cmd, core, eth, les, node: chain freezer on top of db rework #19244
Conversation
core/rawdb/accessors_chain.go
Outdated
| @@ -51,6 +54,24 @@ func DeleteCanonicalHash(db ethdb.Deleter, number uint64) { | |||
| } | |||
| } | |||
|
|
|||
| // readAllHashes retrieves all the hashes assigned to blocks at a certain heights, | |||
There was a problem hiding this comment.
| // readAllHashes retrieves all the hashes assigned to blocks at a certain heights, | |
| // readAllHashes retrieves all the hashes assigned to blocks at certain heights, |
core/rawdb/database.go
Outdated
| @@ -22,10 +22,44 @@ import ( | |||
| "github.com/ethereum/go-ethereum/ethdb/memorydb" | |||
| ) | |||
|
|
|||
| // freezerdb is a databse wrapper that enabled freezer data retrievals. | |||
There was a problem hiding this comment.
| // freezerdb is a databse wrapper that enabled freezer data retrievals. | |
| // freezerdb is a databse wrapper that enables freezer data retrievals. |
core/rawdb/freezer.go
Outdated
| // freezerBlockGraduation is the number of confirmations a block must achieve | ||
| // before it becomes elligible for chain freezing. This must exceed any chain | ||
| // reorg depth, since the freezer also deletes all block siblings. | ||
| freezerBlockGraduation = 60000 |
There was a problem hiding this comment.
Consider making this a variable that is passed into the freezer so that its value can correspond to eth/downloader/MaxForkAncestry in some way.
core/rawdb/freezer.go
Outdated
| freezer := &freezer{ | ||
| tables: make(map[string]*freezerTable), | ||
| } | ||
| for _, name := range []string{"hashes", "headers", "bodies", "receipts", "diffs"} { |
There was a problem hiding this comment.
Nit: IMHO "diffs" is an overloaded terminology. I would have used tds.
core/rawdb/freezer.go
Outdated
| // reserving it for go-ethereum. This would also reduce the memory requirements | ||
| // of Geth, and thus also GC overhead. | ||
| type freezer struct { | ||
| tables map[string]*freezerTable // Data tables for storing everything |
There was a problem hiding this comment.
I understand that using a map for the freezerTable adds some niceties like being able to iterate across the tables. However, I would consider making each freezer table an explicit member of the struct. It makes it immediately clear what the freezer is storing without having to look at newFreezer.
core/rawdb/freezer.go
Outdated
| } | ||
| freezer.tables[name] = table | ||
| } | ||
| // Truncate all data tables to the same length |
There was a problem hiding this comment.
Just giving my two wei: a method called truncateAllTableToEqualLength would remove this comment and decrease the cognitive load to know what the remaining code is doing.
There was a problem hiding this comment.
loving your usage of my two wei 👍
| freezerBatchLimit = 30000 | ||
| ) | ||
|
|
||
| // freezer is an memory mapped append-only database to store immutable chain data |
There was a problem hiding this comment.
Can you point me to where the memory mapping is happening? My understanding is that os.File is not guaranteed to be memory-mapped as its left up to the OS.
core/rawdb/freezer.go
Outdated
| return nil | ||
| } | ||
|
|
||
| // Ancient retrieves an ancient binary blob from the append-only immutable files. |
There was a problem hiding this comment.
It seems like the kind is around because each table is not coupled to the data it stores. This could be changed if it was placed within the ChainDB proposed in #19200 (as discussed previously).
| "github.com/ethereum/go-ethereum/common" | ||
| "github.com/ethereum/go-ethereum/log" | ||
| "github.com/ethereum/go-ethereum/metrics" | ||
| "github.com/golang/snappy" |
There was a problem hiding this comment.
Has there been any benchmarking to determine if snappy compression is helpful (e.g. low overhead, high data savings)? Perhaps it is useful for bodies and receipts (and headers?), but may not do much for the other pieces of data.
Have you considered making this an optional parameter for each freezerTable instance?
There was a problem hiding this comment.
From an earlier test
16 blocks.
- as one binary file, uncompressed
332K,compressed254K. - As 16 indivudually compressed files,
257K
Afaik, we haven't tested that on headers

There was a problem hiding this comment.
Though we cut off a lot of redundant data from the receipts, so I expect snappy to be less effective since the charts were plotted.
