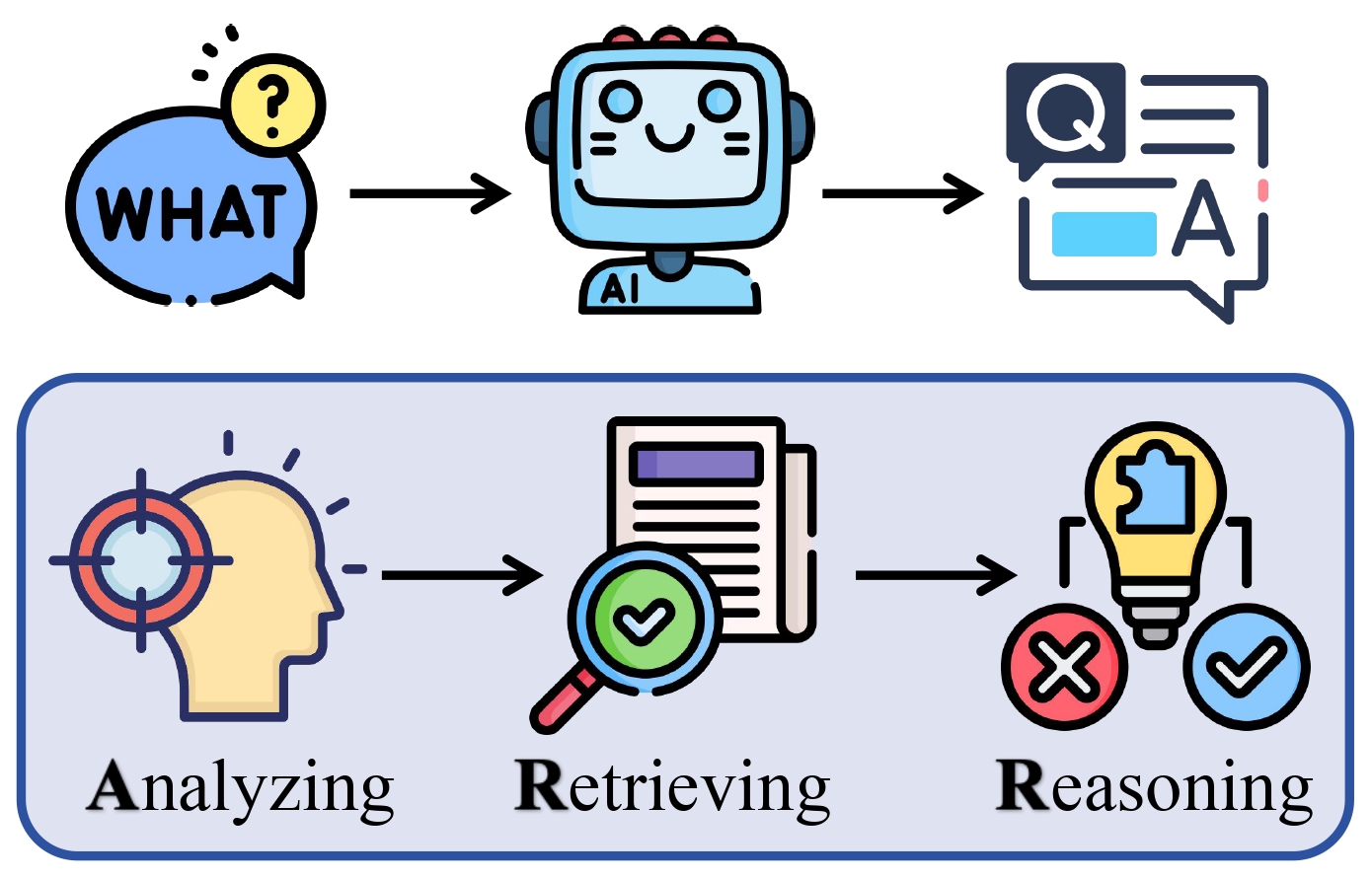
Paper Abstract
- ARR: Question Answering with Large Language Models via Analyzing, Retrieving, and Reasoning
- Authors: Yuwei Yin and Giuseppe Carenini
- Paper: https://huggingface.co/papers/2502.04689
Large language models (LLMs) achieve remarkable performance on challenging benchmarks
that are often structured as multiple-choice question-answering (QA) tasks. Zero-shot
Chain-of-Thought (CoT) prompting enhances reasoning in LLMs but provides only vague and
generic guidance ("think step by step"). This paper introduces ARR, an intuitive and
effective zero-shot prompting method that explicitly incorporates three key steps in QA
solving: analyzing the intent of the question, retrieving relevant information, and
reasoning step by step. Comprehensive experiments across diverse and challenging QA tasks
demonstrate that ARR consistently improves the Baseline (without ARR prompting) and
outperforms CoT. Ablation and case studies further validate the positive contributions of
each component: analyzing, retrieving, and reasoning. Notably, intent analysis plays
a vital role in ARR. Additionally, extensive evaluations across various model sizes,
LLM series, and generation settings solidify the effectiveness, robustness, and
generalizability of ARR.
