forked from microsoft/nni
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request #48 from microsoft/master
pull code
- Loading branch information
Showing
38 changed files
with
1,605 additions
and
222 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,54 @@ | ||
| L1FilterPruner on NNI Compressor | ||
| === | ||
|
|
||
| ## 1. Introduction | ||
|
|
||
| L1FilterPruner is a general structured pruning algorithm for pruning filters in the convolutional layers. | ||
|
|
||
| In ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710), authors Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet and Hans Peter Graf. | ||
|
|
||
|  | ||
|
|
||
| > L1Filter Pruner prunes filters in the **convolution layers** | ||
| > | ||
| > The procedure of pruning m filters from the ith convolutional layer is as follows: | ||
| > | ||
| > 1. For each filter , calculate the sum of its absolute kernel weights | ||
| > 2. Sort the filters by 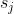. | ||
| > 3. Prune 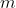 filters with the smallest sum values and their corresponding feature maps. The | ||
| > kernels in the next convolutional layer corresponding to the pruned feature maps are also | ||
| > removed. | ||
| > 4. A new kernel matrix is created for both the th and 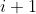th layers, and the remaining kernel | ||
| > weights are copied to the new model. | ||
| ## 2. Usage | ||
|
|
||
| PyTorch code | ||
|
|
||
| ``` | ||
| from nni.compression.torch import L1FilterPruner | ||
| config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'], 'op_names': ['conv1', 'conv2'] }] | ||
| pruner = L1FilterPruner(model, config_list) | ||
| pruner.compress() | ||
| ``` | ||
|
|
||
| #### User configuration for L1Filter Pruner | ||
|
|
||
| - **sparsity:** This is to specify the sparsity operations to be compressed to | ||
| - **op_types:** Only Conv2d is supported in L1Filter Pruner | ||
|
|
||
| ## 3. Experiment | ||
|
|
||
| We implemented one of the experiments in ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710), we pruned **VGG-16** for CIFAR-10 to **VGG-16-pruned-A** in the paper, in which $64\%$ parameters are pruned. Our experiments results are as follows: | ||
|
|
||
| | Model | Error(paper/ours) | Parameters | Pruned | | ||
| | --------------- | ----------------- | --------------- | -------- | | ||
| | VGG-16 | 6.75/6.49 | 1.5x10^7 | | | ||
| | VGG-16-pruned-A | 6.60/6.47 | 5.4x10^6 | 64.0% | | ||
|
|
||
| The experiments code can be found at [examples/model_compress]( https://github.com/microsoft/nni/tree/master/examples/model_compress/) | ||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,23 @@ | ||
| Lottery Ticket Hypothesis on NNI | ||
| === | ||
|
|
||
| ## Introduction | ||
|
|
||
| The paper [The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks](https://arxiv.org/abs/1803.03635) is mainly a measurement and analysis paper, it delivers very interesting insights. To support it on NNI, we mainly implement the training approach for finding *winning tickets*. | ||
|
|
||
| In this paper, the authors use the following process to prune a model, called *iterative prunning*: | ||
| >1. Randomly initialize a neural network f(x;theta_0) (where theta_0 follows D_{theta}). | ||
| >2. Train the network for j iterations, arriving at parameters theta_j. | ||
| >3. Prune p% of the parameters in theta_j, creating a mask m. | ||
| >4. Reset the remaining parameters to their values in theta_0, creating the winning ticket f(x;m*theta_0). | ||
| >5. Repeat step 2, 3, and 4. | ||
| If the configured final sparsity is P (e.g., 0.8) and there are n times iterative pruning, each iterative pruning prunes 1-(1-P)^(1/n) of the weights that survive the previous round. | ||
|
|
||
| ## Reproduce Results | ||
|
|
||
| We try to reproduce the experiment result of the fully connected network on MNIST using the same configuration as in the paper. The code can be referred [here](https://github.com/microsoft/nni/tree/master/examples/model_compress/lottery_torch_mnist_fc.py). In this experiment, we prune 10 times, for each pruning we train the pruned model for 50 epochs. | ||
|
|
||
|  | ||
|
|
||
| The above figure shows the result of the fully connected network. `round0-sparsity-0.0` is the performance without pruning. Consistent with the paper, pruning around 80% also obtain similar performance compared to non-pruning, and converges a little faster. If pruning too much, e.g., larger than 94%, the accuracy becomes lower and convergence becomes a little slower. A little different from the paper, the trend of the data in the paper is relatively more clear. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,39 @@ | ||
| SlimPruner on NNI Compressor | ||
| === | ||
|
|
||
| ## 1. Slim Pruner | ||
|
|
||
| SlimPruner is a structured pruning algorithm for pruning channels in the convolutional layers by pruning corresponding scaling factors in the later BN layers. | ||
|
|
||
| In ['Learning Efficient Convolutional Networks through Network Slimming'](https://arxiv.org/pdf/1708.06519.pdf), authors Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan and Changshui Zhang. | ||
|
|
||
|  | ||
|
|
||
| > Slim Pruner **prunes channels in the convolution layers by masking corresponding scaling factors in the later BN layers**, L1 regularization on the scaling factors should be applied in batch normalization (BN) layers while training, scaling factors of BN layers are **globally ranked** while pruning, so the sparse model can be automatically found given sparsity. | ||
| ## 2. Usage | ||
|
|
||
| PyTorch code | ||
|
|
||
| ``` | ||
| from nni.compression.torch import SlimPruner | ||
| config_list = [{ 'sparsity': 0.8, 'op_types': ['BatchNorm2d'] }] | ||
| pruner = SlimPruner(model, config_list) | ||
| pruner.compress() | ||
| ``` | ||
|
|
||
| #### User configuration for Filter Pruner | ||
|
|
||
| - **sparsity:** This is to specify the sparsity operations to be compressed to | ||
| - **op_types:** Only BatchNorm2d is supported in Slim Pruner | ||
|
|
||
| ## 3. Experiment | ||
|
|
||
| We implemented one of the experiments in ['Learning Efficient Convolutional Networks through Network Slimming'](https://arxiv.org/pdf/1708.06519.pdf), we pruned $70\%$ channels in the **VGGNet** for CIFAR-10 in the paper, in which $88.5\%$ parameters are pruned. Our experiments results are as follows: | ||
|
|
||
| | Model | Error(paper/ours) | Parameters | Pruned | | ||
| | ------------- | ----------------- | ---------- | --------- | | ||
| | VGGNet | 6.34/6.40 | 20.04M | | | ||
| | Pruned-VGGNet | 6.20/6.39 | 2.03M | 88.5% | | ||
|
|
||
| The experiments code can be found at [examples/model_compress]( https://github.com/microsoft/nni/tree/master/examples/model_compress/) |
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Oops, something went wrong.