-
Notifications
You must be signed in to change notification settings - Fork 0
/
Copy pathdb.json
1 lines (1 loc) · 538 KB
/
db.json
1
{"meta":{"version":1,"warehouse":"1.0.3"},"models":{"Asset":[{"_id":"themes/landscape/source/js/script.js","path":"js/script.js","modified":1},{"_id":"themes/landscape/source/fancybox/jquery.fancybox.pack.js","path":"fancybox/jquery.fancybox.pack.js","modified":1},{"_id":"themes/landscape/source/fancybox/jquery.fancybox.js","path":"fancybox/jquery.fancybox.js","modified":1},{"_id":"themes/landscape/source/fancybox/jquery.fancybox.css","path":"fancybox/jquery.fancybox.css","modified":1},{"_id":"themes/landscape/source/fancybox/helpers/jquery.fancybox-thumbs.js","path":"fancybox/helpers/jquery.fancybox-thumbs.js","modified":1},{"_id":"themes/landscape/source/fancybox/helpers/jquery.fancybox-thumbs.css","path":"fancybox/helpers/jquery.fancybox-thumbs.css","modified":1},{"_id":"themes/landscape/source/fancybox/helpers/jquery.fancybox-media.js","path":"fancybox/helpers/jquery.fancybox-media.js","modified":1},{"_id":"themes/landscape/source/fancybox/helpers/jquery.fancybox-buttons.js","path":"fancybox/helpers/jquery.fancybox-buttons.js","modified":1},{"_id":"themes/landscape/source/fancybox/helpers/jquery.fancybox-buttons.css","path":"fancybox/helpers/jquery.fancybox-buttons.css","modified":1},{"_id":"themes/landscape/source/fancybox/helpers/fancybox_buttons.png","path":"fancybox/helpers/fancybox_buttons.png","modified":1},{"_id":"themes/landscape/source/fancybox/fancybox_sprite@2x.png","path":"fancybox/fancybox_sprite@2x.png","modified":1},{"_id":"themes/landscape/source/fancybox/fancybox_sprite.png","path":"fancybox/fancybox_sprite.png","modified":1},{"_id":"themes/landscape/source/fancybox/fancybox_overlay.png","path":"fancybox/fancybox_overlay.png","modified":1},{"_id":"themes/landscape/source/fancybox/fancybox_loading@2x.gif","path":"fancybox/fancybox_loading@2x.gif","modified":1},{"_id":"themes/landscape/source/fancybox/fancybox_loading.gif","path":"fancybox/fancybox_loading.gif","modified":1},{"_id":"themes/landscape/source/fancybox/blank.gif","path":"fancybox/blank.gif","modified":1},{"_id":"themes/landscape/source/css/style.styl","path":"css/style.styl","modified":1},{"_id":"themes/landscape/source/css/images/banner.jpg","path":"css/images/banner.jpg","modified":1},{"_id":"themes/landscape/source/css/fonts/fontawesome-webfont.woff","path":"css/fonts/fontawesome-webfont.woff","modified":1},{"_id":"themes/landscape/source/css/fonts/fontawesome-webfont.ttf","path":"css/fonts/fontawesome-webfont.ttf","modified":1},{"_id":"themes/landscape/source/css/fonts/fontawesome-webfont.svg","path":"css/fonts/fontawesome-webfont.svg","modified":1},{"_id":"themes/landscape/source/css/fonts/fontawesome-webfont.eot","path":"css/fonts/fontawesome-webfont.eot","modified":1},{"_id":"themes/landscape/source/css/fonts/FontAwesome.otf","path":"css/fonts/FontAwesome.otf","modified":1}],"Cache":[{"_id":"source/_posts/AIO.md","shasum":"5c7c54313fc823ca4d175f0ed248c3c135443eb4","modified":1449135338726},{"_id":"source/_drafts/Hibernate-事务管理和并发控制.md","shasum":"36e40aea56a0a8834de705bfa812c2b09e0470c0","modified":1449031175618},{"_id":"source/_posts/HashMap 和 HashTable的区别.md","shasum":"3680474d8dfa6f6b02d079d35cf3450c3d428fd4","modified":1449031175619},{"_id":"source/_posts/Abstract 与 Interface的区别.md","shasum":"637704e1f32e0dfbe92fa4e315154cf13d50ea5f","modified":1449031175619},{"_id":"source/_posts/Hibernate 基本配置及操作.md","shasum":"249e803c20bc0c74de72e0c42685ec559faf482c","modified":1449031175620},{"_id":"source/_posts/JAVA-NIO-Netty.md","shasum":"ebc4ea02355aa37e2db4e54ef35872e8aef5ff3f","modified":1449716193053},{"_id":"source/_posts/Hibernate高级映射.md","shasum":"23cb50dcb3db2426414e47bad3cafb95efb5a9f6","modified":1449031175621},{"_id":"source/_posts/Hibernate 数据查询.md","shasum":"f3767091f937e03f8332fafe89173d68b3c9a371","modified":1449034315702},{"_id":"source/_posts/IO-Contrast.md","shasum":"892814afa3fda5b84e0b47adc975378f344dfb56","modified":1449474326580},{"_id":"source/_posts/NIO-Programing.md","shasum":"303b6dcd5519ed46582584b9e80ffce7405ce886","modified":1449717090259},{"_id":"source/_posts/NIO-Introduce-Abstractly.md","shasum":"482dedd74528c52ebb666857b712f2fc64011fb0","modified":1449031682085},{"_id":"source/_posts/Java中的一些概念.md","shasum":"7e4ce816d74c9f0f33aaf81ad00bb06b93f82468","modified":1449031175621},{"_id":"source/_posts/Java 终结处理&垃圾回收.md","shasum":"e55018b9faaa4abfbbf30204a12aa9189ceaf982","modified":1449031175621},{"_id":"source/_posts/Path ClassPath 的区别.md","shasum":"cdf151f73c1efeb242b47cdfb05a76dff39d8890","modified":1449031175623},{"_id":"source/_posts/ORM(Object Relation Mapping).md","shasum":"eb6947a5765ffdbdd187a72b72943491096cfbad","modified":1449031175622},{"_id":"source/_posts/Singleton.md","shasum":"fdc76cabfd4d1787879bd16729de6555d461b7c5","modified":1451279762346},{"_id":"source/_posts/Struts validate验证框架配置使用.md","shasum":"35a0dac61f9dd10dd7c07be531d9b82fead0331c","modified":1449031175623},{"_id":"source/_posts/Struts 工作原理.md","shasum":"dbb4f70c4f425d514d662652315385226d22c1c7","modified":1449031175623},{"_id":"source/_posts/PYTHON YIELD 使用浅析.md","shasum":"9ec085b922a1018bb1cab756bc58c48b3afa9c5b","modified":1449031175622},{"_id":"source/_posts/NIO-library.md","shasum":"f69eee80deed478aebc8dfdb8134404ebbf2f579","modified":1449107396728},{"_id":"source/_posts/Python 工具总结.md","shasum":"b1b7ddf1651bb2e8ad7e50b3ddd2662bdc85a687","modified":1449031175623},{"_id":"source/_posts/Struts (V-1.3.8) 应用概述.md","shasum":"fd88d54b99fe046233de98c43723b8d3cbd73887","modified":1449031175624},{"_id":"source/_posts/check-linux-version.md","shasum":"12d586dd86b69b8169ab9beb5c0d85a3238f43b1","modified":1450418128513},{"_id":"source/_posts/Struts 标签.md","shasum":"bf3003f0010d85a1bcc247fa2a90fb57df332b48","modified":1449031175624},{"_id":"source/_posts/XML Schema 和 DTD的区别.md","shasum":"3aa3c2baf938f677e41d8608d27403a35e49273f","modified":1449031175625},{"_id":"source/_posts/flask-mysql-migrate.md","shasum":"5fdaf50aa05436d9c107cbb566154eecb5404078","modified":1449031175626},{"_id":"source/_posts/hexo-commands.md","shasum":"b0bad536654b7487c7d9bae617c9953b33bdcb2e","modified":1449031175627},{"_id":"source/_posts/fibonacci.md","shasum":"51a0496d8750a764caa810b6c8a6852c98ff0aa6","modified":1449031175626},{"_id":"source/_posts/java 打印素数.md","shasum":"c7d74135b50b04b62e5619873d52bb229f872537","modified":1449031175627},{"_id":"source/_posts/Sublime Text 2 插件安装.md","shasum":"2b9e303ce0bf9f785d1507da264b9ffe65dc895a","modified":1449031175624},{"_id":"source/_posts/java 