forked from microsoft/nni
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[Retiarii] Transformer example (microsoft#4222)
- Loading branch information
1 parent
e779d7f
commit 28c686a
Showing
2 changed files
with
226 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,19 @@ | ||
| # Tuning Transformer with Retiarii | ||
|
|
||
| This demo is adapted from PyTorch Transformer tutorial. | ||
| Here, we show how we use functions provided by retiarii to tune Transformer's hyper-parameters, in order to achieve better performance. | ||
| This demo is tested with PyTorch 1.9, torchtext == 0.10, and nni == 2.4. | ||
| Please change the configurations (starting on line 196) accordingly and then run: `python retiarii_transformer_demo.py` | ||
|
|
||
| We use a built-in dataset provided by torchtext, WikiText-2, to evaluate Transformer on language modeling. We tune two hyper-parameters: the number of encoder layers (`n_layer`) whose default value in the original paper is 6, and the dropout rate shared by all encoder layers (`p_dropout`) whose default value is 0.1. We report validation perplexity as metric (the lower is better). | ||
|
|
||
| We first tune one hyper-parameter with another fixed to the default value. The results are: | ||
| 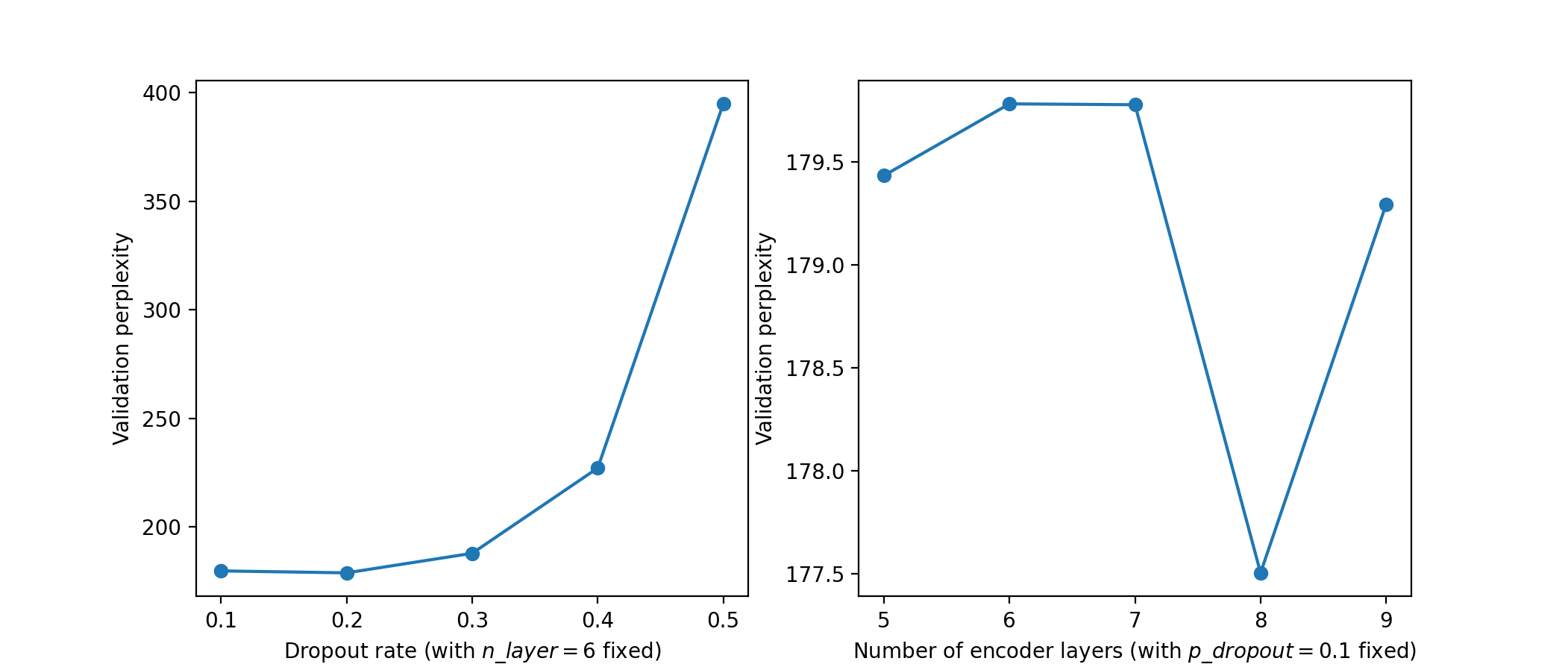 | ||
|
|
||
| And then we tune these two hyper-parameters jointly. The results are: | ||
| <p align="center"> | ||
| <img src="https://user-images.githubusercontent.com/22978940/136937807-342fde98-6498-4cdd-abdd-4633fd15b7dc.png" width="700"> | ||
| </p> | ||
|
|
||
| As we can observe, we have found better hyper-parameters (`n_layer = 8`, `p_dropout = 0.2`) than default values. | ||
|
|
207 changes: 207 additions & 0 deletions
207
examples/nas/multi-trial/transformer/retiarii_transformer_demo.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,207 @@ | ||
| ############################################################### | ||
| # This demo is adapted from PyTorch Transformer tutorial <https://pytorch.org/tutorials/beginner/transformer_tutorial.html> | ||
| # Here we show how we use functions provided by retiarii to tune Transformer's hyper-parameters, | ||
| # in order to achieve better performance. | ||
| # This demo is tested with PyTorch 1.9, torchtext == 0.10, and nni == 2.4 | ||
| import torch | ||
| import torch.nn.functional as F | ||
| import nni.retiarii.nn.pytorch as nn | ||
| from nni.retiarii import model_wrapper | ||
| import nni | ||
| import nni.retiarii.strategy as strategy | ||
| from nni.retiarii.evaluator import FunctionalEvaluator | ||
| from nni.retiarii.experiment.pytorch import RetiariiExperiment, RetiariiExeConfig | ||
|
|
||
| import math | ||
|
|
||
| from torchtext.datasets import WikiText2 | ||
| from torchtext.data.utils import get_tokenizer | ||
| from torchtext.vocab import build_vocab_from_iterator | ||
|
|
||
| class PositionalEncoding(nn.Module): | ||
|
|
||
| def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000): | ||
| super().__init__() | ||
| self.dropout = nn.Dropout(p=dropout) | ||
|
|
||
| position = torch.arange(max_len).unsqueeze(1) | ||
| div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model)) | ||
| pe = torch.zeros(max_len, 1, d_model) | ||
| pe[:, 0, 0::2] = torch.sin(position * div_term) | ||
| pe[:, 0, 1::2] = torch.cos(position * div_term) | ||
| self.register_buffer('pe', pe) | ||
|
|
||
| def forward(self, x): | ||
| """ | ||
| Args: | ||
| x: Tensor, with size [seq_len, batch_size, embedding_dim] | ||
