The official repository for "Multi-Corpus Emotion Recognition Method based on Cross-Modal Gated Attention Fusion", Pattern Recognition Letters (submitted)
This study addresses key challenges in automatic emotion recognition (ER), particularly the limitations of single-corpus training that hinder generalizability. To overcome these issues, the authors introduce a novel multi-corpus, multimodal ER method evaluated using a leave-one-corpus-out (LOCO) protocol. This approach incorporates fine-tuned encoders for audio, video, and text, combined through a context-independent gated attention mechanism for cross-modal feature fusion.
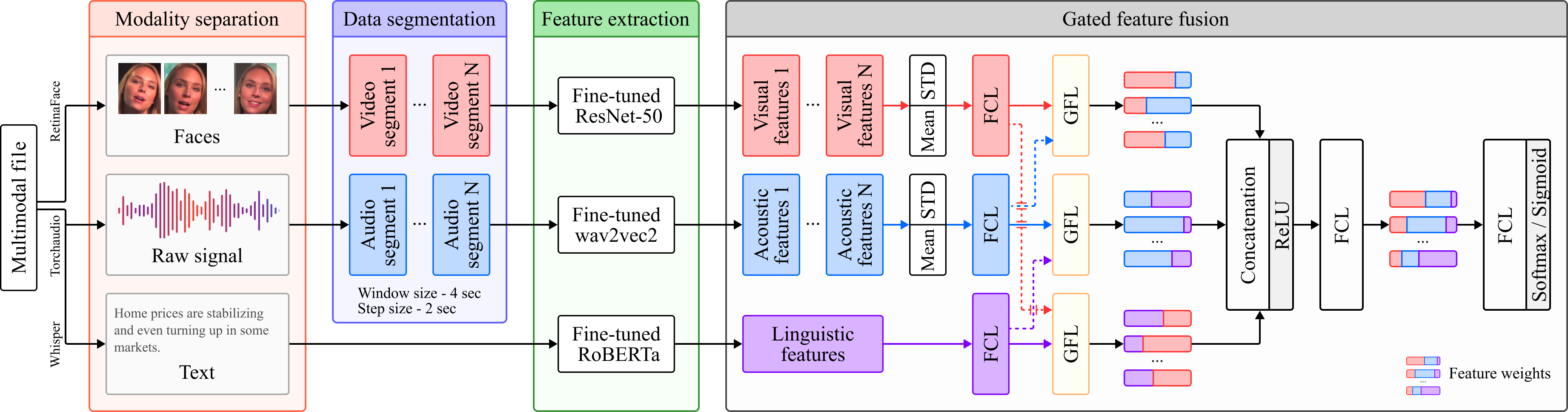
- Visual Encoder: Fine-tuned ResNet-50.
- Acoustic Encoder: Fine-tuned emotional wav2vec2.
- Linguistic Encoder: Fine-tuned RoBERTa model.
- Audio/Video Segment Aggregation: Extraction of feature statistics (mean and standard deviation (STD) values).
- Multimodal Feature Aggregation: Cross-modal, context-independent gated attention mechanism.
The proposed method achieves state-of-the-art performance across multiple benchmark corpora, including MOSEI, MELD, IEMOCAP, and AFEW. The study reveals that models trained on MELD demonstrate superior cross-corpus generalization. Additionally, AFEW annotations show strong alignment with other corpora, resulting in the best cross-corpus performance. These findings validate the robustness and applicability of the method across diverse real-world scenarios.
The pre-trained models are available here.
To predict emotions for your multimodal files, configure the config.toml file with paths to the models and files, and then run python src/inference.py.
To train the multimodal model, first extract features from your data python src/avt_feature_extraction.py.
Then, initiate training with python src/train_avt_model.py.
Ensure the config.toml file is properly configured for both steps.
If you are using our models in your research, please consider to cite research:
@article{RYUMINA2024, title = {Multi-Corpus Emotion Recognition Method based on Cross-Modal Gated Attention Fusion}, author = {Elena Ryumina and Dmitry Ryumin and Alexandr Axyonov and Denis Ivanko and Alexey Karpov}, journal = {Pattern Recognition Letters}, year = {2024}, }
Parts of this project page were adopted from the Nerfies page.
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