集合类.md","shasum":"ab8b3ae93c075ddcde6b2213fcf60403a60a1116","modified":1449031175628},{"_id":"source/_posts/fibonacci-2.md","shasum":"f4727f5bd5ed9b5026ccacdd88e0b34ebace8f16","modified":1449031175625},{"_id":"source/_posts/java-environment.md","shasum":"555ad40fbb1da0746932ed1e58aae8e4dfc9ca73","modified":1458019592837},{"_id":"source/_posts/java-exception.md","shasum":"fea9b4fb0a372406e753f33625a82722b51227aa","modified":1449031175629},{"_id":"source/_posts/java-I-O-2.md","shasum":"5a9c4bfefb4ded23ba263a44563d4c401eafe169","modified":1449031175628},{"_id":"source/_posts/markdown.md","shasum":"3db8897513656214c2acfd30ab15e729adff3fa8","modified":1449031175629},{"_id":"source/_posts/how-to-remove-duplicates-elements-from-arraylist-in-java.md","shasum":"5dbd5cf7d7b0a0be2af1330102633ab2d442aff3","modified":1449031175627},{"_id":"source/_posts/python scrapy.md","shasum":"391a75af0eb5e6489c3126f9fefb04c931e5fcf7","modified":1449031175630},{"_id":"source/_posts/python-scrapymongodb.md","shasum":"1306e3440e650cc73989d2a31c345a57ccfd627c","modified":1449031175630},{"_id":"source/_posts/java-I-O.md","shasum":"0f75f4443c753d5a5270eeb4734ea30b35b14a0b","modified":1449031175629},{"_id":"source/_posts/struts-advanced.md","shasum":"a250e24357b620f002ccbda21c11e62fb0d41a35","modified":1449031175631},{"_id":"source/_posts/producer-consumer-problem.md","shasum":"d59bc21628fc84f4c2b520ab325b8a0b957d27ab","modified":1449031175630},{"_id":"source/_posts/struts-login-demo.md","shasum":"536c1ac739b59818c1e542c24acf1596d303eb85","modified":1449031175632},{"_id":"source/_posts/struts-tiles.md","shasum":"57abc7f077062de88b632701c939c69ceb6cc3ab","modified":1449031175632},{"_id":"source/_posts/struts-components.md","shasum":"0a54b11a139fe4ae5f2abb23d9ebcd8803599444","modified":1449031175631},{"_id":"source/_posts/socket blocking noblocking IO model.md","shasum":"3aeee642eec60c77ece62ebe5e31006e5e47623e","modified":1449031175631},{"_id":"source/_posts/对象入门.md","shasum":"f97634bddb7cbc61a7b55f2e50eb3e6df4ac7a6b","modified":1449031175633},{"_id":"source/_posts/java-object-method.md","shasum":"dd92071b43ee45c6bc2b644d660f4b6d8877275d","modified":1449031175629},{"_id":"source/_posts/版本控制概述.md","shasum":"1590b6536632e3a2eae340d7cae53aa77c205c28","modified":1449031175634},{"_id":"source/about/index.md","shasum":"42a82cf6c84068c3096d1f1726b470a32a37381b","modified":1449031175634},{"_id":"source/python-books-for-data-analysis/index.md","shasum":"a224e7e05365e582be5414c9f9dc9bdc1fa66619","modified":1449031175635},{"_id":"source/_drafts/一切都是对象.md","shasum":"9db5306e944895543c1d6cb5f97c7bc6d1384829","modified":1449031175619},{"_id":"source/_posts/死锁及如何避免.md","shasum":"a88907eaf2efe12d54b5e79ee656c9230a98fcf7","modified":1449031175633},{"_id":"source/_posts/网络爬虫.md","shasum":"ac7adaa897d6bafb12cf5126f6f2dda54a5de140","modified":1449031175634},{"_id":"source/_posts/操纵Session.md","shasum":"afcf06f0c880d5d197200d9c2be54b558ef4df66","modified":1449031175633},{"_id":"themes/landscape/Gruntfile.js","shasum":"412e30530784993c8997aa8b1319c669b83b91c2","modified":1449031175635},{"_id":"themes/landscape/_config.yml","shasum":"c59ab5713d13ab0a147c5275f8aae96aa0beeac6","modified":1449031175636},{"_id":"themes/landscape/layout/_partial/archive-post.ejs","shasum":"5062c723721d8497eebad372f57092ade45041f4","modified":1449031175637},{"_id":"themes/landscape/LICENSE","shasum":"82ce1e15ddeabeaaca60e2186b5a3ce42b1a9c49","modified":1449031175636},{"_id":"themes/landscape/layout/_partial/article.ejs","shasum":"46e1ab7f03a7d5a8d15e61c5a8d04ca3d0265047","modified":1449031175638},{"_id":"themes/landscape/layout/_partial/footer.ejs","shasum":"29849f7d8f34acf80fc1a2bfd11a935581c32e3d","modified":1449031175638},{"_id":"themes/landscape/layout/_partial/google-analytics.ejs","shasum":"1ccc627d7697e68fddc367c73ac09920457e5b35","modified":1449031175639},{"_id":"themes/landscape/layout/_partial/archive.ejs","shasum":"e440311811c74c20cbdf70f6fd44fd4855d059ae","modified":1449031175638},{"_id":"themes/landscape/layout/_partial/after-footer.ejs","shasum":"a7faab4f3601b28107af5b1095b3966c2f88fec8","modified":1449031175637},{"_id":"themes/landscape/layout/_partial/mobile-nav.ejs","shasum":"347cf1befd2ea637c24bd5901929d8e36e359e75","modified":1449031175652},{"_id":"themes/landscape/layout/_partial/post/category.ejs","shasum":"16128d2422645e18d1b6882d4c4df17d895bd76e","modified":1449031175652},{"_id":"themes/landscape/layout/_partial/post/date.ejs","shasum":"947f513f7a85fbcf085624e46dc2ae6de8185eec","modified":1449031175653},{"_id":"themes/landscape/README.md","shasum":"e7cc82dc79596f36ba05a8139e7d6b2dfc4ae5f9","modified":1449031175636},{"_id":"themes/landscape/layout/_partial/post/tag.ejs","shasum":"694b5101bcc44c9f9c1cc62e5ad2fdfb4b7c7a07","modified":1449031175654},{"_id":"themes/landscape/layout/_partial/post/title.ejs","shasum":"d4a460a35e2112d0c7414fd5e19b3a16093f1caf","modified":1449031175654},{"_id":"themes/landscape/layout/_partial/sidebar.ejs","shasum":"c70869569749a8f48cce202fa57926c06b55fdab","modified":1449031175655},{"_id":"themes/landscape/layout/_widget/archive.ejs","shasum":"88e191e3d14541299ed03b9a45be70974df51143","modified":1449031175655},{"_id":"themes/landscape/layout/_widget/category.ejs","shasum":"4d3f92e3cd652cb69d71e40d1c64b2369922ca26","modified":1449031175655},{"_id":"themes/landscape/layout/_widget/recent_posts.ejs","shasum":"d6591c745402fbc600e682830a343f732e336e4f","modified":1449031175656},{"_id":"themes/landscape/layout/_partial/post/gallery.ejs","shasum":"b0bf3f5d923c261ca2b5fabab513f1ec2708c8ca","modified":1449031175653},{"_id":"themes/landscape/layout/_widget/tag.ejs","shasum":"7ba10fbd17b83b9b89eaea99bb78158d318c6d75","modified":1449031175656},{"_id":"themes/landscape/layout/archive.ejs","shasum":"2703b07cc8ac64ae46d1d263f4653013c7e1666b","modified":1449031175657},{"_id":"themes/landscape/layout/category.ejs","shasum":"765426a9c8236828dc34759e604cc2c52292835a","modified":1449031175657},{"_id":"themes/landscape/layout/_widget/tagcloud.ejs","shasum":"9028129dd2e56813197d0c38db5df8110aaeaabb","modified":1449031175656},{"_id":"themes/landscape/layout/layout.ejs","shasum":"5d86bc48b0f1bdce9a2bb548c2f8e7a4f50d499a","modified":1449031175658},{"_id":"themes/landscape/layout/page.ejs","shasum":"7d80e4e36b14d30a7cd2ac1f61376d9ebf264e8b","modified":1449031175658},{"_id":"themes/landscape/layout/post.ejs","shasum":"7d80e4e36b14d30a7cd2ac1f61376d9ebf264e8b","modified":1449031175659},{"_id":"themes/landscape/layout/tag.ejs","shasum":"eaa7b4ccb2ca7befb90142e4e68995fb1ea68b2e","modified":1449031175659},{"_id":"themes/landscape/package.json","shasum":"d07f326588fef82f1d23ae3101c9ddfff34c132f","modified":1449031175659},{"_id":"themes/landscape/scripts/fancybox.js","shasum":"4c130fc242cf9b59b5df6ca5eae3b14302311e8c","modified":1449031175660},{"_id":"themes/landscape/layout/_partial/head.ejs","shasum":"65bf933f4b87bbda41eefae52ac1a1cde00deee9","modified":1449031175639},{"_id":"themes/landscape/layout/_partial/header.ejs","shasum":"b69855e07b65117769adc515cb64b803932068c9","modified":1449031175639},{"_id":"themes/landscape/layout/index.ejs","shasum":"aa1b4456907bdb43e629be3931547e2d29ac58c8","modified":1449031175657},{"_id":"themes/landscape/source/css/_partial/comment.styl","shasum":"2834870661e490775f9154d71638bfdc72e640a6","modified":1449031175662},{"_id":"themes