本项目严禁售卖,只供学习娱乐使用。请于24小时内删除。使用本项目所产生的任何后果由使用者自行承担。在使用本项目之前,请确保您已充分了解相关法律法规,并确保您的行为符合所在国家或地区的法律要求。未经授权的情况下,请勿将本项目用于商业用途或其他非法用途。转载使用请标明出处。
目前冲榜 刷排名都已是最优思路
2024-10-15 20:15 协议刷题(可以做到不打开页面自动刷胜场)
来自 xmexg/xyks#35 可以直接去看他这个,注意这个方式需要手动的部分有些多。有一定的技术含量。
之后是他这个main.py运行的时候多线程我有时候会有一些莫名其妙的问题,所以我稍微改了一下,其他的js之类的我都没做修改。如果你用他这个没有问题当然用他这个就可以了(一般情况下是都没问题的)。
我这个是加上了一个自选题数。
之后说需要修改的地方,首先是俩个url
matchV2_url和upAnswer_url 这俩个需要修改成你自己的。
cookie里面的YFD_U ks_persistent userid需要修改成你自己的。(这里用到他那里的get_cookie的py脚本)
脚本成功的话结果应该是这个样子
 如果说获取到试题未解密大概长度是73的。就是matchV2_url和upAnswer_url 没有修改好。
如果说获取到试题未解密大概长度是73的。就是matchV2_url和upAnswer_url 没有修改好。
import base64
import gzip
import time
import requests
import json
import threading
from hook.gan_sign.gan_sign_model import FridaSignExtractor # 用于生成sign
from hook.matchV2_byDataDecryptCommand.do_matchV2_byDataDecryptCommand_model import FridaResponseDecrypt # 用于解密试题
from hook.answer_encrypt.do_answer_encrypt_model import FridaRequestEncrypt # 用于加密答案
# 配置cookie
cookies = {
"YFD_U": "3847438009944888250",
"__sub_user_infos__": "",
"g_loc": "",
"g_sess": "",
"ks_deviceid": "",
"ks_persistent": "QMmkLezpVEnIDy5DBBYH8JCtetnHBMoeF/oLExT1M0Mm3vXOWYQkW94Fup6lG1fG/nwHtujAywRgm/iYSBKbz/M4NepnRtXRxV/mxXQN7Ec=; sid=5378041981795643460",
"ks_sess": "",
"persistent": "",
"sess": "wXmbuKWPmdrsrkkQ7bqj3zCfG8Jpa7yOIlYCFWMVt3lFRC7Qh0Gtw40S358h6ct2YzGCSQKswQvT1pKoHRNL9ACDDrtZM+Mq2O+jKz4l1Ks=",
"sid": "",
"userid": "1053892750"
}
# 定义要执行的次数
execution_count = 50 # 这里填入你要重复的次数
def execute_task():
try:
# 生成签名
#这里的第三个参数是pid
getQuestion_extractor = FridaSignExtractor("com.fenbi.android.leo", "hook/gan_sign/gan_sign_model.js", 15120)
getQuestion_extractor.start()
getQuestion_sign_value = getQuestion_extractor.getsign("/leo-game-pk/android/math/pk/match/v2")
print("gan_sign_model sign value:", getQuestion_sign_value)
# 获取试题
matchV2_url = (
f"https://xyks.yuanfudao.com/leo-game-pk/android/math/pk/match/v2?"
f"pointId=2&_productId=611&platform=android32&version=3.93.3&vendor=fenbi"
f"&av=5&sign={getQuestion_sign_value}&deviceCategory=pad"
)
matchV2_response = requests.post(matchV2_url, headers={
"cookie": "; ".join([f"{k}={v}" for k, v in cookies.items()])
})
print("获取到试题未解密大概长度", len(matchV2_response.text))
# 解密试题
#这里的第三个参数是pid
decrypt = FridaResponseDecrypt("com.fenbi.android.leo",
"hook/matchV2_byDataDecryptCommand/do_matchV2_byDataDecryptCommand_model.js",
15120)
decrypt.start()
match_question = decrypt.getstr(base64.b64encode(matchV2_response.content).decode('utf-8'))
print("解密试题: ", match_question)
# 构建答案数据包
match_question_json = json.loads(match_question)
answer_json = match_question_json["examVO"]
answer_json["correctCnt"] = answer_json["questionCnt"]
answer_json["costTime"] = 100
answer_json["updatedTime"] = int(time.time() * 1000)
for question in answer_json["questions"]:
question["status"] = 1
question["userAnswer"] = question["answer"][0]
question["script"] = ""
question["curTrueAnswer"] = {
"recognizeResult": question["answer"][0],
"pathPoints": [],
"answer": 1,
"showReductionFraction": 0
}
answer_data = json.dumps(answer_json, ensure_ascii=False)
print("生成答案: ", answer_data)
# 提交答案
answer_data_base64 = base64.b64encode(answer_data.encode('utf-8')).decode('utf-8')
request_encrypt = FridaRequestEncrypt("com.fenbi.android.leo", "hook/answer_encrypt/do_answer_encrypt_model.js",
None)
request_encrypt.start()
answer_encrypt_base64 = request_encrypt.get_request_encrypt(answer_data_base64)
upAnswer_sign_value = getQuestion_extractor.getsign("/leo-game-pk/android/math/pk/submit")
upAnswer_url = f"https://xyks.yuanfudao.com/leo-game-pk/android/math/pk/submit?_productId=611&platform=android32&version=3.93.3&vendor=fenbi&av=5&sign={upAnswer_sign_value}&deviceCategory=pad"
upAnswer_response = requests.put(url=upAnswer_url, headers={
"cookie": "; ".join([f"{k}={v}" for k, v in cookies.items()])
}, data=base64.b64decode(answer_encrypt_base64))
print("提交结果: ", upAnswer_response.text)
except Exception as e:
print("执行任务时出错: ", e)
def main():
threads = []
for _ in range(execution_count):
thread = threading.Thread(target=execute_task)
thread.start()
threads.append(thread)
time.sleep(1) # 控制线程启动间隔
for thread in threads:
thread.join() # 等待所有线程完成
print("所有任务执行完成,脚本退出。")
if __name__ == "__main__":
main()2024-10-15 12:57 首先看战绩

