
HTML-парсер на чистом Java, поддерживающий синтаксис стандарта W3C Xpath 1.0. HTML-парсер на основе Jsoup и Antlr4. Возможно, это лучший в своем роде на Java, просто попробуйте.
JsoupXpath - это HTML-анализатор на чистом Java, который использует Xpath для извлечения данных из HTML-файлов. Целиком переосмыслена стандартная грамматика W3C XPATH 1.0 для HTML, анализаторы и парсеры Xpath построены на базе Antlr4, а дерево DOM для HTML создается при помощи Jsoup, отсюда и название - JsoupXpath. Для того, чтобы насладиться мощью и удобством Xpath на Java, но, одновременно, испытывая трудности при поиске подходящего Xpath-разборщика, был создан JsoupXpath. Реализация в JsoupXpath четко структурирована и легко расширяема, обеспечивая полную поддержку стандарта W3C XPath 1.0. Описание стандарта W3C: http://www.w3.org/TR/1999/REC-xpath-19991116 . Файл описания грамматики JsoupXpath Xpath.g4.
https://github.com/zhegexiaohuozi/JsoupXpath/releases
- Задачи (Issues)
https://github.com/zhegexiaohuozi/JsoupXpath/issues
- Микросайт в WeChat

В нем публикуются примеры использования и статьи, а также информацию о последних обновлениях связанных проектов. Автор также выкладывает статьи и свои рефлекции о некоторых технологиях и направлениях в интернет-технологиях.
Зависимость для Maven, полностью доступна на странице релизов или на централизованном репозитории Maven:
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>JsoupXpath</artifactId>
<version>2.5.3</version>
</dependency>
Пример:
Строка html = "<html><body><script>console.log('aaaaa')</script><div class='test'>some body</div><div class='xiao'>Two</div></body></html>";
JXDocument underTest = JXDocument.create(html);
Строка xpath = "//div[contains(@class,'xiao')]/text()";
JXNode node = underTest.selNOne(xpath);
Assert.assertEquals("Two",node.asString());
Другие примеры можно найти в org.seimicrawler.xpath.JXDocumentTest, там представлена масса тестовых случаев.
Или вы можете посмотреть типичные примеры в разделе Issue.