Environment Setup
- Python: Python 3.10
- GPU: A single NVIDIA V100-32GB or A100-40GB GPU
- 1B/3B/7B/8B LLMs
float16inference mode only
- 1B/3B/7B/8B LLMs
git clone https://github.com/YuweiYin/ARR
cd ARR/
# Now, "/path/to/ARR/" is the project root directory
# https://docs.conda.io/projects/miniconda/en/latest/
conda create -n arr python=3.10 -y
conda activate arr
pip install -r requirements.txt -i https://pypi.org/simple/
pip install -e . -i https://pypi.org/simple/
# We can set the Hugging Face cache directory. The following is for the dataset cache.
export HF_HOME="/path/to/your/.cache/huggingface/datasets" # Default: "${HOME}/.cache/huggingface/datasets/"- Download the datasets and models beforehand if the computing nodes have no Internet access or HOME storage is limited.
- Please ensure
CACHE_DIRandHF_TOKENin the script are correct directories.
# https://huggingface.co/datasets
HF_TOKEN="YOUR_HF_TOKEN" # https://huggingface.co/settings/tokens
CACHE_DIR="YOUR_HF_CACHE_DIR" # E.g., "${HOME}/.cache/huggingface/"
bash run_download_datasets.sh "${HF_TOKEN}" "${CACHE_DIR}" # Download data to "${CACHE_DIR}/datasets/"Multi Choice QA Datasets
- Reading Comprehension
- Commonsense Reasoning
- World Knowledge
- Multitask Understanding
-
bbh: BigBench Hard (BBH) - BigBench Paper; BigBench GitHub; BBH Paper; BBH Dataset -
mmlu: MMLU - Paper; Dataset; No-Train Data -
mmlu_pro: MMLU-Pro - Paper; Dataset
-
# https://huggingface.co/models
HF_TOKEN="YOUR_HF_TOKEN" # https://huggingface.co/settings/tokens
CACHE_DIR="YOUR_HF_CACHE_DIR" # E.g., "${HOME}/.cache/huggingface/"
bash run_download_models.sh "${HF_TOKEN}" "${CACHE_DIR}" # Download models to "${CACHE_DIR}/"For each bash script, please ensure CACHE_DIR and PROJECT_DIR in the script are
correct Hugging Face cache directory (default: "~/.cache/huggingface/") and
project root directory ("/path/to/ARR/").
mkdir -p logs/ # where we save running logs
mkdir -p results/ # where we save experimental resultsExperimental Settings
- Comparison: (Zero-shot Settings)
- w/o Reason: directly selecting options without relying on rationales (skipping Reasoning Generation)
- Baseline:
"Answer:" - CoT:
"Answer: Let's think step by step." - ARR:
"Answer: Let's analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning."
- Models:
-
meta-llama/Llama-3.1-8B-Instruct(Link)
-
Experiment Script
CACHE_DIR="YOUR_HF_CACHE_DIR" # E.g., "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/ARR/"
MODEL="meta-llama/Llama-3.1-8B-Instruct"
NUM_FEWSHOT="0"
# [Reasoning Generation] **First**, freely generate answer with reasoning/rationale:
echo -e "\n\n >>> bash run_gen_lm.sh --hf_id ${MODEL} QA_ALL ${NUM_FEWSHOT}-shot"
bash run_gen_lm.sh "1;${MODEL};1;QA_ALL;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_gen_lm-cot.sh --hf_id ${MODEL} QA_ALL ${NUM_FEWSHOT}-shot"
bash run_gen_lm-cot.sh "1;${MODEL};1;QA_ALL;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_gen_lm-arr.sh --hf_id ${MODEL} QA_ALL ${NUM_FEWSHOT}-shot"
bash run_gen_lm-arr.sh "1;${MODEL};1;QA_ALL;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
# [Option Selection] **Second**, answer the question (evaluate each option) (multi-choice QA -- Accuracy):
echo -e "\n\n >>> bash run_eval_lm-no_gen.sh --hf_id ${MODEL} QA_ALL ${NUM_FEWSHOT}-shot" # w/o Reason
bash run_eval_lm-no_gen.sh "1;${MODEL};1;QA_ALL;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} QA_ALL ${NUM_FEWSHOT}-shot" # Baseline
bash run_eval_lm.sh "1;${MODEL};1;QA_ALL;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_eval_lm-cot.sh --hf_id ${MODEL} QA_ALL ${NUM_FEWSHOT}-shot" # CoT
bash run_eval_lm-cot.sh "1;${MODEL};1;QA_ALL;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_eval_lm-arr.sh --hf_id ${MODEL} QA_ALL ${NUM_FEWSHOT}-shot" # ARR
bash run_eval_lm-arr.sh "1;${MODEL};1;QA_ALL;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"Experimental Settings
- Comparison:
- A / R / R: Analyzing / Retrieving / Reasoning
- ARR = "000" "001" "010" "100" "111"
- ARR 000 = Baseline:
"Answer:" - ARR 001 = Reasoning-only:
"Answer: Let's answer the question with step-by-step reasoning." - ARR 010 = Retrieving-only:
"Answer: Let's find relevant information, and answer the question." - ARR 100 = Analyzing-only:
"Answer: Let's analyze the intent of the question, and answer the question." - ARR 111 = ARR:
"Answer: Let's analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning."
