This is a Python 2 script, with GUI, designed to transform oral history transcripts, presumably created using InqScribe, into XML suitable for ingest into the Islandora Oral Histories (IOH) Solution Pack to populate a TRANSCRIPT datastream and its derivatives.
The script and accompanying CSS are intended to deliver oral histories that look something like this:

Note that the names of speakers appear in different colors in the video window captions, and speaker names appear in bold in the indexed transcript below the video. Also note that each speaker and corresponding text appears on a new line.
Once installed you should run the script using a command like the following (you can easily create an alias and use that if you like):
python /path/to/script/Transform_InqScribe_to_IOH.py
Doing so should launch a simple GUI that looks like this:
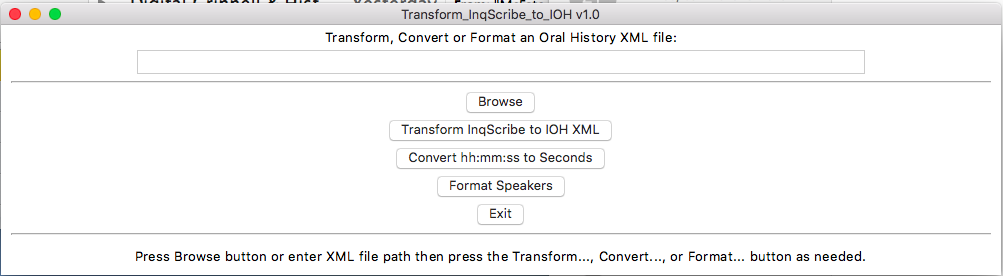
You typically use this script like so:
-
Click the Browse button and navigate to a transcript XML file prepared in and exported from InqScribe.
This action opens the selected XML file for processing with the path to the file reflected in the box at the top of the GUI.
-
Click the Transform InqScribe to IOH XML button.
This action invokes the XSLT in Transform_InqScribe_to_IOH.xsl to transform the InqScribe XML <transcript> and <scene> tags into <cues> and <cue> tags reqiured for IOH ingest. It also transforms 'in' and 'out' attributes to <start> and <end> tags, and wraps the text of each <scene> inside <transcript> tags within each <cue>. Changes are saved in a new XML file named to match the input filename prefixed by IOH-. The new file is automatically 'selected' and its path now appears in the box at the top of the GUI.
-
Click the Convert hh:mm:ss to Seconds button.
This action converts <start> and <end> values from hours:minutes:seconds notation to the decimal seconds notation required for IOH. The changes are saved directly in the selected IOH- file. This file should be suitable for ingest into IOH.
-
Optionally click the Format Speakers button.
This action detects any/all <speaker> tags in the XML file and enumerates the speakers for subsequent formatting. It then re-reads the file looking for the first name (one word only!) of an enumerated speaker followed by a pipe (vertical bar character). Pipes are converted to colons. The following are all valid samples of speaker identifiers and transcript text taken from our example:
Heather | Okay, so.. Margo| Cool. Maggie | Where you live. Jenny| My name is JennyThe preceeding transcript snippet would be transformed to read as follows:
Heather: Okay, so.. Margo: Cool. Maggie: Where you live. Jenny: My name is JennyIf there are no errors, the format changes are written directly into the selected IOH- file. This file should be suitable for ingest into IOH with formatted speaker names.
The script reads an XML transcript in a format that can be easily created in and exported from InqScribe. The required format should look like the following example.
<transcript>
<prologue/>
<scene id="1" in="00:00:00.21" out="00:00:12.07"><speaker> Heather Riggs </speaker>
Heather | Okay, so.. Yeah, just before we start, if you could each go around and say your name, your class year, and where you live now, just for the microphone.</scene>
<scene id="2" in="00:00:12.08" out="00:00:18.02"><speaker> Margo Gray </speaker>
Margo | Cool. I’m Margo Gray of the class of 2005, and, what else am I saying?</scene>
<scene id="3" in="00:00:18.03" out="00:00:19.07">Heather | Your home.
<speaker> Maggie Montanaro </speaker>
Maggie | Where you live.</scene>
<scene id="4" in="00:00:19.08" out="00:00:21.14">Margo | I live in Chicago, Illinois.</scene>
<scene id="5" in="00:00:21.15" out="00:00:26.07"><speaker> Jenny Noyce </speaker>
Jenny | My name is Jenny Noyce, the class of 2005 and I live in Oakland, California.</scene>
<scene id="6" in="00:00:26.08" out="00:00:32.11">Maggie | I’m Maggie Montanaro, also class of 2005, and I live in Avignon, France.</scene>
<scene id="7" in="00:00:32.12" out="00:00:39.17">Heather | Wow. So, what are your strongest memories of Grinnell?</scene>
<scene id="8" in="00:00:39.18" out="00:00:45.05">Maggie | Harris Parties.</scene>
<scene id="9" in="00:00:45.06" out="00:00:53.00">Jenny | Mud sliding in the rain.
Maggie | Yeah, mud wrestling. Mud sliding on Mac Field. Lots and lots of work.</scene>
<scene id="10" in="00:00:53.01" out="00:01:30.27">Margo | I guess I remember people, like, I still am in touch with a lot of people from Grinnell and yeah. So I don’t, I mean I don’t have like
these really specific memories of like meeting people, but just mostly, like this whole sort of like pool of memories of times when I was hanging out with people or working with people or, yeah. Building the sort of, you don’t think of it when you’re there, it’s not like, "Ah, I’m building connections to last me!" You’re just like, "I’m hanging out with my friends." But those sort of things tend to last.
