Fixed AttributeError: 'UsedTable' has no attribute 'table' by adding more type checks
#2895
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
…g more type checks Fix #2887
|
✅ 87/87 passed, 2 flaky, 5 skipped, 3h23m14s total Flaky tests:
Running from acceptance #6562 |
nfx
added a commit
that referenced
this pull request
Oct 9, 2024
* Added UCX history schema and table for storing UCX's artifact ([#2744](#2744)). In this release, we have introduced a new dataclass `Historical` to store UCX artifacts for migration progress tracking, including attributes such as workspace identifier, job run identifier, object type, object identifier, data, failures, owner, and UCX version. The `ProgressTrackingInstallation` class has been updated to include a new method for deploying a table for historical records using the `Historical` dataclass. Additionally, we have modified the `databricks labs ucx create-ucx-catalog` command, and updated the integration test file `test_install.py` to include a parametrized test function for checking if the `workflow_runs` and `historical` tables are created by the UCX installation. We have also renamed the function `test_progress_tracking_installation_run_creates_workflow_runs_table` to `test_progress_tracking_installation_run_creates_tables` to reflect the addition of the new table. These changes add necessary functionality for tracking UCX migration progress and provide associated tests to ensure correctness, thereby improving UCX's progress tracking functionality and resolving issue [#2572](#2572). * Added `hjson` to known list ([#2899](#2899)). In this release, we are excited to announce the addition of support for the Hjson library, addressing partial resolution for issue [#1931](#1931) related to configuration. This change integrates the following Hjson modules: hjson, hjson.compat, hjson.decoder, hjson.encoder, hjson.encoderH, hjson.ordered_dict, hjson.scanner, and hjson.tool. Hjson is a powerful library that enhances JSON functionality by providing comments and multi-line strings. By incorporating Hjson into our library's known list, users can now leverage its advanced features in a more streamlined and cohesive manner, resulting in a more versatile and efficient development experience. * Bump databrickslabs/sandbox from acceptance/v0.3.0 to 0.3.1 ([#2894](#2894)). In this version bump from acceptance/v0.3.0 to 0.3.1 of the databrickslabs/sandbox library, several enhancements and bug fixes have been implemented. These changes include updates to the README file with instructions on how to use the library with the databricks labs sandbox command, fixes for the `unsupported protocol scheme` error, and the addition of more git-related libraries. Additionally, dependency updates for golang.org/x/crypto from version 0.16.0 to 0.17.0 have been made in the /go-libs and /runtime-packages directories. This version also introduces new commits that allow larger logs from acceptance tests and implement experimental OIDC refresh token rotation. The tests using this library have been updated to utilize the new version to ensure compatibility and functionality. * Fixed `AttributeError: `UsedTable` has no attribute 'table'` by adding more type checks ([#2895](#2895)). In this release, we have made significant improvements to the library's type safety and robustness in handling `UsedTable` objects. We fixed an AttributeError related to the `UsedTable` class not having a `table` attribute by adding more type checks in the `collect_tables` method of the `TablePyCollector` and `CollectTablesVisit` classes. We also introduced `AstroidSyntaxError` exception handling and logging. Additionally, we renamed the `table_infos` variable to `used_tables` and changed its type to 'list[JobProblem]' in the `collect_tables_from_tree` and '_SparkSqlAnalyzer.collect_tables' functions. We added conditional statements to check for the presence of required attributes before yielding a new 'TableInfoNode'. A new unit test file, 'test_context.py', has been added to exercise the `tables_collector` method, which extracts table references from a given code snippet, improving the linter's table reference extraction capabilities. * Fixed `TokenError` in assessment workflow ([#2896](#2896)). In this update, we've implemented a bug fix to improve the robustness of the assessment workflow in our open-source library. Previously, the code only caught parse errors during the execution of the workflow, but parse errors were not the only cause of failures. This commit changes the exception being caught from `ParseError` to the more general `SqlglotError`, which is the common ancestor of both `ParseError` and `TokenError`. By catching the more general `SqlglotError`, the code is now able to handle both parse errors and tokenization errors, providing a more robust solution. The `walk_expressions` method has been updated to catch `SqlglotError` instead of `ParseError`. This change allows the assessment workflow to handle a wider range of issues that may arise during the execution of SQL code, making it more versatile and reliable. The `SqlglotError` class has been imported from the `sqlglot.errors` module. This update enhances the assessment workflow's ability to handle more complex SQL queries, ensuring smoother execution. * Fixed `assessment` workflow failure for jobs running tasks on existing interactive clusters ([#2889](#2889)). In this release, we have implemented changes to address a failure in the `assessment` workflow when jobs are run on existing interactive clusters (issue [#2886](#2886)). The fix includes modifying the `jobs.py` file by adding a try-except block when loading libraries for an existing cluster, utilizing a new exception type `ResourceDoesNotExist` to handle cases where the cluster does not exist. Furthermore, the `_register_cluster_info` function has been enhanced to manage situations where the existing cluster is not found, raising a `DependencyProblem` with the message 'cluster-not-found'. This