/landscape/source/css/_partial/footer.styl","shasum":"6f7aa810f296d6a1a4486637b5a853d35a198938","modified":1449031175662},{"_id":"themes/landscape/layout/_partial/post/nav.ejs","shasum":"eb000d9d8a9ebd9087046fa019abe1cddae8fd9c","modified":1449031175653},{"_id":"themes/landscape/source/css/_partial/article.styl","shasum":"e291bc8c5f0c21080baa549d5d9ef2f39a871ea7","modified":1449031175661},{"_id":"themes/landscape/source/css/_partial/mobile.styl","shasum":"680c7b809b62cd3ad294e822793fbd0b1a32cc33","modified":1449031175663},{"_id":"themes/landscape/source/css/_partial/archive.styl","shasum":"9e574d8eb1a5285ec3b4346607414770d2f7e0ff","modified":1449031175661},{"_id":"themes/landscape/source/css/_partial/sidebar-bottom.styl","shasum":"f6023861b2fbd858946e2108438b5f8f17586179","modified":1449031175679},{"_id":"themes/landscape/source/css/_partial/sidebar.styl","shasum":"8d971a00e644a600179b04815688d188f094012e","modified":1449031175679},{"_id":"themes/landscape/source/css/_extend.styl","shasum":"8ab1ad313bd6707d248c5ca1ee9a5eab8d815e42","modified":1449031175661},{"_id":"themes/landscape/source/css/_partial/header.styl","shasum":"67e59feb18eee6026717cb440d86ab9551782628","modified":1449031175663},{"_id":"themes/landscape/source/css/_partial/sidebar-aside.styl","shasum":"1fb15f13ba70d5b954f62920c6b63d26e2fb2985","modified":1449031175679},{"_id":"themes/landscape/source/css/_util/mixin.styl","shasum":"429bad87fc156eacf226c5e35b0eafc277f2504b","modified":1449031175695},{"_id":"themes/landscape/source/css/_partial/highlight.styl","shasum":"05da1b8f4859761dc60bca40b8682f167e350742","modified":1449031175663},{"_id":"themes/landscape/source/css/_util/grid.styl","shasum":"1aa883ab432d9e4139c89dcbd40ae2bd1528d029","modified":1449031175695},{"_id":"themes/landscape/source/css/_variables.styl","shasum":"8b63ea3c7199524b9a1541075c6f8fb2c0d0ea3d","modified":1449031175695},{"_id":"themes/landscape/source/css/fonts/fontawesome-webfont.eot","shasum":"7619748fe34c64fb157a57f6d4ef3678f63a8f5e","modified":1449031175695},{"_id":"themes/landscape/source/fancybox/blank.gif","shasum":"2daeaa8b5f19f0bc209d976c02bd6acb51b00b0a","modified":1449031175695},{"_id":"themes/landscape/source/fancybox/fancybox_loading@2x.gif","shasum":"273b123496a42ba45c3416adb027cd99745058b0","modified":1449031175695},{"_id":"themes/landscape/source/css/fonts/FontAwesome.otf","shasum":"b5b4f9be85f91f10799e87a083da1d050f842734","modified":1449031175695},{"_id":"themes/landscape/source/fancybox/fancybox_overlay.png","shasum":"b3a4ee645ba494f52840ef8412015ba0f465dbe0","modified":1449031175695},{"_id":"themes/landscape/source/fancybox/fancybox_sprite.png","shasum":"17df19f97628e77be09c352bf27425faea248251","modified":1449031175695},{"_id":"themes/landscape/source/fancybox/fancybox_sprite@2x.png","shasum":"30c58913f327e28f466a00f4c1ac8001b560aed8","modified":1449031175695},{"_id":"themes/landscape/source/fancybox/helpers/fancybox_buttons.png","shasum":"e385b139516c6813dcd64b8fc431c364ceafe5f3","modified":1449031175695},{"_id":"themes/landscape/source/fancybox/helpers/jquery.fancybox-buttons.css","shasum":"6394c48092085788a8c0ef72670b0652006231a1","modified":1449031175695},{"_id":"themes/landscape/source/fancybox/helpers/jquery.fancybox-buttons.js","shasum":"4c9c395d705d22af7da06870d18f434e2a2eeaf9","modified":1449031175696},{"_id":"themes/landscape/source/fancybox/helpers/jquery.fancybox-thumbs.css","shasum":"b88b589f5f1aa1b3d87cc7eef34c281ff749b1ae","modified":1449031175696},{"_id":"themes/landscape/source/fancybox/helpers/jquery.fancybox-media.js","shasum":"e14c32cc6823b81b2f758512f13ed8eb9ef2b454","modified":1449031175696},{"_id":"themes/landscape/source/fancybox/helpers/jquery.fancybox-thumbs.js","shasum":"83cdfea43632b613771691a11f56f99d85fb6dbd","modified":1449031175696},{"_id":"themes/landscape/source/fancybox/jquery.fancybox.css","shasum":"2e54d51d21e68ebc4bb870f6e57d3bfb660d4f9c","modified":1449031175696},{"_id":"themes/landscape/source/fancybox/jquery.fancybox.js","shasum":"58193c802f307ec9bc9e586c0e8a13ebef45d2f8","modified":1449031175696},{"_id":"themes/landscape/source/fancybox/jquery.fancybox.pack.js","shasum":"2da892a02778236b64076e5e8802ef0566e1d9e8","modified":1449031175696},{"_id":"themes/landscape/source/css/fonts/fontawesome-webfont.woff","shasum":"04c3bf56d87a0828935bd6b4aee859995f321693","modified":1449031175695},{"_id":"themes/landscape/source/js/script.js","shasum":"c0d368681c687258b628bacc84cc30d353de6d47","modified":1449031175696},{"_id":"themes/landscape/source/css/fonts/fontawesome-webfont.ttf","shasum":"7f09c97f333917034ad08fa7295e916c9f72fd3f","modified":1449031175695},{"_id":"themes/landscape/source/css/style.styl","shasum":"4a3e64ee8dad5834860c30b4176882eff628ca6b","modified":1449031175695},{"_id":"themes/landscape/source/css/fonts/fontawesome-webfont.svg","shasum":"a275426daefd3716c53561fad121d258a7f05b47","modified":1449031175695},{"_id":"themes/landscape/source/css/images/banner.jpg","shasum":"843d9d47bf2b7b75495db11b3d765efaaae442a9","modified":1449031175695},{"_id":"themes/landscape/source/fancybox/fancybox_loading.gif","shasum":"1a755fb2599f3a313cc6cfdb14df043f8c14a99c","modified":1449031175695},{"_id":"public/js/script.js","modified":1458022822469,"shasum":"2876e0b19ce557fca38d7c6f49ca55922ab666a1"},{"_id":"public/fancybox/jquery.fancybox.pack.js","modified":1458022822486,"shasum":"9e0d51ca1dbe66f6c0c7aefd552dc8122e694a6e"},{"_id":"public/fancybox/jquery.fancybox.js","modified":1458022822492,"shasum":"d08b03a42d5c4ba456ef8ba33116fdbb7a9cabed"},{"_id":"public/fancybox/jquery.fancybox.css","modified":1458022822496,"shasum":"aaa582fb9eb4b7092dc69fcb2d5b1c20cca58ab6"},{"_id":"public/fancybox/helpers/jquery.fancybox-thumbs.js","modified":1458022822500,"shasum":"47da1ae5401c24b5c17cc18e2730780f5c1a7a0c"},{"_id":"public/fancybox/helpers/jquery.fancybox-thumbs.css","modified":1458022822505,"shasum":"4ac329c16a5277592fc12a37cca3d72ca4ec292f"},{"_id":"public/fancybox/helpers/jquery.fancybox-media.js","modified":1458022822509,"shasum":"294420f9ff20f4e3584d212b0c262a00a96ecdb3"},{"_id":"public/fancybox/helpers/jquery.fancybox-buttons.js","modified":1458022822512,"shasum":"dc3645529a4bf72983a39fa34c1eb9146e082019"},{"_id":"public/fancybox/helpers/jquery.fancybox-buttons.css","modified":1458022822516,"shasum":"1a9d8e5c22b371fcc69d4dbbb823d9c39f04c0c8"},{"_id":"public/fancybox/helpers/fancybox_buttons.png","modified":1458022822521,"shasum":"e385b139516c6813dcd64b8fc431c364ceafe5f3"},{"_id":"public/fancybox/fancybox_sprite@2x.png","modified":1458022822526,"shasum":"30c58913f327e28f466a00f4c1ac8001b560aed8"},{"_id":"public/fancybox/fancybox_sprite.png","modified":1458022822529,"shasum":"17df19f97628e77be09c352bf27425faea248251"},{"_id":"public/fancybox/fancybox_overlay.png","modified":1458022822531,"shasum":"b3a4ee645ba494f52840ef8412015ba0f465dbe0"},{"_id":"public/fancybox/fancybox_loading@2x.gif","modified":1458022822534,"shasum":"273b123496a42ba45c3416adb027cd99745058b0"},