Set pd.options.display.max_columns=0 by default #17023
Conversation
|
Could you provide some before / after screenshots? This will need some feedback from the wider community, since the visual display of DataFrames is an API grey-zone; prepare for bike-shedding 😄 We still have some situations where we can't detect the terminal width reliably. We need to make sure the output is handled as well as possible there. I'm +1 for reducing the number of rows displayed. Typically I use 10 rows. |
|
Here's the current output when printing a data frame with shape (5, 10) in a terminal with 100 characters width:
And here is the same data frame after the proposed change:
|


|
I'm OK with this. I do think it needs a big note in the whatsnew, with instructions on how to change back (maybe a ref to IPython config too). Also looks like some tests that will need adjusted. |
pandas/core/config_init.py
Outdated
| validator=is_instance_factory([type(None), int])) | ||
| cf.register_option('max_categories', 8, pc_max_categories_doc, | ||
| validator=is_int) | ||
| cf.register_option('max_colwidth', 50, max_colwidth_doc, validator=is_int) | ||
| cf.register_option('max_columns', 20, pc_max_cols_doc, | ||
| cf.register_option('max_columns', 0, pc_max_cols_doc, |
There was a problem hiding this comment.
hmm, this should be None to auto-detect (0 might do the same though)
There was a problem hiding this comment.
So should I change 0 to None or leave it as is?
There was a problem hiding this comment.
A quick test shows that None means there is no limit (i.e. display all columns). So I guess this should remain 0.
There was a problem hiding this comment.
hmm, so 0 is NOT the same as None here ? that is very odd. can you show an example
There was a problem hiding this comment.
Well, I tried setting this value to None after importing pandas, i.e.
import pandas as pd
pd.options.display.max_columns = None
And this results in all columns printed out (so no ellipsis to mark skipped columns in the output). But I will try setting the value in config_init.py as well.
There was a problem hiding this comment.
I can confirm that None and 0 have different meanings. None prints all columns, whereas 0 prints columns that fit within the terminal width.
|
yeah changing the column default to auto-detect is fine. I personally use an event smaller default for |
|
Do you really want screenshots or could we mimic the old and new behavior with markdown? If you want screenshots let me modify them so that my username doesn't show up. Regarding the tests, I'll see what I can do (I certainly didn't expect to break so many tests just by changing one value 😄). |
|
the issue is that we are now auto-detecting and so the actual terminal width matters. yes certainly we can 'set' it so it works and show in mark down. I think screenshots might be more clear here though. |
|
I see, I'll provide new screenshots then. Thanks for pointing out the issue, of course this makes a huge difference! |
|
Also, the IPython QtConsole doesn't play nicely with
|
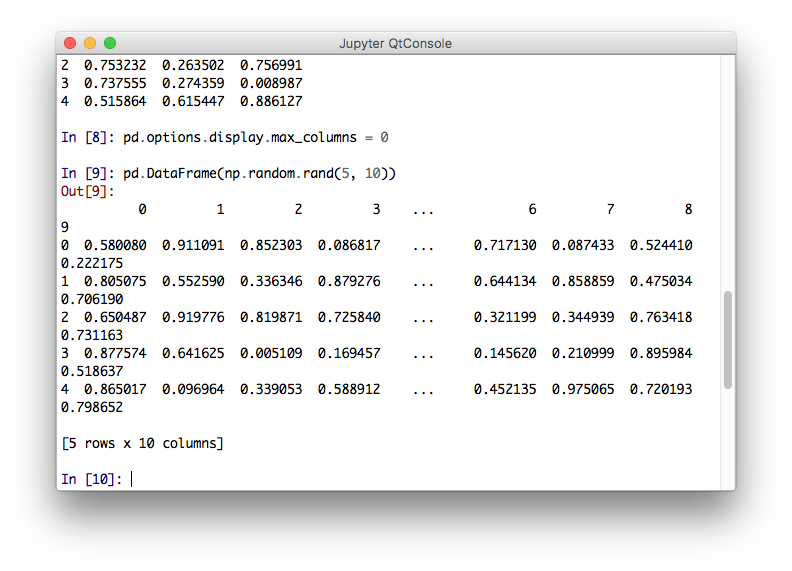
|
@takluyver - assuming this hasn't changed, but do you know offhand if it's still not possible to detect terminal size running in the qtconsole? Found an older SO answer from you, thanks! |
|
No, sorry. It's a conceptual mismatch, not just a technical one. The kernel is producing output for (potentially) several frontends which may be receiving it at the moment, and for applications which may later display saved copies of that output. So questions about the shape of 'the' output area don't really make sense in the Jupyter protocol. As I see it, the real issue is that the Qt console doesn't understand any structured way of representing a table. We turned off its HTML support because it's just too limited and tends to break richer HTML written for the notebook frontend. I have occasionally advocated for a 'simple HTML' repr option which the Qt console would display, but it's never been high priority. In the long run, I think our plan is to make an HTML console and use QtWebkit to embed it in Qt applications. Then it should be able to display HTML tables. |
|
Thanks @takluyver - so this isn't going to work until HTML tables are rendered (which would be awesome BTW). Is it possible to determine if Pandas is running in a real terminal or not? Could someone point me to the relevant code parts? |
|
It's possible to distinguish terminal IPython from IPython as a kernel for a Jupyter frontend, something like this: try:
ip = get_ipython()
except NameError:
... # Not IPython
else:
if hasattr(ip, 'kernel'):
... # IPython as a Jupyter kernel
else:
... # IPython terminal interface |
|
@cbrnr can you rebase this and compose a note for the what's new? |
|
Sure, but many tests need to be fixed and I don't know if I have the time to do that. I guess this change should be added to the API changes section? |
|
@cbrnr this would need its own sub-section in API yes would need to fix any tests. |
|
Many tests rely on calling |
nothing to do with that issue |
|
OK, I've fixed almost all tests. Only 2 tests still fail, but I'm not sure if these failures are related to my changes:
Here's the complete test output: Any ideas? |
|
OK cool, so let's wait if CIs come back happy (except for these 2 timezone-related ones). Could you help me with the whats_new entry (because we've agreed that this should be prominently visible)? Also, I hope that my changes to the tests are OK, I mostly set the values for |
|
whatsnew, make a new subsection. then put a screen shot of the before and one of the after. then it should read as if you are a user wanting to know whether this change will affect you (e.g. if you use ipython, the interpreter, etc). |
|
for 0.22 |
|
A new subsection under "New features"? It's not really a new feature, but it doesn't fit into the other categories either. |
|
under api breaking changes |
Codecov Report
@@ Coverage Diff @@
## master #17023 +/- ##
==========================================
- Coverage 91.42% 91.38% -0.05%
==========================================
Files 163 163
Lines 50068 50071 +3
==========================================
- Hits 45776 45755 -21
- Misses 4292 4316 +24
Continue to review full report at Codecov.
|

