producer configuration
Here you can find the list of the parameters to be configured when defining the producer side for the plugin.
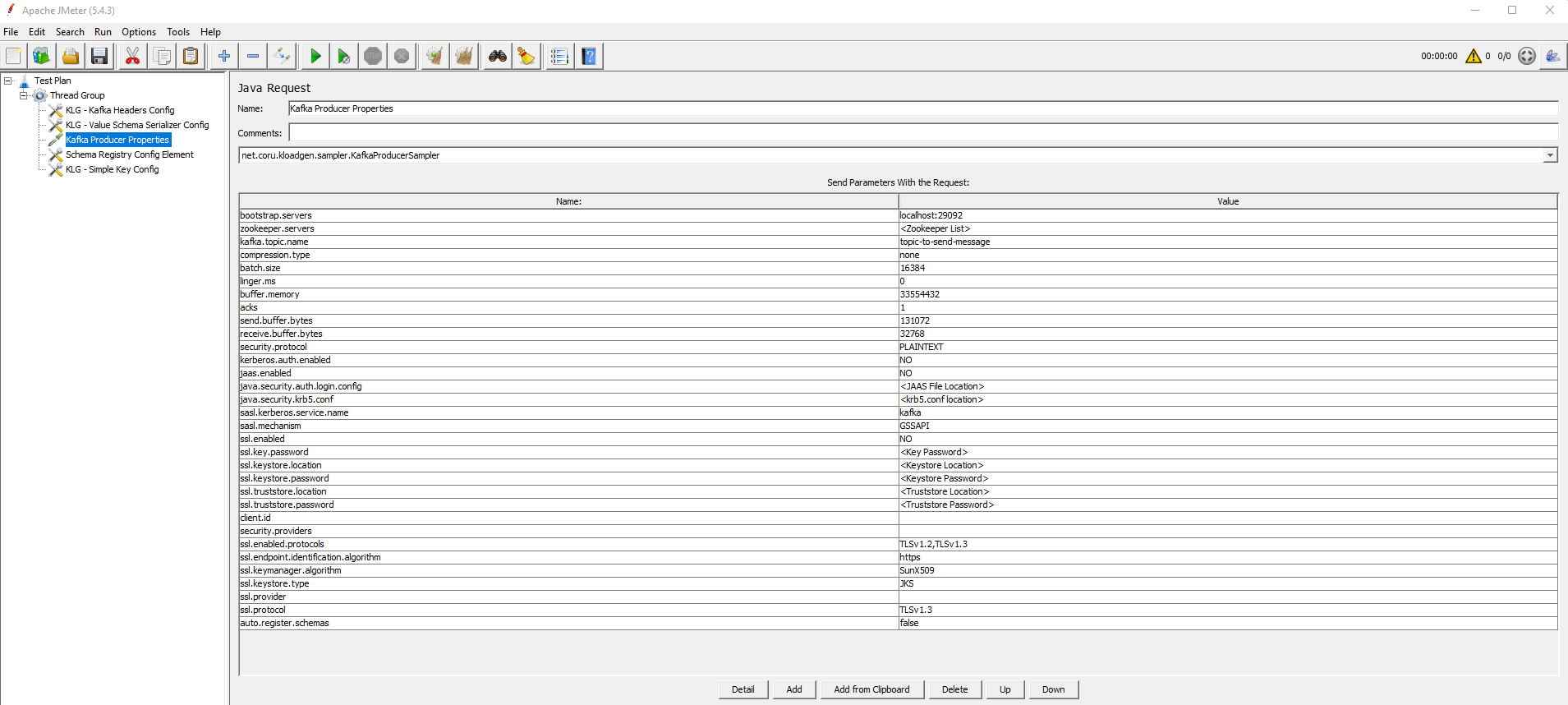
-
bootstrap.servers: list of Bootstrap servers with format: broker-ip-1:port, broker-ip-2:port, broker-ip-3:port. -
zookeeper.servers: list of Zookeeper servers with format: zookeeper-ip-1:port, zookeeper-ip-2:port, zookeeper-ip-3:port. -
kafka.topic.name: topic on which messages will be sent. -
compression.type: Kafka producer compression type. Valid values are:none/gzip/snappy/lz4. The default value isnone. -
batch.size: messages batch size. If you define a compression type such aslz4, and also increase this batch size value, you get better throughput. The default value is16384. -
linger.ms: establishes how much time the producer should wait until the batch becomes full. If the batch size is increased and compression is enabled, it should be in the range5-10. The default value is0. -
buffer.memory: total buffer memory for producer. The default value is33554432. -
acks: acknowledgement of message sent. Valid values are:0/1/-1. The default value is1. -
send.buffer.bytes: the size of the TCP send buffer (SO_SNDBUF) to use when sending data. If the value is-1, the OS default will be used. The default value is131072. -
