Cache small blocks on the gateway seperately from responses #301
Assignees

Comments
fforbeck
added a commit
to storacha/freeway
that referenced
this issue
Jan 28, 2025
#147) ### Context The requests to fetch a DAG Protobuf directory structure using a CID execute the following steps: 1. Get all content claims lookups to identify where we are pulling data from 2. Fetch cid `bafy...cid` - which represents the folder containing the target file, so that we can determine the verifiable cid for the file (let's call that `bafy...file`) 3. Fetch cid `bafy...file` to get the root block of the file, which in UnixFS contains NO raw data, but rather is a list of sub-blocks that contain the file (let's call those `bafy...bytes1` and `bafy...bytes2`) 4. Fetch the first raw data blocks to send the first byte This PR enables the caching strategy for steps 2 to 4 where instead of fetching the directory structure from the locator and navigating the DAG for every request, it caches the DAGs if they have a Protobuf structure and content size <= 2MB. ### Changes - Updated `withContentClaimsDagula` middleware to cache DAG PB content requests - New KV Store - `DAGPB_CONTENT_CACHE` - Caching rules - `FF_DAGPB_CONTENT_CACHE_TTL_SECONDS`: The number that represents when to expire the key-value pair in seconds from now. The minimum value is 60 seconds. Any value less than 60MB will