Codecov Report
@@ Coverage Diff @@
## master #17023 +/- ##
==========================================
+ Coverage 91.82% 91.84% +0.01%
==========================================
Files 152 152
Lines 49235 49245 +10
==========================================
+ Hits 45212 45230 +18
+ Misses 4023 4015 -8
Continue to review full report at Codecov.
|

I think you need to add |
|
Regarding the deleted images (that I locally moved to |
|
@cbrnr you need to add them by force ( |
We could also decide to move our actual images somewhere else, to not have this confusion, but that's for another PR. |
|
Got it, the images are back. |
|
What do you mean with adding |
Yes. You can always check if the images are included in the output with |
|
Nice, thanks! Images are now correctly embedded. |
|
I think I already asked that, but is it possible to see the HTML docs built by a CI service? I know that other projects use CircleCI for this purpose (so that it is not necessary to set up everything locally). |
No, it is currently not possible. Open issue about this: #17921 |
doc/source/whatsnew/v0.23.0.txt
Outdated
|
|
||
| pd.options.display.max_columns = 20 | ||
|
|
||
| .. _whatsnew_0230.api: |
There was a problem hiding this comment.
I think this one sneaked in due to merge conflict? (anyhow it can be removed)
There was a problem hiding this comment.
I'm sorry, what do you mean?
There was a problem hiding this comment.
According to the diff, you added this line. But this should not be added (therefore I assumed you added it by accident while updating against master with rebasing/merging). But so you can just remove this line.
There was a problem hiding this comment.
You mean line 690 (.. _whatsnew_0230.api:)?
There was a problem hiding this comment.
yes, that's the line on which I commented. There is no header following for which that link would make sense (there is actually already another link label on line 692)
There was a problem hiding this comment.
I thought there should be a section header before introducing the subsections. At least that's how it is done with .. _whatsnew_0230.api_breaking: in line 350 (but there is a heading after that). In any case, I'm happy to delete it.
There was a problem hiding this comment.
Yes, that is correct. But I don't understand the relation with this line? This link is just floating with no section or subsection header following it. You already have a header with link at line 661 - 664 ?
There was a problem hiding this comment.
It's for the section below:
.. _whatsnew_0230.api:
.. _whatsnew_0230.api.datetimelike:
Datetimelike API Changes
^^^^^^^^^^^^^^^^^^^^^^^^
There was a problem hiding this comment.
But that header already has the "whatsnew_0230.api.datetimelike" label, it does not need two labels.
|
Hello @cbrnr! Thanks for updating the PR.
|
pandas/io/formats/format.py
Outdated
| @@ -625,7 +625,7 @@ def to_string(self): | |||
| max_len += size_tr_col # Need to make space for largest row | |||
| # plus truncate dot col | |||
| dif = max_len - self.w | |||
| adj_dif = dif | |||
| adj_dif = dif + 1 # see GH PR #17023 | |||
There was a problem hiding this comment.
can you put it on the line above?
There was a problem hiding this comment.
You mean
dif = max_len - self.w # see GH PR #17023
adj_dif = dif
?
dif is never used so we might as well skip it completely.
There was a problem hiding this comment.
No, I just meant to put the comment on its own line, not on the same line after the code, like
# '+ 1' to avoid too wide repr (GH PR #17023)
adj_dif = dif + 1
There was a problem hiding this comment.
I'm sorry, of course, I'll change that.
|
@cbrnr Thanks a lot for this (and for your patience getting this merged :)) |
Change `max_columns` to `0` (automatically adapt the number of displayed columns to the actual terminal width)
Change `max_columns` to `0` (automatically adapt the number of displayed columns to the actual terminal width)
Change `max_columns` to `0` (automatically adapt the number of displayed columns to the actual terminal width)
Update: Remove everything related to
max_rowsand only deal withmax_columnsin this PR.Changed
max_columnsto0(automatically adapt the number of displayed columns to the actual terminal width) when run in a terminaland.max_rowsto20(because I'd like to see the "whole" data frame at a glance like in R's tibble)git diff upstream/master -u -- "*.py" | flake8 --diff