{kind=link}
{kind=link}
How does YouTube know what videos you’ll watch? How does Netflix always seem to know what new movies you would like to watch? They must have a magical crystal ball!
The crystal ball is a Machine Learning technique called Recommender Systems. In a very general way, recommender systems are algorithms that aim to predict relevant items to users and recommend items that most likely are interesting for them; items being movies to watch, text to read, products to buy or anything else depending on industries.
Recommender systems, when applied right and efficient, can be crucial in some industries because they can generate a huge amount of income. Moreover, they can be a way to stand out significantly from competitors. For example, a few years ago, Netflix organized a challenge (the Netflix prize) where the goal was to produce a recommender system that performs 10% better than its own algorithm with a prize of 1 million dollars to win.
Recommender systems are generally divided into two main categories: collaborative filtering and content-based systems.
Content-based systems use user’s item and profile features. The general idea is, if a user was interested in an item in the past, they will again be interested in it in the future. Similar items are usually grouped based on their features. User profiles are constructed using historical interactions or by explicitly asking users about their interests. There are other systems, not considered purely content-based, which utilize user personal and social data.
The main advantage of content-based systems is, that it is relatively simple to add new items to the system. We just need to ensure that we assign them a group according to their features. However, there are two issues concerning these systems. One is due to making obvious recommendations because of excessive specialization, meaning that a user is only interested in specific categories and the system is not able to recommend items outside those categories, even though they could be interesting. The other issue is that new users lack a defined profile unless they are explicitly asked for information.
Collaborative filtering are methods that are based just on the past interactions recorded between users and items to produce new recommendations. These interactions are stored in the so-called user-item interactions matrix where each entry (i,j) represents the interaction between user i and item j. The main idea behind collaborative methods is that these past user-item interactions are sufficient to detect similar users and/or similar items and make predictions based on these estimated proximities. An interesting way of looking at collaborative filtering is to think of it as a generalization of classification and regression. While in these cases we aim to predict a variable that directly depends on other variables (features), in collaborative filtering there is no such distinction of feature variables and class variables.
Collaborative filtering algorithms can be further divided into two sub-categories: memory based and model based. Memory based approaches directly work with values of recorded interactions, assuming no model. Model-based approaches, on the other hand, always assume some kind of underlying model and generally speaking, try to make sure that whatever predictions come out will fit the model well.
The main advantage of collaborative approaches is that they require no information about users or items and thus can be applied to many situations. Furthermore, the more users interact with items and thus bring new information, will make the system more and more effective. However, since we only consider past interactions to make recommendations, collaborative filtering suffers from the cold start problem: we should have enough information (user-item interactions) for the system to work. When adding new users/items to the system we have no prior information about them since they don’t have existing interactions. There are different ways how we can handle this drawback:
- recommending random items to new users or new items to random users (random strategy),
- recommending popular items to new users or new items to most active users (maximum expectation strategy),
- recommending a set of various items to new users or a new item to a set of various users (exploratory strategy),
- using a non-collaborative method for the early life of the user or the item.
Collaborative filtering is currently one of the most frequently used approaches and usually provides better results than content-based recommendations. Some examples of this are found in the recommendation systems of Youtube, Netflix, and Spotify. In the following we will consider the MoviLens dataset and create a recommender system using memory based collaborative filtering.
Data is the single most important asset. Essentially, we need to know some details about the users and items. Data required for recommender systems are derived from explicit user ratings after watching a movie or listening to a song, from implicit search engine queries and purchase histories, or other knowledge about the users/items themselves. If metadata is all we have available, we can start with content-based approaches. If we have a large number of user interactions, we can experiment with more powerful collaborative filtering. The larger the data set in the possession, the better the systems will work.
