
- 首先分析网页类型, 这是典型的列表页+详情页的结构。
- 打开初始网页,打开开发者工具, 切换到network下, 观察最先加载的html文档, 打开预览, 发现没有数据, 说明数据可能是通过javescript渲染得到的;打开XHR, 果然找到了一个ajax请求。
- 观察这个请求,url结构有规律,且没有加密,那么列表页的数据基本上没有障碍了。
- 然后分析详情页, 点开列表中的链接, network中发现了对应的ajax请求, 查看url结构, 也是没有加密的, 那么详情页也没有障碍了。
- 在方法选择上, 采用aiohttp异步爬取是较为高效的, 为了加深对于不同爬虫方法的理解, 逐一尝试, 储存方式采用Mongodb。
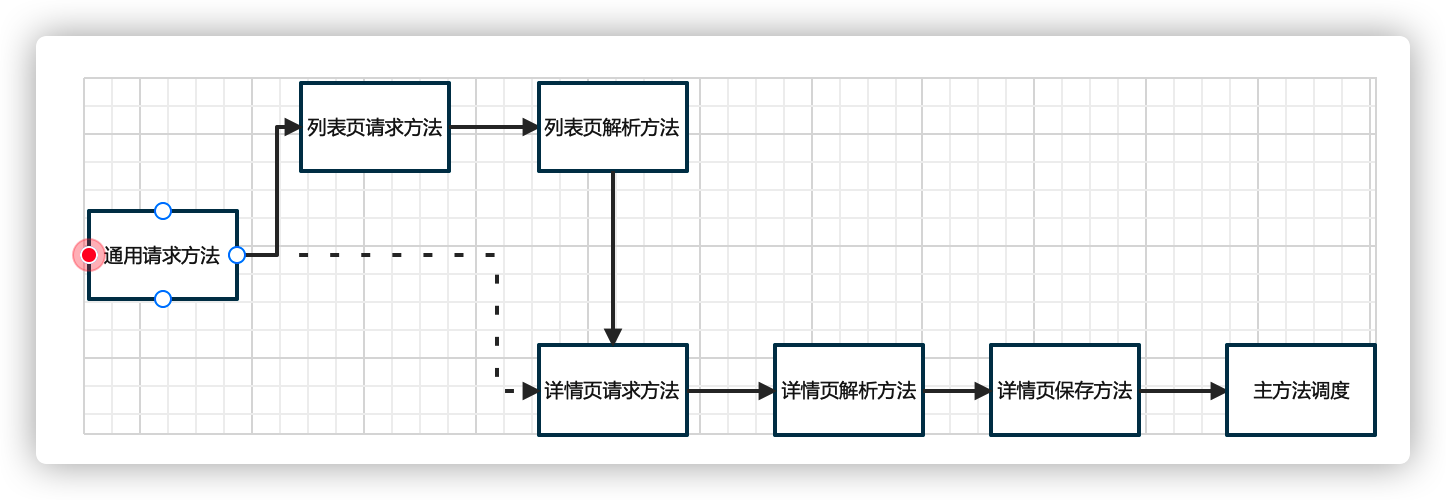
大体上,主要是建立了7个方法, 以降低代码的耦合度, 也利于调试和维护。
主体代码见同级目录下的py文件,命名方式是方法名。
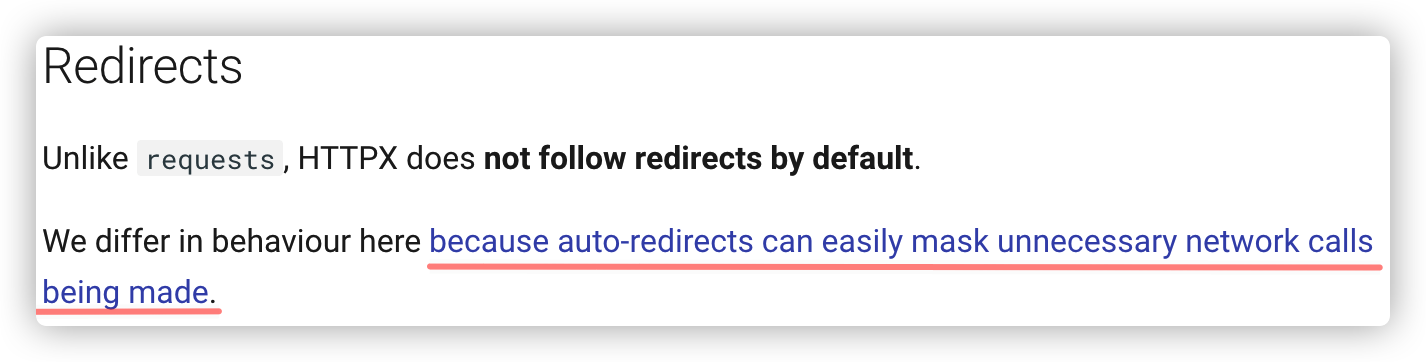
Q1:Httpx.py中请求详情页时显示301返回状态。

A1:httpx默认不开启重定向,需要手动打开,参数为'follow_redirects'
def Common_json(url):
with httpx.Client() as client:
r=client.get(url,headers=headers,follow_redirects=True) # 没有follow_redirects 则显示301报错,网页被永久移除,于是开启了重定向,但很容易定向到一些广告之类的网址。
return r.json()以下是官网解释:https://www.python-httpx.org/compatibility/
Q1:pyppeteer.py中浏览器无法隐藏提示条。
async def Init(): # 此处没有用内置的的chromium
global browser, tab
browser = await launch(filename='userdata',executablePath='/Applications/Google Chrome.app/Contents/MacOS/Google Chrome',headless=False,
args=['--disable-infobars']) # --disable-infobars隐藏提示条,但实测下来没有用,可能是因为指定了浏览器,自带的chromium则没有这个问题,但很容易崩溃。