1 libgo使用
mkdir build
cd build
cmake ..
make
make debug # Skip it if you don`t want a debuggable versions.
make install # 如果需要安装的话cmake .. -DENABLE_DEBUGGER=ON # 开启调试模式如果想在程序中打印出特定的调试信息,则还需要在程序中对co_opt.debug进行设置,如下:
co_opt.debug = co::dbg_scheduler;
// debug 类型定义在 commom/config.h 中cd tutorial
mkdir build
cd build
cmake ..
make可能遇到的错误
CMake Error at /usr/lib/x86_64-linux-gnu/cmake/Boost-1.71.0/BoostConfig.cmake:117 (find_package):
Found package configuration file:
/usr/lib/x86_64-linux-gnu/cmake/boost_thread-1.71.0/boost_thread-config.cmake
but it set boost_thread_FOUND to FALSE so package "boost_thread" is
considered to be NOT FOUND. Reason given by package:
No suitable build variant has been found.
The following variants have been tried and rejected:
* libboost_thread.so.1.71.0 (shared, Boost_USE_STATIC_LIBS=ON)
* libboost_thread.a (shared runtime, Boost_USE_STATIC_RUNTIME=ON)
Call Stack (most recent call first):
/usr/lib/x86_64-linux-gnu/cmake/Boost-1.71.0/BoostConfig.cmake:182 (boost_find_component)
/usr/share/cmake-3.16/Modules/FindBoost.cmake:443 (find_package)
boost.cmake:7 (find_package)
CMakeLists.txt:38 (include)
-- Configuring incomplete, errors occurred!
See also "/home/zcl/workspace/worktask/2022/12yue/Coroutine-code/libgo/tutorial/build/CMakeFiles/CMakeOutput.log".
首先定位到系统中boost_thread的位置
$ locate boost_thread
/usr/lib/x86_64-linux-gnu/libboost_thread.a
/usr/lib/x86_64-linux-gnu/libboost_thread.so
/usr/lib/x86_64-linux-gnu/libboost_thread.so.1.58.0
/usr/local/MATLAB/R2017a/bin/glnxa64/libboost_thread.so.1.56.0修改方式:修改当前文件夹下的CmakeList.txt,根据上面的位置添加
set(BOOST_LIBRARYDIR /usr/lib)
find_package(Boost REQUIRED COMPONENTS thread)示例代码位于tutorial/sample1_go.cpp
使用关键字go可以创建协程,go的用法有以下几种:
1. void(*)()函数指针, 比如:foo.
2. 也可以使用无参数的lambda, std::bind对象, function对象,
3. 以及一切可以无参调用的仿函数对象目前看来,libgo是不支持直接使用带参数的函数的,需要使用bind将函数和参数进行绑定
用法1:
void foo()
{
printf("function pointer\n");
}
go foo;用法2:
std::bind 用来将可调用对象与其参数一起进行绑定。绑定后的结果可以使用 std::function进行保存,并延迟调用到任何我们需要的时候。bind函数接受一个可调用对象,生成一个新的可调用对象来适配原对象。
通俗来讲,它主要有两大作用:
1)将可调用对象与其参数一起绑定成一个仿函数。
2)将多元(参数个数为 n, n>1)可调用对象转成一元或者( n-1)元可调用对象,即只绑定部分参数。
// 1. 无参lambda
go []{
printf("lambda\n");
};
---------------------------------
// 2. bind
// 绑定参数
void fooint(int a)
{
printf("int a = %d\n", a);
printf("function pointer\n");
}
go std::bind(fooint, 3);
// bind其他用法
struct A {
void fA() { printf("std::bind\n"); }
void fB() { printf("std::function\n"); }
};
go std::bind(&A::fA, A()); // 将A的成员函数fA和函数A()绑定返回一个可调用对象,接下来的调用相当于 go A;
---------------------------------
// 3. std::function
// std::function将不同类型的可调用对象共享同一种调用形式。
std::function<void()> fn(std::bind(&A::fB, A()));
go fn;指定协程栈大小
// 也可以使用go_stack创建指定栈大小的协程
// 创建拥有10MB大栈的协程
go co_stack(10 * 1024 * 1024) []{
printf("large stack\n");
};
go co_stack(10 * 1024 * 1024) foo;- 协程创建以后不会立即执行,而是暂存至可执行列表中,等待调度器调度。
- co_sched是默认的协程调度器,用户也可以使用自创建的协程调度器。
- 当仅使用一个线程进行协程调度时, 协程的执行会严格地遵循其创建顺序.