现在测试的刷分速度的1分钟40w 一个小时也就是2400w 思路如下。rh1 首先感谢哔哩哔哩的一个人提供的免进入结算画面(这样可以有效的提高速度) 思路就是在结算过程中退出。然后用自动精灵来实现自动化。
还是这个js题目改到25000道。太高的话会刷不上去
const num = 25000 //题数
function Hookr2B(){
Java.perform(function(){
const JString= Java.use("java.lang.String")
let r2 = Java.use("com.fenbi.android.leo.utils.r2")
r2.b.overload("[B").implementation = function (data) {
data = JSON.parse(String.fromCharCode(...new Uint8Array(data)))
data.costTime = 1
for(let i=0;i<num;i++){
data.questions.push({"answers":[">"],"content":"5\\circle3","costTime":319,"errorState":0,"examId":0,"id":1,"keypointId":0,"ruleType":0,"script":"[[{\"x\":388.6875,\"y\":1198.2977},{\"x\":431.756,\"y\":1198.2083},{\"x\":474.76447,\"y\":1202.074},{\"x\":515.89124,\"y\":1211.7893},{\"x\":565.727,\"y\":1224.9923},{\"x\":618.53485,\"y\":1237.8978},{\"x\":666.50287,\"y\":1247.9371},{\"x\":709.3284,\"y\":1258.8792},{\"x\":722.86755,\"y\":1271.5013},{\"x\":712.543,\"y\":1301.1832},{\"x\":672.1436,\"y\":1350.3722},{\"x\":616.1422,\"y\":1401.6215},{\"x\":552.83264,\"y\":1445.8134},{\"x\":486.4492,\"y\":1477.8749},{\"x\":436.92188,\"y\":1499.6764}]]","status":1,"userAnswer":">","wrongScript":"[]"})
}
data = JString.$new(JSON.stringify(data)).getBytes()
return this["b"](data)
}
})
}
setTimeout(Hookr2B, 0);这个是具体的演示视频:
https://github.com/user-attachments/assets/f1394378-bd91-4095-8f9a-7bb8ae7fcf99 关于视频里面的方案使用的自动精灵
各位可以看我这个的配置 第一个是跳过的 第二个和第三个是点击退出的。(退出一定要快,要在刚出来加载页面的时候退出,不然还是会卡) 第四个就是点击自动练习的

