Bug 1850057: Use bfq scheduler on control plane, idle I/O for rpm-ostreed #1957
Conversation
67dced6 to
9a9e6f2
Compare
|
@cgwalters: This pull request references Bugzilla bug 1852047, which is valid. The bug has been updated to refer to the pull request using the external bug tracker. 3 validation(s) were run on this bug
In response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
|
/cc @fabianofranz @hexfusion |
9a9e6f2 to
0e15813
Compare
|
I rolled in #1962 to this PR because I really want to be able to see the effect of the change by looking at events. |
566f5bc to
d6e210c
Compare
|
Rebased 🏄♂️ |
|
OK looking at some Prometheus queries mentioned in #1897 - this does seem to help. I see lower p99 and p999 spikes in etcd fsync latency, as expected. Staging an update took maybe 10s before, would now become 30s or more, but that's obviously totally fine. I've mostly done investigation with the larger PR that also prefers etcd followers, but I haven't done a huge amount of investigation as to how much of a difference that makes. I lean towards getting this one in at least relatively soon and get more data from all of the PR jobs and periodics. |
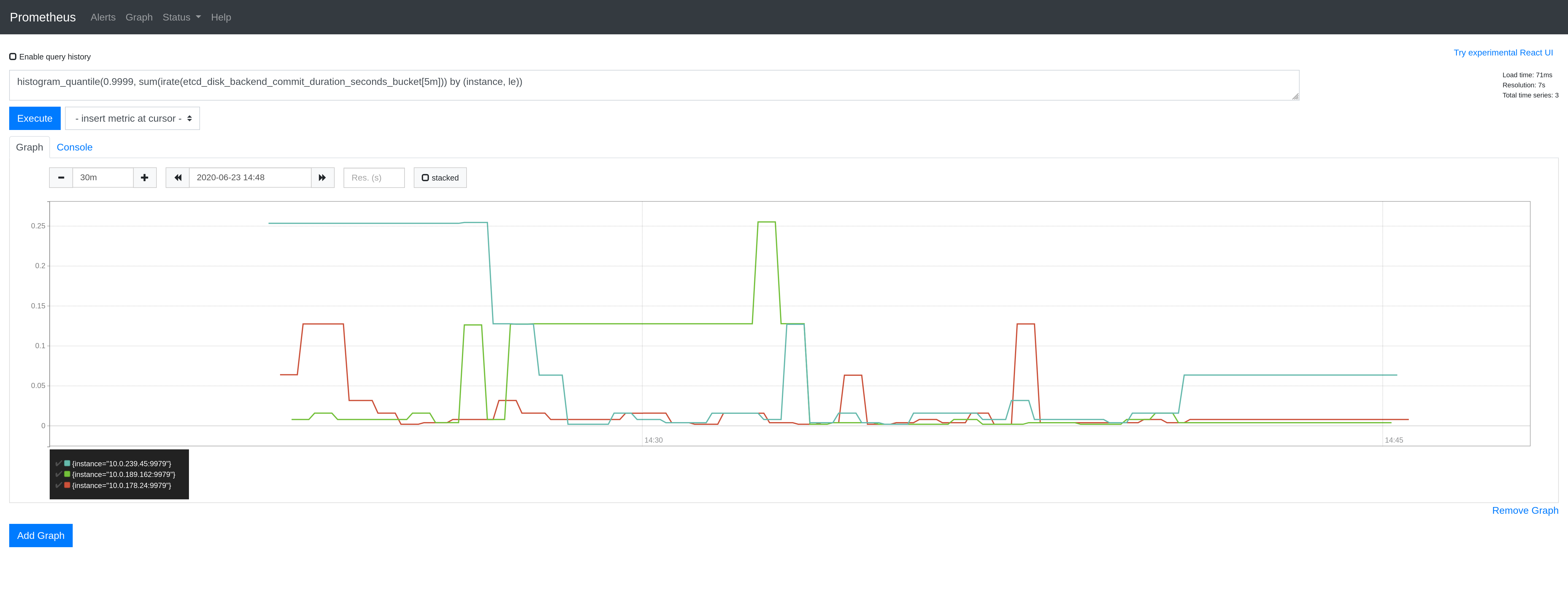{kind=link}
.png){kind=link}
|
Though, most test runs won't produce interesting data around this until we change the default |
|
I did a very basic test of bfq that was inconclusive. One thing with ionice I was under the impression was it was only honored with cc @cgwalters
|
|
@cgwalters's testing seems to be making the claim that with |
The man page is out of date, see the BFQ docs which talk about using this, and see also the actual code: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/block/bfq-iosched.c#n4988 |
9bb0b40 to
3c7d716
Compare
|
Previously I'd been trying to add information in the PRs but I found I really wanted to write scripts and track nontrivial data there. I ended up creating a "workboard" repo which has a subdirectory for this: https://github.com/cgwalters/workboard/tree/master/openshift/bz1850057-etcd-osupdate I'm increasingly confident that this is a good fix - comparing some metrics before after proves out that we are seeing much better p999 latency for example. Please see the bottom half of this file: https://github.com/cgwalters/workboard/blob/master/openshift/bz1850057-etcd-osupdate/bz185007.md |
|
@sinnykumari @yuqi-zhang @kikisdeliveryservice @ericavonb PTAL (and the linked internal Slack thread) |
Part of solving openshift#1897 A lot more details in https://hackmd.io/WeqiDWMAQP2sNtuPRul9QA The TL;DR is that the `bfq` I/O scheduler better respects IO priorities, and also does a better job of handling latency sensitive processes like `etcd` versus bulk/background I/O .