receive.buffer.bytes: the size of the TCP receive buffer (SO_RCVBUF) to use when reading data. If the value is-1, the OS default will be used. The default value is32768. -
security.protocol: Kafka producer protocol. Valid values are:PLAINTEXT/SSL/SASL_PLAINTEXT/SASL_SSL. The default value isPLAINTEXT. -
kerberos.auth.enabled: establishes whether the Kerberos authorization is enabled or disabled. If it is disabled, the two following properties will be ignored. The default value isNO. -
java.security.krb5.conf: location of thekrb5.conffile for the Kerberos server. -
sasl.kerberos.service.name: Kafka Kerberos service name. The default value iskafka. -
jaas.enabled: establishes whether JAAS is enabled or disabled. The default value isNO. -
java.security.auth.login.config: location of thejaas.conffile for Kafka Kerberos. -
sasl.mechanism: configures the SASL mechanism to use to connect to the Kafka cluster. The default value isGSSAPI. -
ssl.enabled: establishes whether SSL is enabled or disabled. The default value isNO. -
ssl.key.password: SSL password. -
ssl.keystore.location: SSL keystore location. -
ssl.keystore.password: SSL keystore password. -
ssl.truststore.location: SSL trust store location. -
ssl.truststore.password: SSL trust store password. -
client.id: Kafka producer client ID. -