2024-10-13 18:43
最新刷分思路真正的万分思路
首先感谢这个项目的作者
https://github.com/MDYY1/XiaoYuanKouSuan_ShuaFen_Frida_Hook
之后我来说一下教程
去他这里下载上js文件
这里我也贴上js
这里建议题数别太高,不然会卡甚至是闪退,亲测1w是极限了差不多,(会黑屏一会,但是会正常给经验)


const num = 2000 //题数
function Hookr2B(){
Java.perform(function(){
const JString= Java.use("java.lang.String")
let r2 = Java.use("com.fenbi.android.leo.utils.r2")
r2.b.overload("[B").implementation = function (data) {
data = JSON.parse(String.fromCharCode(...new Uint8Array(data)))
data.costTime = 1
for(let i=0;i<num;i++){
data.questions.push({"answers":[">"],"content":"5\\circle3","costTime":319,"errorState":0,"examId":0,"id":1,"keypointId":0,"ruleType":0,"script":"[[{\"x\":388.6875,\"y\":1198.2977},{\"x\":431.756,\"y\":1198.2083},{\"x\":474.76447,\"y\":1202.074},{\"x\":515.89124,\"y\":1211.7893},{\"x\":565.727,\"y\":1224.9923},{\"x\":618.53485,\"y\":1237.8978},{\"x\":666.50287,\"y\":1247.9371},{\"x\":709.3284,\"y\":1258.8792},{\"x\":722.86755,\"y\":1271.5013},{\"x\":712.543,\"y\":1301.1832},{\"x\":672.1436,\"y\":1350.3722},{\"x\":616.1422,\"y\":1401.6215},{\"x\":552.83264,\"y\":1445.8134},{\"x\":486.4492,\"y\":1477.8749},{\"x\":436.92188,\"y\":1499.6764}]]","status":1,"userAnswer":">","wrongScript":"[]"})
}
data = JString.$new(JSON.stringify(data)).getBytes()
return this["b"](data)
}
})
}
setTimeout(Hookr2B, 0);之后还是python运行这个,pid可以用gg模拟器来获取。 之后注入成功后进入练习,答十道题
import sys
import frida
# 获取 PID
pid = 4338
# 通过链接到虚拟机frida-server
device = frida.get_usb_device()
# 附加到已有进程的PID
session = device.attach(pid)
# 加载js文件
with open("2.js", encoding='utf-8') as f:
script = session.create_script(f.read())
# 加载js文件并获取脚本输出的信息
script.load()
# 保持脚本运行
sys.stdin.read()进行结算就可以了
2024-10-13 16:36 最新真正意义上的0s 不管你做题速度多慢,提交后为0s 这个的整体思路是通过frida进行拦截,修改做题用时。
先看结果

最先是这个项目所提出来的方案 https://github.com/Hawcett/XiaoYuanKouSuan_Frida_hook 之后我这里简单教学一下我对于这个方案实操的过程。 代码方面使用的是 x781078959用户写出的 https://github.com/x781078959/xyks/tree/master/frida/submit 首先是mumu模拟器安装firda-service 这里推荐的是14.2.18版本。(前俩天更新的那个版本没有适配mumu模拟器,安装会出现问题)
之后把包移动到data/local/tmp这里