There was a problem hiding this comment.
Storage-wise it seems worthwhile. Is the decompression overhead for reads something to consider?
core/rawdb/freezer.go
Outdated
| for { | ||
| // Retrieve the freezing threshold. In theory we're interested only in full | ||
| // blocks post-sync, but that would keep the live database enormous during | ||
| // dast sync. By picking the fast block, we still get to deep freeze all the |
core/rawdb/freezer.go
Outdated
| } | ||
| // Inject all the components into the relevant data tables | ||
| if err := f.tables["hashes"].Append(f.frozen, hash[:]); err != nil { | ||
| log.Error("Failed to deep freeze hash", "number", f.frozen, "hash", hash, "err", err) |
There was a problem hiding this comment.
It seems like that if one of the subsequent freezerTable.Appends fails and then the import is retried (without reopening the freezer) then this will result in a panic since the entry will already have been written? Is that the failure model you want?
| if n := len(ancients); n > 0 { | ||
| context = append(context, []interface{}{"hash", ancients[n-1]}...) | ||
| } | ||
| log.Info("Deep froze chain segment", context...) |
There was a problem hiding this comment.
This is another example of something I would have extracted out to not distract from the core functionality in this method.
There was a problem hiding this comment.
Left a few comments. They really center around two points:
(1) Using atomic within code regions that are already guarded by locks
(2) File handle management. It seems like the freezer will have quite a few file handles open across the tables being used, which may compete with LevelDB's handle budget without being careful (which I know you are well aware of since you raised the point to me a while back)
| errOutOfBounds = errors.New("out of bounds") | ||
| ) | ||
|
|
||
| // indexEntry contains the number/id of the file that the data resides in, aswell as the |
| offset uint32 // stored as uint32 ( 4 bytes) | ||
| } | ||
|
|
||
| const indexEntrySize = 6 |
There was a problem hiding this comment.
Nit: move const to the top of the file
There was a problem hiding this comment.
Whilst I generally agree with that, this number depends on the above type declaration. Moving it elsewhere would give the false sense that it can be modified freely.
| // offset within the file to the end of the data | ||
| // In serialized form, the filenum is stored as uint16. | ||
| type indexEntry struct { | ||
| filenum uint32 // stored as uint16 ( 2 bytes) |
There was a problem hiding this comment.
Is the index's storage footprint such a concern that you have to use uint[16|32] instead of uint64? Using uint64 seems simpler, consistent with the BlockChain API, and is the common word size in modern processors. It just feels like an additional piece of context to remember without having any substantial impact on a running system.
There was a problem hiding this comment.
In-memory wise it doesn't matter tbh, it could even be a plain int. On-disk storage wise we know it won't ever exceed uint16, so no point in wasting more disk space on zeroes.
There was a problem hiding this comment.
I hear you. Just figured I would point it out.
core/rawdb/freezer_table.go
Outdated
|
|
||
| // newTable opens a freezer table with default settings - 2G files and snappy compression | ||
| func newTable(path string, name string, readMeter metrics.Meter, writeMeter metrics.Meter) (*freezerTable, error) { | ||
| return newCustomTable(path, name, readMeter, writeMeter, 2*1000*1000*1000, false) |
There was a problem hiding this comment.
Nit: Consider making this a constant. Also should this be 2 * 1024 * 1024 * 1024?
There was a problem hiding this comment.
Yeah, I did wonder about this. I think I'd go with your suggestion.
There was a problem hiding this comment.
We just need to take extra care not to ever overflow it, since many file systems + 32bit architectures are hard limited to that number.
There was a problem hiding this comment.
Ah, scratch 32 bit arch, that should handle 4GB (or 3 in case of windows, lol).
| t.releaseFilesAfter(0, false) | ||
| // Open all except head in RDONLY | ||
| for i := uint32(0); i < t.headId; i++ { | ||
| if _, err = t.openFile(i, os.O_RDONLY); err != nil { |
There was a problem hiding this comment.
Are there any issues with file handler management here? The scenario I'm imagining is when multiple tables each have a bunch of files open (and LevelDB is also active).
There was a problem hiding this comment.
The current historical chain is about 80GB in size, so that's +- 40 fds. These will probably be opened either way if someone syncs from us. I think 40 is safe, but if we grow we probably want to eventually add fd management. That seems an overcomplication at this point however.