security.providers: establishes the security providers. The default value is blank. -
ssl.enabled.protocols: SSL enabled protocols. Valid values are:TLSv1.2/TLSv1.3. The default value isTLSv1.2,TLSv1.3. -
ssl.endpoint.identification.algorithm: SSL endpoint identification algorithm. You can leave the default value if you don't want to set it. The default value ishttps. -
ssl.keymanager.algorithm: the algorithm used by the key manager factory for SSL connections. The default value isSunX509. -
ssl.protocol: the SSL protocol used to generate the SSLContext. The default value isTLSv1.3. -
ssl.keystore.type: type of the repository for the security certificates. The default value isJKS. -
ssl.provider: the name of the security provider used for SSL connections. The default value is blank. -
ssl.protocol: the SSL protocol used to generate the SSLContext. The default value isTLSv1.3. -
auto.register.schemas: allows or disallows the Schema Registry client to register the schema if missing. The default value isfalse.
These are the configuration elements corresponding to the Kafka producer. See below the details for each one.
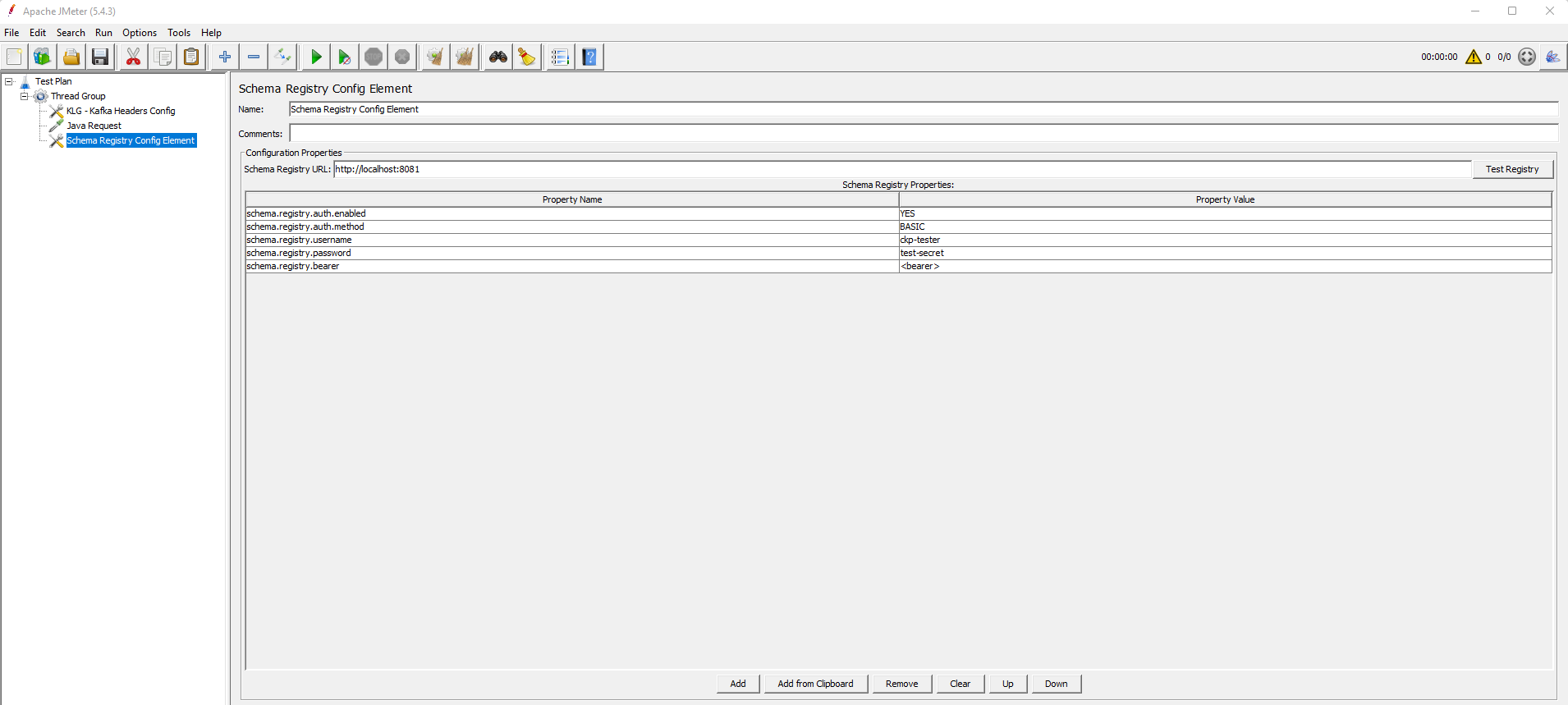
This configuration element establishes the connection to the Schema Registry and retrieves the list of subjects included there.