之后用adb shell进入adb控制台把他启动起来就可以

这个的https://github.com/x781078959/xyks/tree/master/frida/submit
代码可以直接用。如果你出现无法获得pid,(这个我刚才操作出现过,不过后面就没有再出现了。)
可以使用gg修改器去查看pid。
 之后运行这个代码就没问题了
之后运行这个代码就没问题了
import json
import sys
import frida
# 获取 PID
pid = 3602
# 通过链接到虚拟机frida-server
device = frida.get_usb_device()
# 附加到已有进程的PID
session = device.attach(pid)
# 加载js文件
with open("submit.js", encoding='utf-8') as f:
script = session.create_script(f.read())
# 设置控制台消息处理程序
def on_message(message, data):
print(1)
if message['type'] == 'send':
print(1)
# 复制粘贴 https://github.com/Hawcett/XiaoYuanKouSuan_Frida_hook 的代码
bytes_obj = bytes.fromhex(message['payload'])
string = bytes_obj.decode('utf-8')
string = string.replace(r'\"', "%")
# 修正null不加引号导致的错误
string = string.replace("null", '"null"')
print("字符串: ", string)
json_data = json.loads(string)
print(json_data)
print('原始花费时间:', json_data['costTime'])
# TODO 时间不要修改为0 最低为1 否则会有难以解决的错误
json_data['costTime'] = 1
print('现在花费时间:', json_data['costTime'])
print(json_data)
data = str(json_data).replace('%', r'\"')
data = str(data).replace('\'', '\"')
data = str(data).replace(' ', '')
script.post({'type': 'send', 'my_data': data})
else:
print("[{}] {}".format(message['type'], message['description']))
# 设置消息处理程序
script.on('message', on_message)
# 加载js文件并获取脚本输出的信息
script.load()
# 保持脚本运行
sys.stdin.read()之后是另外一个xp模块的项目(这个适合想要冲全国榜的) https://github.com/zhangLog08/Simian 这个可以方便快速的完成下面的功能 自定义答案(题数不变) 模式二:自定义答案(只有一道题) 冲榜方法可以看这里:https://www.bilibili.com/video/BV1Y52vYVEEd/?spm_id_from=333.999.0.0
最新10-12 21:48 可直接看这个项目 已经测试pk可用,https://github.com/cr4n5/XiaoYuanKouSuan 顺便补一句,如果冲榜也可选择1w道题,可以改成功
pk的代码精简版(要去那个项目里面下载上那个js文件)Mitmproxy的端口和host自己去改,代码里面是我的:
import argparse
import sys
from mitmproxy.tools.main import mitmdump
# 命令行参数解析
parser = argparse.ArgumentParser(description="Mitmproxy script")
parser.add_argument("-P", "--port", type=int, default=8080, help="Port to listen on")
parser.add_argument("-H", "--host", type=str, default="192.168.190.1", help="Host to listen on")
args = parser.parse_args()
sys.argv = ["mitmdump", "-s", __file__, "--listen-host", args.host, "--listen-port", str(args.port)]
# 直接处理请求和响应
def handle_flow(flow):
print(f"Response: {flow.response.status_code} {flow.request.url}")
if "https://leo.fbcontent.cn/bh5/leo-web-oral-pk/exercise_" in flow.request.url:
with open("exercise.js", "r", encoding="utf-8") as f:
text = f.read()
if text:
flow.response.text = text
print("修改成功")
else:
print("未能修改响应文本")
# 启动 mitmdump
mitmdump()最新10-11 20:12:现在pk改包虽然不能用了,但是识别题目已经有人解出来了,那就可以用抓包后获取答案加adb继续炸鱼。
xmexg/xyks#9
先放战绩:


先说整体思路:抓包+改答案+adb模拟
之后详细教程:
我这里用到的是小黄鸟,你用别的抓包软件也可以。
过ssl用这个
之后刷分最快的是练习里面去修改题数
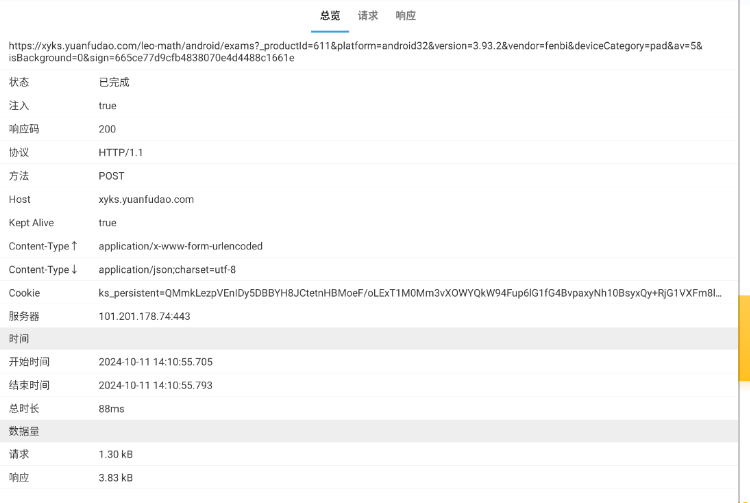
修改题数我这里是改的这个的请求体