{"_id":"public/fancybox/fancybox_loading.gif","modified":1458022822537,"shasum":"1a755fb2599f3a313cc6cfdb14df043f8c14a99c"},{"_id":"public/fancybox/blank.gif","modified":1458022822540,"shasum":"2daeaa8b5f19f0bc209d976c02bd6acb51b00b0a"},{"_id":"public/css/style.css","modified":1458022823006,"shasum":"e9ae89d3eaf09b4fb3b48f3da5e58e74ea5875b0"},{"_id":"public/css/images/banner.jpg","modified":1458022823159,"shasum":"843d9d47bf2b7b75495db11b3d765efaaae442a9"},{"_id":"public/css/fonts/fontawesome-webfont.woff","modified":1458022823162,"shasum":"04c3bf56d87a0828935bd6b4aee859995f321693"},{"_id":"public/css/fonts/fontawesome-webfont.ttf","modified":1458022823165,"shasum":"7f09c97f333917034ad08fa7295e916c9f72fd3f"},{"_id":"public/css/fonts/fontawesome-webfont.svg","modified":1458022823167,"shasum":"a275426daefd3716c53561fad121d258a7f05b47"},{"_id":"public/css/fonts/fontawesome-webfont.eot","modified":1458022823169,"shasum":"7619748fe34c64fb157a57f6d4ef3678f63a8f5e"},{"_id":"public/css/fonts/FontAwesome.otf","modified":1458022823170,"shasum":"b5b4f9be85f91f10799e87a083da1d050f842734"},{"_id":"public/python-books-for-data-analysis/index.html","modified":1458022823237,"shasum":"77a6ab1c2fb034f221fe53af23c6e78961d5f80c"},{"_id":"public/about/index.html","modified":1458022823249,"shasum":"724caeaa8e1d9016162d861d03cc8191666f4800"},{"_id":"public/2016/03/15/java-environment/index.html","modified":1458022823262,"shasum":"7da073f98fea8a698376c9dcae6af158866b95bb"},{"_id":"public/2015/12/28/Singleton/index.html","modified":1458022823301,"shasum":"1d96bc7ee1018d8b224bbf1e104f038ece01bf5e"},{"_id":"public/2015/12/18/check-linux-version/index.html","modified":1458022823311,"shasum":"a67a074f6ae8f33cf8044431edd4511a2fafd4d6"},{"_id":"public/2015/12/10/NIO-Programing/index.html","modified":1458022823318,"shasum":"2246fe31bec7d1c3dcba5b932981f46c9ef4e4eb"},{"_id":"public/2015/12/09/JAVA-NIO-Netty/index.html","modified":1458022823332,"shasum":"924922c3cec0851f3f08e7f124a7b9b38c9f71dc"},{"_id":"public/2015/12/03/IO-Contrast/index.html","modified":1458022823338,"shasum":"fb2877b036beba48b837e560bec5c0dd9b9042a4"},{"_id":"public/2015/12/03/AIO/index.html","modified":1458022823345,"shasum":"c0b3ed049b69540d9a3bd7b7bfda9d4103be731b"},{"_id":"public/2015/12/02/NIO-library/index.html","modified":1458022823355,"shasum":"c91df641cf9d56de1853025a9529671be04d46fb"},{"_id":"public/2015/11/30/NIO-Introduce-Abstractly/index.html","modified":1458022823364,"shasum":"36528dc47a078d246f27741033b35739c9dc6652"},{"_id":"public/2015/11/30/java-I-O-2/index.html","modified":1458022823371,"shasum":"10527bf2c340f31ec7375898a902c0ce7860099b"},{"_id":"public/2015/11/27/java-I-O/index.html","modified":1458022823378,"shasum":"b0c9c02a2106a08223f8db1093c461525b8c9fa3"},{"_id":"public/2015/11/27/markdown/index.html","modified":1458022823384,"shasum":"bfd4eae8b8551c5b329f7a703cfd3999c707c891"},{"_id":"public/2015/11/27/hexo-commands/index.html","modified":1458022823390,"shasum":"e3f5d26a5ba3a44d463b2e2d4d9467e7e0b99ec9"},{"_id":"public/2015/06/22/java-exception/index.html","modified":1458022823397,"shasum":"4dd322564c3fc7f6b11af24e2d507736fa7c4f3b"},{"_id":"public/2015/06/15/fibonacci-2/index.html","modified":1458022823406,"shasum":"0900de20662891962672a7da1ce9e6e3668675ee"},{"_id":"public/2015/06/15/producer-consumer-problem/index.html","modified":1458022823414,"shasum":"892458b5b51c5cb8b0d117ad73719fe3df20e82c"},{"_id":"public/2015/06/10/java 集合类/index.html","modified":1458022823422,"shasum":"112fb5cd1e2f85c3f57cc99e349e4a46bd1e574c"},{"_id":"public/2015/06/10/Java 终结处理&垃圾回收/index.html","modified":1458022823429,"shasum":"95594c279100ef262685f5fdc9741f8bd722d4fd"},{"_id":"public/2015/05/20/java 打印素数/index.html","modified":1458022823436,"shasum":"71808841cca5ad0ef94904f8c651f6c77dc7dea7"},{"_id":"public/2015/05/17/Java中的一些概念/index.html","modified":1458022823442,"shasum":"1ac74a0c45f2ab11689d91e77c6c3bf84d100dcc"},{"_id":"public/2015/05/15/how-to-remove-duplicates-elements-from-arraylist-in-java/index.html","modified":1458022823450,"shasum":"2748a5c2a115e8f23152cbd1c36b5ab24c10b7aa"},{"_id":"public/2015/05/15/死锁及如何避免/index.html","modified":1458022823457,"shasum":"c56947524ef26393362e880ea925172dfaf21691"},{"_id":"public/2015/05/15/Path ClassPath 的区别/index.html","modified":1458022823464,"shasum":"d4910b976ef1808df9d904a67e9ba161d9bde91f"},{"_id":"public/2015/05/15/XML Schema 和 DTD的区别/index.html","modified":1458022823476,"shasum":"01da017f33b8c49c192b8fe34608d42e9fbe74e1"},{"_id":"public/2015/05/15/fibonacci/index.html","modified":1458022823484,"shasum":"07cdef786e33c1b436ab125e9cc9af997308a353"},{"_id":"public/2015/05/14/java-object-method/index.html","modified":1458022823492,"shasum":"82eb470f46ed5cbcf5bf1db641226c454b53666c"},{"_id":"public/2015/05/13/Abstract 与 Interface的区别/index.html","modified":1458022823498,"shasum":"4daa71565dd52666c0902e54d5cf4c1fc242a3c9"},{"_id":"public/2015/05/12/对象入门/index.html","modified":1458022823509,"shasum":"b724c6a7106627dfd13f9af0c6770c863c437a9c"},{"_id":"public/2015/05/11/HashMap 和 HashTable的区别/index.html","modified":1458022823515,"shasum":"1d49d205384fb767c363e2dec1b0d286a86c18bc"},{"_id":"public/2015/05/08/socket blocking noblocking IO model/index.html","modified":1458022823528,"shasum":"f2fef6b66326989dd723bca12eebce2580e2560d"},{"_id":"public/2015/05/07/Hibernate 数据查询/index.html","modified":1458022823541,"shasum":"676ea06f231990be097708ffcfb789fa5bb20f80"},{"_id":"public/2015/05/05/Hibernate高级映射/index.html","modified":1458022823548,"shasum":"b659b3342ac7c7d510dd5852a9ee5ae40e29e792"},{"_id":"public/2015/05/05/操纵Session/index.html","modified":1458022823556,"shasum":"c1154e7b091c3e09b2cd5ac389c970eb2ed920a0"},{"_id":"public/2015/05/04/Hibernate 基本配置及操作/index.html","modified":1458022823563,"shasum":"6a36724c330681d1efbaf07e80102f3330bd9498"},{"_id":"public/2015/05/03/ORM(Object Relation Mapping)/index.html","modified":1458022823570,"shasum":"4f159e8692f202fce443e84e46e07ffded676778"},{"_id":"public/2015/05/03/版本控制概述/index.html","modified":1458022823576,"shasum":"409a4e853f0e97ec9c011e64e3fba6a7bef75ef9"},{"_id":"public/2015/04/30/struts-advanced/index.html","modified":1458022823583,"shasum":"f11a5e3b72955c1676477d136249bc1231627329"},{"_id":"public/2015/04/30/struts-tiles/index.html","modified":1458022823588,"shasum":"d1dd7a6e762fce72a44ebcb33e4cd801433e40ec"},{"_id":"public/2015/04/29/flask-mysql-migrate/index.html","modified":1458022823594,"shasum":"717948d515e3bb43ce3940592f16152d7afbe546"},{"_id":"public/2015/04/28/Struts validate验证框架配置使用/index.html","modified":1458022823603,"shasum":"c388cbfe6224557d6e1f67a87a92f76d0e347315"},{"_id":"public/2015/04/27/PYTHON YIELD 使用浅析/index.html","modified":1458022823611,"shasum":"67b913d943fdb33bd8eaf314e9ec734694ccd53a"},{"_id":"public/2015/04/27/Sublime Text 2 插件安装/index.html","modified":1458022823625,"shasum":"46f26db9cb278aabb3eb84feaa3d5388b7dd08a0"},{"_id":"public/2015/04/26/python-scrapymongodb/index.html","modified":1458022823633,"shasum":"a3c23fd4797d4252ef8f81ac607ee5db36de984d"},{"_id":"public/2015/04/24/Struts 