There was a problem hiding this comment.
Agree. I was just asking to serve as a sanity check.
| t.lock.Lock() | ||
| defer t.lock.Unlock() | ||
| // If out item count is corrent, don't do anything | ||
| if atomic.LoadUint64(&t.items) <= items { |
There was a problem hiding this comment.
Is the atomic.LoadUint64 needed here if the write lock has already been acquired?
There was a problem hiding this comment.
The locking mechanism was designed to allow reading and appending to be concurrently runable (since append is just pushes some data that readers are unaware of, and at the very end bumps the item count, making it available).
If append does not write lock, just uses atomic, then this write lock here doesn't protect the items counter. Append will only obtain a write lock if it needs to switch to a new file. That said, Append and Truncate may not really be safe to use concurrently, as they might race on what the final value of items should be.
There was a problem hiding this comment.
If it were me I would be more conservative and lock more frequently -- especially for writes. I feel like any slow down would be negligible and it ensures the code is more safe. Just my two wei.
| } | ||
|
|
||
| // releaseFilesAfter closes all open files with a higher number, and optionally also deletes the files | ||
| func (t *freezerTable) releaseFilesAfter(num uint32, remove bool) { |
There was a problem hiding this comment.
Nit: I find the remove option to be misleading for a method about releasing. I would consider adding a second method that makes this more explicit. They can still use a common helper function.
| return errClosed | ||
| } | ||
| // Ensure only the next item can be written, nothing else | ||
| if atomic.LoadUint64(&t.items) != item { |
There was a problem hiding this comment.
Is the atomic.LoadUint64 necessary if you've already acquired a read lock?
There was a problem hiding this comment.
Yes, Append can run concurrently (since it doesn't change internals, just adds something to the end of the file and them atomically makrs it available).
bd9760b to
5810ffe
Compare
|
Nitpick to do: make data file numbers zero padded to 3 digits. TL;DR |
|
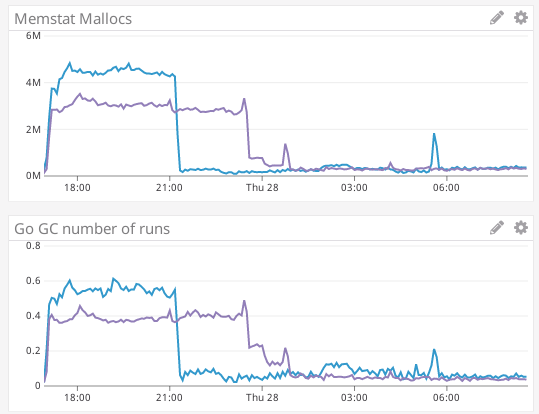
Here are some charts from the test with @rjl493456442 's changes that was run in fast-sync. This is the master. It has a very intense download of blocks/headers/state for about 4 hours, then a long drawn-out state download which takes roughly another 8 hours. For the experimental, it looks a bit different. It has an 'intense' download lasting six hours, followed by one hours of less intense download, and finishes the fast sync in a total of 7 hours. So 7 hours instead of 12. I'm not quite sure why. The malloc/gc overhead was more stable on experimental:
|


|
More stats on the data So the |
|
@holiman The results make sense to me. There is less pressure on LevelDB since it's now responsible for handling half the amount of data as before, which reduces its operation overhead (e.g. compaction). The LevelDB storage hierarchy is also organized by powers of 10, so going from ~150 GB to half that means that one less level is needed. |
|
Nonetheless it's probably worth running it a few times. I'm not sure the exact benchmark setup but if a different peer is being used for each sync then that could introduce some variation as well. |
|
Yeah - we did just that. We swapped the machines, wiped the node-ids and ran again. It's still running, but this time it looks like the |
|
So on the second run, they were roughly equal -- this PR making a fast sync in ~10h, the
OBS Since we switched machines, the colours are swapped in that ^ chart, this PR is the blue line. |

| @@ -367,9 +367,12 @@ func exportPreimages(ctx *cli.Context) error { | |||
|
|
|||
| func copyDb(ctx *cli.Context) error { | |||
| // Ensure we have a source chain directory to copy | |||
| if len(ctx.Args()) != 1 { | |||
| if len(ctx.Args()) < 1 { | |||
| utils.Fatalf("Source chaindata directory path argument missing") | |||
There was a problem hiding this comment.
| utils.Fatalf("Source chaindata directory path argument missing") | |
| utils.Fatalf("Source directory paths missing (chaindata and ancient)") |
| utils.Fatalf("Source chaindata directory path argument missing") | ||
| } | ||
| if len(ctx.Args()) < 2 { |
There was a problem hiding this comment.