You need to provide the URL for the Schema Registry server in the Schema Registry URL field and set up the following properties:
Only the actual set of properties are supported.
| Property | Values | Description |
|---|---|---|
schema.registry.auth.enabled |
YES/NO
|
Enables/disables security configuration |
schema.registry.auth.method |
BASIC/BEARER
|
Authentication method type |
schema.registry.username |
String | The username |
schema.registry.password |
String | The password |
schema.registry.bearer |
String | The bearer for token authentication |
The Test Registry button will test the connection properties and retrieve the subject list from the Schema Registry.
A confirmation message will be shown with the number of subjects retrieved from the Registry.
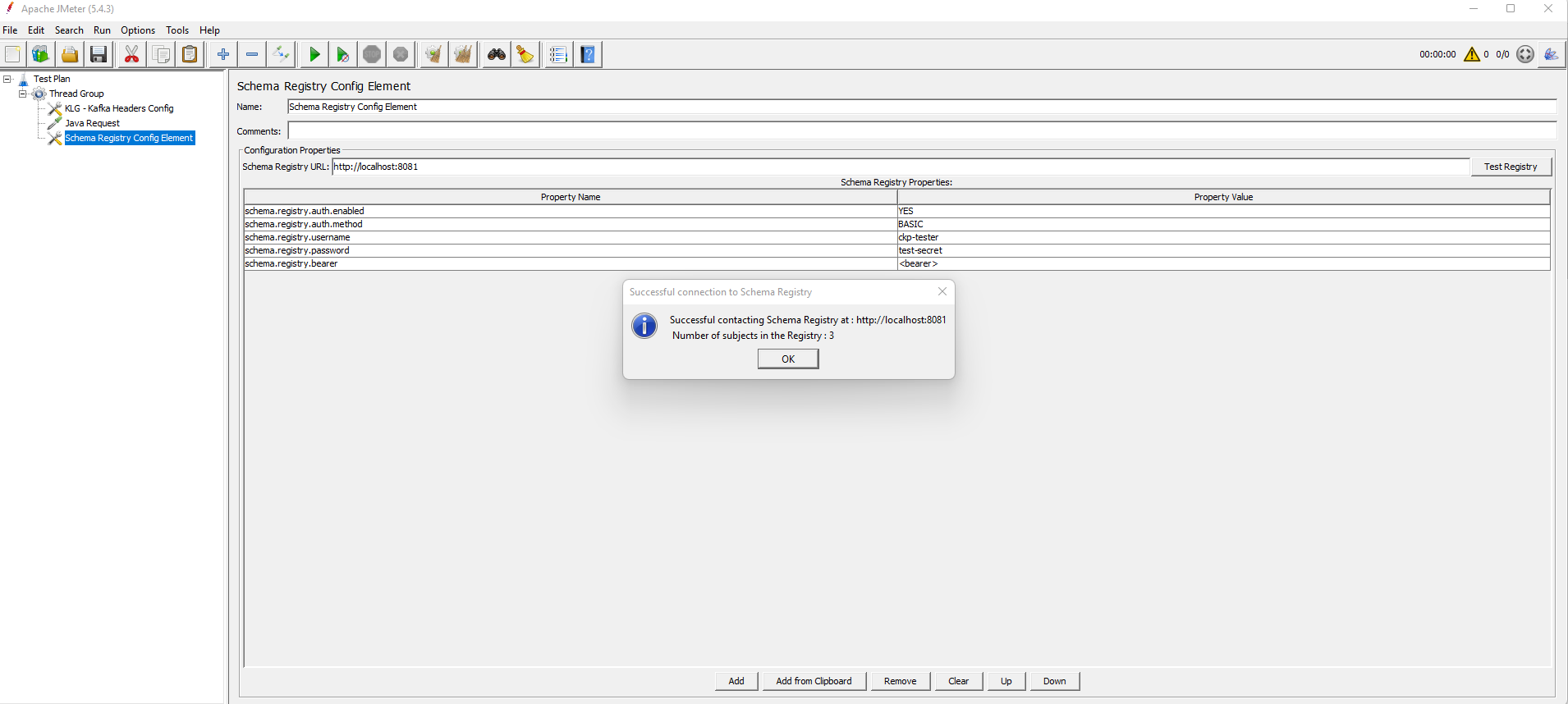
The subject list will be used when configuring the AVRO schema to download.
KLoadGen includes five serializers, apart from the ones from Kafka. Make sure to choose the best option for you.
KLoadGen includes four elements to configure the schema that will be used to serialize the data: KLG - Value Schema Serializer Config, KLG - Value Schema File Serializer Config, KLG - Key Schema Serializer Config, and KLG - Key Schema File Serializer Config.
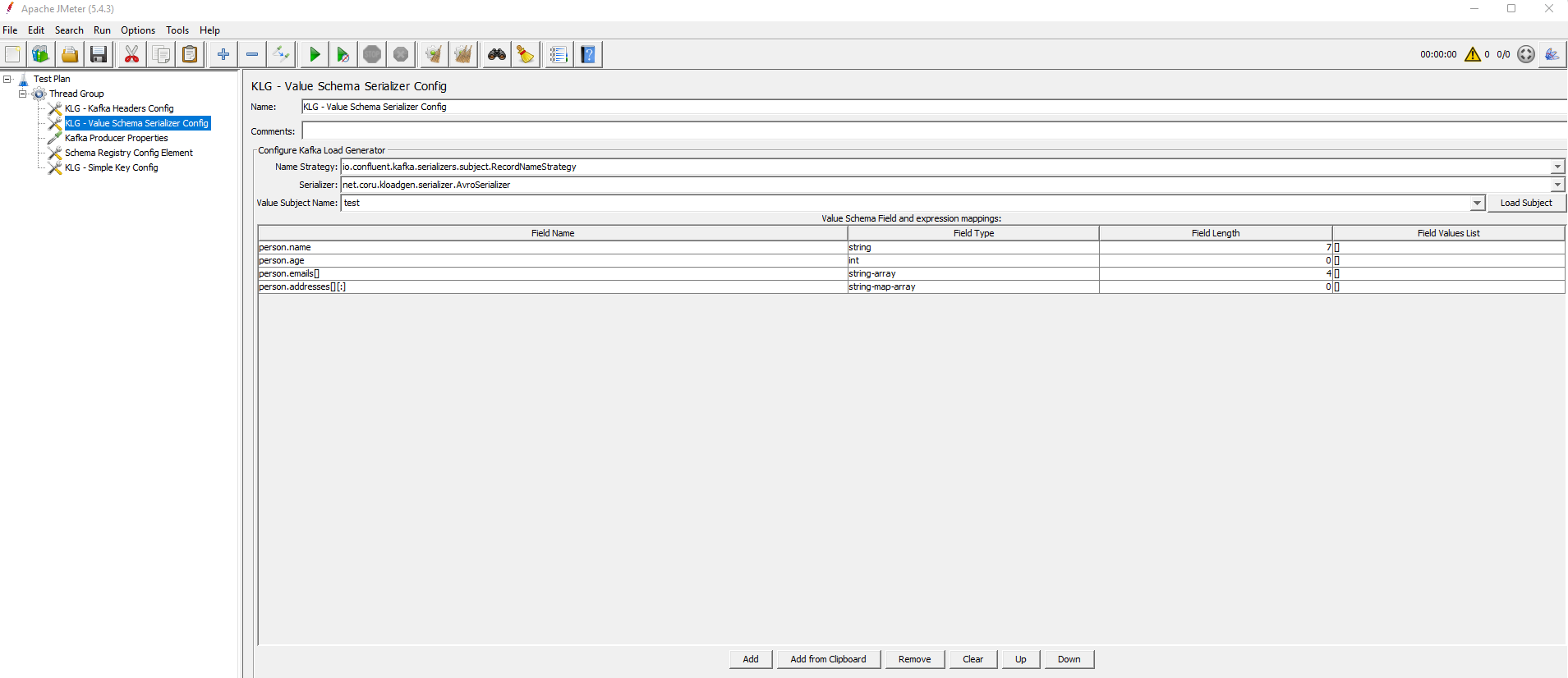
This configuration element allows to choose a subject and download its schema.