We switched rpm-ostree to do this when applying updates, but it also makes sense to do when extracting the oscontainer. Part of: openshift#1897 Which is about staging OS updates more nicely when etcd is running.
3c7d716 to
45b599e
Compare
|
OK rebased this, dropping out #1962 since it's not strictly necessary even though I'd really like to get that one in too. I think we have good enough results to ship this! |
|
@cgwalters: This pull request references Bugzilla bug 1850057, which is valid. The bug has been moved to the POST state. The bug has been updated to refer to the pull request using the external bug tracker. 3 validation(s) were run on this bug
In response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
|
We seem to have used a BZ clone originally accidentally, switching to use the main one. |
|
https://github.com/cgwalters/workboard/tree/master/openshift/bz1850057-etcd-osupdate is now updated with some screenshots as well as links to more Prow jobs you can use for your own inspection (and to launch clusters). For example: |
{kind=link}
{kind=link}
|
What's interesting is the before/after between (That said I do think the effect here could be much more pronounced in clusters that are running a real workload too) |
|
/test e2e-gcp-upgrade |
If we feel that's critical we could work with the perf-scale team to replicate their 250 node 4000 namespace + $bignum pod workload upgrade tests where we could readily reproduce this problem. level of effort for that is measured in days though. |
| // updateOstreeObjectSync enables "per-object-fsync" which helps avoid | ||
| // latency spikes for etcd; see https://github.com/ostreedev/ostree/pull/2152 | ||
| func updateOstreeObjectSync() error { | ||
| if err := exec.Command("ostree", "--repo=/sysroot/ostree/repo", "config", "set", "core.per-object-fsync", "true").Run(); err != nil { |
There was a problem hiding this comment.
question: do you think ionice or the above has the most dramatic effect on reducing latency?
There was a problem hiding this comment.
If you think it's important enough I can try to make new release images with just this change and not the bfq default. But to answer your question, both do matter, see:
There was a problem hiding this comment.
I don't think it's important enough to change anything I am just curious. You have done enough work :)
I don't think we actually need 250 real nodes, just a simulated workload hitting the apiserver/etcd right? |
|
this is amazing work, thank you very much for the high level of effort and professionalism in seeing this through for 4.6. LGTM! |
|
All green here on the core jobs, just needs a lgtm. |
| // and other processes. See | ||
| // https://github.com/openshift/machine-config-operator/issues/1897 | ||
| // Note this is the current systemd default in Fedora, but not RHEL8, | ||
| // except for NVMe devices. |
There was a problem hiding this comment.
So why wouldn't we do this for all root devices on all nodes in the cluster?
There was a problem hiding this comment.
Mostly to limit the "blast radius" of this PR - changing the control plane only minimizes risk. But, it does also mean more divergence.
It probably does make sense to do an across-the-board switch though...maybe as a followup to this? Or would you rather do it in one go?
There was a problem hiding this comment.
The other aspect is that currently the OS update vs etcd happens because we're updating the OS while etcd is still running - that only matters on the control plane. For regular worker nodes that don't have static pods, everything will have been drained before we start the update - so there's less need for bfq inherently.
(Long term I think we really want cgroups v2 + a filesystem that honors IO priorities - it's the only way to get real balance, bfq is mostly heuristics + support for baseline io priorities)
There was a problem hiding this comment.
@sinnykumari @runcom @cgwalters @smarterclayton I would suggest to sync up with the perf-dept, there were some concerns regarding BFQ as the default scheduler in RHEL. There are several workloads where BFQ did not perform the best. MQ-deadline did better. There are probably more workloads that need to be strobed.
Even though BFQ is great on the low end, past experience shows it doesn't do as well on the high end. It would need to be thoroughly tested if RHCOS considered changing it. See http://post-office.corp.redhat.com/archives/kscale-list/2019-September/msg00010.html
There was a problem hiding this comment.
The BFQ may work great for the control-plane where we're only running "one" workload (etcd), on the worker nodes we have a variety of workloads that may or not benefit from BFQ. Would also be interesting to see how the infra pods are reacting to such a change.
There was a problem hiding this comment.
Thank you for raising the concern. This PR uses BFQ only for control plane nodes. We will keep in mind and make sure to talk to perf team if we plan to use BFQ for worker/custom pools.
|
[APPROVALNOTIFIER] This PR is APPROVED This pull-request has been approved by: cgwalters, sinnykumari The full list of commands accepted by this bot can be found here. The pull request process is described here
Needs approval from an approver in each of these files:
Approvers can indicate their approval by writing |
|
/retest Please review the full test history for this PR and help us cut down flakes. |
2 similar comments
|
/retest Please review the full test history for this PR and help us cut down flakes. |
|
/retest Please review the full test history for this PR and help us cut down flakes. |
|
@cgwalters: The following tests failed, say
Full PR test history. Your PR dashboard. Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. I understand the commands that are listed here. |
|
/retest Please review the full test history for this PR and help us cut down flakes. |
|
@cgwalters: Some pull requests linked via external trackers have merged: The following pull requests linked via external trackers have not merged: These pull request must merge or be unlinked from the Bugzilla bug in order for it to move to the next state. Bugzilla bug 1850057 has not been moved to the MODIFIED state. In response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
|
+1 this is a big win, thanks @cgwalters! |
Part of solving #1897
A lot more details in https://hackmd.io/WeqiDWMAQP2sNtuPRul9QA
The TL;DR is that the
bfqI/O scheduler better respects IO priorities,and also does a better job of handling latency sensitive processes
like
etcdversus bulk/background I/O .