Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[Feature] Fix guided decoding blocking bitmask memcpy (vllm-project#1…
…2563) **[Guided decoding performance optimization]** Sending the guided decoding bitmask in xgrammar to the GPU (`self.token_bitmask.to(scores.device)`) is a blocking operation that prevents the CPU from pre-launching the sampler kernels. The CPU waits until decode is complete, then copies the bitmask over. This PR changes the operation to async via setting `non-blocking=True`. (Current) The CPU is blocked on a `cudaStreamSynchronize` and only pre-empts the sampling kernels after bitmask application. Below is the Nsys profile for one decode phase from Llama 3.1 8B. 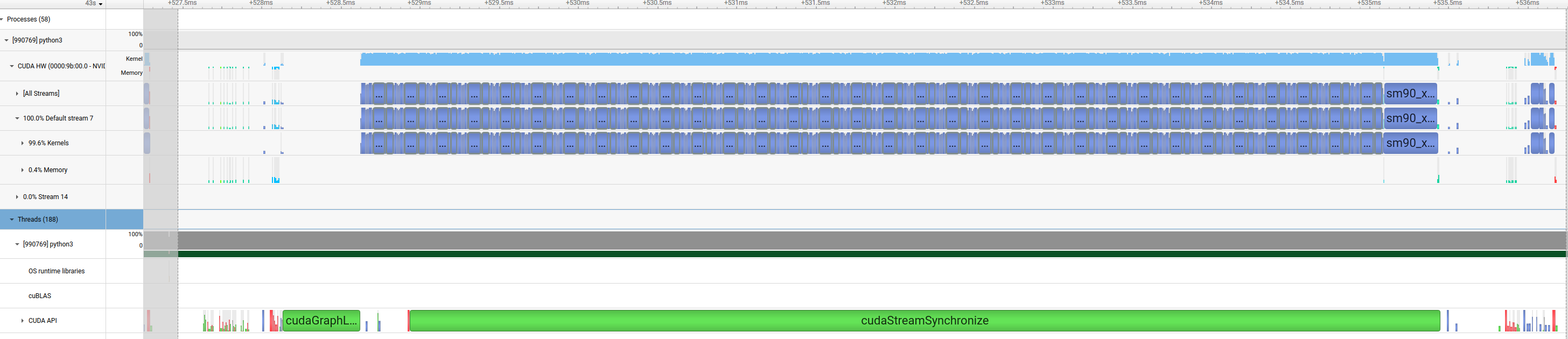 With the optimization, this is no longer the case:  --------- Signed-off-by: Ryan N <ryan.nguyen@centml.ai> Signed-off-by: Isotr0py <2037008807@qq.com>
- Loading branch information