You need to provide values for Name Strategy and Serializer to get the list of subjects. The Load Subject button loads the schema for the chosen subject.
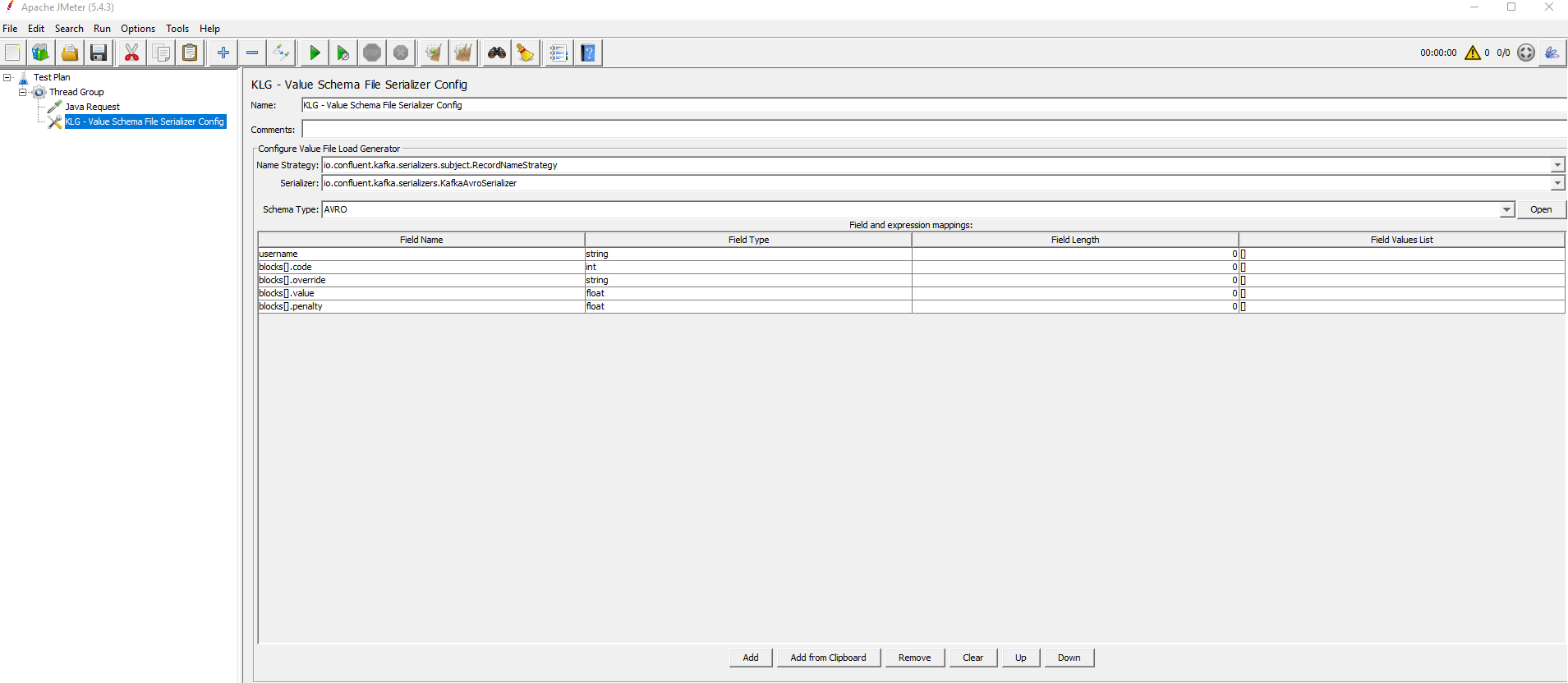
This configuration element allows to load a schema from a file (.avsc, .json or .proto).