Don't we by default put ancient inside the chain directory? Shouldn't we default to that here too?
There was a problem hiding this comment.
By default yes, but if we want to copydb from a database where the ancient is outside?
cmd/utils/flags.go
Outdated
| @@ -1569,7 +1576,7 @@ func MakeChainDatabase(ctx *cli.Context, stack *node.Node) ethdb.Database { | |||
| if ctx.GlobalString(SyncModeFlag.Name) == "light" { | |||
| name = "lightchaindata" | |||
| } | |||
| chainDb, err := stack.OpenDatabase(name, cache, handles, "") | |||
| chainDb, err := stack.OpenDatabaseWithFreezer(name, cache, handles, "", "") | |||
There was a problem hiding this comment.
Shouldn't you pass the cfg.DatabaseFreezer in here somehow?
core/blockchain.go
Outdated
| return i, fmt.Errorf("containing header #%d [%x…] unknown", block.Number(), block.Hash().Bytes()[:4]) | ||
| } | ||
| // Compute all the non-consensus fields of the receipts | ||
| if err := receiptChain[i].DeriveFields(bc.chainConfig, block.Hash(), block.NumberU64(), block.Transactions()); err != nil { |
There was a problem hiding this comment.
We don't need to derive the receipt fields here since they will be discarded during the RLP encoding anyway.
core/blockchain.go
Outdated
| continue | ||
| } | ||
| // Compute all the non-consensus fields of the receipts | ||
| if err := receiptChain[i].DeriveFields(bc.chainConfig, block.Hash(), block.NumberU64(), block.Transactions()); err != nil { |
There was a problem hiding this comment.
We don't need to derive the receipt fields here since they will be discarded during the RLP encoding anyway.
| t.lock.RLock() | ||
| } | ||
|
|
||
| defer t.lock.RUnlock() |
There was a problem hiding this comment.
The lock is used to protect map[uint32]*os.File as well as head and index file descriptor. Since os.File.Write is not thread safe, should we use Lock here instead of RLock?
There was a problem hiding this comment.
I think maybe we should add a freezer.md where we explain things like the concurrency assumptions and the data layout. To answer the question, I think No; we do not cater for multiple callers of Append, tha aim is to prevent concurrent calling of Append/Truncate.
eth/downloader/downloader.go
Outdated
| // feed us valid blocks until head. All of these blocks might be written into | ||
| // the ancient store, the safe region for freezer is not enough. | ||
| if d.checkpoint != 0 && d.checkpoint > MaxForkAncestry+1 { | ||
| d.ancientLimit = height - MaxForkAncestry - 1 |
There was a problem hiding this comment.