not be used. We will use **30 days TTL** by default for Production environment. - `FF_DAGPB_CONTENT_CACHE_MAX_SIZE_MB`: The maximum size of the key-value pair in MB. The minimum value is 1 MB. Any value less than 1MB will not be used. We will use **2MB max file size** by default. - `FF_DAGPB_CONTENT_CACHE_ENABLED`: The flag that enables the DAGPB content cache. The cache is **disabled in prod** by default. ### Samples **2MB file - no cache** 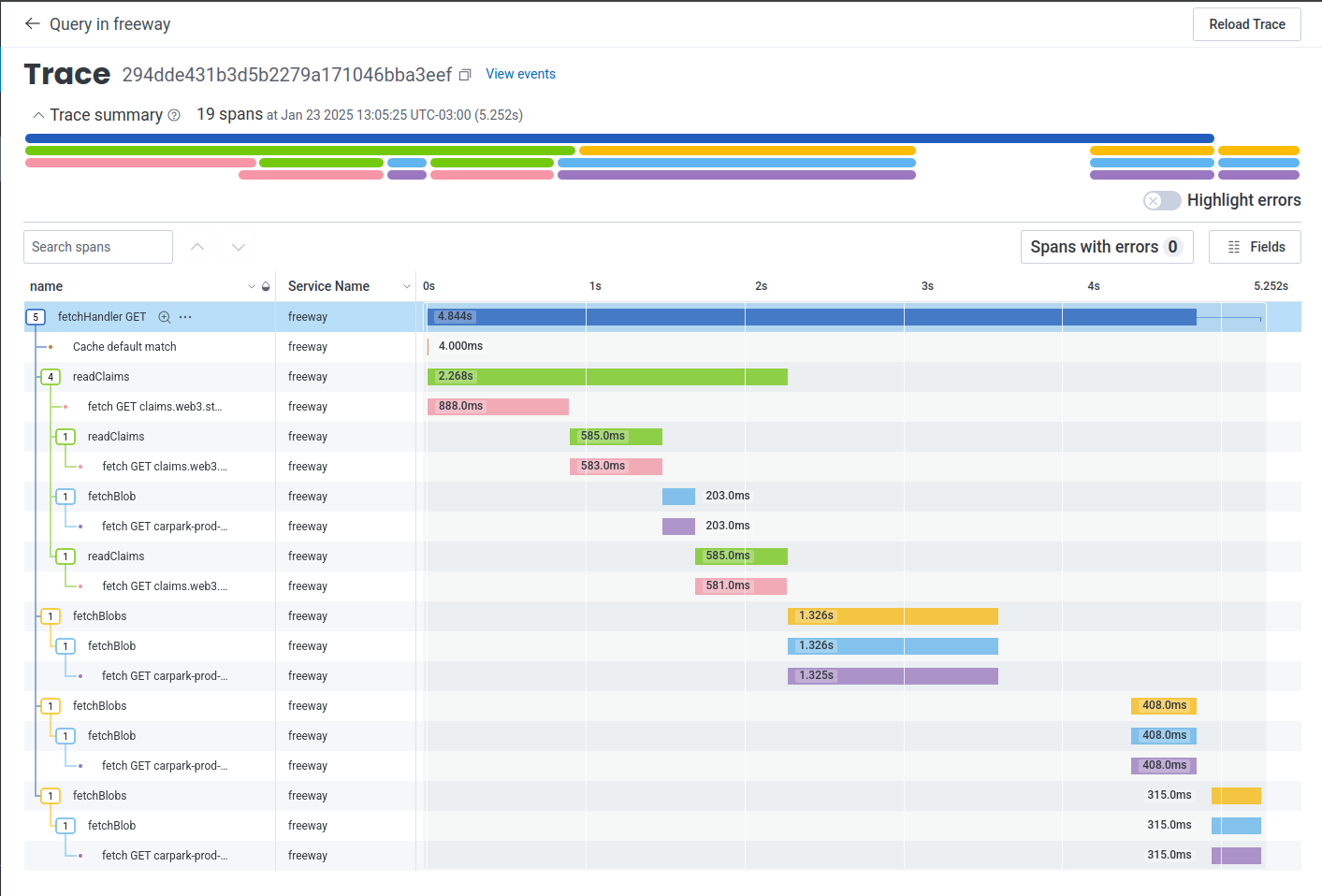 - 5.2 seconds **2MB file - cached** 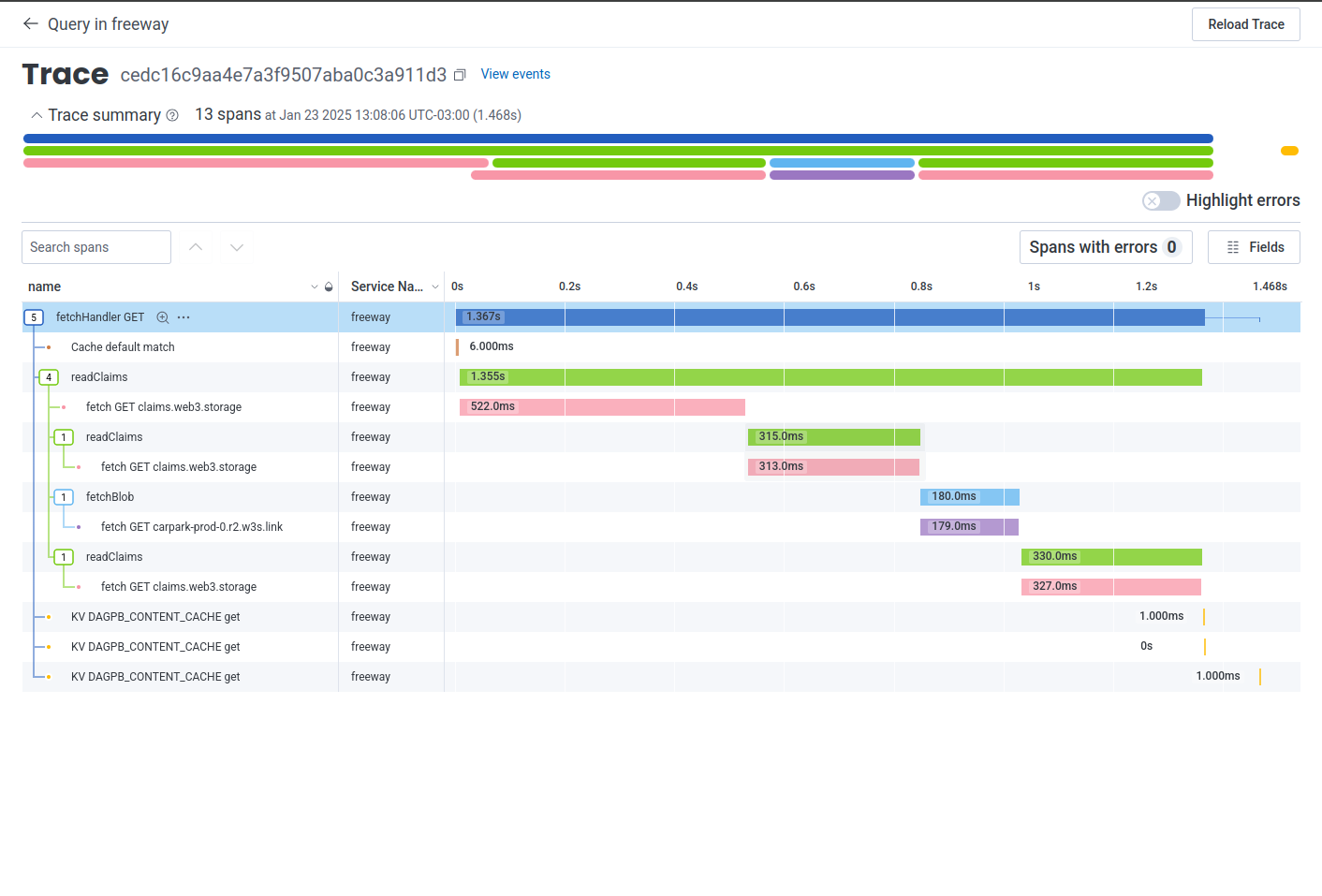 - 1.4 seconds ### KV Limits - Reads: unlimited - Writes (different keys): unlimited - Writes (same key): 1w / sec (rate limiting) - Storage/account & Storage/namespace: unlimited - key size: <= 512 bytes - value size: <= 25MiB - Minimum cache ttl: 60 seconds - Higher limit? -> https://forms.gle/ukpeZVLWLnKeixDu7 resolves storacha/project-tracking#301
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
What
Our typical request pattern for data on the gateway looks like this:
/ipfs/bafy...cid/somefile.txt(orbafy...cid.w3s.link/somefile.txtthrough w3s link). When we upload, even for individual files we wrap them in a folder with one item just so they can be addressed by nameThis means the steps to get to first byte are as follows:
bafy...cidwhich represents the folder containingsomefile.txt, so that we can determine the verifiable cid forsomefile.txt(let's call thatbafy...file)bafy...fileto get the root block of the file, which in UnixFS contains NO raw data, but rather is a list of sub-blocks that contain the file (let's call thosebafy...bytes1andbafy...bytes2)Step 1 is a process we are trying optimize through the indexer.
2-4 however are 3 http roundtrips, which is just not realistic to get to first byte. Two of the round trips for typically small blocks that simply point us to the next link. It's made worse cause of #299, where some of those round trips are taking multiple seconds.
The proposed solution is as follows:
use cloudflare KV to cache these blocks or even better, simply the paths within them.
After first fetch, the following entry
Key:
bafy...cid/somefile.txt/0-1000000Value:
baby...bytes1Is sufficient to eliminate 2 of the 3 round trips on next request.
This should be relatively few lines of code but will require some knowledge of UnixFS, UnixFS exporter, and Dagula to do. Recommend if a newer dev is assigned that we pair with a experienced dev on repo guidance.
The KV should have a longer lifespan and eventually global distribution.
Acceptance criteria
Demonstrate traces in honeycomb
Note: you may need to disable caching of the whole request to demonstrate this behavior in test.
The text was updated successfully, but these errors were encountered: