2 scheduler
[TOC]
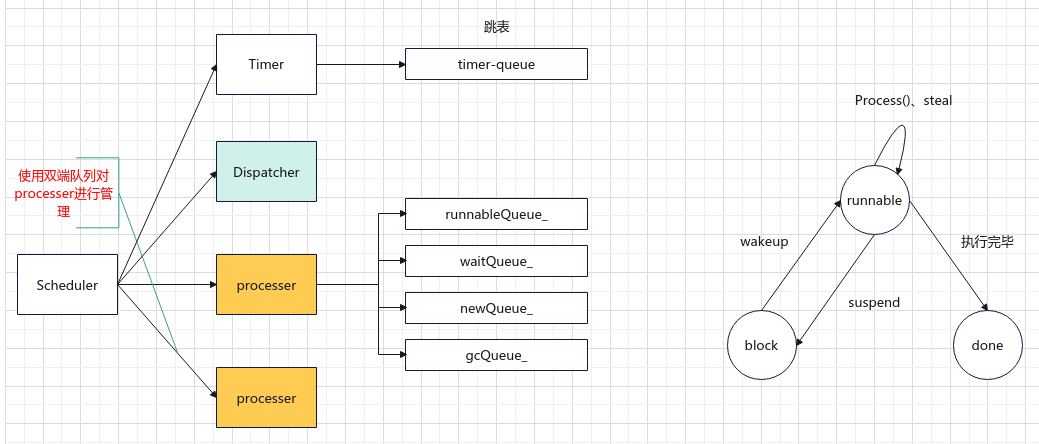
协程中最重要的就是协程的调度,在libgo中负责协程调度的结构为Scheduler,Scheduler由3个部分组成,分别是Processer、Dispatcher和Timer,如图1所示:

libgo中负责调度的有三个角色,分别是Scheduler,Dispatcher和processer,其中:
-
Scheduler负责管理Dispatcher和processer,libgo会提供一个默认的Scheduler名为co_sched,也可以通过Scheduler::Create()创建新的调度器。==协程只会在所属的调度器中被调度, 创建额外的调度器可以实现业务间的隔离.== -
processer负责协程的调度,每一个processer维护了四个队列,-
newQueue_队列存放新加入的协程,包括新创建的协程,唤醒挂起的协程,还有 steal 来的协程; -
runnableQueue_:可运行协程队列; -
waitQueue_:存放挂起的协程; -
gcQueue:存放需要gc的协程。
-
-
Dispatcher负责不同processer上的协程的负载均衡,实现协程的跨线程迁移Steal,增加新的processer等。==只有在processer数量大于1的时候才会创建Dispatcher线程。==
注:
Scheduler使用双端队列对processer进行管理- 调用Processer::Process()时会检查
runnableQueue_是否为空,若为空,把newQueue_中的task放入runnableQueue_- 除此之外,scheduler还拥有一个timer线程用于处理超时任务
下图展示了scheduler相关的类图:主要对processer.h,processer.cpp,scheduler.h,scheduler.cpp中涉及的类进行了梳理
图中对类的成员进行了一定的删减。

scheduler最初的设计是单例模式的,所有的task都被一个scheduler管理,但是为了实现业务间的隔离,提供了创建新的scheduler的方法,协程只会在所属的scheduler中调度。
下面的代码是从scheduler.h中截取的,从中不难看出,构造函数和析构函数都是私有方法,并且不允许复制构造,赋值构造等操作。
private:
Scheduler();
~Scheduler();
Scheduler(Scheduler const&) = delete;
Scheduler(Scheduler &&) = delete;
Scheduler& operator=(Scheduler const&) = delete;
Scheduler& operator=(Scheduler &&) = delete;提供了getInstance方法获取实例,定义了一个全局变量g_Scheduler,
这个全局变量也是默认的调度器co_sched,通过#define co_sched g_Scheduler定义
#define g_Scheduler ::co::Scheduler::getInstance()
ALWAYS_INLINE Scheduler& Scheduler::getInstance()
{
static Scheduler obj;
return obj;
}同时,提供了Create函数,用于创建一个新的scheduler
Scheduler* Scheduler::Create()
{
static int ignore = InitOnExit();
(void)ignore;
Scheduler* sched = new Scheduler;
std::unique_lock<std::mutex> lock(ExitListMtx()); // for thread safe, vec
auto vec = ExitList();
vec->push_back([=] { delete sched; });
return sched;
}该函数:
- 首先注册了程序退出(调用exit或main函数返回时)时需要执行的函数
- 创建一个scheduler
- 为了全局变量vec在添加操作时的线程安全,添加了独占锁
- 在vec中添加退出时需执行的函数
delete sched,在退出时调用析构函数删除创建的实例的空间,完成gc。详见gc. - 返回实例指针
构造函数定义如下:
Scheduler::Scheduler()
{
LibgoInitialize();
processers_.push_back(new Processer(this, 0)); // 新建一个processer,加入管理队列
}下面给出了LibgoInitialize函数的定义;
static int staticInitialize()
{
// scheduler
TaskRefInit(Affinity);
TaskRefInit(Location);
TaskRefInit(DebugInfo);
// cls
TaskRefInit(ClsMap);
#if ENABLE_HOOK
initHook(); // enable syscall
#endif
return 0;
}
void LibgoInitialize()
{
static int ignore = staticInitialize();
(void)ignore;
}
TaskRefInit 是一个宏: #define TaskRefInit(name) do { TaskRef ## name(TaskInitPtr); } while(0)
TaskRefInit(Affinity) 展开后得到 do{TaskRefAffinity(TaskInitPtr);} while(0)类似TaskRefAffinity的函数也是由宏定义的,
#define TaskRefDefine(type, name) \
ALWAYS_INLINE type& TaskRef ## name(Task *tk) \
{ \
typedef type T; \
static int idx = -1; \
if (UNLIKELY(tk == TaskInitPtr)) { \
if (idx == -1) \
idx = TaskAnys::Register<T>(); \
static T ignore{}; \
return ignore; \
} \
return tk->anys_.get<T>(idx); \
}
----------- 同样,以 bool ‘Affinity’ 为例,展开后得到:
ALWAYS_INLINE bool& TaskRefAffinity(Task *tk)
{
typedef bool T;
static int idx = -1;
if (UNLIKELY(tk == TaskInitPtr)) {
if (idx == -1) idx = TaskAnys::Register<T>(); // TaskAnys -- TODO
static T ignore{}; return ignore;
}
return tk->anys_.get<T>(idx);
}void Scheduler::Start(int minThreadNumber, int maxThreadNumber);该函数的作用是根据传入的min和max两个参数确定运行的processer的数量:
- 设置
min和max- 如果
min < 1,设置min = 硬件线程数量 - 如果
max = 0或max < min,设置max = min
- 如果
- 设置一个主
processer,mainProc = processers_[0] - 根据
min的大小创建新的processer - 如果
max > 1,启动dispatcher线程 - 启动一个定时器线程
std::thread(FastSteadyClock::ThreadRun).detach(); - 主
processer开始执行Process(),进行协程的执行。详见processer.Process()
析构函数定义如下:
Scheduler::~Scheduler()
{
IsExiting() = true; // 为成员 exiting 赋值为ture
Stop();
}
void Scheduler::Stop()
{
std::unique_lock<std::mutex> lock(stopMtx_);
if (stop_) return;
stop_ = true;
size_t n = processers_.size();
for (size_t i = 0; i < n; ++i) {
auto p = processers_[i];
if (p)
p->NotifyCondition();
}
if (timer_) timer_->stop();
if (dispatchThread_.joinable())
dispatchThread_.join();
}每一个scheduler都拥有一个timer线程,负责管理该scheduler所有设定超时的任务,通过带时间的Suspend函数进行设置。也管理hook的系统调用,同样也是通过带时间的Suspend函数。
在scheduler类中对timer进行了封装 typedef ::libgo::RoutineSyncTimer TimerType;
通过TimerType & StaticGetTimer();获取默认的timer
static Scheduler::TimerType &staticGetTimer()
{
static Scheduler::TimerType *ptimer = new Scheduler::TimerType;
std::unique_lock<std::mutex> lock(ExitListMtx());
auto vec = ExitList();
vec->push_back([=]
{ ptimer->stop(); });
return *ptimer;
}
Scheduler::TimerType &Scheduler::StaticGetTimer()
{
static TimerType &timer = staticGetTimer();
return timer;
}TimerType的默认构造函数会启动一个线程,执行run函数
RoutineSyncTimer() : thread_([this]{ run(); }) {}
void run()
{
std::unique_lock<MutexT> lock(mtx_);
while (!exit_) //未调用 stop()
{
TimerId* id = orderedList_.front(); // 取出跳表第一个元素
auto nowTp = now(); // 获取当前时间
if (id && nowTp >= id->key) { // 当前时间大于第一个元素的时间(定时时间)
std::shared_ptr<MutexT> invoke_mtx = id->value.mutex();
std::unique_lock<MutexT> invoke_lock(*invoke_mtx, std::defer_lock);
bool locked = invoke_lock.try_lock(); // ABBA
orderedList_.erase(id); // 删除元素
if (locked) { // 加锁成功
lock.unlock();
id->value.invoke(); // 执行 schedule 中注册的函数
lock.lock();
}
continue;
}
std::chrono::milliseconds sleepTime(1);
if (id) { // 队列中还有其他超时元素
std::chrono::milliseconds delta = std::chrono::duration_cast<
std::chrono::milliseconds>(id->key - nowTp);
sleepTime = (std::min)(sleepTime, delta); // 设置休眠时间
} else {
sleepTime = loop_interval(); // 默认的休眠时间 20ms
}
nextCheckAbstime_ = std::chrono::duration_cast<std::chrono::nanoseconds>((now() + sleepTime).time_since_epoch()).count();