Maggie | Lots of good hanging out.
Margo | Yes.</scene>
<scene id="11" in="00:01:30.28" out="00:02:01.00">Heather | What kind of Harris parties did you have? Like themed...
Maggie | All the, I assume they still have them, the hall ones like the Haines Underwear Ball, the Mary B. James, Disco... what else? Lots of just themed…
Jenny | They started a fetish party.
Maggie | Really? They still have fetish?
Jenny | I never went to that one. Maybe I was too close-minded.
Maggie | Yeah.</scene>
<scene id="12" in="00:02:01.01" out="00:02:18.14">Heather | What are your first memories of Grinnell?
Attention! You may include as many <speaker> tags as you wish in your transcript, and they may occur ANYWHERE within the transcript, but only the first <speaker> tag in each <scene> will be recognized!
Output from the script should be an XML file with a format and content like the following:
<cues>
<cue>
<speaker>Heather Riggs</speaker>
<start>0.21</start>
<end>12.07</end>
<transcript><span class='oh_speaker_1'>Heather: <span class='oh_speaker_text'> Okay, so.. Yeah, just before we start, if you could each go around and say your name, your class year, and where you live now, just for the microphone.</span></span></transcript>
</cue>
<cue>
<speaker>Margo Gray</speaker>
<start>12.08</start>
<end>18.02</end>
<transcript><span class='oh_speaker_2'>Margo: <span class='oh_speaker_text'> Cool. I’m Margo Gray of the class of 2005, and, what else am I saying?</span></span></transcript>
</cue>
<cue>
<speaker>Heather Riggs & Maggie Montanaro</speaker>
<start>18.03</start>
<end>19.07</end>
<transcript><span class='oh_speaker_1'>Heather: <span class='oh_speaker_text'> Your home.</span></span><span class='oh_speaker_3'>Maggie: <span class='oh_speaker_text'> Where you live.</span></span></transcript>
</cue>
<cue>
<speaker>Margo Gray</speaker>
<start>19.08</start>
<end>21.14</end>
<transcript><span class='oh_speaker_2'>Margo: <span class='oh_speaker_text'> I live in Chicago, Illinois.</span></span></transcript>
</cue>
<cue>
<speaker>Jenny Noyce</speaker>
<start>21.15</start>
<end>26.07</end>
<transcript><span class='oh_speaker_4'>Jenny: <span class='oh_speaker_text'> My name is Jenny Noyce, the class of 2005 and I live in Oakland, California.</span></span></transcript>
</cue>
<cue>
<speaker>Maggie Montanaro</speaker>
<start>26.08</start>
<end>32.11</end>
<transcript><span class='oh_speaker_3'>Maggie: <span class='oh_speaker_text'> I’m Maggie Montanaro, also class of 2005, and I live in Avignon, France.</span></span></transcript>
</cue>
InqScribe allows the transcriber to define and use keyboard shortcuts that make it easy to add key elements to a transcript. The following are samples of InqScribe shortcuts used in conjunction with this script and associated workflow:


The first shortcut or "Snippet" defines:
- A timecode,
- <speaker> tag, and
- The speaker's first name with trailing pipe.
Snippets like this are intended to be used when a speaker is first encountered in a transcript.
The second snippet defines:
- A timecode, and
- The speaker's first name with trailing pipe.
Snippets like this are intended to be used only after the corresponding speaker has been encountered since only one <speaker> tag is required for each speaker in a given transcript file.
To take advantage of the script's "speaker formatting" capabilities you must add the following CSS, or something very similar, to your theme. This CSS produces coloring and formatting like that shown in the example above.
/* Color, display and font additions for Oral Histories */
div.tier.active span {
font-weight: bold;
}
div.tier.active span,
div.tier.active span span.oh_speaker_text {
color: black !important;
}
div.tier.active span span.oh_speaker_text {
font-weight: normal !important;
}
span.oh_speaker_text {
color: #ffff00 !important; /* yellow */
}
span.oh_speaker_1 {
display: block;
color: #00ffff; /* aqua */
}
span.oh_speaker_2 {
display: block;
color: #80ff00; /* bright green */
}
span.oh_speaker_3 {
display: block;
color: #ff0000; /* bright red */
}
span.oh_speaker_4 {
display: block;
color: #ff00ff; /* fuchsia */
}
span.oh_speaker_5 {
display: block;
color: #ffbf00; /* orange */
}
In June 2017 an additional "Reformat an Old Transcript" feature was added to the script. This feature may be specific to Grinnell College and to Digital Grinnell (https://digital.grinnell.edu), but it could easily be re-purposed for other, similar features.
The feature, as currently written, is designed to add speaker-formatting to older XML. Specificaly, it converts XML of the form...
<cues>
<cue>
<speaker>Camarin Madigan</speaker>
<start>0.16</start>
<end>45.29</end>
<transcript>My name is Camarin Madigan. When I went to Grinnell my name was... </transcript>
</cue>
...
</cues>
...into speaker-formatted XML of the form...
<cues>
<cue>
<speaker>Camarin Madigan</speaker>
<start>0.16</start>
<end>45.29</end>
<transcript><span class='oh_speaker_1'>Camarin: <span class='oh_speaker_text'>My name is Camarin Madigan. When I went to Grinnell my name was...</span></span></transcript>
</cue>