closes apache#19247 from xysun/SPARK-21996.
… and Catalog in PySpark ## What changes were proposed in this pull request? This PR proposes to deprecate `register*` for UDFs in `SQLContext` and `Catalog` in Spark 2.3.0. These are inconsistent with Scala / Java APIs and also these basically do the same things with `spark.udf.register*`. Also, this PR moves the logcis from `[sqlContext|spark.catalog].register*` to `spark.udf.register*` and reuse the docstring. This PR also handles minor doc corrections. It also includes apache#20158 ## How was this patch tested? Manually tested, manually checked the API documentation and tests added to check if deprecated APIs call the aliases correctly. Author: hyukjinkwon <gurwls223@gmail.com> Closes apache#20288 from HyukjinKwon/deprecate-udf.
## What changes were proposed in this pull request? Migrate ConsoleSink to data source V2 api. Note that this includes a missing piece in DataStreamWriter required to specify a data source V2 writer. Note also that I've removed the "Rerun batch" part of the sink, because as far as I can tell this would never have actually happened. A MicroBatchExecution object will only commit each batch once for its lifetime, and a new MicroBatchExecution object would have a new ConsoleSink object which doesn't know it's retrying a batch. So I think this represents an anti-feature rather than a weakness in the V2 API. ## How was this patch tested? new unit test Author: Jose Torres <jose@databricks.com> Closes apache#20243 from jose-torres/console-sink.
…lanner ## What changes were proposed in this pull request? `DataSourceV2Strategy` is missing in `HiveSessionStateBuilder`'s planner, which will throw exception as described in [SPARK-23140](https://issues.apache.org/jira/browse/SPARK-23140). ## How was this patch tested? Manual test. Author: jerryshao <sshao@hortonworks.com> Closes apache#20305 from jerryshao/SPARK-23140.
…ften returns NULL ## What changes were proposed in this pull request? When there is an operation between Decimals and the result is a number which is not representable exactly with the result's precision and scale, Spark is returning `NULL`. This was done to reflect Hive's behavior, but it is against SQL ANSI 2011, which states that "If the result cannot be represented exactly in the result type, then whether it is rounded or truncated is implementation-defined". Moreover, Hive now changed its behavior in order to respect the standard, thanks to HIVE-15331. Therefore, the PR propose to: - update the rules to determine the result precision and scale according to the new Hive's ones introduces in HIVE-15331; - round the result of the operations, when it is not representable exactly with the result's precision and scale, instead of returning `NULL` - introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss` which default to `true` (ie. the new behavior) in order to allow users to switch back to the previous one. Hive behavior reflects SQLServer's one. The only difference is that the precision and scale are adjusted for all the arithmetic operations in Hive, while SQL Server is said to do so only for multiplications and divisions in the documentation. This PR follows Hive's behavior. A more detailed explanation is available here: https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E. ## How was this patch tested? modified and added UTs. Comparisons with results of Hive and SQLServer. Author: Marco Gaido <marcogaido91@gmail.com> Closes apache#20023 from mgaido91/SPARK-22036.
…for registerJavaFunction. ## What changes were proposed in this pull request? Currently `UDFRegistration.registerJavaFunction` doesn't support data type string as a `returnType` whereas `UDFRegistration.register`, `udf`, or `pandas_udf` does. We can support it for `UDFRegistration.registerJavaFunction` as well. ## How was this patch tested? Added a doctest and existing tests. Author: Takuya UESHIN <ueshin@databricks.com> Closes apache#20307 from ueshin/issues/SPARK-23141.
## What changes were proposed in this pull request?
Stage's task page table will throw an exception when there's no complete tasks. Furthermore, because the `dataSize` doesn't take running tasks into account, so sometimes UI cannot show the running tasks. Besides table will only be displayed when first task is finished according to the default sortColumn("index").
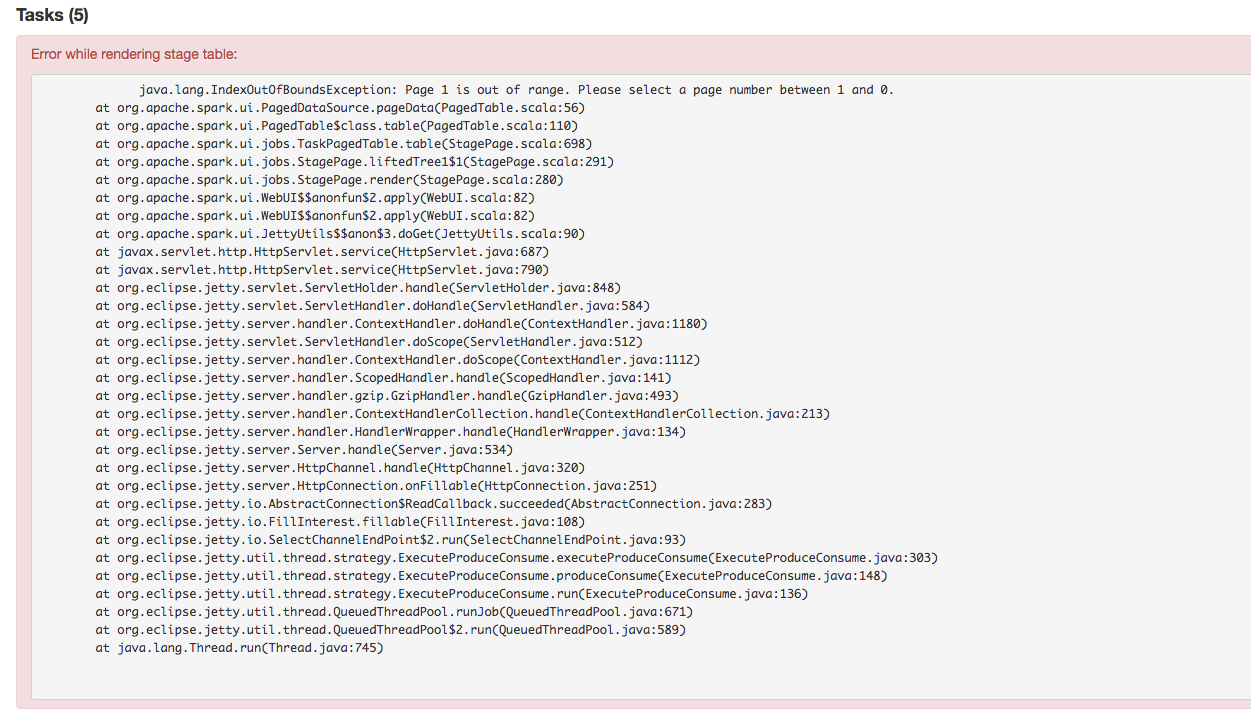
To reproduce this issue, user could try `sc.parallelize(1 to 20, 20).map { i => Thread.sleep(10000); i }.collect()` or `sc.parallelize(1 to 20, 20).map { i => Thread.sleep((20 - i) * 1000); i }.collect` to reproduce the above issue.
Here propose a solution to fix it. Not sure if it is a right fix, please help to review.
## How was this patch tested?
Manual test.
Author: jerryshao <sshao@hortonworks.com>
Closes apache#20315 from jerryshao/SPARK-23147.
{kind=link}
## What changes were proposed in this pull request? This PR completes the docs, specifying the default units assumed in configuration entries of type size. This is crucial since unit-less values are accepted and the user might assume the base unit is bytes, which in most cases it is not, leading to hard-to-debug problems. ## How was this patch tested? This patch updates only documentation only. Author: Fernando Pereira <fernando.pereira@epfl.ch> Closes apache#20269 from ferdonline/docs_units.
…gger ## What changes were proposed in this pull request? Self-explanatory. ## How was this patch tested? New python tests. Author: Tathagata Das <tathagata.das1565@gmail.com> Closes apache#20309 from tdas/SPARK-23143.