cv_.wait_for(lock, sleepTime); // 原子地释放 lock ,阻塞当前线程,并将它添加到等待在 *this 上的线程列表。
// 线程将在执行 notify_all() 或 notify_one() 时,或度过相对时限 rel_time 时被解除阻塞。
}
}本小节内容来自1。
orderedList_ 实际上是一个跳表1,为了方便对超时的任务进行插入删除操作。
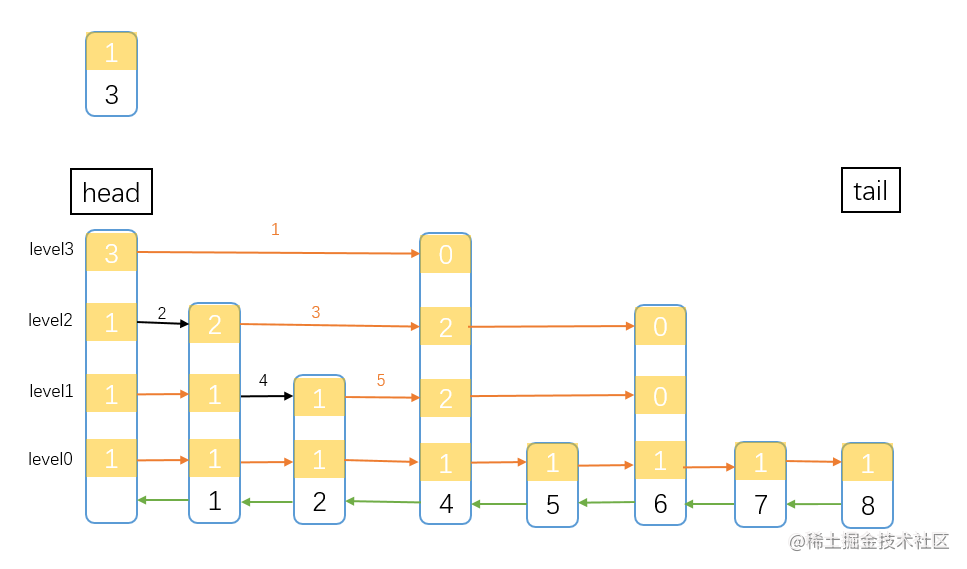
插入元素的第一步就是先查找元素。因为是有序链表,元素都是按序排列的,插入元素前先找到元素应该在的位置。
图中要把score为3的元素插入跳表中,带序号的箭头(指针)是搜索顺序,其中黑色的箭头是实际确定的路径,在搜索过程中,还要记录一下rank,也就是经过所有node的span之和。 先明确一下我们要搜索的结点是哪个。我们要找一个小于3的最大的数(先不考小数和虑链表中有多个3的情况),体现在图中,也就是我们要找到元素2的位置。
搜索前先确定 当前跳表的最高level值。也可以无脑从最上层开始,但是没有意义。图中最高level是4,也就是level3(因为level数组从0开始)。然后从头结点(head)的level层(level3)开始。
先设一个临时指针 t 指向head结点。 先通过图中 1 指针,指向的是元素4,要插入的节点是3,这个明显是大于3的,所以不符合。划重点了 当 现在的node当前层的下一个node不符合条件时,就需要开始搜索下一层 这算是一个转移条件吧。 这时候当前node还是在head,所以从head的level2开始向右搜索。此时node的下一个node是1,1小于3,所以符合条件,所以 t 指针要指向 1 node,再记录一下head的span值。
如此往复,经过 3 4 5 指针的判断,最终来到了node 2 的level0,这时node2的下一个node是大于3的,而此时也是最后一层了,所以node 2 就是小于3 的最大值了,也就是要找的元素。
找到合适的位置,接下来就是把node 3 插入进去了,并把span调整一下。
在确定好要插入的位置后,还要确定node3元素的level高度,这个高度按照理想状态跳表中间的node是最高的,类似一个 山 字型,山字的左半边,再找到中间的node,这个node是次高的,以此类推。但实际上,跳表没有严格执行这种理想状态,node的高度是通过 随机 数确定的,你没看错,就是通过随机数确定。这也就是跳表相对红黑树实现起来简单的原因。
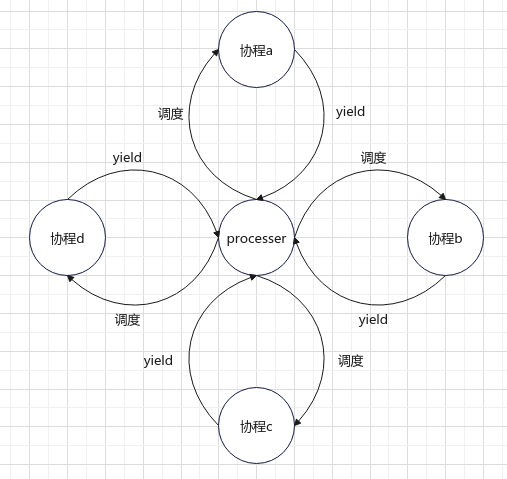
对应一个线程, 负责本线程的协程调度, 非线程安全.
Process 采用的是星切调度(非对称协程调度):
调度线程 -> 协程 A -> 调度线程 -> 协程 B -> 调度线程 -> …
调度线程居中,协程画在周围,调度顺序图看起来就像是星星一样,因此戏称为星切。
将当前可调度的协程组织成先进先出的队列 (runnable list),顺序 pop 出来做调度;新创建的协程排入队尾,调度一次后如果状态依然是可调度 (runnable) 的协程则排入队尾,调度一次后如果状态变为阻塞,那阻塞事件触发后也一样排入队尾,是为公平调度。
Why c++ coroutine?Why libgo?2
协程上下文切换有很多种实现方式:
-
\1. 使用操作系统提供的 api:ucontext、fiber
这种方式是最安全可靠的,但是性能比较差。(切换性能大概在 200 万次 / 秒左右)
-
\2. 使用 setjump、longjump:
代表作:libmill
-
\3. 自己写汇编码实现
这种方式的性能可以很好,但是不同系统、甚至不同版本的 linux 都需要不同的汇编码,兼容性奇差无比,代表作:libco
-
\4. 使用 boost.coroutine
这种方式的性能很好,boost 也帮忙处理了各种平台架构的兼容性问题,缺陷是这东西随着 boost 的升级,并不是向后兼容的,不推荐使用
-
\5. 使用 boost.context
性能、兼容性都是当前最佳的,推荐使用。(切换性能大概在 1.25 亿次 / 秒左右)
libgo 在这一块的方案是 1+5:
- 不愿意依赖 boost 库的用户直接编译即可选择第 1 种方案;
- 追求更佳性能的用户编译时使用 cmake 参数 - DENABLE_BOOST_CONTEXT=ON 即可选择第 5 种方案
每一个processer维护了四个队列:
-
newQueue_队列存放新加入的协程,包括新创建的协程,唤醒挂起的协程,还有 steal 来的协程; -
runnableQueue_:可运行协程队列; -
waitQueue_:存放挂起的协程; -
gcQueue:存放需要gc的协程。
定义如下:
typedef TSQueue<Task, true> TaskQueue; // 线程安全
TaskQueue runnableQueue_;
TaskQueue waitQueue_;
TSQueue<Task, false> gcQueue_; // 非线程安全
TaskQueue newQueue_;其中所有的链表都是双向链表
TSqueue是一个带独立头结点的、支持线程安全(自旋锁)的双端队列,使用双向链表进行组织。
// 线程安全的队列(支持随机删除)
template <typename T, bool ThreadSafe = true>
class TSQueue
{
static_assert((std::is_base_of<TSQueueHook, T>::value), "T must inherit TSQueueHook");
public:
typedef typename std::conditional<ThreadSafe,
LFLock, FakeLock>::type lock_t;
typedef typename std::conditional<ThreadSafe,
std::lock_guard<LFLock>,
fake_lock_guard>::type LockGuard;
lock_t ownerLock_;
lock_t *lock_;
TSQueueHook* head_;
TSQueueHook* tail_;
volatile std::size_t count_;
void *check_; // 可选的erase检测
......