Поддерживается полный синтаксис стандартной спецификации W3C XPATH 1.0, спецификация W3C: http://www.w3.org/TR/1999/REC-xpath-19991116
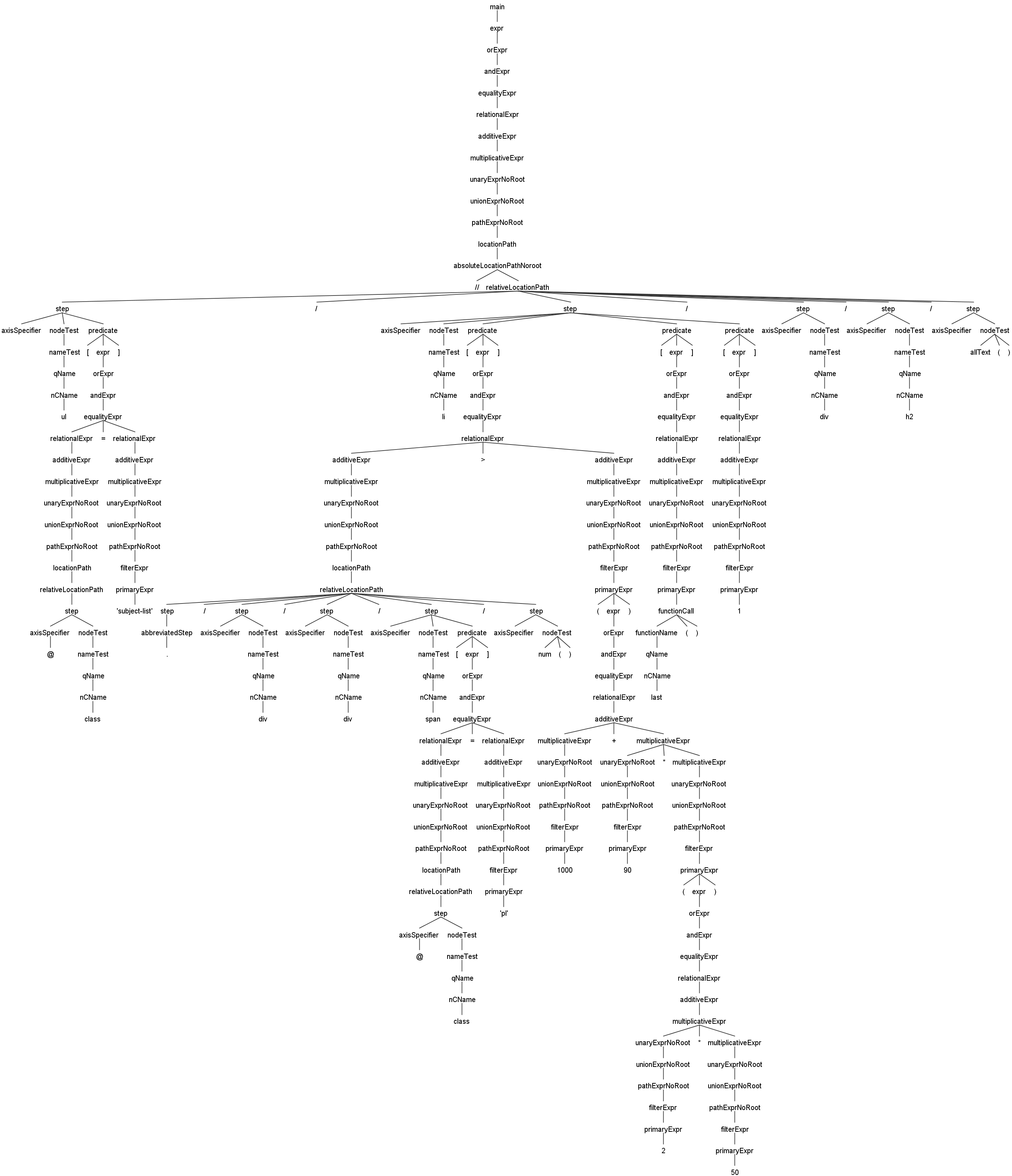
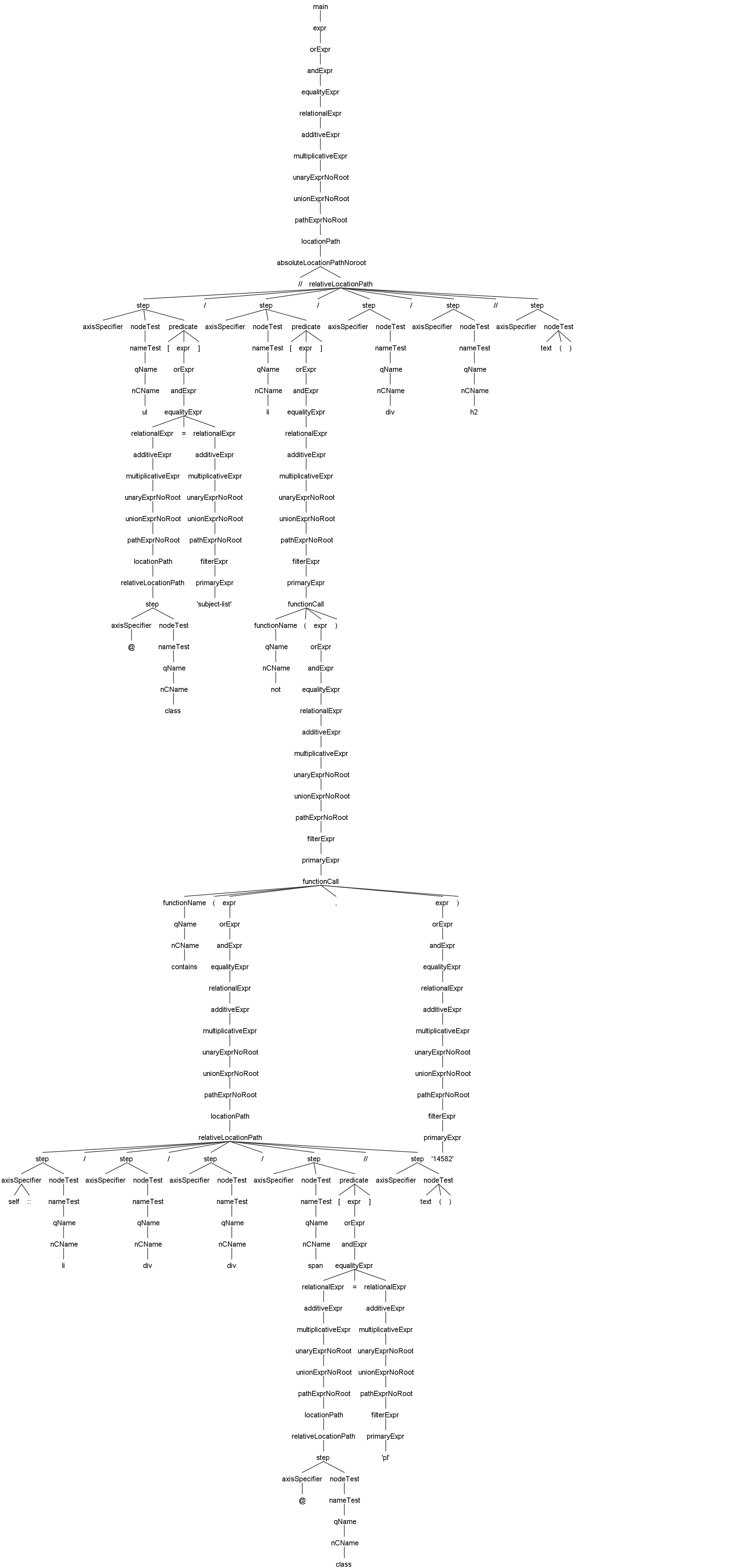
Вот пример дерева разбора синтаксиса JsoupXpath на основе Antlr4, что облегчает общий обзор способностей JsoupXpath по обработке синтаксиса и процесс разбора и выполнения синтаксиса.
-
//ul[@class='subject-list']/li[./div/div/span[@class='pl']/num()>(1000+90*(2*50))][last()][1]/div/h2/allText()Этот пример в основном показывает парсинг вложенных выражений, на изображении можно увидеть полноразмерный вариант. -
//ul[@class='subject-list']/li[not(contains(self::li/div/div/span[@class='pl']//text(),'14582'))]/div/h2//text()Этот пример демонстрирует анализ поддерживаемых встроенных функций. Вы можете увеличить изображение для большей ясности.
Большинство ситуаций не рекомендует простое копирование XPath, сгенерированного Firefox или chrome. Эти браузеры при отображении страниц автоматически дополняют некоторые теги в соответствии со стандартами, например, теги таблицы автоматически обновляются тегами tbody, и поэтому сгенерированный путь XPath, очевидно, не является наиболее общим. Вероятнее всего, он не сможет получить данные. Поэтому для использования XPath и для того, чтобы испытать силу XPath, а также удобство и элегантность, которые он приносит, лучше всего ознакомиться со стандартным синтаксисом XPath. Таким образом, вы сможете подойти к решению различных проблем с уверенностью и наслаждаться истинной мощью XPath!
-
int position()возвращает текущую позицию узла в его контексте -
int last()возвращает позицию последнего узла в контексте -
int first()возвращает позицию первого узла в контексте -
string concat(string, string, string*)объединяет несколько строк -
boolean contains(string, string)определяет, содержит ли первая строка вторую -
int count(node-set)подсчитывает количество узлов в заданном наборе узлов -
double/long sum(node-set)вычисляет сумму значений числовых узлов в заданном наборе узлов, вычисление недействительно, если в параметрах содержится нечисловое значение. -