The MovieLens dataset consists of ratings assigned to movies by users. For example:
df.head() # df is pandas DataFrame() containg the dataset
user_id movie_id rating
0 196 242 3
1 186 302 3
2 22 377 1
3 244 51 2
4 166 346 1
Ratings range from 0.5 stars to 5. The goal is to predict the rating a given user will give a particular movie. The features userid_ and movieid_ are both sparse categorical variables and they have many possible values:
610 distinct users rated 9,724 different movies (total ratings = 100,836)
By sparse categorical variables we mean a categorical variable with lots of possible values (high cardinality), with a small number of them (often just 1) present in any given observation. One good example is the words. There are hundreds of thousands of them in the English language, but a single tweet might only have a dozen.
We will create a deep neural network to build a model that takes a user and a movie and outputs a number from 0.5-5, representing how many stars this user would give that movie. Deep learning is a subfield of machine learning that is a set of algorithms that is inspired by the structure and function of the brain. These algorithms are usually called Artificial Neural Networks (ANN). Deep learning is one of the hottest fields in data science with many case studies that have astonishing results in robotics, image recognition and Artificial Intelligence (AI).
One of the most powerful and easy-to-use Python libraries for developing and evaluating deep learning models is Keras. It is an open-source neural-network library and capable of running on top of TensorFlow, Microsoft Cognitive Toolkit, R, Theano, or PlaidML. The advantage of using Keras is mainly that we can get started with neural networks in an easy way. The following definition or description is from Wikipedia:
Before we can build a model, we need to figure out how to interpret the user and movie ids. The most straightforward way would be to use the ids assigned to users and movies as numerical inputs, but the actual numerical values of the ids are meaningless. Toys Story has id 1 and City Hall has id 100, but that doesn't mean City Hall is 'hundred times bigger' than Toys story. Another widespread approach is to use One-Hot Encoding which creates new (binary) columns, indicating the presence of each possible value from the original data. However, this approach is fine for categorical variables with a small number of possible values. If we would one-hot-encode the movies we will obtain a 9.724 dimension vector for each movie, with a single 1 indicating the movie. Furthermore, in a one-hot encoding, similar movies would not be "closer" to one another.
An embedding layer maps each element in a set of discrete things (like words, users, or movies) to a dense vector of real numbers (its embedding). The idea of entity embeddings is to map high-dimensional categorical variables to a low-dimensional learned representation that places similar entities closer together in the embedding space. By training a neural network to learn entity embeddings, we not only get a reduced dimension representation of the users and movies, we also get a representation that keeps similar users and movies closer to each other. Therefore, the basic approach for a recommendation system is to create entity embeddings of all the users and movies, and then for any user, find the closest other user and movie in the embedding space. A key thing to note when creating a network is that, the network is not simply a stack of layers from input to output. We treat the user and the movie as separate inputs, which come together only after each has gone through its own embedding layer. This means that the network should be able to have multiple inputs, in particular two. Therefore, we use the powerful functional API, using the keras.Model class.
Each instance will consist of two inputs: a single user id, and a single movie id:
# The dimension of the embedding space where the model will map the inputs to
movie_embedding_size = 8
user_embedding_size = 8
# Defining the inputs for the model
user_id_input = Input(shape=(1,), name='user_id')
movie_id_input = Input(shape=(1,), name='movie_id')
# Adding the Embedding Layers for each input
user_embedded = Embedding(df.user_id.max()+1, user_embedding_size,
input_length=1, name='user_embedding')(user_id_input)
movie_embedded = Embedding(df.movie_id.max()+1, movie_embedding_size,
input_length=1, name='movie_embedding')(movie_id_input)
Next we need to concatenate the two embeddings (and also remove useless extra dimensions) and then we flatten them so that we can add dense layers to the network:
concatenated = Concatenate()([user_embedded, movie_embedded])
out = Flatten()(concatenated)
# Adding dense layers
hidden_units = (32,4)
# Add one or more hidden layers
for n_hidden in hidden_units:
out = Dense(n_hidden, activation='relu')(out)
We want a single output from the network; the predicted rating:
out = Dense(1, activation='linear', name='prediction')(out)
And lastly, we give the above inputs and output to the model:
model = Model(inputs = [user_id_input, movie_id_input],outputs = out)
We compile the model to minimize squared error ('MSE'). We also include absolute error ('MAE') as a metric to report during training, since it is a bit easier to interpret.