| """ | ||
| x = x + self.pe[:x.size(0)] | ||
| return self.dropout(x) | ||
|
|
||
| ############################################################### | ||
| # PyTorch has already provided modules for Transformer: nn.TransformerEncoderLayer and nn.TransformerEncoder, | ||
| # so we can use them directly, but note that to enable retiarii functions, we need to replace "import torch.nn as nn" | ||
| # with "import nni.retiarii.nn.pytorch as nn". | ||
| # | ||
| # We use nn.ValueChoice to make the number of encoder layers (the default is 6) and the dropout rate mutable. | ||
| # For other hyper-parameters, we follow the setting in the original paper "Attention is All You Need". | ||
| @model_wrapper # This decorator should be put on the top level module. | ||
| class Transformer(nn.Module): | ||
|
|
||
| def __init__(self, n_token: int, n_head: int = 8, | ||
| d_model: int = 512, d_ff: int = 2048): | ||
| super().__init__() | ||
| p_dropout = nn.ValueChoice([0.1, 0.2, 0.3, 0.4, 0.5], label='p_dropout') | ||
| n_layer = nn.ValueChoice([5, 6, 7, 8, 9], label='n_layer') | ||
| self.encoder = nn.TransformerEncoder( | ||
| nn.TransformerEncoderLayer(d_model, n_head, d_ff, p_dropout), | ||
| n_layer | ||
| ) | ||
| self.d_model = d_model | ||
| self.decoder = nn.Linear(d_model, n_token) | ||
| self.embeddings = nn.Embedding(n_token, d_model) | ||
| self.position = PositionalEncoding(d_model) | ||
|
|
||
| def forward(self, src, src_mask): | ||
| """ | ||
| Args: | ||
| src: Tensor, with size [seq_len, batch_size] | ||
| src_mask: Tensor, with size [seq_len, seq_len] | ||
| Returns: | ||
| output: Tensor, with size [seq_len, batch_size, n_token] | ||
| """ | ||
| src = self.embeddings(src) * math.sqrt(self.d_model) | ||
| src = self.position(src) | ||
| output = self.encoder(src, src_mask) | ||
| output = self.decoder(output) | ||
| return output | ||
|
|
||
| ############################################################### | ||
| # We wrap the whole training procedure in the fit function. | ||
| # This function takes one positional argument model_cls which represents one exploration (i.e., one trial). | ||
| # model_cls is automatically generated and passed in by retiarii, and we should instantiate model_cls | ||
| # through model = model_cls() | ||
| def fit(model_cls): | ||
|
|
||
| train_iter = WikiText2(split='train') | ||
| tokenizer = get_tokenizer('basic_english') | ||
| vocab = build_vocab_from_iterator(map(tokenizer, train_iter), specials=['<unk>']) | ||
| vocab.set_default_index(vocab['<unk>']) | ||
|
|
||
| def process_data(raw_text_iter): | ||
| """Converts raw text into a flat Tensor.""" | ||
| data = [torch.tensor(vocab(tokenizer(item)), dtype=torch.long) for item in raw_text_iter] | ||
| return torch.cat(tuple(filter(lambda t: t.numel() > 0, data))) | ||
|
|
||
| train_iter, val_iter, _ = WikiText2() | ||
| train_data = process_data(train_iter) | ||
| val_data = process_data(val_iter) | ||
|
|
||
| device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') | ||
|
|
||
| def generate_batches(data, bsz): | ||
| """Divides the data into bsz separate sequences.""" | ||
| seq_len = data.size(0) // bsz | ||
| data = data[:seq_len * bsz] | ||
| data = data.view(bsz, seq_len).t().contiguous() | ||
| return data.to(device) | ||
|
|
||
| batch_size = 20 | ||
| eval_batch_size = 10 | ||
| train_data = generate_batches(train_data, batch_size) | ||
| val_data = generate_batches(val_data, eval_batch_size) | ||
|
|
||