## What changes were proposed in this pull request? Refactored ConsoleWriter into ConsoleMicrobatchWriter and ConsoleContinuousWriter. ## How was this patch tested? new unit test Author: Tathagata Das <tathagata.das1565@gmail.com> Closes apache#20311 from tdas/SPARK-23144.
## What changes were proposed in this pull request? Correctly guard against empty datasets in `org.apache.spark.ml.classification.Classifier` ## How was this patch tested? existing tests Author: Matthew Tovbin <mtovbin@salesforce.com> Closes apache#20321 from tovbinm/SPARK-23152.
…stration timeout and maxAttempts conf" ## What changes were proposed in this pull request? [Ticket](https://issues.apache.org/jira/browse/SPARK-22297) - one of the tests seems to produce unreliable results due to execution speed variability Since the original test was trying to connect to the test server with `40 ms` timeout, and the test server replied after `50 ms`, the error might be produced under the following conditions: - it might occur that the test server replies correctly after `50 ms` - but the client does only receive the timeout after `51 ms`s - this might happen if the executor has to schedule a big number of threads, and decides to delay the thread/actor that is responsible to watch the timeout, because of high CPU load - running an entire test suite usually produces high loads on the CPU executing the tests ## How was this patch tested? The test's check cases remain the same and the set-up emulates the previous version's. Author: Mark Petruska <petruska.mark@gmail.com> Closes apache#19671 from mpetruska/SPARK-22297.
…ataLossSuite to test ContinuousExecution ## What changes were proposed in this pull request? Currently, `KafkaContinuousSourceStressForDontFailOnDataLossSuite` runs on `MicroBatchExecution`. It should test `ContinuousExecution`. ## How was this patch tested? Pass the updated test suite. Author: Dongjoon Hyun <dongjoon@apache.org> Closes apache#20374 from dongjoon-hyun/SPARK-23198.
## What changes were proposed in this pull request? This PR is repaired as follows 1、update y -> x in "left outer join" test case ,maybe is mistake. 2、add a new test case:"left outer join and left sides are limited" 3、add a new test case:"left outer join and right sides are limited" 4、add a new test case: "right outer join and right sides are limited" 5、add a new test case: "right outer join and left sides are limited" 6、Remove annotations without code implementation ## How was this patch tested? add new unit test case. Author: caoxuewen <cao.xuewen@zte.com.cn> Closes apache#20381 from heary-cao/LimitPushdownSuite.
…zily ## What changes were proposed in this pull request? Currently,the deserializeStream in ExternalAppendOnlyMap#DiskMapIterator init when DiskMapIterator instance created.This will cause memory use overhead when ExternalAppendOnlyMap spill too much times. We can avoid this by making deserializeStream init when it is used the first time. This patch make deserializeStream init lazily. ## How was this patch tested? Exist tests Author: zhoukang <zhoukang199191@gmail.com> Closes apache#20292 from caneGuy/zhoukang/lay-diskmapiterator.
…ted) expressions ## What changes were proposed in this pull request? The `GenArrayData.genCodeToCreateArrayData` produces illegal java code when code splitting is enabled. This is used in `CreateArray` and `CreateMap` expressions for complex object arrays. This issue is caused by a typo. ## How was this patch tested? Added a regression test in `complexTypesSuite`. Author: Herman van Hovell <hvanhovell@databricks.com> Closes apache#20391 from hvanhovell/SPARK-23208.
## What changes were proposed in this pull request? This syncs the ML Python API with Scala for differences found after the 2.3 QA audit. ## How was this patch tested? NA Author: Bryan Cutler <cutlerb@gmail.com> Closes apache#20354 from BryanCutler/pyspark-ml-doc-sync-23163.