You need to provide values for Name Strategy, Serializer and Schema Type.
The Open button loads the file.
Note: If the file includes embedded schemas, the last definition will be considered the main one, and the ones above will be considered as related to it. If there are unrelated schemas, they will be ignored.
This configuration element is similar to KLG - Value Schema Serializer Config, except that it is focused in a key schema instead of a value schema.
Whatever schema you define and configure here will be used as the message key.
This configuration element is similar to KLG - Value Schema File Serializer Config, except that it is focused in a key schema instead of a value schema.
Whatever schema you define and configure here will be used as the message key.
The four previous configuration elements share the same table, which includes the flattened structure that will be used to generate the random values.
-
Field Name: flattened field name composed by all the properties from the root class. Ex:
PropClass1.PropClass2.PropClass3.
Note:- The arrays show
[]at the end. If you want to define a specific size for the array, just type the number inside (i.e.[10]). - The maps show
[:]at the end. If you want to define a specific size for the map, just type the number to the left of the colon (i.e.[10:]).
- The arrays show
- Field Type: field type, such as String, Int, Double, Array, etc. For a complete list of field types, see Field types.
- Field Length: field length configuration for the Random Tool. For strings, it indicates the number of characters. For numbers, it indicates the number of digits.
-
Field Values List: possible list of values for the field, which will be used by the Random Tool to generate values.
Note:
- For reading context values by default in JMeter, they must be in the way:
${name_of_variable} - If the field type is an array or a map, you can define a specific list of values ([1,2,3,4,5] or [key1:value1, key2:value2, key3:value3]).
- For reading context values by default in JMeter, they must be in the way:
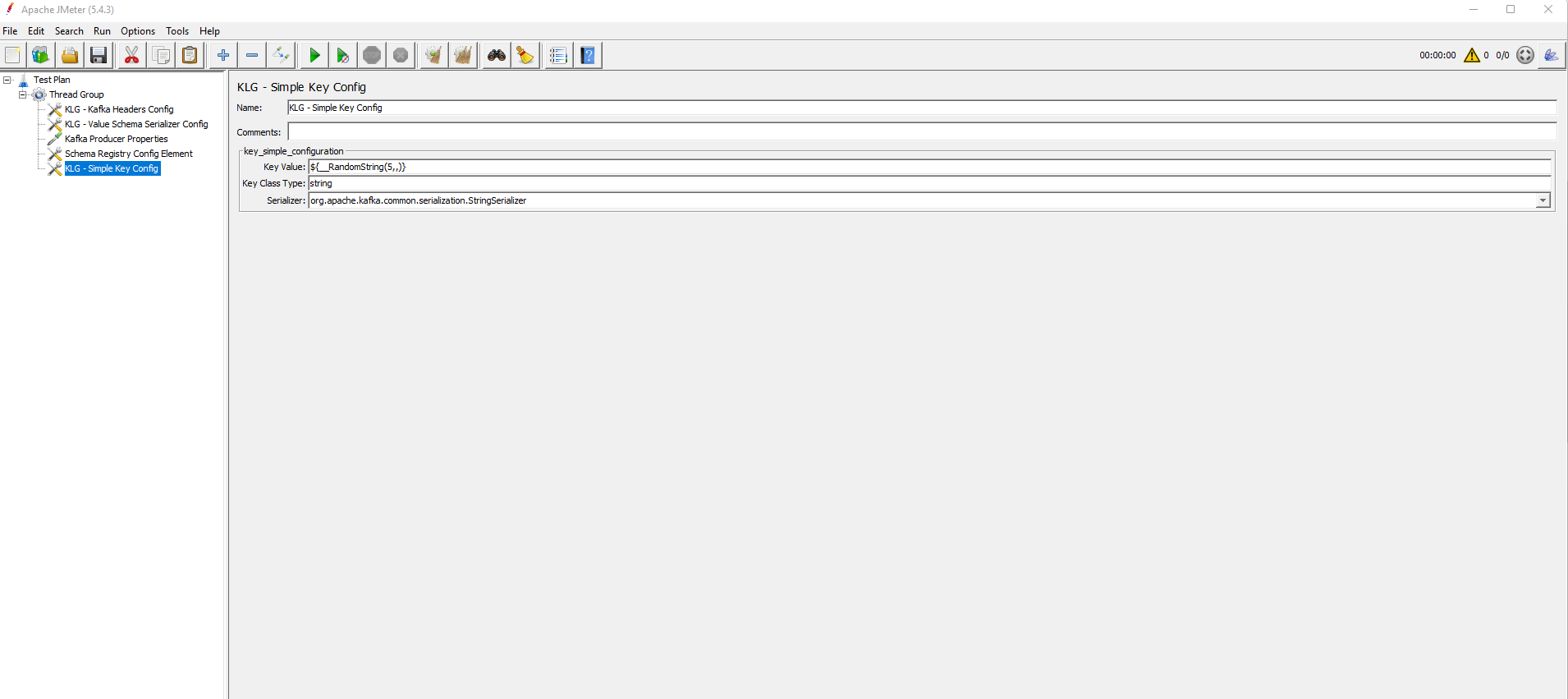
This configuration element allows to define a simple key with primitive types.