}可以看到,队列的头尾指针是TSQueueHook*类型的,因此在类的最开始,使用断言判定传入的模板类必须是TSQueueHook的子类。
接下来是一个编译期的分支逻辑:
typedef typename std::conditional<ThreadSafe, LFLock, FakeLock>::type lock_t;如果是线程安全的(ThreadSafe == true),采用LFLock,否则采用FakeLock。
从下面的代码可以看出来LFLock使用了自旋锁;FakeLock顾名思义,不执行锁的动作。
struct LFLock
{
std::atomic_flag flag;
LFLock() : flag{false}{}
ALWAYS_INLINE void lock() {
while (flag.test_and_set(std::memory_order_acquire)) ;
}
ALWAYS_INLINE bool try_lock() {
return !flag.test_and_set(std::memory_order_acquire);
}
ALWAYS_INLINE void unlock() {
flag.clear(std::memory_order_release);
}
};
struct FakeLock {
void lock() {}
bool is_lock() { return false; }
bool try_lock() { return true; }
void unlock() {}
};TSQueue还定义了一些队列的常用操作,push、pop单个元素等这里就不详细介绍了;除此之外还支持push、pop多个元素
ALWAYS_INLINE void pushWithoutLock(SList<T> && elements)
{
if (elements.empty()) return ;
assert(elements.head_->prev == nullptr);
assert(elements.tail_->next == nullptr);
TSQueueHook* listHead = elements.head_;
count_ += elements.size();
tail_->link(listHead);
tail_ = elements.tail_;
elements.stealed();
}那么接下来,介绍SList
SList是一个不带独立头节点的双向链表。
template <typename T>
class SList
{
static_assert((std::is_base_of<TSQueueHook, T>::value), "T must inherit TSQueueHook");
public:
// !! 支持边遍历边删除 !!
struct iterator
{
T* ptr;
T* prev;
T* next;
iterator() : ptr(nullptr), prev(nullptr), next(nullptr) {}
iterator(T* p) { reset(p); }
void reset(T* p) {
ptr = p;
next = ptr ? (T*)ptr->next : nullptr;
prev = ptr ? (T*)ptr->prev : nullptr;
}
friend bool operator==(iterator const& lhs, iterator const& rhs)
{ return lhs.ptr == rhs.ptr; }
friend bool operator!=(iterator const& lhs, iterator const& rhs)
{ return !(lhs.ptr == rhs.ptr); }
iterator& operator++() { reset(next); return *this; }
iterator operator++(int) { iterator ret = *this; ++(*this); return ret; }
iterator& operator--() { reset(prev); return *this; }
iterator operator--(int) { iterator ret = *this; --(*this); return ret; }
T& operator*() { return *(T*)ptr; }
T* operator->() { return (T*)ptr; }
};
T* head_;
T* tail_;
std::size_t count_;
...
}同样,链表中的元素必须是TSQueueHook的子类。
定义了iterator实现了一个迭代器。
struct TSQueueHook
{
TSQueueHook* prev = nullptr;
TSQueueHook* next = nullptr;
void *check_ = nullptr;
ALWAYS_INLINE void link(TSQueueHook* theNext) {
assert(next == nullptr);
assert(theNext->prev == nullptr);
next = theNext;
theNext->prev = this;
}
ALWAYS_INLINE void unlink(TSQueueHook* theNext) {
assert(next == theNext);
assert(theNext->prev == this);
next = nullptr;
theNext->prev = nullptr;
}
};Process()函数是一个私有函数,但Scheduler是其友元类,因此scheduler可以调用其中的私有函数。
-
从runnableQueue_队列中取出队首元素,若队列为空,则将
newQueue_队列中的元素取出,加入runnableQueue队首元素为
runningTask_,其为将要运行的协程 -
切换上下文,切换至runningTask_ 进行执行。
直到 runningTask_ 调用 yield ,执行权又回到 processer
-
判断 runningTask_ 的状态:
- 是runnable:取出队列中下一个协程,赋值给 runningTask_
- 是block:
runningTask_ = nextTask_, nextTask_ 会在调用 SuspendBySelf 时进行设置 - 是done或其他:从队列中移出 runningTask_,
runningTask_ = nextTask_
void Processer::Process()
{
GetCurrentProcesser() = this;
while (!scheduler_->IsStop())
{
runnableQueue_.front(runningTask_); // runningTask_ 将要执行的协程
if (!runningTask_) {
if (AddNewTasks()) // 将`newQueue_`队列中的元素取出,加入runnableQueue
runnableQueue_.front(runningTask_);
if (!runningTask_) {
WaitCondition(); // 等待
AddNewTasks(); // 被唤醒后,将`newQueue_`队列中的元素取出,加入runnableQueue
continue;
}
}
addNewQuota_ = 1;
while (runningTask_ && !scheduler_->IsStop()) {
runningTask_->state_ = TaskState::runnable;
runningTask_->proc_ = this;
++switchCount_; // 总的切换次数
runningTask_->SwapIn(); // 上下文切换,执行权给 runningTask_
switch (runningTask_->state_) { // 直到 runningTask_ 调用yield,执行权切回processer
case TaskState::runnable:
{
std::unique_lock<TaskQueue::lock_t> lock(runnableQueue_.LockRef());