标签/index.html","modified":1458022823639,"shasum":"721192c6ef854edb9138c47717dcc0eb8ae40ab3"},{"_id":"public/2015/04/23/struts-components/index.html","modified":1458022823646,"shasum":"035d162ffeb76adab3e3007e6d50e6788b404dc4"},{"_id":"public/2015/04/22/Struts 工作原理/index.html","modified":1458022823651,"shasum":"d5fd425969b0d1b786333f6a839d20cba6f14c92"},{"_id":"public/2015/04/22/struts-login-demo/index.html","modified":1458022823673,"shasum":"d110d25b31bc0bbee7ae351ab2d8dcb6edec9f48"},{"_id":"public/2015/04/21/Struts (V-1.3.8) 应用概述/index.html","modified":1458022823678,"shasum":"d14fb56cc6b2f6491417de9c1cd9eb6143cffe95"},{"_id":"public/2015/04/21/Python 工具总结/index.html","modified":1458022823684,"shasum":"ef3c958aaa4c8c4288e4576e4cb3778186b26e73"},{"_id":"public/2015/04/20/网络爬虫/index.html","modified":1458022823689,"shasum":"4f1d3824097ce2dba0173e06445ad25d300ef5b4"},{"_id":"public/2015/04/14/python scrapy/index.html","modified":1458022823695,"shasum":"633fc488c00fd7d48098b9c41d4b22963231a970"},{"_id":"public/categories/Hibernate/index.html","modified":1458022823702,"shasum":"f41375717aa60f4321d2b15a665811a51383b70e"},{"_id":"public/categories/python/index.html","modified":1458022823705,"shasum":"f7c9d2f2abe88db2da0256183d1694a8c25dcba3"},{"_id":"public/categories/Git/index.html","modified":1458022823709,"shasum":"dacbe1dff8596678624ddb94daf40468d342fece"},{"_id":"public/categories/Java/index.html","modified":1458022823716,"shasum":"a203008c6d3f90df18635158e1c221f8227c836a"},{"_id":"public/categories/Java/page/2/index.html","modified":1458022823721,"shasum":"b846b8cb984ecd72f5c9a44d6e8d9541d44e88c0"},{"_id":"public/categories/Struts/index.html","modified":1458022823732,"shasum":"0509b3b49164a044e32d0f13c7fd4d0058939a96"},{"_id":"public/categories/socket/index.html","modified":1458022823735,"shasum":"b5a9b68c7cd31f7c25857fd72ed38b167037650a"},{"_id":"public/categories/Python/index.html","modified":1458022823739,"shasum":"098b695e32c79c593c2c488c79bfd0ae4d9bf394"},{"_id":"public/categories/Flask/index.html","modified":1458022823743,"shasum":"ccebce031939ee1721f13611a4f635e7bed5eac7"},{"_id":"public/categories/fibonacci/index.html","modified":1458022823746,"shasum":"b50f6b9c6a3055c6e3a3accc0adab5228e3a29d1"},{"_id":"public/categories/Tools/index.html","modified":1458022823748,"shasum":"94928342888dd0134d91ddd02bae4e6942f77ac2"},{"_id":"public/index.html","modified":1458022823761,"shasum":"76594782dc4ad6655990ad27c39d1172c39dd308"},{"_id":"public/page/2/index.html","modified":1458022823774,"shasum":"f3148b186b56f1173869c6dfda6e74340cbf8d8f"},{"_id":"public/page/3/index.html","modified":1458022823786,"shasum":"49f316bae653e570a0ccdd154d0a5cabb13f281d"},{"_id":"public/page/4/index.html","modified":1458022823802,"shasum":"631d2e383710ff43eb37ee86080702fa3bddf34f"},{"_id":"public/page/5/index.html","modified":1458022823816,"shasum":"4fb962c4776b812f2ed015153d93935359a2215b"},{"_id":"public/page/6/index.html","modified":1458022823822,"shasum":"9c25d9fdede02c53f0b253dfe1f48b98b11411dc"},{"_id":"public/tags/Bloom-Filter/index.html","modified":1458022823826,"shasum":"3f546e7bbe1c228b623e37faf7cae5a9a5e5efb1"},{"_id":"public/tags/网络爬虫/index.html","modified":1458022823830,"shasum":"0706d08dd37d839978ec3e738c10e6d9a1d733fe"},{"_id":"public/tags/python-rq/index.html","modified":1458022823833,"shasum":"0e784affcb624992769514eb828ad5702e43c54e"},{"_id":"public/tags/分布式爬虫/index.html","modified":1458022823844,"shasum":"649078a272d48550b2fd29047ca6567ede761c1c"},{"_id":"public/tags/SVN/index.html","modified":1458022823847,"shasum":"dd12b32617ce0d926bd8a2e4b563cb663b7193b5"},{"_id":"public/tags/Deadlock/index.html","modified":1458022823850,"shasum":"8b502792c5bbd426a9ffd4b3857243adce6a15f3"},{"_id":"public/tags/Hibernate/index.html","modified":1458022823854,"shasum":"ed3516739c81e5b0f68c87bd07b4742e1292035c"},{"_id":"public/tags/Session/index.html","modified":1458022823857,"shasum":"4efece88bfb84a72f0d08c43fd2f7da3d70d4472"},{"_id":"public/tags/OOP/index.html","modified":1458022823859,"shasum":"2bea59878089d623f22475e48556d09887ec2eed"},{"_id":"public/tags/struts/index.html","modified":1458022823865,"shasum":"6d60fd90b01a1aa54c6075dd7c586e405c17a12a"},{"_id":"public/tags/Tiles/index.html","modified":1458022823869,"shasum":"ceb240a3d3396ce91779ac4bb2499f14dc3b8ddd"},{"_id":"public/tags/Login/index.html","modified":1458022823872,"shasum":"844d82c014c3cca6dcbe5d440923027f5ea66e52"},{"_id":"public/tags/component/index.html","modified":1458022823876,"shasum":"96ae3e2eaec760e464ba0a23621c183451b66bf6"},{"_id":"public/tags/Tokens/index.html","modified":1458022823878,"shasum":"25d2c1dade02061afb0095b05c9c230ad2e378fd"},{"_id":"public/tags/中文乱码/index.html","modified":1458022823881,"shasum":"d791df19e8379ab0e50d9697e6eafed23eb542c4"},{"_id":"public/tags/crawler/index.html","modified":1458022823884,"shasum":"ac239127adfe70e8f27bc598e17db81a6bb99fd9"},{"_id":"public/tags/mongodb/index.html","modified":1458022823887,"shasum":"31227b3ff3b5ec56ae258d18a154cc6963022607"},{"_id":"public/tags/Scrapy/index.html","modified":1458022823891,"shasum":"933f553cf78942f23f1582d05685748db7485f1f"},{"_id":"public/tags/python/index.html","modified":1458022823894,"shasum":"1791410397053003e045768ce0dbede668a94393"},{"_id":"public/tags/srcapy/index.html","modified":1458022823897,"shasum":"3fdb69974ca06a1706f5fcd34fd47e286fe4a5d1"},{"_id":"public/tags/concurrent/index.html","modified":1458022823900,"shasum":"45e8da5995345f5bbb29292e8b5bae5e23e13ae3"},{"_id":"public/tags/java/index.html","modified":1458022823904,"shasum":"d073bfc92bdd1cc47f5023d7e6e9292e899837a3"},{"_id":"public/tags/multiThread/index.html","modified":1458022823907,"shasum":"e37922b96fe5251d80951fa05bcf950df63efacf"},{"_id":"public/tags/markdown/index.html","modified":1458022823910,"shasum":"261a6c6605e9040c724d01758921642c341c99ea"},{"_id":"public/tags/Exception/index.html","modified":1458022823913,"shasum":"e96c14e521b55399b55e8559f306da875a4a3321"},{"_id":"public/tags/Java/index.html","modified":1458022823916,"shasum":"e71b8e61ea5fb989509488ddd48a9bd8c489232e"},{"_id":"public/tags/javaIO/index.html","modified":1458022823919,"shasum":"308721a6e7eecfaf184b1752eb6d82cd720b2fce"},{"_id":"public/tags/JavaIO/index.html","modified":1458022823924,"shasum":"a2398379f91e49b342bd306baa5b3f2156ab5697"},{"_id":"public/tags/Collections/index.html","modified":1458022823927,"shasum":"bb873f1d2f25a846ac59d66aaf10676010e5ce25"},{"_id":"public/tags/Duplicate-from-Array/index.html","modified":1458022823930,"shasum":"19091f2134ccd651b2eef070a947a00eede43c83"},{"_id":"public/tags/Hexo/index.html","modified":1458022823933,"shasum":"4e65145499faa2f753409d6fca641ccc81ae8d31"},{"_id":"public/tags/Flask-migrate/index.html","modified":1458022823936,"shasum":"a4c742c8cddff9ce3f969957ed0f8c99859f52ea"},{"_id":"public/tags/Linux/index.html","modified":