You need to provide values for Key Value, Key Class Type and Serializer.
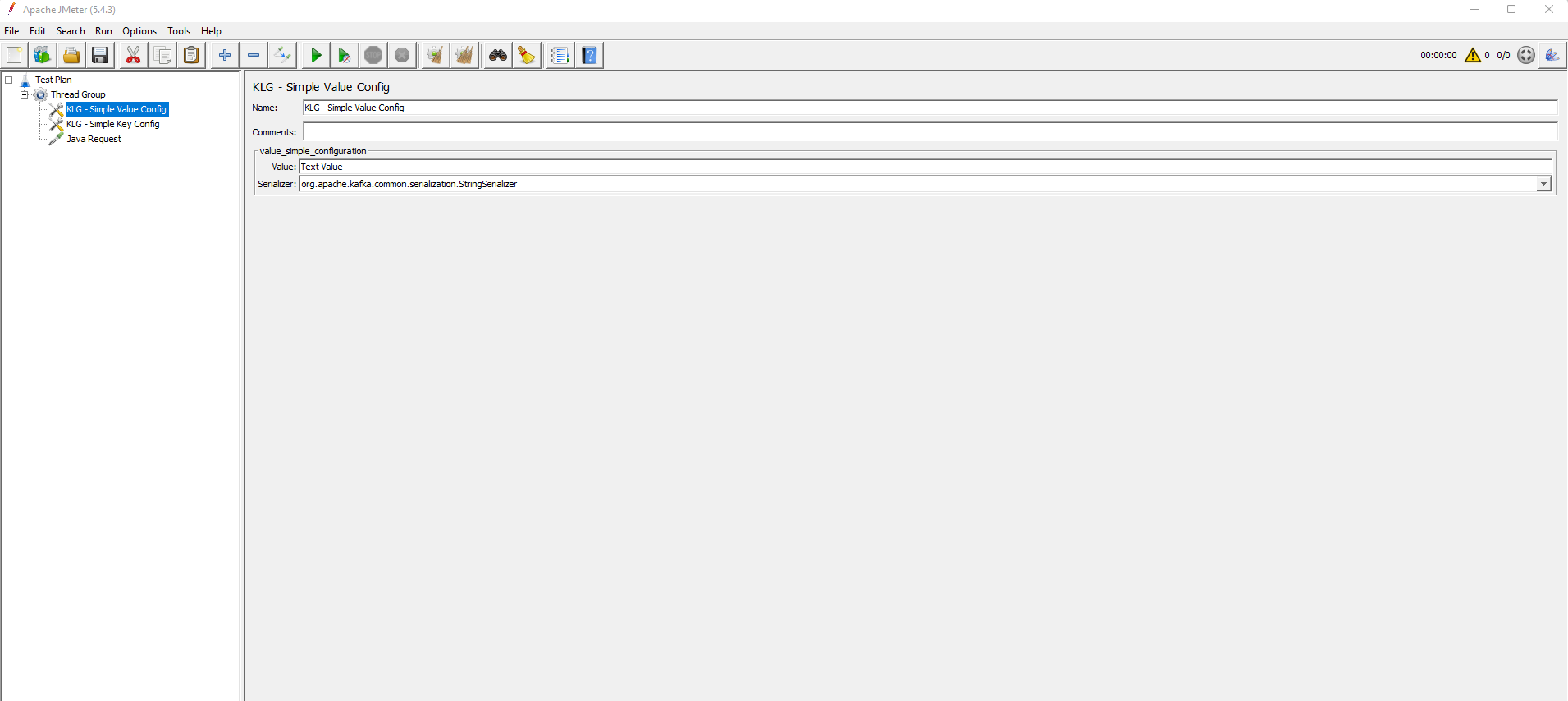
This configuration element allows to define a simple value with no schema needed.