model.compile(optimizer = 'Adam',loss='MSE',metrics=['MAE'])
A problem with training neural networks is in the choice of the number of training epochs to use. Too many epochs can lead to overfitting of the training dataset, whereas too few may result in an underfit model. Early stopping is a method that allows specify an arbitrarily large number of training epochs and stop training once the model performance stops improving on the test dataset. We thus add early stopping before training the model.
es=EarlyStopping(monitor='val_MAE', min_delta=0, patience=0, verbose=0, mode='min', baseline=None, restore_best_weights=False)
# train
history=model.fit(x=[df.user_id, df.movie_id], y=df.y, batch_size=500,epochs=20, verbose=1, validation_split=0.15, callbacks=[es])
We are passing in df.y as the target variable rather than df.rating. The y column is just a 'centered' version of the rating - i.e. the rating column minus its mean over the training set. For example, if the overall average rating in the training set was 3 stars, then we would translate 3 star ratings to 0, 5 star ratings to 2.0, etc. to get y. This is a common practice in deep learning, and tends to help achieve better results in fewer epochs.
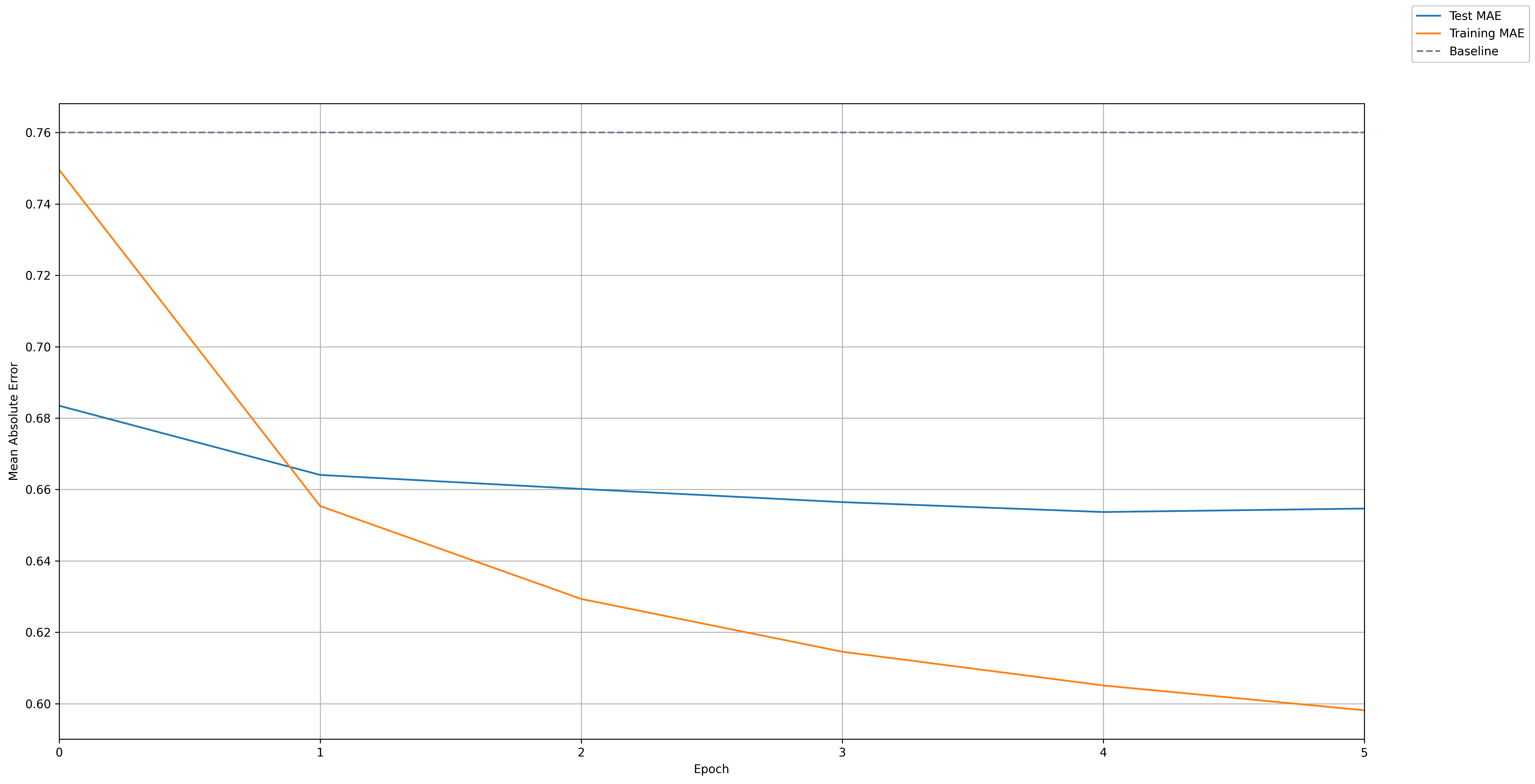
To judge whether the model is any good, it is helpful to have a baseline. We thus calculate the error of a couple of baselines, always predicting the global average rating, and predicting the average rating per movie. Here is the outcome of the baseline:
Average rating in training set is 3.50 stars
Always predicting global average rating results in Mean Absolute Error=0.83, Mean Squared Error=1.10
Predicting mean per movie results in Mean Absolute Error=0.76, Mean Squared Error=0.96
The following plot shoes the embedding model's absolute error over time. For comparison, our best baseline (predicting the average rating per movie) is marked with a dotted line:
To demonstrate how we can use the above model, we will predict for a specific user, chosen at random from the dataset:
User #557 has rated 23 movies (avg. rating = 3.8)
Here are some of the top ratings the user had made:
Movie_id rating title genre
5618 5.0 Spirited Away (Sen to Chihiro no kamikakushi) ... Adventure-Animation-Fantasy
648 5.0 Mission: Impossible (1996) Action-Adventure-Mystery-Thriller
1036 5.0 Die Hard (1988) Action-Crime-Thriller
10 4.5 GoldenEye (1995) Action-Adventure-Thriller
2571 4.5 Matrix, The (1999) Action-Sci-Fi-Thriller
1485 4.5 Liar Liar (1997) Comedy
2617 4.5 Mummy, The (1999) Action-Adventure-Comedy-Fantasy-Horror-Thriller
4896 4.5 Harry Potter and the Sorcerer's Stone (a.k.a. ... Adventure-Children-Fantasy
150 4.5 Apollo 13 (1995) Adventure-Drama-IMAX
We can use the model to recommend movies. To do so, we first collect all movies the user has not watched. We then let the model predict the ratings of the users to those movies and pick the top e.g. 5 movies:
Showing recommendations for user: 557
====================================
--------------------------------
Top 5 movie recommendations
--------------------------------
One I Love, The (2014) : Comedy-Drama-Romance
Hunger (2008) : Drama
Doctor Who: The Time of the Doctor (2013) : Adventure-Drama
13th (2016) : Documentary
Three Billboards Outside Ebbing, Missouri (2017) : Crime-Drama
Here are some ideas that can be further exploited:
- The MovieLens dataset also includes information about each movie such as its title, its year of release, a set of genres and user-assigned tags that could be used to improve the network.
- The ratings can only take on the values {0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5}, hence we could treat the problem as a multiclass classification problem with 10 classes, one for each possible star rating.