1458022823938,"shasum":"5f321ea64287c2bb4d5a38aae7c469dc8d40a65c"},{"_id":"public/tags/DTD/index.html","modified":1458022823942,"shasum":"6829bfb51ea64795e670e56e3ebd575483bac004"},{"_id":"public/tags/Schema/index.html","modified":1458022823945,"shasum":"09726a1bd8ce306f455946717d0d85a2ee697f37"},{"_id":"public/tags/XML/index.html","modified":1458022823948,"shasum":"c4e8ee32750a2de6ab663b201b847c7d1f66bb18"},{"_id":"public/tags/Sublime-Text2-Plugins-install/index.html","modified":1458022823951,"shasum":"d9275b6e5a9e80644053934d3aaa8495b84fca19"},{"_id":"public/tags/MVC/index.html","modified":1458022823954,"shasum":"21a3eca2e14e3aef90e69db580ad76106d8fdb7e"},{"_id":"public/tags/Tag/index.html","modified":1458022823959,"shasum":"b12054eec9a1166729a628dca6e25d6b52382a2a"},{"_id":"public/tags/work-principal/index.html","modified":1458022823964,"shasum":"ec5f0fc28efb7e0433138a1e37bafc00412c4747"},{"_id":"public/tags/Validation/index.html","modified":1458022823967,"shasum":"92bddfb4af1f2633e86d6095fdaf534367075df8"},{"_id":"public/tags/Java-Singleton/index.html","modified":1458022823970,"shasum":"0392a0cbcb2f097aa83085f656dabaa256633ac8"},{"_id":"public/tags/科学计算/index.html","modified":1458022823972,"shasum":"fb400eefb711adc5973567767c62701131080168"},{"_id":"public/tags/全栈工程师/index.html","modified":1458022823976,"shasum":"ab614a0ec6fe60dcf1e35a55dd1e45dbd4c0d79c"},{"_id":"public/tags/数据挖掘/index.html","modified":1458022823979,"shasum":"16d80d44a92c7097439088cf652f0298877afb61"},{"_id":"public/tags/文本处理/index.html","modified":1458022823983,"shasum":"993bfd3723c14e926fb53798da5cf26176baf5d5"},{"_id":"public/tags/机器学习/index.html","modified":1458022823987,"shasum":"2c1967e515b0d2b93b10a94259d140a92137ab80"},{"_id":"public/tags/Classpath/index.html","modified":1458022823990,"shasum":"2959d7fcfc451b1871ae71c08a0cb7ab5ed67c39"},{"_id":"public/tags/Path/index.html","modified":1458022823993,"shasum":"659c2f44202755f0969bce146e5a796be5c5c4bc"},{"_id":"public/tags/python-yield/index.html","modified":1458022823996,"shasum":"84015cb7b797c02458d8734343e9dca74e360d16"},{"_id":"public/tags/study/index.html","modified":1458022823999,"shasum":"742ca185a7dbd632b0a48059fd2d980c1717243f"},{"_id":"public/tags/ORM/index.html","modified":1458022824001,"shasum":"ceebc7e3bb656526d6f0cfad8ece91749011b60c"},{"_id":"public/tags/NIO/index.html","modified":1458022824007,"shasum":"f4c8eb082a943a25ea891b5f41f45d969c46dfb6"},{"_id":"public/tags/对象映射/index.html","modified":1458022824010,"shasum":"bc7431882b01624c933529e9ea0785e13eb5666c"},{"_id":"public/tags/HQL/index.html","modified":1458022824013,"shasum":"70d35f46b77aed1596b5a7614694f7986a4c5b07"},{"_id":"public/tags/QBC/index.html","modified":1458022824015,"shasum":"ba9e62a046430e4bb395076822017095ce941410"},{"_id":"public/tags/Query/index.html","modified":1458022824018,"shasum":"c926d121e755c3665031f651a638603a7a711574"},{"_id":"public/tags/stored-procedure/index.html","modified":1458022824023,"shasum":"fb05d73291a71acce8513d2d73a6ce3a2445d430"},{"_id":"public/tags/Configuration/index.html","modified":1458022824026,"shasum":"6099dde33ad14df6d13faade66b6ef0a6eb9232b"},{"_id":"public/tags/Hashmap/index.html","modified":1458022824029,"shasum":"d9aab281a31a1bc008c528d8c64fdb4a706c094d"},{"_id":"public/tags/hashtable/index.html","modified":1458022824031,"shasum":"7ea1c6ed86f85f40cc07533c25575c6eaccb90be"},{"_id":"public/tags/Abstract/index.html","modified":1458022824035,"shasum":"0583d50397251de6c9b5c7847c952308f5966e92"},{"_id":"public/tags/Interface/index.html","modified":1458022824038,"shasum":"85cc5b9377014f8e169d895eeb93f4ce5b705362"},{"_id":"public/archives/index.html","modified":1458022824046,"shasum":"3b2878a373828d8c0061b6e5bbe0748541b96d70"},{"_id":"public/archives/page/2/index.html","modified":1458022824056,"shasum":"b8c8c0c752cb690568368c440f37aa8070523967"},{"_id":"public/archives/page/3/index.html","modified":1458022824064,"shasum":"f408e4b52e16c87b6d6bbaf3127db301d19bf464"},{"_id":"public/archives/page/4/index.html","modified":1458022824073,"shasum":"50cbf4167240502e007e6bd1e64f7f6e00d751dd"},{"_id":"public/archives/page/5/index.html","modified":1458022824080,"shasum":"effa578e5d75dcabc010aac7924af26b8eb20cd1"},{"_id":"public/archives/page/6/index.html","modified":1458022824083,"shasum":"3fc9649e591772911179330f6fb1bf38886182f3"},{"_id":"public/archives/2015/index.html","modified":1458022824091,"shasum":"ddecfae53931e50fab1475844a7dce72b31d5362"},{"_id":"public/archives/2015/page/2/index.html","modified":1458022824099,"shasum":"97e0e34bf29b4d1fca5b6a53baaa92952474bd3a"},{"_id":"public/archives/2015/page/3/index.html","modified":1458022824107,"shasum":"c6c270eb4cd75fb492d38e86f58cc81d107b4269"},{"_id":"public/archives/2015/page/4/index.html","modified":1458022824114,"shasum":"c54cd0cab2156c4240024e7913bb08ba3ff8d98a"},{"_id":"public/archives/2015/page/5/index.html","modified":1458022824122,"shasum":"cbffdf2d4d4f7591874ad213e796490c855fdd5c"},{"_id":"public/archives/2015/04/index.html","modified":1458022824129,"shasum":"a8f7943e590289c7a8086d84c98e18815cab630f"},{"_id":"public/archives/2015/04/page/2/index.html","modified":1458022824134,"shasum":"ad48f2384a909c786e0900850ef39e0ec487a4a1"},{"_id":"public/archives/2015/05/index.html","modified":1458022824145,"shasum":"daebfe0faaccf12e67ea5d01ed285b8b5931459b"},{"_id":"public/archives/2015/05/page/2/index.html","modified":1458022824152,"shasum":"da6e33a71c41664715fdde288765b39a5565b8da"},{"_id":"public/archives/2015/06/index.html","modified":1458022824158,"shasum":"42afe57c549d2b5d6f2cc2f2d9e20d174052e83c"},{"_id":"public/archives/2015/11/index.html","modified":1458022824164,"shasum":"bed12f4a27048314787a4414a1711f831d93e4c8"},{"_id":"public/archives/2015/12/index.html","modified":1458022824169,"shasum":"631c8cbaa3ba89769bf2c1c417197b95534300b1"},{"_id":"public/archives/2016/index.html","modified":1458022824174,"shasum":"04873de8f662a67b0b578539f6e232d0bd2466da"},{"_id":"public/archives/2016/03/index.html","modified":1458022824177,"shasum":"8b997a388de8db55343960b4b49f7d434ac76c68"}],"Category":[{"name":"Hibernate","_id":"cilt153tu0001c0tjhfqe7p89"},{"name":"python","_id":"cilt153un000ac0tj1u77u9vu"},{"name":"Git","_id":"cilt153uy000lc0tj9ljzdf3g"},{"name":"Java","_id":"cilt153v9000qc0tj1xryp40m"},{"name":"Struts","_id":"cilt153vo0015c0tjoomlsji8"},{"name":"socket","_id":"cilt153w3001tc0tjys9xot3s"},{"name":"Python","_id":"cilt153w7001wc0tj5d6nivhw"},{"name":"Flask","_id":"cilt153xb003fc0tjvdcum0d1"},{"name":"fibonacci","_id":"cilt153xg003lc0tj1dzagn04"},{"name":"Tools","_id":"cilt153xu0042c0tjukwsqgih"}],"Data":[],"Page":[{"title":"Python books for data analysis","id":30,"date":"2015-04-20T05:36:36.000Z","_content":"\n### NLTK:自然语言处理\n\n《Natural Language Processing with Python》\n\n《Python Text Processing with NLTK 2.0 Cookbook》\n\n### NumPy,SciPy,Matplotlib\n\n《Python科学计算》\n\n《Python for Data Analysis》\n\n《Python机器学习库》\n\n《23个python的机器学习包》","source":"python-books-for-data-analysis/index.md","raw":"title: Python books for data analysis\nid: 30\ndate: 2015-04-20 13:36:36\n---\n\n### NLTK:自然语言处理\n\n《Natural Language Processing with Python》\n\n《Python Text Processing with NLTK 2.0 Cookbook》\n\n### NumPy,SciPy,Matplotlib\n\n《Python科学计算》\n\n《Python for Data Analysis》\n\n《Python机器学习库》\n\n《23个python的机器学习包》","updated":"2015-12-02T04:39:35.635Z","path":"python-books-for-data-analysis/index.html","comments":1,"layout":"page","_id":"cilt153ue0007c0tjtz1hlpiq"},{"title":"About","id":1,"date":"2015-04-14T04:46:32.000Z","_content":"\nThis is an example of a page. Unlike posts, which are displayed on your blog’s front page in the order they’re published, pages are better suited for more timeless content that you want to be easily accessible, like your About or Contact information. Click the Edit link to make changes to this page or [add another page](https://wordpress.com/page \"Direct link to Add New Page in your Dashboard\").","source":"about/index.md","raw":"title: About\nid: 1\ndate: 2015-04-14 12:46:32\n---\n\nThis is an example of a page. Unlike posts, which are displayed on your blog’s front page in the order they’re published, pages are better suited for more timeless content that you want to be easily accessible, like your About or Contact information. Click the Edit link to make changes to this page or [add another page](https://wordpress.com/page \"Direct link to Add New Page in your Dashboard\").","updated":"2015-12-02T04:39:35.634Z","path":"about/index.html","comments":1,"layout":"page","_id":"cilt153ui0008c0tjjbvx7z9f"}],"Post":[{"title":"Hibernate 事务管理和并发控制","id":"170","_content":"\n1,事务管理\n\n事务就是单个逻辑单元执行的一组数据操作,这些操作要么必须全部成功,要么必须全部失败,以保证数据一致性和完整性。事务具有ACID。\n\n* 原子性(Atomic):事务由一个或多个行为绑在一起组成,好像是一个单独的工作单元。原子性确保在事务中的所有操作要么完成,要么都不发生。\n* 一致性(consistent):一旦一个事务结束(不管成功与否),系统所处的状态和它的业务规则是一致的。既数据应当不会被破坏。\n* 隔离性(Isolated):事务允许多个用户操作同一条数据,一个用户的操作不会和其他用户的操作相混淆。\n* 持久性(Durable):一旦事务完成,事务的记过应该持久化。\n2,数据库事务管理\n\n数据库事务的ACID特性是由关系数据库管理系统(RDBMS)来实现的。数据库管理系统采用日志保证事务的原子性、一致性和持久性,日志记录事务对数据库所做的更新,如果某个事务在执行过程中发生错误,就可以根据日志,撤销事务对数据库已做的更新,使数据库退回到执行事务前的状态。数据库管理系统采用锁的机制来实现事务的隔离性。当多个事务同时更新数据库同一个数据时,只允许持有锁的事务能更新该数据,其他事务必须等待,知道前一个事务释放了锁,其他事务才有机会更新改数据。\n\n数据库系统自动保证数据的ACID属性。\n\nJDBC API中,java.sql.Connection类代表一个数据库连接。\n\n* setAutoCommit(true)\n* commit()\n* rollback()\n<pre>Connection con = null;\nPrepareStatement pstmt = null;\ntry{\ncon = DriverManager.getConnection(dbURL,username,password);\ncon.setAutoCommit(false);\npstmt = ...;\npstmt.executeUpdate();\ncon.commit()\n}catch(Exception e){\ncom.rollback();\n}finally{\n}</pre>\n3,Hibernate应用程序中的事务管理\n\nHibernate对JDBC进行轻量级的对象封装,Hibernate本身在设计时并不具备事务处理功能,平时所用的Hibernate的事务,只是将底层的JDBCTransaction,或者JTATransaction进行一下封装,在外面套上Transaction和Session的外壳,其实底层都是通过委托底层的JDBC或JTA来实现事务的调度功能。\n\n(1)Hibernate中使用JDBC事务\n\n要在Hibernate中使用JDBC事务,可以在Hibernate.cfg.xml中指定hibernate事务为JDBCTransaction。\n\n<property name=\"hibernate.transaction.factory_class\">org.hibernate.transaction.JDBCTransactionFactory</property>\n\nHibernate使用JDBC transaction处理方法\n<pre>Transaction tx = null;\ntry{\n tx = session.beginTransaction();\n ...\n tx.commit();\n}catch(RuntimeException e){\n throw e;\n}finally{\n session.close();\n}</pre>\n(2)Hibernate中使用JTA事务\n\nJava Transaction API 是事务服务的JavaEE解决方案,本质上,它是描述事务接口的JavaEE模型的一部分。\n\nUserTransaction,TransactionManager,Transaction,这些接口共享公共事务操作。UserTransaction能够执行事务划分和基本的事务操作,TransactionManager能够执行上下文管理。\n\nJTA服务需要第三方应用程序提供具体的实现。\n\n### 并发访问控制\n\n1,数据库事务并发引起的问题\n\n在并发环境,一个数据库系统会同时为各种各样的客户端程序提供服务,也就是说,在同一时刻,会有多个客户程序同时访问数据库系统,这多个客户程序中的事务访问数据库中相同的数据时,如果没有采取必要的隔离机制,就会导致各种各样的并发问题的发生。\n\n* 第一类丢失更新:两个事务都更新同一行,而另外一个事务异常回滚,使两处变化都丢失。这种并发问题是由完全没有隔离事务造成的。\n* 脏读:一个事务读到另一个事务未提交的更改数据。\n* 不可重复读:一个事物两次读取同一行数据,两次数据不同。\n* 第二类丢失更新:这是不可重复读中的特例,一个事务覆盖另一个事务已经提交的数据。\n* 幻读:一个事务前后执行一个查询两次,在第二个结果集中包括第一个结果集中不可见的行,或者包括已经删除的行。\n2,事务隔离级别\n\n让用户根据在事务隔离性和并发性之间做合理的权衡。\n\n* Read Uncommitted(读未提交):可以防止第一类丢失更新问题,但没有解决第一类丢失更新和脏读的并发问题。它的事务隔离性最低。1\n* Read Committed(读已提交):可以防止脏读一下的并发问题,但没有解决第一类丢失更新,脏读和不可重复读的并发问题。2\n* Repeatable Read(可重复读):可以防止不可重复读第二类丢失更新和幻读的并发问题,但没有解决幻读问题。4\n* Serializable(串行化):提供最严格的事务隔离性。它把事务隔离成连续的一个接一个地执行,而不是并发执行。8\n在hibernate.cfg.xml中配置隔离级别如下:\n\n<property name=\"hibernate.connection.isolation\">2</property>\n\n在开始一个事务之前,Hibernate将为从连接池中获得的JDBC连接设备级别。\n\n3,乐观的并发控制\n\n乐观锁:假定当前事务曹总数据资源是,不会有其他事务同时访问改数据资源,因此不做数据库层次上的锁定。为了维护正确的数据,乐观锁使用应用程序上的版本控制来避免可能出现的并发问题的发生。\n\n唯一能够同时保持高并发和高可伸缩性的方法就是实用带版本话的乐观并发控制。版本检查使用版本号,或者时间戳来检测更新冲突。\n\nHibernate通过版本号","source":"_drafts/Hibernate-事务管理和并发控制.md","raw":"title: Hibernate 事务管理和并发控制\ntags:\n - 并发访问控制\n - 事务\nid: 170\ncategories:\n - Hibernate\n---\n\n1,事务管理\n\n事务就是单个逻辑单元执行的一组数据操作,这些操作要么必须全部成功,要么必须全部失败,以保证数据一致性和完整性。事务具有ACID。\n\n* 原子性(Atomic):事务由一个或多个行为绑在一起组成,好像是一个单独的工作单元。原子性确保在事务中的所有操作要么完成,要么都不发生。\n* 一致性(consistent):一旦一个事务结束(不管成功与否),系统所处的状态和它的业务规则是一致的。既数据应当不会被破坏。\n* 隔离性(Isolated):事务允许多个用户操作同一条数据,一个用户的操作不会和其他用户的操作相混淆。\n* 持久性(Durable):一旦事务完成,事务的记过应该持久化。\n2,数据库事务管理\n\n数据库事务的ACID特性是由关系数据库管理系统(RDBMS)来实现的。数据库管理系统采用日志保证事务的原子性、一致性和持久性,日志记录事务对数据库所做的更新,如果某个事务在执行过程中发生错误,就可以根据日志,撤销事务对数据库已做的更新,使数据库退回到执行事务前的状态。数据库管理系统采用锁的机制来实现事务的隔离性。当多个事务同时更新数据库同一个数据时,只允许持有锁的事务能更新该数据,其他事务必须等待,知道前一个事务释放了锁,其他事务才有机会更新改数据。\n\n数据库系统自动保证数据的ACID属性。\n\nJDBC API中,java.sql.Connection类代表一个数据库连接。\n\n* setAutoCommit(true)\n* commit()\n* rollback()\n<pre>Connection con = null;\nPrepareStatement pstmt = null;\ntry{\ncon = DriverManager.getConnection(dbURL,username,password);\ncon.setAutoCommit(false);\npstmt = ...;\npstmt.executeUpdate();\ncon.commit()\n}catch(Exception e){\ncom.rollback();\n}finally{\n}</pre>\n3,Hibernate应用程序中的事务管理\n\nHibernate对JDBC进行轻量级的对象封装,Hibernate本身在设计时并不具备事务处理功能,平时所用的Hibernate的事务,只是将底层的JDBCTransaction,或者JTATransaction进行一下封装,在外面套上Transaction和Session的外壳,其实底层都是通过委托底层的JDBC或JTA来实现事务的调度功能。\n\n(1)Hibernate中使用JDBC事务\n\n要在Hibernate中使用JDBC事务,可以在Hibernate.cfg.xml中指定hibernate事务为JDBCTransaction。\n\n<property name=\"hibernate.transaction.factory_class\">org.hibernate.transaction.JDBCTransactionFactory</property>\n\nHibernate使用JDBC transaction处理方法\n<pre>Transaction tx = null;\ntry{\n tx = session.beginTransaction();\n ...\n tx.commit();\n}catch(RuntimeException e){\n throw e;\n}finally{\n session.close();\n}</pre>\n(2)Hibernate中使用JTA事务\n\nJava Transaction API 是事务服务的JavaEE解决方案,本质上,它是描述事务接口的JavaEE模型的一部分。\n\nUserTransaction,TransactionManager,Transaction,这些接口共享公共事务操作。UserTransaction能够执行事务划分和基本的事务操作,TransactionManager能够执行上下文管理。\n\nJTA服务需要第三方应用程序提供具体的实现。\n\n### 并发访问控制\n\n1,数据库事务并发引起的问题\n\n在并发环境,一个数据库系统会同时为各种各样的客户端程序提供服务,也就是说,在同一时刻,会有多个客户程序同时访问数据库系统,这多个客户程序中的事务访问数据库中相同的数据时,如果没有采取必要的隔离机制,就会导致各种各样的并发问题的发生。\n\n* 第一类丢失更新:两个事务都更新同一行,而另外一个事务异常回滚,使两处变化都丢失。这种并发问题是由完全没有隔离事务造成的。\n* 脏读:一个事务读到另一个事务未提交的更改数据。\n* 不可重复读:一个事物两次读取同一行数据,两次数据不同。\n* 第二类丢失更新:这是不可重复读中的特例,一个事务覆盖另一个事务已经提交的数据。\n* 幻读:一个事务前后执行一个查询两次,在第二个结果集中包括第一个结果集中不可见的行,或者包括已经删除的行。\n2,事务隔离级别\n\n让用户根据在事务隔离性和并发性之间做合理的权衡。\n\n* Read Uncommitted(读未提交):可以防止第一类丢失更新问题,但没有解决第一类丢失更新和脏读的并发问题。它的事务隔离性最低。1\n* Read Committed(读已提交):可以防止脏读一下的并发问题,但没有解决第一类丢失更新,脏读和不可重复读的并发问题。