…n whole-stage codegen ## What changes were proposed in this pull request? It has been observed in SPARK-21603 that whole-stage codegen suffers performance degradation, if the generated functions are too long to be optimized by JIT. We basically produce a single function to incorporate generated codes from all physical operators in whole-stage. Thus, it is possibly to grow the size of generated function over a threshold that we can't have JIT optimization for it anymore. This patch is trying to decouple the logic of consuming rows in physical operators to avoid a giant function processing rows. ## How was this patch tested? Added tests. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes apache#18931 from viirya/SPARK-21717.
Update ML user guide with highlights and migration guide for `2.3`. ## How was this patch tested? Doc only. Author: Nick Pentreath <nickp@za.ibm.com> Closes apache#20363 from MLnick/SPARK-23112-ml-guide.
## What changes were proposed in this pull request? Add colRegex API to PySpark ## How was this patch tested? add a test in sql/tests.py Author: Huaxin Gao <huaxing@us.ibm.com> Closes apache#20390 from huaxingao/spark-23081.
…nExec
## What changes were proposed in this pull request?
**Proposal**
Add a per-query ID to the codegen stages as represented by `WholeStageCodegenExec` operators. This ID will be used in
- the explain output of the physical plan, and in
- the generated class name.
Specifically, this ID will be stable within a query, counting up from 1 in depth-first post-order for all the `WholeStageCodegenExec` inserted into a plan.
The ID value 0 is reserved for "free-floating" `WholeStageCodegenExec` objects, which may have been created for one-off purposes, e.g. for fallback handling of codegen stages that failed to codegen the whole stage and wishes to codegen a subset of the children operators (as seen in `org.apache.spark.sql.execution.FileSourceScanExec#doExecute`).
Example: for the following query:
```scala
scala> spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1)
scala> val df1 = spark.range(10).select('id as 'x, 'id + 1 as 'y).orderBy('x).select('x + 1 as 'z, 'y)
df1: org.apache.spark.sql.DataFrame = [z: bigint, y: bigint]
scala> val df2 = spark.range(5)
df2: org.apache.spark.sql.Dataset[Long] = [id: bigint]
scala> val query = df1.join(df2, 'z === 'id)
query: org.apache.spark.sql.DataFrame = [z: bigint, y: bigint ... 1 more field]
```
The explain output before the change is:
```scala
scala> query.explain
== Physical Plan ==
*SortMergeJoin [z#9L], [id#13L], Inner
:- *Sort [z#9L ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(z#9L, 200)
: +- *Project [(x#3L + 1) AS z#9L, y#4L]
: +- *Sort [x#3L ASC NULLS FIRST], true, 0
: +- Exchange rangepartitioning(x#3L ASC NULLS FIRST, 200)
: +- *Project [id#0L AS x#3L, (id#0L + 1) AS y#4L]
: +- *Range (0, 10, step=1, splits=8)
+- *Sort [id#13L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(id#13L, 200)
+- *Range (0, 5, step=1, splits=8)
```
Note how codegen'd operators are annotated with a prefix `"*"`. See how the `SortMergeJoin` operator and its direct children `Sort` operators are adjacent and all annotated with the `"*"`, so it's hard to tell they're actually in separate codegen stages.
and after this change it'll be:
```scala
scala> query.explain
== Physical Plan ==
*(6) SortMergeJoin [z#9L], [id#13L], Inner
:- *(3) Sort [z#9L ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(z#9L, 200)
: +- *(2) Project [(x#3L + 1) AS z#9L, y#4L]
: +- *(2) Sort [x#3L ASC NULLS FIRST], true, 0
: +- Exchange rangepartitioning(x#3L ASC NULLS FIRST, 200)
: +- *(1) Project [id#0L AS x#3L, (id#0L + 1) AS y#4L]
: +- *(1) Range (0, 10, step=1, splits=8)
+- *(5) Sort [id#13L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(id#13L, 200)
+- *(4) Range (0, 5, step=1, splits=8)
```
Note that the annotated prefix becomes `"*(id) "`. See how the `SortMergeJoin` operator and its direct children `Sort` operators have different codegen stage IDs.