auto next = (Task*)runningTask_->next;
if (next) {
runningTask_ = next;
runningTask_->check_ = runnableQueue_.check_;
break;
}
if (addNewQuota_ < 1 || newQueue_.emptyUnsafe()) {
runningTask_ = nullptr;
} else {
lock.unlock();
if (AddNewTasks()) {
runnableQueue_.next(runningTask_, runningTask_);
-- addNewQuota_;
} else {
std::unique_lock<TaskQueue::lock_t> lock2(runnableQueue_.LockRef());
runningTask_ = nullptr;
}
}
}
break;
case TaskState::block:
{
std::unique_lock<TaskQueue::lock_t> lock(runnableQueue_.LockRef());
runningTask_ = nextTask_; // nextTask_ 会在调用 SuspendBySelf 时进行设置
nextTask_ = nullptr;
}
break;
case TaskState::done:
default:
{
runnableQueue_.next(runningTask_, nextTask_); // nextTask_ = runningTask_->next
if (!nextTask_ && addNewQuota_ > 0) {
if (AddNewTasks()) {
runnableQueue_.next(runningTask_, nextTask_);
-- addNewQuota_;
}
}
DebugPrint(dbg_task, "task(%s) done.", runningTask_->DebugInfo());
runnableQueue_.erase(runningTask_); // 移出该 task
if (gcQueue_.size() > 16)
GC();
gcQueue_.push(runningTask_); // 加入gc队列
if (runningTask_->eptr_) { // 错误处理
std::exception_ptr ep = runningTask_->eptr_;
std::rethrow_exception(ep);
}
std::unique_lock<TaskQueue::lock_t> lock(runnableQueue_.LockRef());
runningTask_ = nextTask_; // 设置下一个要执行的task
nextTask_ = nullptr;
}
break;
}
}
}
}#define co_yield do { ::co::Processer::StaticCoYield(); } while (0)
ALWAYS_INLINE void Processer::CoYield()
{
Task *tk = GetCurrentTask();
assert(tk);
++ tk->yieldCount_;
tk->SwapOut(); // 让出执行权,回到processer,进行调度
}通常用户不会使用Suspend(),因为这会导致将协程加入wait队列,但没设置唤醒方式,通常都会使用Suspend(FastSteadyClock::duration dur)将协程加入timer的管理中。
一个不带参数的Suspend最终调用SuspendBySelf
Processer::SuspendEntry Processer::Suspend()
{
Task* tk = GetCurrentTask();
assert(tk);
assert(tk->proc_);
return tk->proc_->SuspendBySelf(tk);
}
Processer::SuspendEntry Processer::SuspendBySelf(Task* tk)
{
assert(tk == runningTask_);
assert(tk->state_ == TaskState::runnable);
tk->state_ = TaskState::block; // 修改状态为block
uint64_t id = ++ TaskRefSuspendId(tk);
std::unique_lock<TaskQueue::lock_t> lock(runnableQueue_.LockRef());
runnableQueue_.nextWithoutLock(runningTask_, nextTask_); // 设定 nextTask_ 的task
runnableQueue_.eraseWithoutLock(runningTask_, false, false); // 从runnableQueue_ 队列中移出
DebugPrint(dbg_suspend, "tk(%s) Suspend. nextTask(%s)", tk->DebugInfo(), nextTask_->DebugInfo());
waitQueue_.pushWithoutLock(runningTask_, false); // 加入 waitQueue_
return SuspendEntry{ WeakPtr<Task>(tk), id };
}Processer::SuspendEntry Processer::Suspend(FastSteadyClock::duration dur)
{
FastSteadyClock::time_point tp = FastSteadyClock::now();
tp += dur;
return Suspend(tp);
}
Processer::SuspendEntry Processer::Suspend(FastSteadyClock::time_point timepoint)
{
SuspendEntry entry = Suspend(); // 执行SuspendBySelf,将本身放入wait队列
Task* tk = GetCurrentTask();
if (tk->isInTimer_) {
tk->schedTimer_->join_unschedule(tk->suspendTimerId_);
tk->schedTimer_ = nullptr;
} else {
tk->isInTimer_ = true;
}
tk->schedTimer_ = &GetCurrentScheduler()->GetTimer();
// 加入timer线程管理的跳表中
tk->schedTimer_->schedule(tk->suspendTimerId_, timepoint,
[entry, tk]() mutable { // 声明捕获的两个外部参数在匿名函数中是需要做修改的
Processer::Wakeup(entry, [tk]{ // 回掉函数,会在 timer.run 中执行,详见 timer 一节
tk->isInTimer_ = false;
tk->schedTimer_ = nullptr;
});
});
return entry;
}/**
* @brief 优先从newQueue_ 中steal一定数量的task,若不够则从runningTask_中获取
* 分两种情况:1. n > 0 则从当前p中steal n个task
* 2. n <=0 则从当前p中steal 全部task,需要注意的是,虽是全部,但不包括 runningTask_ 和 nextTask_
*
* @param n
* @return SList<Task>
*/
SList<Task> Processer::Steal(std::size_t n)这个函数写的有些冗余。TODO
与processer不同,dispatcher并没有定义一个类对其进行描述,而是直接在Scheduler类中定义了一个函数对其进行管理。
dispatcher是一个线程,线程的创建由Scheduler::DispatcherThread()完成。