You need to provide values for Value and Serializer.
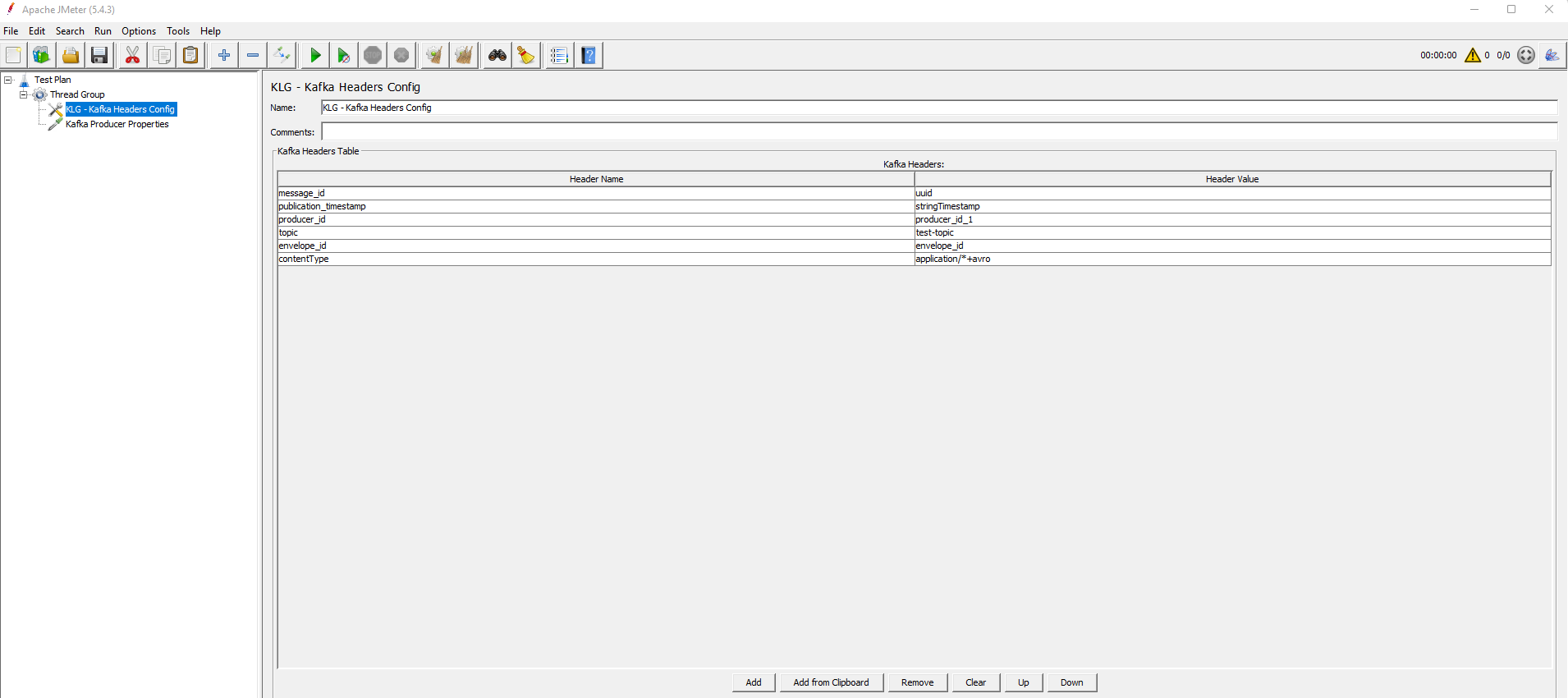
This configuration element allows to specify a list of headers which will be included in the producer.
The headers specified here will be included in every message after they are serialized.
Values will also be included. They will be considered of type string, whether they are supplied in the table or randomly generated.
-
AvroSerializer: adds a header with the id of the schema, uses GenericDatumWriter to transform the data into an array of bytes and sends it.
-
GenericAvroRecordBinarySerializer: uses SpecificDatumWriter to transform the data into an array of bytes and sends it.
-
GenericAvroRecordSerializer: uses SpecificDatumWriter to transform the data into JSON and sends it.
-
GenericJsonRecordSerializer: maps the data and sends it.
-
ProtobufSerializer: transforms the data into an array of bytes and sends it.