It'll also show up in the name of the generated class, as a suffix in the format of `GeneratedClass$GeneratedIterator$id`.
For example, note how `GeneratedClass$GeneratedIteratorForCodegenStage3` and `GeneratedClass$GeneratedIteratorForCodegenStage6` in the following stack trace corresponds to the IDs shown in the explain output above:
```
"Executor task launch worker for task 42412957" daemon prio=5 tid=0x58 nid=NA runnable
java.lang.Thread.State: RUNNABLE
at org.apache.spark.sql.execution.UnsafeExternalRowSorter.insertRow(UnsafeExternalRowSorter.java:109)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage3.sort_addToSorter$(generated.java:32)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage3.processNext(generated.java:41)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$9$$anon$1.hasNext(WholeStageCodegenExec.scala:494)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage6.findNextInnerJoinRows$(generated.java:42)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage6.processNext(generated.java:101)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$11$$anon$2.hasNext(WholeStageCodegenExec.scala:513)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:253)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$2.apply(SparkPlan.scala:247)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:828)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsInternal$1$$anonfun$apply$25.apply(RDD.scala:828)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
```
**Rationale**
Right now, the codegen from Spark SQL lacks the means to differentiate between a couple of things:
1. It's hard to tell which physical operators are in the same WholeStageCodegen stage. Note that this "stage" is a separate notion from Spark's RDD execution stages; this one is only to delineate codegen units.
There can be adjacent physical operators that are both codegen'd but are in separate codegen stages. Some of this is due to hacky implementation details, such as the case with `SortMergeJoin` and its `Sort` inputs -- they're hard coded to be split into separate stages although both are codegen'd.
When printing out the explain output of the physical plan, you'd only see the codegen'd physical operators annotated with a preceding star (`'*'`) but would have no way to figure out if they're in the same stage.
2. Performance/error diagnosis
The generated code has class/method names that are hard to differentiate between queries or even between codegen stages within the same query. If we use a Java-level profiler to collect profiles, or if we encounter a Java-level exception with a stack trace in it, it's really hard to tell which part of a query it's at.
By introducing a per-query codegen stage ID, we'd at least be able to know which codegen stage (and in turn, which group of physical operators) was a profile tick or an exception happened.
The reason why this proposal uses a per-query ID is because it's stable within a query, so that multiple runs of the same query will see the same resulting IDs. This both benefits understandability for users, and also it plays well with the codegen cache in Spark SQL which uses the generated source code as the key.
The downside to using per-query IDs as opposed to a per-session or globally incrementing ID is of course we can't tell apart different query runs with this ID alone. But for now I believe this is a good enough tradeoff.
## How was this patch tested?
Existing tests. This PR does not involve any runtime behavior changes other than some name changes.
The SQL query test suites that compares explain outputs have been updates to ignore the newly added `codegenStageId`.
Author: Kris Mok <kris.mok@databricks.com>
Closes apache#20224 from rednaxelafx/wsc-codegenstageid.
…a values for four-channel images ## What changes were proposed in this pull request? When parsing raw image data in ImageSchema.decode(), we use a [java.awt.Color](https://docs.oracle.com/javase/7/docs/api/java/awt/Color.html#Color(int)) constructor that sets alpha = 255, even for four-channel images (which may have different alpha values). This PR fixes this issue & adds a unit test to verify correctness of reading four-channel images. ## How was this patch tested? Updates an existing unit test ("readImages pixel values test" in `ImageSchemaSuite`) to also verify correctness when reading a four-channel image. Author: Sid Murching <sid.murching@databricks.com> Closes apache#20389 from smurching/image-schema-bugfix.