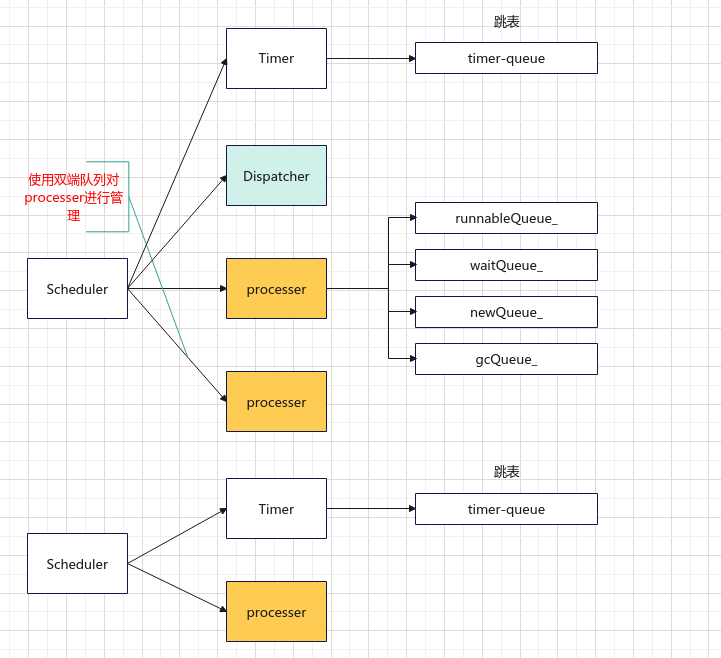
libgo中负责调度的有三个角色,分别是Scheduler,Dispatcher和processer,其中:
-
Scheduler负责管理Dispatcher和processer,libgo会提供一个默认的Scheduler名为co_sched,也可以通过Scheduler::Create()创建新的调度器。==协程只会在所属的调度器中被调度, 创建额外的调度器可以实现业务间的隔离.== -
processer负责协程的调度,每一个processer维护了四个队列,-
newQueue_队列存放新加入的协程,包括新创建的协程,唤醒挂起的协程,还有 steal 来的协程; -
runnableQueue_:可运行协程队列; -
waitQueue_:存放挂起的协程; -
gcQueue:存放需要gc的协程。
-
-
Dispatcher负责不同processer上的协程的负载均衡,实现协程的跨线程迁移Steal,增加新的processer等。==只有在processer数量大于1的时候才会创建Dispatcher线程。==
注:
Scheduler使用双端队列对processer进行管理调用Processer::Process()时会检查
runnableQueue_是否为空,若为空,把newQueue_中的task放入runnableQueue_
示例代码位于tutorial/sample1_go.cpp
函数原型为:
Scheduler::
void Start(int minThreadNumber = 1, int maxThreadNumber = 0);函数有两个默认参数,默认情况下,将开启一个调度线程
co_sched是默认的调度器,直接在主线程中调用
co_sched.Start();开启协程的调度,但需要注意的是,这样调用后会使主线程卡在调度上,调度程序是一个死循环
如果不想让调度器卡住,可以使用下面的方法:
// 另开启一个线程进行调度
std::thread t([]{ co_sched.Start(); });
t.detach();通过设置minThreadNumber和maxThreadNumber两个参数,对调度器个数进行控制:
1. 如果 minThreadNumber < 1,则设置minThreadNumber为系统硬件线程数
2. 如果 maxThreadNumber = 0或者 maxThreadNumber < minThreadNumber,则设置 maxThreadNumber = minThreadNumber根据minThreadNumber创建执行器
for (int i = 0; i < minThreadNumber_ - 1; i++) {
NewProcessThread();
}如果maxThreadNumber > 1开启DispatcherThread负责其他线程中协程的负载控制,代码为:
if (maxThreadNumber_ > 1) {
DebugPrint(dbg_scheduler, "---> Create DispatcherThread");
std::thread t([this]{
DebugPrint(dbg_thread, "Start dispatcher(sched=%p) thread id: %lu", (void*)this, NativeThreadID());
this->DispatcherThread(); // 负载控制函数
});
dispatchThread_.swap(t);
}// 除了上述的使用默认的调度器外, 还可以自行创建额外的调度器,
// 协程只会在所属的调度器中被调度, 创建额外的调度器可以实现业务间的隔离.
