Add sdpa and fa2 the Wav2vec2 family. #30121
Conversation
Co-authored-by: kamilakesbi <kamil@huggingface.co> Co-authored-by: jp1924 <jp42maru@gmail.com>
|
The docs for this PR live here. All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. |
|
@kamilakesbi |
|
Hey @jp1924 - thanks for your enthusiasm over this feature! It looks like this PR is close to completion, with @kamilakesbi having marked you as a co-author to give you credit for your initial efforts 🤗 Would you like to review this PR in conjunction with myself to complete the integration? |
|
Sure! I'm new to co-authored-by and didn't know what that meant, so thanks for clearing that up! |
There was a problem hiding this comment.
Code changes for Wav2Vec2 look good! A few TODOs before we merge this PR:
- Update the slow test to confirm the batch inputs give correctness with an attention mask
- Propagate the changes made to Wav2Vec2 to other models in the library: models like HuBERT get a non-negligible amount of usage (a few hundred thousand downloads per month). It would be good to add support for SDPA and FA2 for all the Wav2Vec2-derived models as well in this PR, such that they get this new feature and code for these models are sync'd properly with the
Copied frommechanism. No need to add any additional slow tests - if we confirm Wav2Vec2 is correct, and assume that the other models copy from Wav2Vec2, then we can be pretty confident these models are correct as well
Co-authored-by: Sanchit Gandhi <93869735+sanchit-gandhi@users.noreply.github.com>
|
Hey @amyeroberts! Would appreciate a final review here when you get the chance - should be a pretty fast PR to review since we leverage lots of |
There was a problem hiding this comment.
Thanks for working on this! Overall looks very clean
Three main comments:
- All the models should have FA2 and SDPA tests added to make sure the values are similar to their eager equivalents
- All the models should have FA2 and SDPA info added to the model pages, including an expected expeced performance graph e.g. like here
- Some comments in-line about managing the copied from comments
| @@ -478,6 +498,335 @@ def forward( | |||
| return attn_output, attn_weights_reshaped, past_key_value | |||
|
|
|||
|
|
|||
| # Copied from transformers.models.bart.modeling_bart.BartFlashAttention2 with Bart->Data2VecAudio | |||
There was a problem hiding this comment.
Why use the copied from for BART here when most of the important logic is copied from Llama? I'd advise removing this top-level copied from header and just having # copied from for each of the respective methods
There was a problem hiding this comment.
Note that the attention module in Wav2Vec2 is one-to-one the same as BART (self-attn and cross-attn), but inherently different from LLaMA (self-attn only). Therefore, we copy the main attention class from BART, and only override the FA2 forward method from LLaMA. This is consistent with how we implement FA2 in Whisper:
transformers/src/transformers/models/whisper/modeling_whisper.py
Lines 398 to 399 in 60dea59
I would be in favour of maintaining consistency with both Whisper, and the non-FA2 attention class, where we copy from BART and only override the specific FA2 methods that come from LLaMA.
There was a problem hiding this comment.
OK - let's keep things consistent!
| @@ -536,6 +562,335 @@ def forward( | |||
| return attn_output, attn_weights_reshaped, past_key_value | |||
|
|
|||
|
|
|||
| # Copied from transformers.models.bart.modeling_bart.BartFlashAttention2 with Bart->SEW | |||
There was a problem hiding this comment.
Same comment here and for the rest of the models - let's just use a copied from per method
There was a problem hiding this comment.
There should be FA2 integration tests added for all the models
There was a problem hiding this comment.
The remainder of the models have one-to-one the same attention architecture as Wav2Vec2 and each have super low usage. We can add FA2 integration tests, but this seems like an unnecessary burden on the CI?
When we added FA2 for BART and it's derived models, we only added integration tests for the most used models, in this case Whisper: https://github.com/huggingface/transformers/pull/27203/files
I'd be happy to do the same here and only perform the slow integration tests for the most important checkpoint, in this case Wav2Vec2.
There was a problem hiding this comment.
OK - if the models aren't used much then let's leave it!