该线程是一个死循环,只要当前的Scheduler没有停止(即stop_标志为0)该线程就会一直执行下去。循环中的工作为:
-
使用
this_thread::sleep_for()定义线程的执行频率 -
遍历
processer,判定状态,将阻塞状态的p加入blockings进行管理
-
遍历
processer- 获取当前p的负载(可运行的协程数量),总体负载累加当前负载
- 将处于等待状态的p唤醒(active_置为1)
- 将
active_=1的p加入actives进行管理,activeTasks (活动的协程数量)累加当前负载 - 唤醒处于等待状态但是有任务的P
-
如果
actives数量为0,即所有的p都处于阻塞状态,如果当前
processer的数量小于max,则启动一个新的processer -
如果
actives数量仍为0,即全部阻塞并且不能起新线程, 无需调度, 等待即可。continue -
处理阻塞的P,DispatchBlocks
-
负载均衡,LoadBalance
void Scheduler::DispatcherThread()
{
DebugPrint(dbg_scheduler, "---> Start DispatcherThread");
while (!stop_) {
// TODO: 用condition_variable降低cpu使用率
std::this_thread::sleep_for(std::chrono::microseconds(CoroutineOptions::getInstance().dispatcher_thread_cycle_us));
// 1.收集负载值, 收集阻塞状态, 打阻塞标记, 唤醒处于等待状态但是有任务的P
idx_t pcount = processers_.size();
std::size_t totalLoadaverage = 0;
ActiveMap actives;
BlockMap blockings;
int isActiveCount = 0;
for (std::size_t i = 0; i < pcount; i++) {
auto p = processers_[i];
//等待中的p不能算阻塞,无法加入新协程导致p饿死
if (!p->IsWaiting() && p->IsBlocking()) {
blockings[i] = p->RunnableSize();
if (p->active_) {
p->active_ = false;
DebugPrint(dbg_scheduler, "Block processer(%d)", (int)i);
}
}
if (p->active_)
isActiveCount++;
}
// 还可激活几个P
int activeQuota = isActiveCount < minThreadNumber_ ? (minThreadNumber_ - isActiveCount) : 0;
std::size_t activeTasks = 0;
for (std::size_t i = 0; i < pcount; i++) {
auto p = processers_[i];
std::size_t loadaverage = p->RunnableSize();
totalLoadaverage += loadaverage;
if (!p->active_) {
//处于等待中的p也应该唤醒
if (activeQuota > 0 && (!p->IsBlocking() || p->IsWaiting())) {
p->active_ = true;
activeQuota--;
DebugPrint(dbg_scheduler, "Active processer(%d)", (int)i);
lastActive_ = i;
}
}
if (p->active_) {
actives.insert(ActiveMap::value_type{loadaverage, i});
activeTasks += p->RunnableSize();
p->Mark();
}
if (loadaverage > 0 && p->IsWaiting()) {
p->NotifyCondition();
}
}
if (actives.empty() && (int)pcount < maxThreadNumber_) {
// 全部阻塞, 并且还有协程待执行, 起新线程
NewProcessThread();
actives.insert(ActiveMap::value_type{0, pcount});
++pcount;
}
// 全部阻塞并且不能起新线程, 无需调度, 等待即可
if (actives.empty())
continue;
DispatchBlocks(blockings,actives);
LoadBalance(actives,activeTasks);
}
}将阻塞p的协程都steal出来,并添加到未阻塞的p中。
在执行该动作时,也尝试进行了负载均衡,但是此处的逻辑不太正确,计算方式取决于第一个p的协程数量,而且紧跟着就是负载均衡函数,有些冗余。 TODO
TODO
void Scheduler::LoadBalance(Scheduler::ActiveMap &actives, std::size_t activeTasks)
{
std::size_t avg = activeTasks / actives.size();
if (actives.begin()->first > avg * CoroutineOptions::getInstance().load_balance_rate)
return;
SList<Task> tasks;
for (auto it = actives.rbegin(); it != actives.rend(); ++it)
{
if (it->first <= avg) // 这里应该也是有问题的,TODO 一旦有一个p的负载小于均值则后面的被忽略,不能完全均衡
break;
auto p = processers_[it->second];
SList<Task> in = p->Steal(it->first - avg);
tasks.append(std::move(in));
}
if (tasks.empty())
return;
for (auto &kv : actives)
{
if (kv.first >= avg) //一旦有一个p的负载大于均值,后面的p都的不到均衡 TODO
break;
auto p = processers_[kv.second];
auto in = tasks.cut(avg - kv.first);
p->AddTask(std::move(in));
}
// 如果还剩下task,全都给最小的p
if (!tasks.empty())
{
auto p = processers_[actives.begin()->second];
p->AddTask(std::move(tasks));
}
}Task是协程的数据结构
struct Task
: public TSQueueHook, public SharedRefObject, public CoDebugger::DebuggerBase<Task>
{
TaskState state_ = TaskState::runnable; // 创建时的状态为 runnnable
uint64_t id_;
Processer* proc_ = nullptr; // 从属于哪个 processer
Context ctx_; // 上下文
TaskF fn_; // 协程要执行的函数
std::exception_ptr eptr_; // 保存exception的指针
TaskAnys anys_;
void* extern_switcher_ {nullptr};
// 加入timer所需的成员
::libgo::RoutineSyncTimer::TimerId suspendTimerId_;
::libgo::RoutineSyncTimer* schedTimer_ = nullptr;
bool isInTimer_ {false};
uint64_t yieldCount_ = 0; // 协程切换的次数
atomic_t<uint64_t> suspendId_ {0};