d.ancientLimit = height - MaxForkAncestry - 1 -> d.ancientLimit = d.checkpoint - MaxForkAncestry - 1
|
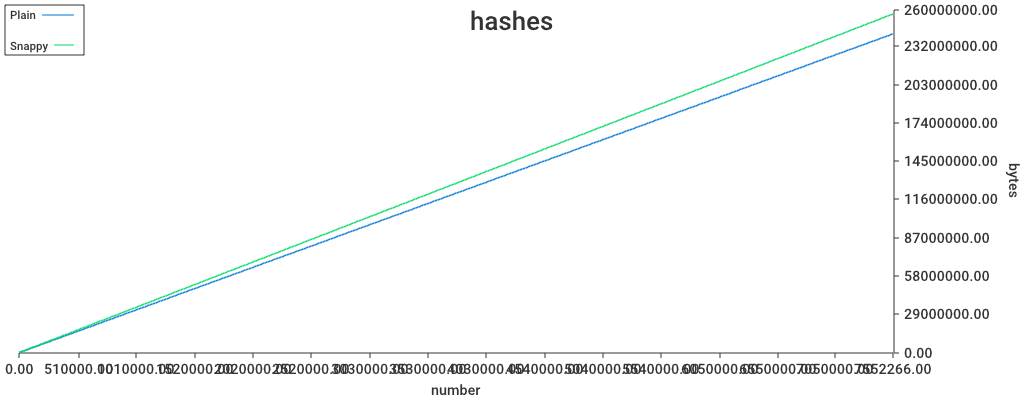
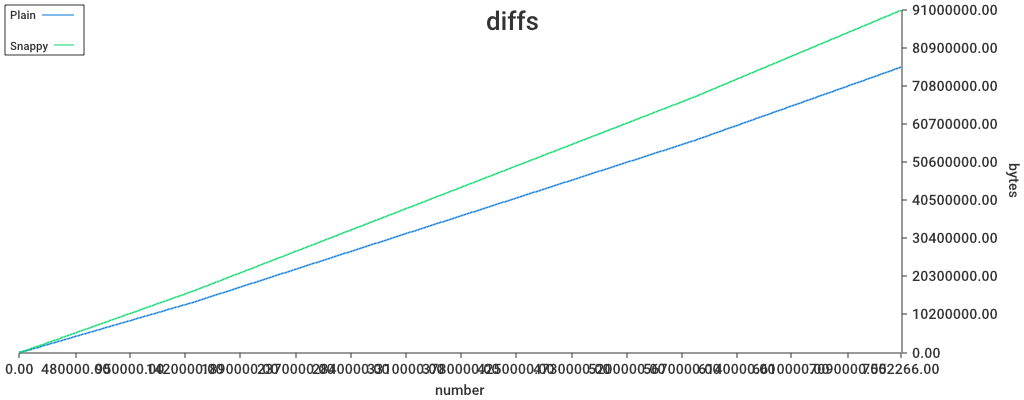
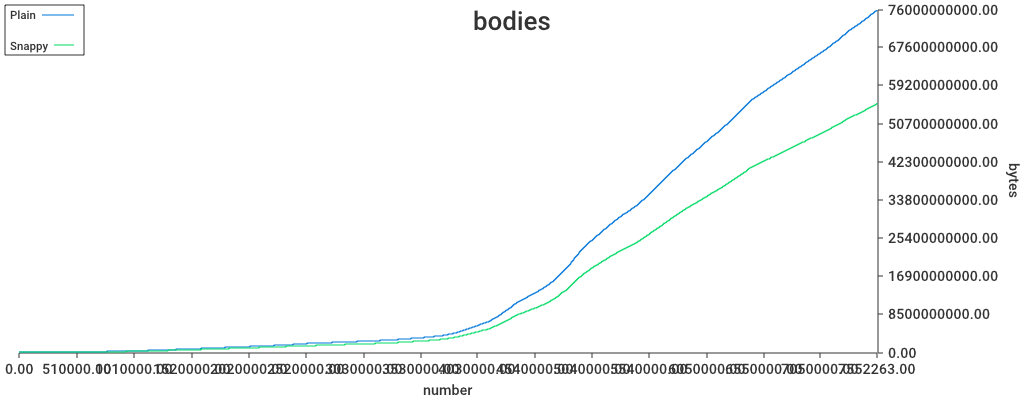
Data taken from Sorry for the crappyness of the labeling, but aside from that, in order of size:
Also, the index for each type is takes rougly |


core/blockchain.go
Outdated
| @@ -218,6 +219,39 @@ func NewBlockChain(db ethdb.Database, cacheConfig *CacheConfig, chainConfig *par | |||
| if err := bc.loadLastState(); err != nil { | |||
| return nil, err | |||
| } | |||
| if frozen, err := bc.db.Ancients(); err == nil && frozen >= 1 { | |||
There was a problem hiding this comment.
Nit: frozen > 0 is slightly clearer.
| rawdb.DeleteBody(db, hash, num) | ||
| rawdb.DeleteReceipts(db, hash, num) | ||
| } | ||
| // Todo(rjl493456442) txlookup, bloombits, etc |
There was a problem hiding this comment.
Nit: s/Todo/TODO (and possibly end in a ':'):
// TODO(rjl493456442): txlookup, bloombits, etc
| // | ||
| // Notably, it can happen that system crashes without truncating the ancient data | ||
| // but the head indicator has been updated in the active store. Regarding this issue, | ||
| // system will self recovery by truncating the extra data during the setup phase. |
|
|
||
| case *number-freezerBlockGraduation <= f.frozen: | ||
| log.Debug("Ancient blocks frozen already", "number", *number, "hash", hash, "frozen", f.frozen) | ||
| time.Sleep(freezerRecheckInterval) |
There was a problem hiding this comment.