boolean starts-with(string, string)определяет, начинается ли первая строка с второй -
int string-length(string?)возвращает длину строки, если она указана, в другом случае преобразует текущий узел в строку и возвращает длину -
string substring(string, number, number?)первый параметр задает строку, второй определяет начальную позицию (индексы XPath начинаются с 1), третий определяет длину извлеченного отрезка, следует заметить, что, согласно синтаксису XPath, это не конечная позиция.substring("12345", 1.5, 2.6) возвращает "234"
substring("12345", 2, 3) вернет "234"
-
string substring-ex(string, number, number)первый параметр задает строку, второй определяет начальную позицию (по привычке Java c нуля) и третий - конечная позиция (поддерживает отрицательные числа), это функция, расширяющая JsoupXpath, удобная для разработчиков привыкших к стилю Java. -
string substring-after(string, string)извлекает часть первой строки после второго строки -
string substring-after-last(string, string)извлекает часть первой строки после последнего появления второй строки -
string substring-before(string, string)извлекает часть первой строки до появления второй строки -
string substring-before-last(string, string)извлекает часть первой строки до последнего появления второй строки -
format-date(date, string ,string)первый параметр - это выражение, второй - выражение времени в формате, третий параметр - локалязированная часовой пояс, является необязательным
Выше перечислены только функции standards XPath 1.0. Разработчики могут легко добавлять свои собственные функции, реализовав интерфейс org.seimicrawler.xpath.core.Function.java и вызвав Scanner.registerFunction(Class<? extends Function> func) в момент инициализации системы. Нет необходимости модифицировать синтаксическое соглашение, JsoupXpath может идентифицировать и загрузить их во время выполнения. По поводу функций текущего стандарта, которые еще не реализованы в JsoupXpath, мы рады прибытию Pull request в основной репозиторий, чтобы вместе улучшить его.