ensures the workflow can continue running jobs on other clusters or with other configurations. Overall, these enhancements improve the system's robustness by gracefully handling edge cases and preventing workflow failure due to non-existent clusters. * Ignore UCX inventory database in HMS while scanning tables ([#2897](#2897)). In this release, changes have been implemented in the 'tables.py' file of the 'databricks/labs/ucx/hive_metastore' directory to address the issue of mistakenly scanning the UCX inventory database during table scanning. The `_all_databases` method has been updated to exclude the UCX inventory database by checking if the database name matches the schema name and skipping it if so. This change affects the `_crawl` and `_get_table_names` methods, which no longer process the UCX inventory schema when scanning for tables. A TODO comment has been added to the `_get_table_names` method, suggesting potential removal of the UCX inventory schema check in future releases. This change ensures accurate and efficient table scanning, avoiding the `hallucination` of mistaking the UCX inventory schema as a database to be scanned. * Tech debt: fix situations where `next()` isn't being used properly ([#2885](#2885)). In this commit, technical debt related to the proper usage of Python's built-in `next()` function has been addressed in several areas of the codebase. Previously, there was an assumption that `None` would be returned if there is no next value, which is incorrect. This commit updates and fixes the implementation to correctly handle cases where `next()` is used. Specifically, the `get_dbutils_notebook_run_path_arg`, `of_language` class method in the `CellLanguage` class, and certain methods in the `test_table_migrate.py` file have been updated to correctly handle situations where there is no next value. The `has_path()` method has been removed, and the `prepend_path()` method has been updated to insert the given path at the beginning of the list of system paths. Additionally, a test case for checking table in mount mapping with table owner has been included. These changes improve the robustness and reliability of the code by ensuring that it handles edge cases related to the `next()` function and paths correctly. * [chore] apply `make fmt` ([#2883](#2883)). In this release, the `make_random` parameter has been removed from the `save_locations` method in the `conftest.py` file for the integration tests. This method is used to save a list of `ExternalLocation` objects to the `external_locations` table in the inventory database, and it no longer requires the `make_random` parameter. In the updated implementation, the `save_locations` method creates a single `ExternalLocation` object with a specific string and priority based on the workspace environment (Azure or AWS), and then uses the SQL backend to save the list of `ExternalLocation` objects to the database. This change simplifies the `save_locations` method and makes it more reusable throughout the test suite. Dependency updates: * Bump databrickslabs/sandbox from acceptance/v0.3.0 to 0.3.1 ([#2894](#2894)).
Merged
nfx
added a commit
that referenced
this pull request
Oct 9, 2024
* Added UCX history schema and table for storing UCX's artifact ([#2744](#2744)). In this release, we have introduced a new dataclass `Historical` to store UCX artifacts for migration progress tracking, including attributes such as workspace identifier, job run identifier, object type, object identifier, data, failures, owner, and UCX version. The `ProgressTrackingInstallation` class has been updated to include a new method for deploying a table for historical records using the `Historical` dataclass. Additionally, we have modified the `databricks labs ucx create-ucx-catalog` command, and updated the integration test file `test_install.py` to include a parametrized test function for checking if the `workflow_runs` and `historical` tables are created by the UCX installation. We have also renamed the function `test_progress_tracking_installation_run_creates_workflow_runs_table` to `test_progress_tracking_installation_run_creates_tables` to reflect the addition of the new table. These changes add necessary functionality for tracking UCX migration progress and provide associated tests to ensure correctness, thereby improving UCX's progress tracking functionality and resolving issue [#2572](#2572). * Added `hjson` to known list ([#2899](#2899)). In this release, we are excited to announce the addition of support for the Hjson library, addressing partial resolution for issue [#1931](#1931) related to configuration. This change integrates the following Hjson modules: hjson, hjson.compat, hjson.decoder, hjson.encoder, hjson.encoderH, hjson.ordered_dict, hjson.scanner, and hjson.tool. Hjson is a powerful library that enhances JSON functionality by providing comments and multi-line strings. By incorporating Hjson into our library's known list, users can now leverage its advanced features in a more streamlined and cohesive manner, resulting in a more versatile and efficient development experience. * Bump databrickslabs/sandbox from acceptance/v0.3.0 to 0.3.1 ([#2894](#2894)). In this version bump from acceptance/v0.3.0 to 0.3.1 of the databrickslabs/sandbox library, several enhancements and bug fixes have been implemented. These changes include updates to the README file with instructions on how to use the library with the databricks labs sandbox command, fixes for the `unsupported protocol scheme` error, and the addition of more git-related libraries. Additionally, dependency updates for golang.org/x/crypto from version 0.16.0 to 0.17.0 have been made in the /go-libs and /runtime-packages directories. This version also introduces new commits that allow larger logs from acceptance tests and implement experimental OIDC refresh token rotation. The tests using this library have been updated to utilize the new version to ensure compatibility and functionality. * Fixed `AttributeError: `UsedTable` has no attribute 'table'` by adding more type checks ([#2895](#2895)). In this release, we have made significant improvements to the library's type safety and robustness in handling `UsedTable` objects. We fixed an AttributeError related to the `UsedTable` class not having a `table` attribute by adding more type checks in the `collect_tables` method of the `TablePyCollector` and `CollectTablesVisit` classes. We also introduced `AstroidSyntaxError` exception handling and logging. Additionally, we renamed the `table_infos` variable to `used_tables` and changed its type to 'list[JobProblem]' in the `collect_tables_from_tree` and '_SparkSqlAnalyzer.collect_tables' functions. We added conditional statements to check for the presence of required attributes before yielding a new 'TableInfoNode'. A new unit test file, 'test_context.py', has been added to exercise the `tables_collector` method, which extracts table references from a given code snippet, improving the linter's table reference extraction capabilities. * Fixed `TokenError` in assessment workflow ([#2896](#2896)). In this update, we've implemented a bug fix to improve the robustness of the assessment workflow in our open-source library. Previously, the code only caught parse errors during the execution of the workflow, but parse errors were not the only cause of failures. This commit changes the exception being caught from `ParseError` to the more general `SqlglotError`, which is the common ancestor of both `ParseError` and `TokenError`. By catching the more general `SqlglotError`, the code is now able to handle both parse errors and tokenization errors, providing a more robust solution. The `walk_expressions` method has been updated to catch `SqlglotError` instead of `ParseError`. This change allows the assessment workflow to handle a wider range of issues that may arise during the execution of SQL code, making it more versatile and reliable. The `SqlglotError` class has been imported from the `sqlglot.errors` module. This update enhances the assessment workflow's ability to handle more complex SQL queries, ensuring smoother execution. * Fixed `assessment` workflow failure for jobs running tasks on existing interactive clusters ([#2889](#2889)). In this release, we have implemented changes to address a failure in the `assessment` workflow when jobs are run on existing interactive clusters (issue [#2886](#2886)). The fix includes modifying the `jobs.py` file by adding a try-except block when loading libraries for an existing cluster, utilizing a new exception type `ResourceDoesNotExist` to handle cases where the cluster does not exist. Furthermore, the `_register_cluster_info` function has been enhanced to manage situations where the existing cluster is not found, raising a `DependencyProblem` with the message 'cluster-not-found'. This ensures the workflow can continue running jobs on other clusters or with other configurations. Overall, these enhancements improve the system's robustness by gracefully handling edge cases and preventing workflow failure due to non-existent clusters. * Ignore UCX inventory database in HMS while scanning tables ([#2897](#2897)). In this release, changes have been implemented in the 'tables.py' file of the 'databricks/labs/ucx/hive_metastore' directory to address the issue of mistakenly scanning the UCX inventory database during table scanning. The `_all_databases` method has been updated to exclude the UCX inventory database by checking if the database name matches the schema name and skipping it if so. This change affects the `_crawl` and `_get_table_names` methods, which no longer process the UCX inventory schema when scanning for tables. A TODO comment has been added to the `_get_table_names` method, suggesting potential removal of the UCX inventory schema check in future releases. This change ensures accurate and efficient table scanning, avoiding the `hallucination` of mistaking the UCX inventory schema as a database to be scanned. * Tech debt: fix situations where `next()` isn't being used properly ([#2885](#2885)). In this commit, technical debt related to the proper usage of Python's built-in `next()` function has been addressed in several areas of the codebase. Previously, there was an assumption that `None` would be returned if there is no next value, which is incorrect. This commit updates and fixes the implementation to correctly handle cases where `next()` is used. Specifically, the `get_dbutils_notebook_run_path_arg`, `of_language` class method in the `CellLanguage` class, and certain methods in the `test_table_migrate.py` file have been updated to correctly handle situations where there is no next value. The `has_path()` method has been removed, and the `prepend_path()` method has been updated to insert the given path at the beginning of the list of system paths. Additionally, a test case for checking table in mount mapping with table owner has been included. These changes improve the robustness and reliability of the code by ensuring that it handles edge cases related to the `next()` function and paths correctly. * [chore] apply `make fmt` ([#2883](#2883)). In this release, the `make_random` parameter has been removed from the `save_locations` method in the `conftest.py` file for the integration tests. This method is used to save a list of `ExternalLocation` objects to the `external_locations` table in the inventory database, and it no longer requires the `make_random` parameter. In the updated implementation, the `save_locations` method creates a single `ExternalLocation` object with a specific string and priority based on the workspace environment (Azure or AWS), and then uses the SQL backend to save the list of `ExternalLocation` objects to the database. This change simplifies the `save_locations` method and makes it more reusable throughout the test suite. Dependency updates: * Bump databrickslabs/sandbox from acceptance/v0.3.0 to 0.3.1 ([#2894](#2894)).