// 创建一个调度器
co::Scheduler* sched = co::Scheduler::Create();
// 启动4个线程执行新创建的调度器
std::thread t2([sched]{ sched->Start(4); });
t2.detach();
// 在新创建的调度器上创建一个协程
go co_scheduler(sched) []{
printf("run in my scheduler.\n");
};示例代码位于tutorial/sample2_yield.cpp
libgo定义了一个关键字co_yield用于协程主动让出执行权
#define co_yield do { ::co::Processer::StaticCoYield(); } while (0)
ALWAYS_INLINE void Processer::StaticCoYield()
{
auto proc = GetCurrentProcesser();
if (proc) proc->CoYield();
}
ALWAYS_INLINE void Processer::CoYield()
{
Task *tk = GetCurrentTask();
assert(tk);
++ tk->yieldCount_;
tk->SwapOut(); // 实际执行让出CPU的函数
}在协程中使用co_yield关键字, 可以主动让出调度器执行权限,让调度器有机会去执行其他协程,并将当前协程移动到可执行协程列表的尾部。类似于操作系统提供的sleep(0)的功能。
go []{
printf("1\n");
co_yield;
printf("2\n");
};示例代码位于tutorial/sample3_channel.cpp
// Channel也是一个模板类,
// 使用以下代码将创建一个无缓冲区的、用于传递整数的Channel:
co_chan<int> ch_0;
// channel是引用语义, 在协程间共享直接copy即可.
go [=]{
// 在协程中, 向ch_0写入一个整数1.
// 由于ch_0没有缓冲区, 因此会阻塞当前协程, 直到有人从ch_0中读取数据:
ch_0 << 1;
};
go [=] {
// Channel是引用计数的, 复制Channel并不会产生新的Channel, 只会引用旧的Channel.
// 因此, 创建协程时可以直接拷贝Channel.
// Channel是mutable的, 因此可以直接使用const Channel读写数据,
// 这在使用lambda表达式时是极为方便的特性.
// 从ch_0中读取数据:
int i;
ch_0 >> i;
printf("i = %d\n", i);
};// 创建缓冲区容量为1的Channel, 传递智能指针:
co_chan<std::shared_ptr<int>> ch_1(1);
go [=] {
std::shared_ptr<int> p1(new int(1));
// 向ch_1中写入一个数据, 由于ch_1有一个缓冲区空位, 因此可以直接写入而不会阻塞当前协程.
ch_1 << p1;
// 再次向ch_1中写入整数2, 由于ch_1缓冲区已满, 因此阻塞当前协程, 等待缓冲区出现空位.
ch_1 << p1;
};
go [=] {
std::shared_ptr<int> ptr;
// 由于ch_1在执行前一个协程时被写入了一个元素, 因此下面这个读取数据的操作会立即完成.
ch_1 >> ptr;
// 由于ch_1缓冲区已空, 下面这个操作会使当前协程放弃执行权, 等待第一个协程写入数据完成.
ch_1 >> ptr;
printf("*ptr = %d\n", *ptr);
};前面两种对channel的使用方式都是无限期等待的,Channel还支持带超时的等待机制, 和非阻塞的模式
co_chan<int> ch_2;
go [=] {
// 使用TryPop和TryPush接口, 可以立即返回无需等待.
