{kind=link}
The final project for Stepic course Huawei Natural Language Processing.
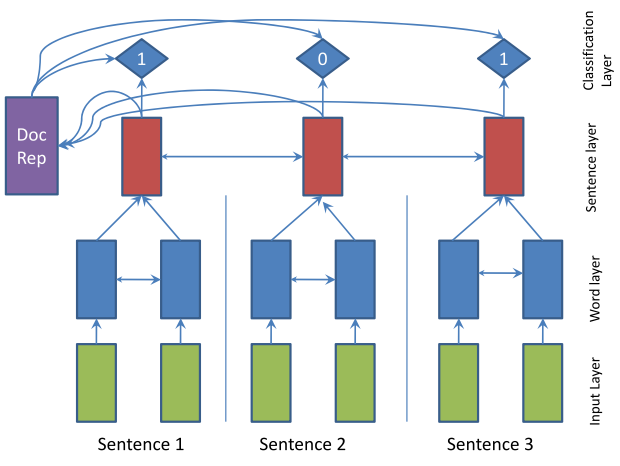
a) What is the problem you are trying to solve? Why it is important?
The prior task is trying to generate news header by it text, where original header can be used as target and original text used as train data. Success solution can be used for "shortization" long texts whithout loosing general line of story. We want to try and compare two types of summarization, extractive and abstract.
b) What are the existing solutions for this problem? If the problem is new, describe the solutions of the most relevant problems to yours.
For extractive summarization we refer to SummaRuNNer: A Recurrent Neural Network based Sequence Model by Nallapati et al (original paper: https://arxiv.org/pdf/1611.04230.pdf). For abstract summarization we search next solutions: At the fist is solution by Gavrilov, D., Kalaidin, P., Malykh, V.: Self-Attentive Model for Headline Generation. The second is VKcom competition 2019 "Headline generation track". We expect to find some good baseline ideas here. And the final is Ilya Gusev model https://github.com/IlyaGusev/summarus
c) What is the data you will be working with? Is it an already released dataset? If so, please provide a description and a link to it. If it is a new one, please describe your methodology to collect the dataset.
We would use self collected dataset of texts from website of Rossiyskaya Gazeta. Licens agreements permits collecting, copying and saving data from this sites for personal non-commersial uses by Russian citizens. Metodology to collect the dataset is self-designed parser through C# and AngleSharp library. Raw HTML -> JSON dataset.
d) What is your team? If there is more than one person, please provide provision responsibilities for all people.
Kotyukov Alexander (github @kotyukov): design parser, dataset collecting, summarization model
German Abramov (github @germanjke): dataset cleaning, summarization model
e) How are you going to solve the described problem? What are the differences from the baselines you are comparing with. Please do include a link to a repository where you are going to keep solution's code and data in case you are collecting the dataset.
For baseline extractive summarization we use ideas from original notebook MIPT NLP course by Ilya Gusev: Oracle model, RNN model. For abstract summarization: is coming.
We collected several news texts from website of Rossiyskaya Gazeta. Licens agreements permits collecting, copying and saving data from this site for personal non-commersial uses by Russian citizens. Metodology to collect the dataset is self-designed parser through C# and AngleSharp library. Raw HTML -> JSON dataset.
The first version of dataset include 44014 lines and 18 columns:
RangeIndex: 44014 entries, 0 to 44013 Data columns (total 18 columns):
| # | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 0 | Article_id | 44014 non-null | int64 |
| 1 | Url | 44014 non-null | object |
| 2 | Date_time | 43771 non-null | object |
| 3 | Day | 43060 non-null | object |
| 4 | Time | 43045 non-null | object |
| 5 | Image_source | 34518 non-null | object |
| 6 | Image_url | 34518 non-null | object |
| 7 | Related_topics | 43850 non-null | object |
| 8 | Related_organizations | 30899 non-null | object |
| 9 | Related_regions | 10061 non-null | object |
| 10 | Head_rubric | 42418 non-null | object |
| 11 | Alt_title | 44013 non-null | object |
| 12 | Head_title | 43965 non-null | object |
| 13 | Head_subtitle | 12497 non-null | object |
| 14 | Text | 43984 non-null | object |
| 15 | Announce | 44012 non-null | object |
| 16 | Keywords | 43773 non-null | object |
| 17 | Authors | 43771 non-null | object |
dtypes: int64(1), object(17)
The second version of dataset is divided into 7 parts:
| # | Name | Head rubric |
|---|---|---|
| 1 | RG01.json | Культура (Culture) |
| 2 | RG02.json | Спорт (Sports) |
| 3 | RG03.json | Общество (Society) |
| 4 | RG04.json | Происшествия (Incidents) |
| 5 | RG05.json | В мире (In the world) |
| 6 | RG06.json | Экономика (Economics) |
| 7 | RG07.json | Власть (Government) |
In total it's include 134010 lines and 9 columns:
| # | Columns | Dtype |
|---|---|---|
| 0 | Article_id | int64 |
| 1 | Url | object |
| 2 | Date_time | object |
| 3 | Head_rubric | object |
| 4 | Head_title | object |
| 5 | Head_subtitle | object |
| 6 | Text | object |
| 7 | Keywords | object |
| 8 | Authors | object |
NOTE: both dataset was collected for different tasks, in addition to differences in structure, they include different data. The first one include news only from site headpage from 2012 to the present day (44014 news). And the second one include news from site rubrics pages from summer 2019 to present days (134010 news). Both datasets include a small number of duplicated news (no more than a couple of hundred).