1 task
nfx
pushed a commit
that referenced
this pull request
Oct 11, 2024
## Changes PR #2895 introduced a workaround for #2887, although the issue was not reproduced. Careful analysis shows that this workaround is not necessary. Tests were added recently in `test_context.py`. Running the above tests against v0.39 reproduces the issue: 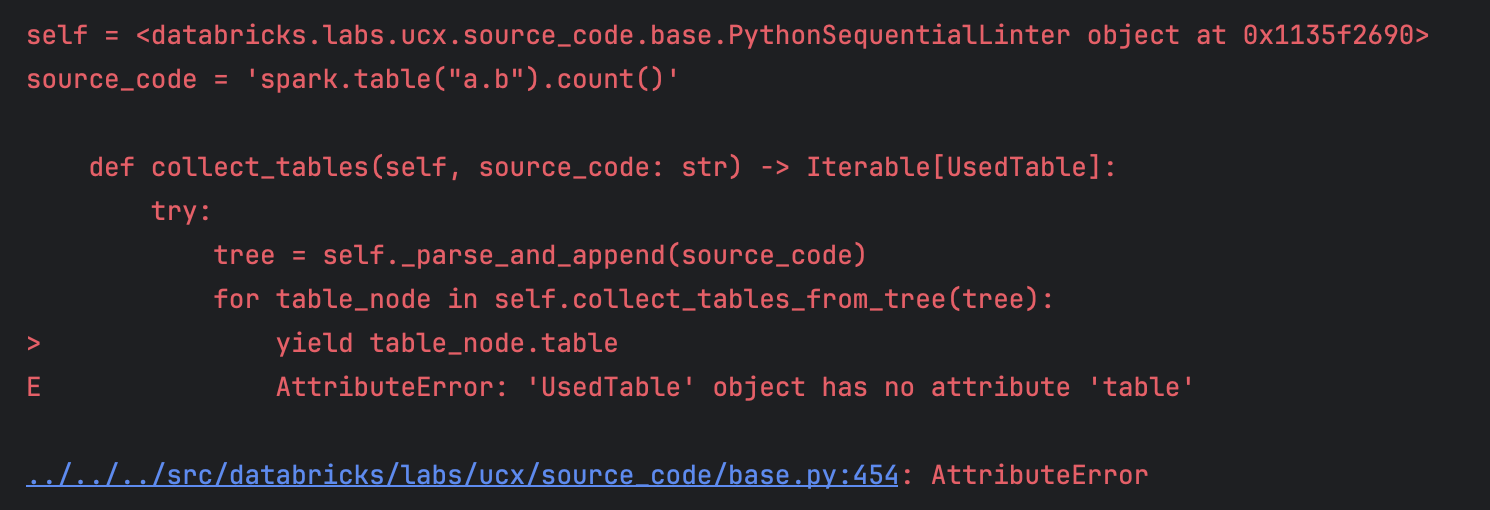 However, running the above tests against v0.40 and above does not reproduce the issue:  The issue was already fixed in `pyspark.py` by PR #2841 and it is likely that the bug reporter was running v0.39 This PR: - rolls back the workaround from #2895 - renames TableInfoNode to UsedTableNode for clarity ### Linked issues #2887 ### Functionality None ### Tests - [x] manually tested --------- Co-authored-by: Eric Vergnaud <eric.vergnaud@databricks.com>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Fix #2887