// 当Channel为空时, TryPop会失败; 当Channel写满时, TryPush会失败.
// 如果操作成功, 返回true, 否则返回false.
int val = 0;
bool isSuccess = ch_2.TryPop(val);
// 使用TimedPop和TimedPush接口, 可以在第二个参数设置等待的超时时间
// 如果超时, 返回false, 否则返回true.
// 注意:当前版本, 原生线程中使用Channel时不支持超时时间, 退化为无限期等待.
isSuccess = ch_2.TimedPush(1, std::chrono::microseconds(100));
(void)isSuccess;
}; /*********************** 4. 多读多写\线程安全 ************************/
// Channel可以同时由多个线程读写.
// Channel是线程安全的, 因此不必担心在多线程调度协程时会出现问题.
/*********************** 5. 跨越多个调度器 ************************/
// Channel可以自由地使用, 不必关心操作它的协程是属于哪个调度器的.
/*********************** 6. 兼容原生线程 ************************/
// Channel不仅可以用于协程中, 还可以用于原生线程.* libgo库原生提供了一个线程安全的定时器
* 还提供了休眠当前协程的方法co_sleep,类似于系统调用sleep, 不过时间单位是毫秒.
* 同时HOOK了系统调用sleep、usleep、nanosleep, 在协程中使用这几个系统调用, 会在等待期间让出cpu控制权, 执行其他协程, 不会阻塞调度线程.
int main()
{
// 创建一个定时器
// 第一个参数: 精度
// 第二个参数: 绑定到一个调度器(Scheduler)
// 两个参数都有默认值, 可以简便地创建一个定时器: co_timer timer;
co_timer timer(std::chrono::milliseconds(1), &co_sched);
// 使用timer.ExpireAt接口设置一个定时任务
// 第一个参数可以是std::chrono中的时间长度,也可以是时间点。
// 第二个参数是定时器回调函数
// 返回一个co_timer_id类型的ID, 通过这个ID可以撤销还未执行的定时函数
co_timer_id id1 = timer.ExpireAt(std::chrono::seconds(1), []{
printf("Timer Callback.\n");
});
// co_timer_id::StopTimer接口可以撤销还未开始执行的定时函数
// 它返回bool类型的结果,如果撤销成功,返回true;
// 如果未来得及撤销,返回false, 此时不保证回调函数已执行完毕。
bool cancelled = id1.StopTimer();
printf("cancelled:%s\n", cancelled ? "true" : "false");
timer.ExpireAt(std::chrono::seconds(2), [&]{
printf("Timer Callback.\n");
co_sched.Stop();
});
for (int i = 0; i < 100; ++i)
go []{
// 休眠当前协程 1000 milliseconds.
// 不会阻塞线程, 因此100个并发的休眠, 总共只需要1秒.
co_sleep(1000);
};
co_sched.Start();
return 0;
}计算密集型任务的思路是多开几个线程,做负载均衡。
const int nWork = 100;
// 大计算量的函数
int c = 0;
std::atomic<int> done{0};
void foo()
{
int v = (int)rand();
for (int i = 1; i < 20000000; ++i) {
v *= i;
}
c += v;
if (++done == nWork * 2)
co_sched.Stop();
}
int main()
{
// 编写cpu密集型程序时, 可以延长协程执行的超时判断阈值, 避免频繁的worksteal产生
co_opt.cycle_timeout_us = 1000 * 1000;
// 普通的for循环做法
auto start = system_clock::now();
for (int i = 0; i < nWork; ++i)
foo();
auto end = system_clock::now();
cout << "for-loop, cost ";
cout << duration_cast<milliseconds>(end - start).count() << "ms" << endl;
// 使用libgo做并行计算
start = system_clock::now();
for (int i = 0; i < nWork; ++i)
go foo;
// 创建8个线程去并行执行所有协程 (由worksteal算法自动做负载均衡)
co_sched.Start(8);
end = system_clock::now();
cout << "go with coroutine, cost ";
cout << duration_cast<milliseconds>(end - start).count() << "ms" << endl;
cout << "result zero:" << c * 0 << endl;
return 0;
}