allText()извлекает все текстовые данные из узла, заменяя expressions вида//div/h3//text()html()получает весь HTML внутри узлаouterHtml()извлекает все HTML, включая сам узелnum()извлекает все числа из собственного текста узла, если известно, что в тексте узла, не связанного с его дочерними элементами (т.е. абсолютно свой текст узла), присутствует всего одно число, как например, объем чтений, число комментариев, стоимость и т.д., то это число можно сразу извлечь. Если чисел несколько, извлечется первое соответствующее попадание.text()получает собственный текст узлаnode()извлекает все узлы
AxisName: 'ancestor' //выбор среди предков узла в текущем контексте
| 'ancestor-or-self' //выбор среди предков узла и самого себя в текущем контексте
| 'attribute' //извлечение атрибутов узла
| 'child' //выбор среди дочерних узлов узла в текущем контексте. Это стандартная ось XPath, например, /div/li эквивалентно /div/child::li
| 'descendant' //выбор среди потомков узла в текущем контексте
| 'descendant-or-self' //выбор среди потомков узла включая само узла в текущем контексте
| 'following' //выбор среди всех узлов после текущего узла в контексте
| 'following-sibling' //выбор всех последующих ссыльных братьев узла в текущем контексте
| 'parent' //выбор родительского узла узла в текущем контексте
| 'preceding' //выбор всех узлов перед текущим узлом в контексте
| 'preceding-sibling' //выбор всех предыдущих ссыльных братьев узла в текущем контексте
| 'self' //выбор в текущем контексте
| 'following-sibling-one' //выбор следующего ссыльного брата узла в контексте (расширение JsoupXpath)
| 'preceding-sibling-one' //выбор предыдущего ссыльного брата узла в контексте (расширение JsoupXpath)
| 'sibling' //все ссыльные братья (расширение JsoupXpath) (в разработке...)
;
MINUS
: '-';
PLUS
: '+';
DOT
: '.';
MUL
: '*';
DIVISION
: '`div`';
MODULO
: '`mod`';
DOTDOT
: '..';
AT
: '@';
COMMA
: ',';
PIPE
: '|';
LESS
: '<';
MORE_
: '>';
LE
: '<=';
GE
: '>=';
START_WITH
: '^='; // `a^=b` строка начинается с "b" (расширение JsoupXpath)
END_WITH
: '$='; // `a*=b` a содержит b (расширение JsoupXpath)
CONTAIN_WITH
: '*='; // a содержит b (расширение JsoupXpath)
REGEXP_WITH
: '~='; // содержимое a соответствует регулярному выражению b (расширение JsoupXpath)
REGEXP_NOT_WITH
: '!~'; // содержимое a не соответствует регулярному выражению b (расширение JsoupXpath)
Сейчас JsoupXpath используется во многих проектах или организациях включая SeimiCrawler. Если вы также используете JsoupXpath в своем проекте, и вы хотите, чтобы ваш проект был в этом списке, вы можете связаться со мной по следующим контактам в формате электронного письма:
Название проекта или организации: XX
URL проекта или организации: http://xxx.xxx.cc