| seq_len = 35 | ||
| def get_seq(source, i): | ||
| """ | ||
| Args: | ||
| source: Tensor, with size [full_seq_len, batch_size] | ||
| i: int | ||
| Returns: | ||
| tuple (data, target): data has size [seq_len, batch_size] | ||
| and target has size [seq_len * batch_size] | ||
| """ | ||
| part_len = min(seq_len, len(source) - 1 - i) | ||
| data = source[i:i+part_len] | ||
| target = source[i+1:i+1+part_len].reshape(-1) | ||
| return data, target | ||
|
|
||
| def generate_square_subsequent_mask(sz): | ||
| """Generates an upper-triangular matrix of -inf, with zeros on diag.""" | ||
| return torch.triu(torch.ones(sz, sz) * float('-inf'), diagonal=1) | ||
|
|
||
| model = model_cls().to(device) | ||
| lr = 5.0 | ||
| optimizer = torch.optim.SGD(model.parameters(), lr=lr) | ||
| scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95) | ||
|
|
||
| def train(model): | ||
| model.train() | ||
| src_mask = generate_square_subsequent_mask(seq_len).to(device) | ||
| for i in range(0, train_data.size(0) - 1, seq_len): | ||
| data, target = get_seq(train_data, i) | ||
| part_len = data.size(0) | ||
| if part_len != seq_len: | ||
| src_mask = src_mask[:part_len, :part_len] | ||
| output = model(data, src_mask) | ||
| loss = F.cross_entropy(output.view(-1, output.size(-1)), target) | ||
|
|
||
| optimizer.zero_grad() | ||
| loss.backward() | ||
| torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5) | ||
| optimizer.step() | ||
|
|
||
| def evaluate(model, eval_data): | ||
| model.eval() | ||
| src_mask = generate_square_subsequent_mask(seq_len).to(device) | ||
| total_loss = 0. | ||
| with torch.no_grad(): | ||
| for i in range(0, eval_data.size(0) - 1, seq_len): | ||
| data, target = get_seq(eval_data, i) | ||
| part_len = data.size(0) | ||
| if part_len != seq_len: | ||
| src_mask = src_mask[:part_len, :part_len] | ||
| output = model(data, src_mask) | ||
| output_flat = output.view(-1, output.size(-1)) | ||
| total_loss += part_len * F.cross_entropy(output_flat, target).item() | ||
| return total_loss / (len(eval_data) - 1) | ||
|
|
||
| best_val_loss = float('inf') | ||
|
|
||
| for epoch in range(20): | ||
| train(model) | ||
| val_loss = evaluate(model, val_data) | ||
| if val_loss < best_val_loss: | ||
| best_val_loss = val_loss | ||
| scheduler.step() | ||
|
|
||
| best_val_ppl = math.exp(best_val_loss) | ||
| nni.report_final_result(best_val_ppl) # reports best validation ppl to nni as final result of one trial | ||
|
|
||
| if __name__ == "__main__": | ||
|
|
||
| train_iter = WikiText2(split='train') | ||
| tokenizer = get_tokenizer('basic_english') | ||
| vocab = build_vocab_from_iterator(map(tokenizer, train_iter), specials=['<unk>']) | ||
| vocab.set_default_index(vocab['<unk>']) | ||
|
|
||
| n_token = len(vocab) | ||
| base_model = Transformer(n_token) | ||
|
|
||
| evaluator = FunctionalEvaluator(fit) | ||
| exp = RetiariiExperiment(base_model, evaluator, [], strategy.Random()) | ||
| exp_config = RetiariiExeConfig('local') | ||
| exp_config.experiment_name = 'transformer tuning' | ||
| exp_config.trial_concurrency = 3 # please change configurations accordingly | ||
| exp_config.max_trial_number = 25 | ||
| exp_config.trial_gpu_number = 1 | ||
| exp_config.training_service.use_active_gpu = False | ||
| export_formatter = 'dict' | ||
|
|
||
| exp.run(exp_config, 8081) | ||
| print('Final model:') | ||
| for model_code in exp.export_top_models(optimize_mode='minimize', formatter=export_formatter): | ||
| print(model_code) |