- Models:
-
meta-llama/Llama-3.1-8B-Instruct(Link)
-
Experiment Script
CACHE_DIR="YOUR_HF_CACHE_DIR" # E.g., "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/ARR/"
MODEL="meta-llama/Llama-3.1-8B-Instruct"
NUM_FEWSHOT="0"
# [Reasoning Generation] **First**, freely generate answer with reasoning/rationale:
for ABLATION in "001" "010" "100" # "000" = baseline; "111" = ARR
do
echo -e "\n\n >>> bash run_gen_lm-arr.sh --hf_id ${MODEL} QA_ALL ${NUM_FEWSHOT}-shot (ABLATION: ARR = ${ABLATION})"
bash run_gen_lm-arr.sh "1;${MODEL};1;QA_ALL;0.0;${NUM_FEWSHOT};${ABLATION}" "${CACHE_DIR}" "${PROJECT_DIR}"
done
# [Option Selection] **Second**, answer the question (evaluate each option) (multi-choice QA -- Accuracy):
for ABLATION in "001" "010" "100" # "000" = baseline; "111" = ARR
do
echo -e "\n\n >>> bash run_eval_lm-arr.sh --hf_id ${MODEL} QA_ALL ${NUM_FEWSHOT}-shot (ABLATION: ARR = ${ABLATION})"
bash run_eval_lm-arr.sh "1;${MODEL};1;QA_ALL;0.0;${NUM_FEWSHOT};${ABLATION}" "${CACHE_DIR}" "${PROJECT_DIR}"
doneExperimental Settings
Experiment Script
CACHE_DIR="YOUR_HF_CACHE_DIR" # E.g., "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/ARR/"
# [Reasoning Generation] **First**, freely generate answer with reasoning/rationale:
for MODEL in "meta-llama/Llama-3.2-1B-Instruct" "meta-llama/Llama-3.2-3B-Instruct"
do
NUM_FEWSHOT="0"
echo -e "\n\n >>> bash run_gen_lm.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_gen_lm.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_gen_lm-cot.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_gen_lm-cot.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_gen_lm-arr.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_gen_lm-arr.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
done
# [Option Selection] **Second**, answer the question (evaluate each option) (multi-choice QA -- Accuracy):
for MODEL in "meta-llama/Llama-3.2-1B-Instruct" "meta-llama/Llama-3.2-3B-Instruct"
do
NUM_FEWSHOT="0"
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_eval_lm.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_eval_lm-cot.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_eval_lm-cot.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_eval_lm-arr.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_eval_lm-arr.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
doneExperimental Settings
Experiment Script
CACHE_DIR="YOUR_HF_CACHE_DIR" # E.g., "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/ARR/"
# [Reasoning Generation] **First**, freely generate answer with reasoning/rationale:
for MODEL in "Qwen/Qwen2.5-7B-Instruct" "google/gemma-7b-it" "mistralai/Mistral-7B-Instruct-v0.3"
do
NUM_FEWSHOT="0"
echo -e "\n\n >>> bash run_gen_lm.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_gen_lm.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_gen_lm-cot.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_gen_lm-cot.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_gen_lm-arr.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_gen_lm-arr.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
done
# [Option Selection] **Second**, answer the question (evaluate each option) (multi-choice QA -- Accuracy):
for MODEL in "Qwen/Qwen2.5-7B-Instruct" "google/gemma-7b-it" "mistralai/Mistral-7B-Instruct-v0.3"
do
NUM_FEWSHOT="0"
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_eval_lm.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_eval_lm-cot.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_eval_lm-cot.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_eval_lm-arr.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_eval_lm-arr.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
doneExperimental Settings
- Comparison:
- Observe the effect of the proposed ARR method using different generation temperatures
- Temperature: 0 (default), 0.5, 1.0, 1.5
- Models:
-
meta-llama/Llama-3.1-8B-Instruct(Link)
-
Experiment Script
CACHE_DIR="YOUR_HF_CACHE_DIR" # E.g., "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/ARR/"