Should this be an error?
a971ccd to
c3bb1b3
Compare
* freezer: implement split files for data * freezer: add tests * freezer: close old head-file when opening next * freezer: fix truncation * freezer: more testing around close/open * rawdb/freezer: address review concerns * freezer: fix minor review concerns * freezer: fix remaining concerns + testcases around truncation * freezer: docs * freezer: implement multithreading * core/rawdb: fix freezer nitpicks + change offsets to uint32 * freezer: preopen files, simplify lock constructs * freezer: delete files during truncation
* all: freezer style syncing core, eth, les, light: clean up freezer relative APIs core, eth, les, trie, ethdb, light: clean a bit core, eth, les, light: add unit tests core, light: rewrite setHead function core, eth: fix downloader unit tests core: add receipt chain insertion test core: use constant instead of hardcoding table name core: fix rollback core: fix setHead core/rawdb: remove canonical block first and then iterate side chain core/rawdb, ethdb: add hasAncient interface eth/downloader: calculate ancient limit via cht first core, eth, ethdb: lots of fixes * eth/downloader: print ancient disable log only for fast sync
* freezer: disable compression on hashes and difficulties * core/rawdb: address review concerns * core/rawdb: address review concerns
* core, eth: some fixes for freezer * vendor, core/rawdb, cmd/geth: add db inspector * core, cmd/utils: check ancient store path forceily * cmd/geth, common, core/rawdb: a few fixes * cmd/geth: support windows file rename and fix rename error * core: support ancient plugin * core, cmd: streaming file copy * cmd, consensus, core, tests: keep genesis in leveldb * core: write txlookup during ancient init * core: bump database version
|
@matthalp This PR did get a bit more complex than I anticipated, though that's because we decided to split the data files into 2GB chunks. Without that the code was really really simple. That said, the operations we are doing are relatively straightforward. The complexity comes mostly from optimizations. With our current code we have a very nice control over how much resources we waste (0 memory, 10-20 file descriptors vs. caches + files for leveldb), and we control how much computational overhead we have (0 vs. compaction for leveldb). Yes, leveldb might be a tad nicer, but by rolling our own files we can take advantage of all the properties of the data we are storing and optimize for our specific use case. |
|
|
||
| // Always keep genesis block in active database. | ||
| if b.NumberU64() != 0 { | ||
| deleted = append(deleted, b) |
There was a problem hiding this comment.
This can cause a huge spike in memory, our monitoring node spiked at nearly 40G memory shoving four million blocks from leveldb to ancients
|
If I want to run an ethereum node from genesis block with --syncmode "snap", but don't want to freeze levledb, is there a switch to disable this feature ? Or can I edit some codes to disable it ? |
|
No, there is no such switch. It should be fairly trivial to disable the live conversion from leveldb to freezer, but there's also the initial download-to-freezer which is maybe a bit less trivial. |
|
@holiman, I want to konw the space-saving rate about the conversion from leveldb to freezer. If i disable the freezer firstly and then enable that feature, we can calculate the rate of space. Is there any experimental data? |
This PR implements a long desired feature of moving ancient chain segments out of the active database into immutable append-only flat files.
There are a few goals of this new mechanism:
By storing less data in the active key/value database, compactions should in theory be a lot faster since there's less to shuffle around. In practice we already prefixed chain items with their block numbers, so compactions might not benefit too much in themselves.
By storing less data in the active key/value database, the same amount of cache and file descriptor allowance should provide better performance, since more state trie nodes can be kept in active memory.
By moving the ancient chain items into their own flat files, we can split the database into an active set requiring a fast SSD disk and an immutable set for which a slow HDD disk suffices. This should permit more people to run Ethereum nodes without huge SSDs (--datadir.ancient=/path/on/hdd).
By keeping ancient chain items in flat files, we can piggyback on the operating system's built in memory manager and file cacher, allowing Geth to potentially max out available memory without actually having to hog it. This should reduce the strain on Go's GC, reduce the amount of memory used by Geth, while at the same time increase overall system stability.