Third time is the charm? There was still a race that was left in previous attempts. If the handle closes the connection, the close() implementation would clean up state that would prevent the thread from waiting on the connection thread to finish. That could cause the race causing the test flakiness reported in the bug. The fix is to move the "wait for connection thread" code to a separate close method that is used by the handle; that also simplifies the code a bit and makes it also easier to follow. I included an unrelated, but correct, change to a YARN test so that it triggers when the PR is built. Tested by inserting a sleep in the connection thread to mimic the race; test failed reliably with the sleep, passes now. (Sleep not included in the patch.) Also ran YARN tests to make sure. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes apache#20388 from vanzin/SPARK-23020.
## What changes were proposed in this pull request? When using the Kubernetes cluster-manager and spawning a Streaming workload, it is important to reset many spark.kubernetes.* properties that are generated by spark-submit but which would get rewritten when restoring a Checkpoint. This is so, because the spark-submit codepath creates Kubernetes resources, such as a ConfigMap, a Secret and other variables, which have an autogenerated name and the previous one will not resolve anymore. In short, this change enables checkpoint restoration for streaming workloads, and thus enables Spark Streaming workloads in Kubernetes, which were not possible to restore from a checkpoint before if the workload went down. ## How was this patch tested? This patch was tested with the twitter-streaming example in AWS, using checkpoints in s3 with the s3a:// protocol, as supported by Hadoop. This is similar to the YARN related code for resetting a Spark Streaming workload, but for the Kubernetes scheduler. I'm adding the initcontainers properties because even if the discussion is not completely settled on the mailing list, my understanding is that at this moment they are going forward for the moment. For a previous discussion, see the non-rebased work at: apache-spark-on-k8s#516 Author: Santiago Saavedra <ssaavedra@openshine.com> Closes apache#20383 from ssaavedra/fix-k8s-checkpointing.
…lti-column params are both set ## What changes were proposed in this pull request? Currently there is a mixed situation when both single- and multi-column are supported. In some cases exceptions are thrown, in others only a warning log is emitted. In this discussion https://issues.apache.org/jira/browse/SPARK-8418?focusedCommentId=16275049&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-16275049, the decision was to throw an exception. The PR throws an exception in `Bucketizer`, instead of logging a warning. ## How was this patch tested? modified UT Author: Marco Gaido <marcogaido91@gmail.com> Author: Joseph K. Bradley <joseph@databricks.com> Closes apache#19993 from mgaido91/SPARK-22799.
## What changes were proposed in this pull request? Bucketizer support multi-column in the python side ## How was this patch tested? existing tests and added tests Author: Zheng RuiFeng <ruifengz@foxmail.com> Closes apache#19892 from zhengruifeng/20542_py.
…lues and putIteratorAsBytes ## What changes were proposed in this pull request? The code logic between `MemoryStore.putIteratorAsValues` and `Memory.putIteratorAsBytes` are almost same, so we should reduce the duplicate code between them. ## How was this patch tested? Existing UT. Author: Xianyang Liu <xianyang.liu@intel.com> Closes apache#19285 from ConeyLiu/rmemorystore.
## What changes were proposed in this pull request? `ColumnVector` is very flexible about how to implement array type. As a result `ColumnVector` has 3 abstract methods for array type: `arrayData`, `getArrayOffset`, `getArrayLength`. For example, in `WritableColumnVector` we use the first child vector as the array data vector, and store offsets and lengths in 2 arrays in the parent vector. `ArrowColumnVector` has a different implementation. This PR simplifies `ColumnVector` by using only one abstract method for array type: `getArray`. ## How was this patch tested? existing tests. rerun `ColumnarBatchBenchmark`, there is no performance regression. Author: Wenchen Fan <wenchen@databricks.com> Closes apache#20395 from cloud-fan/vector.
This reverts commit c22eaa9.
…ncorrect answers
## What changes were proposed in this pull request?
Currently shuffle repartition uses RoundRobinPartitioning, the generated result is nondeterministic since the sequence of input rows are not determined.