MODEL="meta-llama/Llama-3.1-8B-Instruct"
# [Reasoning Generation] **First**, freely generate answer with reasoning/rationale:
NUM_FEWSHOT="0"
for TEMPERATURE in "0.5" "1.0" "1.5" # default: "0.0"
do
echo -e "\n\n >>> bash run_gen_lm.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_gen_lm.sh "1;${MODEL};1;QA_GEN;${TEMPERATURE};${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_gen_lm-cot.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_gen_lm-cot.sh "1;${MODEL};1;QA_GEN;${TEMPERATURE};${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_gen_lm-arr.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_gen_lm-arr.sh "1;${MODEL};1;QA_GEN;${TEMPERATURE};${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
done
# [Option Selection] **Second**, answer the question (evaluate each option) (multi-choice QA -- Accuracy):
NUM_FEWSHOT="0"
for TEMPERATURE in "0.5" "1.0" "1.5" # default: "0.0"
do
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_eval_lm.sh "1;${MODEL};1;QA_GEN;${TEMPERATURE};${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_eval_lm-cot.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_eval_lm-cot.sh "1;${MODEL};1;QA_GEN;${TEMPERATURE};${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_eval_lm-arr.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_eval_lm-arr.sh "1;${MODEL};1;QA_GEN;${TEMPERATURE};${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
doneExperimental Settings
- Comparison:
- Observe the effect of the proposed ARR method in few-shot settings (using different shots)
- QA Performance comparison among baseline (in-context learning), few-shot CoT, and few-shot ARR methods
- N shots: 0 (default), 1, 3, and 5
- Models:
-
meta-llama/Llama-3.1-8B-Instruct(Link)
-
Obtain CoT/ARR Rationales for Few-shot Examples
# Before LLM generation and evaluation, we first obtain 1/3/5 few-shot examples from the dev/train set,
# where the CoT and ARR reasoning/rationale for each few-shot example is constructed by GPT-4o.
# Now, the `few_shot.json` file under each evaluation task already has CoT and ARR reasoning/rationale.
#CACHE_DIR="YOUR_HF_CACHE_DIR" # E.g., "${HOME}/.cache/huggingface/"
#PROJECT_DIR="/path/to/ARR/"
#bash run_gen_gpt.sh "1;QA_GEN;0;111;1.0" "${CACHE_DIR}" "${PROJECT_DIRExperiment Script
CACHE_DIR="YOUR_HF_CACHE_DIR" # E.g., "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/ARR/"
MODEL="meta-llama/Llama-3.1-8B-Instruct"
# [Reasoning Generation] **First**, freely generate answer with reasoning/rationale:
for NUM_FEWSHOT in "1" "3" "5" # default: "0"
do
echo -e "\n\n >>> bash run_gen_lm.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_gen_lm.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_gen_lm-cot.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_gen_lm-cot.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_gen_lm-arr.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_gen_lm-arr.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
done
# [Option Selection] **Second**, answer the question (evaluate each option) (multi-choice QA -- Accuracy):
for NUM_FEWSHOT in "1" "3" "5" # default: "0"
do
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_eval_lm.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_eval_lm-cot.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_eval_lm-cot.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
echo -e "\n\n >>> bash run_eval_lm-arr.sh --hf_id ${MODEL} QA_GEN ${NUM_FEWSHOT}-shot"
bash run_eval_lm-arr.sh "1;${MODEL};1;QA_GEN;0.0;${NUM_FEWSHOT}" "${CACHE_DIR}" "${PROJECT_DIR}"
donePlease refer to the LICENSE file for more details.
- Paper (arXiv): https://arxiv.org/abs/2502.04689
- If you find our work helpful, please kindly star this GitHub repo and cite our paper. 🤗
@article{yin2025arr,
title = {ARR: Question Answering with Large Language Models via Analyzing, Retrieving, and Reasoning},
author = {Yin, Yuwei and Carenini, Giuseppe},
journal = {arXiv preprint arXiv:2502.04689},
year = {2025},
url = {https://arxiv.org/abs/2502.04689},
}