Task(TaskF const& fn, std::size_t stack_size);
~Task();
// 上下文切换
ALWAYS_INLINE void SwapIn()
{
ctx_.SwapIn();
}
ALWAYS_INLINE void SwapOut()
{
ctx_.SwapOut();
}
const char* DebugInfo();
private:
void Run();
static void FCONTEXT_CALL StaticRun(intptr_t vp);
Task(Task const&) = delete;
Task(Task &&) = delete;
Task& operator=(Task const&) = delete;
Task& operator=(Task &&) = delete;
};协程的状态有三种,分别是可运行、阻塞、运行结束:
enum class TaskState
{
runnable,
block,
done,
};接下来,结合协程创建运行和processer管理的4个队列,对协程的状态进行说明。
在libgo中,使用关键字 go来启动一个协程
#define go_alias ::co::__go(__FILE__, __LINE__)-
#define go go_alias
template <typename Function>
ALWAYS_INLINE void operator-(Function const& f)
{
if (!scheduler_) scheduler_ = Processer::GetCurrentScheduler();
if (!scheduler_) scheduler_ = &Scheduler::getInstance();
scheduler_->CreateTask(f, opt_);
}实际上使用scheduler_->CreateTask,对协程进行创建并把协程加入new队列中
void Scheduler::CreateTask(TaskF const &fn, TaskOpt const &opt)
{
Task *tk = new Task(fn, opt.stack_size_ ? opt.stack_size_ :CoroutineOptions::getInstance().stack_size);
tk->SetDeleter(Deleter(&Scheduler::DeleteTask, this));
tk->id_ = ++GetTaskIdFactory(); // 获取协程id
TaskRefAffinity(tk) = opt.affinity_;
TaskRefLocation(tk).Init(opt.file_, opt.lineno_);
++taskCount_;
AddTask(tk); // 将新创建的task加入new队列,等待调度
}
-
使用go关键字时,会创建一个新的协程,加入
new队列中。(从其他P中steal来的协程也会加入new队列)。状态runnable。 -
processer线程运行会执行Process()函数,对协程进行调度,当发现
runnable队列为空时会将new队列中的task移动到runnable队列,并按照队列顺序执行task。 -
Steal会从一个P的
new或runnable队列中偷取一些或全部的task到另一个P的new队列中。状态runnable -> runnable。 -
task执行中途放弃CPU有两种情况:
-
调用yield让出CPU,yield只负责上下文的切换。不改变队列和状态。
-
由于调用hook的系统调用或调用Suspend(timeout)函数,造成本身阻塞,task移动到
wait队列。状态runnable -> block注意:
- 调用Suspend(timeout)函数,同时也会在timer队列中加入一个元素,使得超时时会被唤醒。
- 调用Suspend函数,仅仅是将task移动到wait队列,但不负责上下文切换,切换由yield负责。
-
-
通过wakeup函数(程序员手动调用、超时或条件达成)可以将一个协程唤醒,唤醒实际上是将协程从
wait队列移动到new队列中。状态block -> runnable。 -
运行完毕的协程会从
runnable队列中删除,加入gc队列。状态runnable -> done。gc相关内容详见gc.md。
| 时机 | 队列 | 状态 |
|---|---|---|
| 创建协程 (go function) | newQueue_ | runnable |
| Process() | newQueue_ -> runnable | runnable -> runnable |
| Steal | 从一个P的new或runnable -> 另一个P的new | runnable -> runnable |
| yield | 不改变队列 | runnable -> runnable |
| Suspend | runnable -> wait | runnable -> block |
| wakeup | wait -> runnable | block -> runnable |
| 运行完毕 | runnable -> gc | runnable -> done |
Suspend(timeout),会在timer维护的跳表中加入一个元素。加timer队列。
Why c++ coroutine?Why libgo?2
我们通常会创建数量非常庞大的协程来支持高并发,协程栈内存占用情况就变成一个不容忽视的问题了;
如果采用线程栈相同的大栈方案(linux 系统默认 8MB),启动 1000 个协程就要 8GB 内存,启动 10w 个协程就要 800GB 内存,而每个协程真正使用的栈内存可以几百 kb 甚至几 kb,内存使用率极低,这显然是不可接受的;
如果采用减少协程栈的大小,比如设为 128kb,启动 1000 个协程要 128MB 内存,启动 10w 个协程要 12.8GB 内存,这是一个合理的设置;但是,我们知道有很多人喜欢直接在栈上申请一个 64kb 的 char 数组做缓冲区,即使开发者非常小心的不这样奢侈的使用栈内存,也难免第三方库做这样的行为,而只需两层嵌套就会栈溢出了。
栈内存不可太大,也不可太小,这其中是很难权衡的,一旦定死这个值,就只能针对特定的场景,无法做到通用化了; 针对协程栈的内存问题,一般有以下几种方案。
固定大小的栈,存在上述的难以权衡的问题;
但是如果把问题限定在某一个范围,比如说我就只用来写微信后台、并且严格 review 每一个引入的第三方库的源码,确保其全部谨慎使用栈内存,这种方案也是可以作为实际项目来使用的。
典型代表:libco,它设置了 128KB 大小的堆栈,15 年的时候我们把它引入我们当时的项目中,其后出现过多次栈溢出的问题。
gcc 提供的 “黄金链接器” 支持一种允许栈内存不连续的编译参数,实现原理是在每个函数调用开头都插入一段栈内存检测的代码,如果栈内存不够用了就申请一块新的内存,作为栈内存的延续。
这种方案本应是最佳的实现,但如果遇到的第三方库没有使用这种方式来编译 (注意:glibc 也是这里提到的” 第三方库 "),那就无法在其中检测栈内存是否需要扩展,栈溢出的风险很大。
每次检测到栈内存不够用时,申请一块更大的新内存,将现有的栈内存 copy 过去,就像 std::vector 那样扩展内存。
在某些语言上是可以实现这样的机制,但 C++ 是有指针的,栈内存的 Copy 会导致指向其内存地址的指针失效;又因为其指针的灵活性 (可以加减运算),修改对应的指针成为了一种几乎不可能实现的事情 (参照 c++ 为什么没办法实现 gc 原理,详见《C++11 新特性解析与应用》第 5 章 5.2.4 节)。
申请一块大内存作为共享栈 (比如:8MB),每次开始运行协程之前,先把协程栈的内存 copy 到共享栈中,运行结束后再计算协程栈真正使用的内存,copy 出来保存起来,这样每次只需保存真正使用到的栈内存量即可。
这种方案极大程度上避免了内存的浪费,做到了用多少占多少,同等内存条件下,可以启动的协程数量更多,
libco使用这种方案单机启动了上千万协程。但是这种方案的缺陷也同样明显:
- \1. 协程切换慢:每次协程切换,都需要 2 次 Copy 协程栈内存,这个内存量基本上都在 1KB 以上,通常是几十 kb 甚至几百 kb,这样的 2 次 Copy 要花费很长的时间。
- \2. 栈上引用失效导致隐蔽的 bug:例如下面的代码