The bug can be triggered when there is a repartition call following a shuffle (which would lead to non-deterministic row ordering), as the pattern shows below:
upstream stage -> repartition stage -> result stage
(-> indicate a shuffle)
When one of the executors process goes down, some tasks on the repartition stage will be retried and generate inconsistent ordering, and some tasks of the result stage will be retried generating different data.
The following code returns 931532, instead of 1000000:
```
import scala.sys.process._
import org.apache.spark.TaskContext
val res = spark.range(0, 1000 * 1000, 1).repartition(200).map { x =>
x
}.repartition(200).map { x =>
if (TaskContext.get.attemptNumber == 0 && TaskContext.get.partitionId < 2) {
throw new Exception("pkill -f java".!!)
}
x
}
res.distinct().count()
```
In this PR, we propose a most straight-forward way to fix this problem by performing a local sort before partitioning, after we make the input row ordering deterministic, the function from rows to partitions is fully deterministic too.
The downside of the approach is that with extra local sort inserted, the performance of repartition() will go down, so we add a new config named `spark.sql.execution.sortBeforeRepartition` to control whether this patch is applied. The patch is default enabled to be safe-by-default, but user may choose to manually turn it off to avoid performance regression.
This patch also changes the output rows ordering of repartition(), that leads to a bunch of test cases failure because they are comparing the results directly.
## How was this patch tested?
Add unit test in ExchangeSuite.
With this patch(and `spark.sql.execution.sortBeforeRepartition` set to true), the following query returns 1000000:
```
import scala.sys.process._
import org.apache.spark.TaskContext
spark.conf.set("spark.sql.execution.sortBeforeRepartition", "true")
val res = spark.range(0, 1000 * 1000, 1).repartition(200).map { x =>
x
}.repartition(200).map { x =>
if (TaskContext.get.attemptNumber == 0 && TaskContext.get.partitionId < 2) {
throw new Exception("pkill -f java".!!)
}
x
}
res.distinct().count()
res7: Long = 1000000
```
Author: Xingbo Jiang <xingbo.jiang@databricks.com>
Closes apache#20393 from jiangxb1987/shuffle-repartition.
## What changes were proposed in this pull request? KafkaSourceSuiteBase should be abstract class, otherwise KafkaSourceSuiteBase will also run. ## How was this patch tested? Jenkins Author: Shixiong Zhu <zsxwing@gmail.com> Closes apache#20412 from zsxwing/SPARK-23242.
## What changes were proposed in this pull request? This is a regression introduced by apache#19864 When we lookup cache, we should not carry the hint info, as this cache entry might be added by a plan having hint info, while the input plan for this lookup may not have hint info, or have different hint info. ## How was this patch tested? a new test. Author: Wenchen Fan <wenchen@databricks.com> Closes apache#20394 from cloud-fan/cache.
## What changes were proposed in this pull request? This PR fixes Scala/Java doc examples in `Trigger.java`. ## How was this patch tested? N/A. Author: Dongjoon Hyun <dongjoon@apache.org> Closes apache#20401 from dongjoon-hyun/SPARK-TRIGGER.
brkyvz
pushed a commit
that referenced
this pull request
May 2, 2020
…types
### What changes were proposed in this pull request?
This PR intends to fix a bug that occurs when comparing null types to decimal types in master/branch-3.0;
```
scala> Seq(BigDecimal(10)).toDF("v1").selectExpr("v1 = NULL").explain(true)
org.apache.spark.sql.AnalysisException: cannot resolve '(`v1` = NULL)' due to data type mismatch: differing types in '(`v1` = NULL)' (decimal(38,18) and null).; line 1 pos 0;
'Project [(v1#5 = null) AS (v1 = NULL)#7]
+- Project [value#2 AS v1#5]
+- LocalRelation [value#2]
...
```
The query above passed in v2.4.5.
### Why are the changes needed?
bugfix
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Added tests.
Closes apache#28241 from maropu/SPARK-31468.
Authored-by: Takeshi Yamamuro <yamamuro@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
No description provided.