|
That's a great point regarding the model docs @amyeroberts - would you like to run a quick benchmark for Wav2Vec2 and HuBERT @kamilakesbi and subsequently update the respective model docs? You can use the following code snippet as a starting pointNote that you will need to update the AutoModel class to the correct CTC one, and update the normalisation logic to just lower-case the transcriptions (since CTC doesn't predict punctuation anyway). from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from datasets import load_dataset
from evaluate import load
import torch
from tqdm import tqdm
# define our torch configuration
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
# load the model + processor
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, use_safetensors=True, low_cpu_mem_usage=True)
model = model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
# load the dataset with streaming mode
dataset = load_dataset("librispeech_asr", "clean", split="validation")
# define the evaluation metric
wer_metric = load("wer")
def inference(batch):
# 1. Pre-process the audio data to log-mel spectrogram inputs
audio = [sample["array"] for sample in batch["audio"]]
input_features = processor(audio, sampling_rate=batch["audio"][0]["sampling_rate"], return_tensors="pt").input_features
input_features = input_features.to(device, dtype=torch_dtype)
# 2. Auto-regressively generate the predicted token ids
pred_ids = model.generate(input_features, max_new_tokens=128)
# 3. Decode the token ids to the final transcription
batch["transcription"] = processor.batch_decode(pred_ids, skip_special_tokens=True)
batch["reference"] = batch["text"]
return batch
# batch size 16 inference
dataset = dataset.map(function=inference, batched=True, batch_size=16)
# normalize predictions and references
all_transcriptions = [processor.normalize(transcription) for transcription in dataset["transcription"]]
all_references = [processor.normalize(reference) for reference in dataset["reference"]]
# compute the WER metric
wer = 100 * wer_metric.compute(predictions=all_transcriptions, references=all_references)
print(wer) |
…s into sdpa_fa2_wav2vec
|
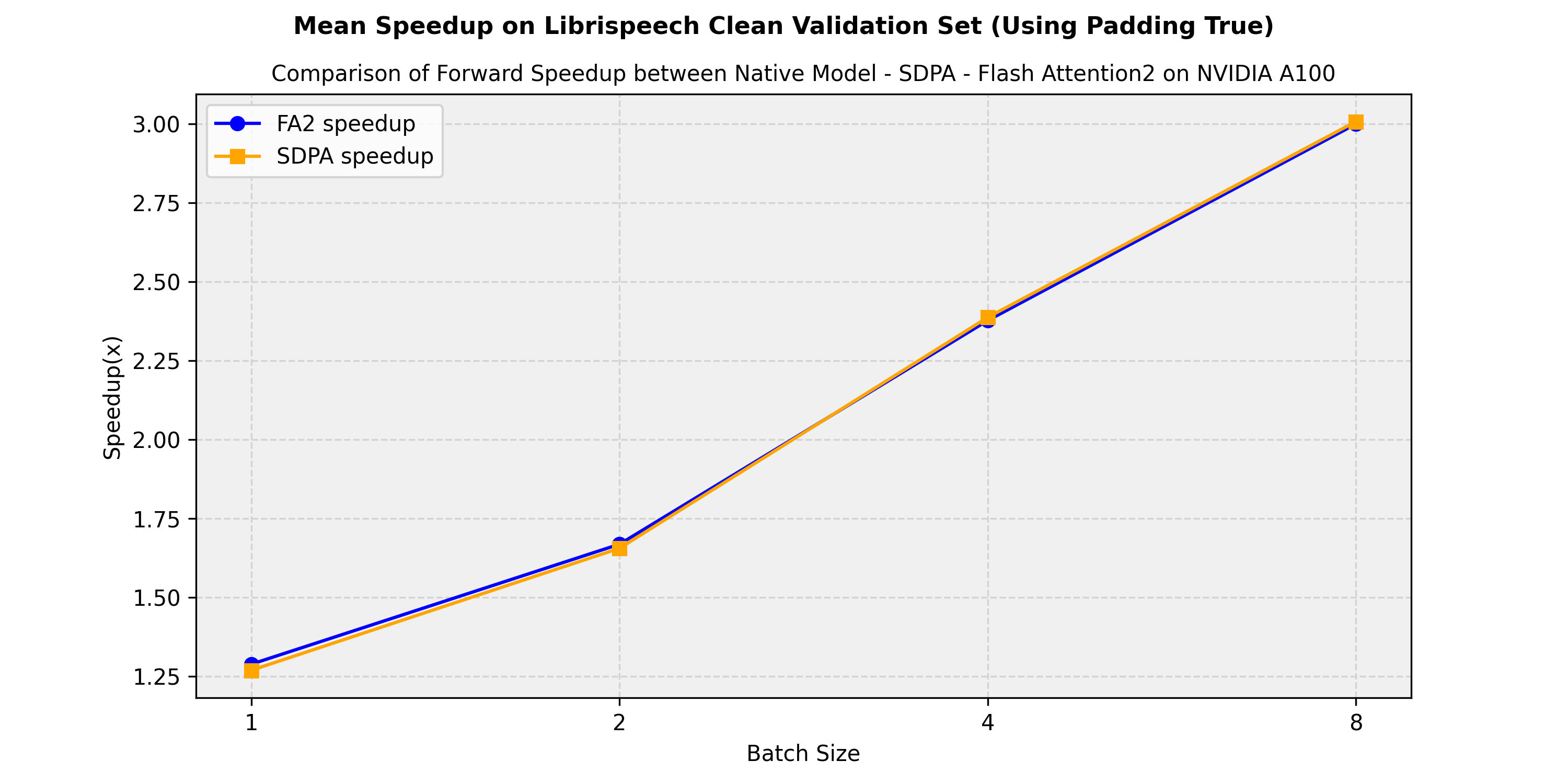
I've run a quick benchmark on both Wav2Vec2 and Hubert and updated the doc. I think we can merge this PR @amyeroberts if you validate the plots :) |
{kind=link}
{kind=link}
Co-authored-by: @kamilakesbi kamil@huggingface.co
Co-authored-by: @jp1924 jp42maru@gmail.com
What does this PR do?
This PR aims at solving issue #30073 by adding SPDA and Flash Attention 2 to the Wav2Vec2 modelling code.
@jp1924 has already done most of the necessary changes here. Based on his code, I added SDPA and made sure it passed
make fixupand updated the documentation.Next steps:
Who can review?
cc @sanchit-gandhi