#include <iostream> #include <libgo/libgo.h> using namespace std; struct A { explicit A(int v) : val_(v) {} void foo() { cout << val_ << endl; } int val_; }; void bar() { A a(100); co_chan<void*> wait; go [&]{ a.foo(); wait << nullptr; }; wait >> nullptr; } int main() { go bar; co_sched.RunUntilNoTask(); }bar 这个协程函数里面,启动了一个新的协程,然后 bar 等待新协程结束后再退出;当切换到新协程时,由于 bar 协程的栈已经被 copy 到了其他位置,栈上分配的变量 a 已经失效,此时调用 a.foo 就会出现难以预料的结果。
这样的场景在开发中数不胜数,比如:某个处理流程需要聚合多个后端的结果、父协程对子协程做一些计数类的操作等等等等
有人说我可以把变量 a 分配到堆上,这样的改法确实可以解决这个已经发现的 bug;那其他没发现的怎么办呢,难道每个变量都放到堆上以提前规避这个坑?这显然是不切实际的。
早期的 libgo 也使用过共享栈的方式,也正是因为作者在实际开发中遇到了这样的问题,才放弃了共享栈的方式。
既然前面提到的 4 种协程栈都有这样那样的弊端,那么有没有一种方案能够相对完美的解决这个问题?答案就是虚拟内存栈。
Linux、Windows、MacOS 三大主流操作系统都有这样一个虚拟内存机制:进程申请的内存并不会立即被映射成物理内存,而是仅管理于虚拟内存中,真正对其读写时会触发缺页中断,此时才会映射为物理内存。
比如:我在进程中 malloc 了 1MB 的内存,但是不做读写,那么物理内存占用是不会增加的;当我读写这块内存的第一个字节时,系统才会将这 1MB 内存中的第一页 (默认页大小 4KB) 映射为物理内存,此时物理内存的占用会增加 4KB,以此类推,可以做到用多少占多少,冗余不超过一个内存页大小。
基于这样一个机制,libgo 为每个协程 malloc 1MB 的虚拟内存作为协程栈 (这个值是可以定制化的);不做读写操作就不会占用物理内存,协程栈使用了多少才会占用多少物理内存,实现了与共享栈近似的内存使用率,并且不存在共享栈的两大弊端。
典型代表:
libgo
Why c++ coroutine?Why libgo?2
libgo 的 HOOK 设计与实现严格的遵守着 HOOK 的基本守则,在 linux 系统上 hook 的 socket 函数列表如下:
connect、accept read、readv、recv、recvfrom、recvmsg write、writev、send、sendto、sendmsg poll、select、__poll、close
fcntl、ioctl、getsockopt、setsockopt dup、dup2、dup3
协程挂起:
如果协程对一个或多个 socket 的 IO 阻塞操作 (read/write/poll/select) 无法立即完成,那么协程会被设置为 io-block 状态并保存到 io-wait 队列中,将当期协程的 sentry 保存在 socket 的等待队列中,然后将这一个或多个 socket 添加到当前线程所属的 epoll 中;
协程唤醒:
如果这一个或多个 socket 被 epoll 监听到协程关心的事件触发了,对应的协程就会被唤醒 (设置成 runnable 状态),并追加到所属 P 的 IO 触发队列尾部,等待再次被调度。
唤醒后的清理:
协程被唤醒后的首次调度,会从 socket 的等待队列中清除当期协程的 sentry,如果 socket 读写事件对应的等待队列被清空且没有设置为 ET 模式,则会调用 epoll_ctl 清理 epoll 对 socket 的对应监听事件。
显而易见,调用 void set_et_mode (int fd); 接口将频繁读写的 socket 设置成 et 模式可以减少 epoll 相关的系统调用,提升性能;libgonet 就做了这样的优化。
inline int libgo_poll(struct pollfd *fds, nfds_t nfds, int timeout, bool nonblocking_check)
{
Task* tk = Processer::GetCurrentTask();
if (!tk)
return poll_f(fds, nfds, timeout);
if (timeout == 0)
return poll_f(fds, nfds, timeout);
// (1.没有协程;2.timeout=0)两种情况,直接调用原生的poll系统调用
// 全部是负数fd时, 等价于sleep
nfds_t negative_fd_n = 0;
for (nfds_t i = 0; i < nfds; ++i)
if (fds[i].fd < 0)
++ negative_fd_n;
if (nfds == negative_fd_n) {
// co sleep
if (timeout > 0) { // 将本身协程加入wait队列,让出CPU
Processer::Suspend(std::chrono::milliseconds(timeout));
Processer::StaticCoYield();
}
return 0;
}
// --------------------------------
if (nonblocking_check) {
// 执行一次非阻塞的poll, 检测异常或无效fd.
int res = poll_f(fds, nfds, 0);
if (res != 0) {
return res;
}
}
short int *arrRevents = new short int[nfds];
memset(arrRevents, 0, sizeof(short int) * nfds);
std::shared_ptr<short int> revents(arrRevents, [](short int* p){ delete[] p; }); // 引用计数
Processer::SuspendEntry entry;
if (timeout > 0)
entry = Processer::Suspend(std::chrono::milliseconds(timeout));
else
entry = Processer::Suspend();
// add file descriptor into epoll or poll.
// 从代码上看是加入了poll中,为什么?TODO
bool added = false;
for (nfds_t i = 0; i < nfds; ++i) {
pollfd & pfd = fds[i];
pfd.revents = 0; // clear revents
if (pfd.fd < 0)
continue;
// 不太懂
if (!Reactor::Select(pfd.fd).Add(pfd.fd, pfd.events, Reactor::Entry(entry, revents, i))) {
// bad file descriptor
arrRevents[i] = POLLNVAL;
continue;
}
added = true;
}
// 这里不太懂 TODO
if (!added) {
// 全部fd都无法加入epoll
for (nfds_t i = 0; i < nfds; ++i)
fds[i].revents = arrRevents[i];
errno = 0;
Processer::Wakeup(entry); // 从wait队列取出,加入runnable队列
Processer::StaticCoYield(); // 让出CPU
return nfds;
}
Processer::StaticCoYield();
// 再次得到调度时,应该是poll的时间被触发或超时
int n = 0;
for (nfds_t i = 0; i < nfds; ++i) {
fds[i].revents = arrRevents[i];
if (fds[i].revents) ++n;
}
errno = 0;
return n;
}