之后修改完成后,要自己手答一遍。建议直接点跳过
之后正常打完后会继续结算页面。(注意这个时候要关闭抓包软件,建议是在修改过后,是你想要的题目数量后就关闭抓包,不然会结算不了)
结算完成后开启抓包,(此时开修改答案为1)
即可完成操作。
之后抓包软件就可以一直开启着。
改答案我这里用到的是我基于这个 XiaoYuanKouSuan/main.py at main · cr4n5/XiaoYuanKouSuan (github.com)的昨天的一个版本修改的当时他还没有练习的模式,现在我看已经有了,可以参考他的代码 当然我的这个也可以用 (这个更新速度很快)里面很多没用的东西我都没删掉。
import re
import time
import sys
import threading
import argparse
import adbutils
from mitmproxy import http
from mitmproxy.tools.main import mitmdump
auto_jump = True
# 拦截 HTTP 响应,检查 URL 并逐个字段替换
def response(flow: http.HTTPFlow):
# 匹配目标 URL
url_pattern = re.compile(r"https://xyks.yuanfudao.com/leo-math/android/exams.+")
# 如果 URL 匹配
if url_pattern.match(flow.request.url):
# 如果响应类型是 JSON
if "application/json" in flow.response.headers.get("Content-Type", ""):
response_text = flow.response.text
# 使用正则表达式逐个替换字段
response_text = re.sub(r'"answer":"[^"]+"', '"answer":"1"', response_text)
response_text = re.sub(r'"answers":\[[^\]]+\]', '"answers":["1"]', response_text)
# 更新修改后的响应体
flow.response.text = response_text
threading.Thread(target=answer_write, args=(len(re.findall(r'answers', flow.response.text)),)).start()
def jump_to_next():
# 结束,自动进下一局
device = adbutils.adb.device()
time.sleep(3)
command = "input tap 540 1520"
device.shell(command) # “开心收下”按钮的坐标
time.sleep(0.3)
command = "input tap 780 1820"
device.shell(command) # “继续”按钮的坐标
time.sleep(0.3)
command = "input tap 510 1700"
device.shell(command) # “继续PK”按钮的坐标
def swipe_screen():
xy = [[1480, 1050], [1440, 1470]]
command = f"input swipe {xy[0][1]} {xy[0][0]} {xy[1][1]} {xy[1][0]} 0"
device = adbutils.adb.device()
device.shell(command)
def answer_write(answer):
time.sleep(6)
for _ in range(5500):
print("11111")
swipe_screen()
time.sleep(0.01)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Mitmproxy script")
parser.add_argument("-P", "--port", type=int, default=8080, help="Port to listen on")
parser.add_argument("-H", "--host", type=str, default="192.168.190.1", help="Host to listen on")
args = parser.parse_args()
sys.argv = ["mitmdump", "-s", __file__, "--listen-host", args.host, "--listen-port", str(args.port)]
mitmdump()0s这些是我昨天弄的,如果你按照我的方法是可行的

关于0s
就是改为一道题,然后用adb
这里就不建议开启抓包了,改好一次后(这里指的是改好题目数量),关闭抓包,不断的点再练一次在刷成绩,也不建议修改答案。
因为这个0s是我昨天弄成的,我不知道今天是否还有用。
还是很容易刷出来的,基本上我刷俩分钟就出来了。
刷出来的标志:就是在图标还没有完全消失之前adb已经绘制好了答案。这样就是0s。
但是0s的话,当前账号就无法看到你取得0s的那个排行榜的榜单了,别人那里是显示的,不过排名是0
后台挂着改包的脚本(改包现在pk没办法用,但是练习还可以用) 之后我这里用的自动精灵,其他的也可以,可以看演示视频:https://www.bilibili.com/video/BV1Ri2SYsEk4/?spm_id_from=333.999.0.0 亲测了一下午发现改题目数量与不改题目数量差距不大,这个操作起来比较简单。
介绍一下自己,大三学生,计算机专业。
从昨天一直搞到今天,大概也弄了十来个小时了。
一路看着各种思路的出现
从最开始的autojs ocr
到后面的抓包提前拿答案。到改包改答案。 pk30题改1题。
我这个思路不见得是最优的方案,并且只是思路,代码实现方面还需要有人去优化。
网络安全路漫漫,这次的事件,不只是给小猿平台,更是给更多的程序员提了醒,其实多一次验证,就可以完美避开这个问题。