2\n* Repeatable Read(可重复读):可以防止不可重复读第二类丢失更新和幻读的并发问题,但没有解决幻读问题。4\n* Serializable(串行化):提供最严格的事务隔离性。它把事务隔离成连续的一个接一个地执行,而不是并发执行。8\n在hibernate.cfg.xml中配置隔离级别如下:\n\n<property name=\"hibernate.connection.isolation\">2</property>\n\n在开始一个事务之前,Hibernate将为从连接池中获得的JDBC连接设备级别。\n\n3,乐观的并发控制\n\n乐观锁:假定当前事务曹总数据资源是,不会有其他事务同时访问改数据资源,因此不做数据库层次上的锁定。为了维护正确的数据,乐观锁使用应用程序上的版本控制来避免可能出现的并发问题的发生。\n\n唯一能够同时保持高并发和高可伸缩性的方法就是实用带版本话的乐观并发控制。版本检查使用版本号,或者时间戳来检测更新冲突。\n\nHibernate通过版本号","slug":"Hibernate-事务管理和并发控制","published":0,"date":"2015-12-02T04:39:35.618Z","updated":"2015-12-02T04:39:35.618Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153tm0000c0tjm80br6r7"},{"title":"网络爬虫","id":"27","date":"2015-04-19T21:38:14.000Z","_content":"\n# **学习要求**\n\n1. 基本的爬虫工作原理;\n2. 基本的http抓取工具,scrapy\n3. Bloom Filter: Bloom\n4. 分布式爬虫:[python-rq](https://github.com/nvie/rq)\n5. rq和Scrapy的结合:[scrapy-redis](https://github.com/darkrho/scrapy-redis)\n6. 后续处理,网页分析:[python-goose](https://github.com/grangier/python-goose)\n\n### 爬虫的工作原理\n\n以人民日报为例:http://www.renminribao.com\n\n基本流程如下:伪代码\n<pre>import Queue\n\ninitial_page = \"http://www.renminribao.com\"\nurl_open = Queue.Queue()\nseen = set()\nseen.insert(initial_page)\nurl_queue.put(initial_page)\n\nwhile(True):\n if url_queue.size()>0:\n current_url = url_queue.get()\n store(current_url)\n for next_url in extract_urls(current_url):\n if next_url not in seen:\n seen.put(next_url)\n url_queue.put(next_url)\n else:\n break</pre>\n\n### 效率\n\nN个网络链接,判重的复杂度N*log(N),python的set实现是hash,太慢\n\n通常的判重,Bloom Filter。它是一种hash的方法,但是它的特点是,它可以使用固定的内存(不随URL的数量而增长)以O(1)的效率判定URL是否已经在set中。[实例](http://billmill.org/bloomfilter-tutorial/)\n\n### 集群化抓取\n\nslave master模式,url_queue 放到master上,所有的slave都可以通过网络跟master通信,每当一个slave完成下载一个网页,就向master请求一个新的网页来抓取,每次slave新抓取到一个网页,就把这个网页上所有链接送到master的queue里去。同样,bloom filter也放到master上,但是master只发送确定没有被访问过的URL给slave。Bloom Filter放到master的内存里,而被访问过的URL放到master上的Redis里,这样保证所有操作都是O(1),[LINSERT – Redis](http://redis.io/documentation)\n\n在各个slave上装好scrapy,在master装好Redis和rq作为分布式队列。\n<pre>#slave.py\ncurrent_url = request_from_master()\nto_send = []\nfor next_url in extract_urls(current_url):\n to_send.append(next_url)\nstore(current_url)\nsend_to_master(to_send)\n\n#master.py\n\ndistributed_queue = DistributedQueue()\nbf = BloomFilter()\n\ninitial_pages = 'www.renminribao.com'\n\nwhile(True):\n if request == 'GET'\n if distributed_queue.size()>0:\n send(distributed_queue.get())\n else:\n break\n elif request == 'POST'\n bf.put(request.url)</pre>\n已经有现成的例子:[<span class=\"author\">arkrho</span><span class=\"path-divider\">/</span>**scrapy-redis**](https://github.com/darkrho/scrapy-redis)\n\n### 展望及后处理\n\n1,有效地存储(数据库应该怎样安排)\n\n2,有效的判重(网页内容判重)\n\n3,有效的信息提取(抽取有用信息)\n\n4,及时更新(预测网页多久更新一次)","source":"_posts/网络爬虫.md","raw":"title: 网络爬虫\ntags:\n - Bloom Filter\n - 网络爬虫\n - python-rq\n - 分布式爬虫\nid: 27\ncategories:\n - python\ndate: 2015-04-20 05:38:14\n---\n\n# **学习要求**\n\n1. 基本的爬虫工作原理;\n2. 基本的http抓取工具,scrapy\n3. Bloom Filter: Bloom\n4. 分布式爬虫:[python-rq](https://github.com/nvie/rq)\n5. rq和Scrapy的结合:[scrapy-redis](https://github.com/darkrho/scrapy-redis)\n6. 后续处理,网页分析:[python-goose](https://github.com/grangier/python-goose)\n\n### 爬虫的工作原理\n\n以人民日报为例:http://www.renminribao.com\n\n基本流程如下:伪代码\n<pre>import Queue\n\ninitial_page = \"http://www.renminribao.com\"\nurl_open = Queue.Queue()\nseen = set()\nseen.insert(initial_page)\nurl_queue.put(initial_page)\n\nwhile(True):\n if url_queue.size()>0:\n current_url = url_queue.get()\n store(current_url)\n for next_url in extract_urls(current_url):\n if next_url not in seen:\n seen.put(next_url)\n url_queue.put(next_url)\n else:\n break</pre>\n\n### 效率\n\nN个网络链接,判重的复杂度N*log(N),python的set实现是hash,太慢\n\n通常的判重,Bloom Filter。它是一种hash的方法,但是它的特点是,它可以使用固定的内存(不随URL的数量而增长)以O(1)的效率判定URL是否已经在set中。[实例](http://billmill.org/bloomfilter-tutorial/)\n\n### 集群化抓取\n\nslave master模式,url_queue 放到master上,所有的slave都可以通过网络跟master通信,每当一个slave完成下载一个网页,就向master请求一个新的网页来抓取,每次slave新抓取到一个网页,就把这个网页上所有链接送到master的queue里去。同样,bloom filter也放到master上,但是master只发送确定没有被访问过的URL给slave。Bloom Filter放到master的内存里,而被访问过的URL放到master上的Redis里,这样保证所有操作都是O(1),[LINSERT – Redis](http://redis.io/documentation)\n\n在各个slave上装好scrapy,在master装好Redis和rq作为分布式队列。\n<pre>#slave.py\ncurrent_url = request_from_master()\nto_send = []\nfor next_url in extract_urls(current_url):\n to_send.append(next_url)\nstore(current_url)\nsend_to_master(to_send)\n\n#master.py\n\ndistributed_queue = DistributedQueue()\nbf = BloomFilter()\n\ninitial_pages = 'www.renminribao.com'\n\nwhile(True):\n if request == 'GET'\n if distributed_queue.size()>0:\n send(distributed_queue.get())\n else:\n break\n elif request == 'POST'\n bf.put(request.url)</pre>\n已经有现成的例子:[<span class=\"author\">arkrho</span><span class=\"path-divider\">/</span>**scrapy-redis**](https://github.com/darkrho/scrapy-redis)\n\n### 展望及后处理\n\n1,有效地存储(数据库应该怎样安排)\n\n2,有效的判重(网页内容判重)\n\n3,有效的信息提取(抽取有用信息)\n\n4,及时更新(预测网页多久更新一次)","slug":"网络爬虫","published":1,"updated":"2015-12-02T04:39:35.634Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153um0009c0tjhd0j3n1e"},{"title":"版本控制概述","id":"120","date":"2015-05-03T00:37:00.000Z","_content":"\n版本控制是一种软件工程技巧,指的是在软件开发过程中,确保由不同人所编辑的同一文件都得到跟新。版本控制的标准做法是通过文档控制来记录各个文件的改动,并未每次改动添加编号。\n\n版本控制系统指能够追踪、比较、回复、提交程序代码或文件改动的软件。\n\n### 版本控制术语\n\n仓库(Repository):是版本控制系统中存放项目文件及这些文件的全部历史的中心。它是版本控制系统策略的核心组件。仓库使用典型的文件和目录层次结构——树状结构来存储信息。在物理结构上它是版本控制系统的根目录。\n\n模块(Module):就是仓库里用一个用户版本控制系统管理起来的工程。\n\n导入(Import):添加文件到版本中控制系统的仓库中,为项目创建了一个模块。\n\n工作目录(Working directory):保存了从仓库中拿到的项目文件到本地复制。也叫工作空间(workspace)。开发人员可以再工作目录下修改其中的文件。\n\n检出(checkout):指的是从仓库中获取一个模块中的文件到本地的工作目录里,然后就可以再工作目录下,修改其中的文件。\n\n提交(commit):在本地的工作目录下,对工程中的文件进行修改,这些修改需要提交到版本控制系统的仓库。\n\n同步(Update):从仓库中的模块中下载被其他人修改过的文件。\n\n文件版本(Revision):指的是单个文件的版本,而不是整个项目的版本。基本上,每个文件每次修改,经过提交后,它的文件版本都会改变一次。单个文件的版本(Revision)与整个工程的版本(Version或Release)可以没有任何关系。\n\n发行版本(Release):整个产品的版本。\n\n标签(Tag):在工程开发过程的一个特定时期,对一个文件或者多个文件给的符号名,一般是有意义的字符串:如Beta_2_0,RC_3_0,GA_1_0等。tag是服务版本的一些文字含义。\n\n[各个版本的含义](http://www.blogjava.net/RomulusW/archive/2008/05/04/197985.html)\n\nAlpha:是内部测试版,一般不向外部发布,会有很多Bug.一般只有测试人员使用。\n\nBeta:也是测试版,这个阶段的版本会一直加入新的功能。在Alpha版之后推出。\n\nRC:(Release Candidate) 顾名思义么 ! 用在软件上就是候选版本。系统平台上就是发行候选版本。RC版不会再加入新的功能了,主要着重于除错。\n\n<span class=\"hilite1\"><span class=\"hilite1\">GA</span></span>:General Availability,正式发布的版本,在国外都是用<span class=\"hilite1\"><span class=\"hilite1\">GA</span></span>来说明release版本的。\n\nRTM:(Release to Manufacture)是给工厂大量压片的版本,内容跟正式版是一样的,不过RTM版也有出限制、评估版的。但是和正式版本的主要程序代码都是一样的。\n\nOEM:是给计算机厂商随着计算机贩卖的,也就是随机版。只能随机器出货,不能零售。只能全新安装,不能从旧有操作系统升级。包装不像零售版精美,通常只有一面CD和说明书(授权书)。\n\nRVL:号称是正式版,其实RVL根本不是版本的名称。它是中文版/英文版文档破解出来的。\n\nEVAL:而流通在网络上的EVAL版,与“评估版”类似,功能上和零售版没有区别。\n\nRTL:Retail(零售版)是真正的正式版,正式上架零售版。在安装盘的i386文件夹里有一个eula.txt,最后有一行EULAID,就是你的版本。比如简体中文正式版是EULAID:WX.4_PRO_RTL_CN,繁体中文正式版是WX.4_PRO_RTL_TW。其中:如果是WX.开头是正式版,WB.开头是测试版。_PRE,代表家庭版;_PRO,代表专业版。\n\nα、β、λ常用来表示<a target=\"_self\">软件测试</a>过程中的三个阶段,α是第一阶段,一般只供内部测试使用;β是第二个阶段,已经消除了软件中大部分的不完善之处,但仍有可能还存在缺陷和漏洞,一般只提供给特定的用户群来测试使用;λ是第三个阶段,此时产品已经相当成熟,只需在个别地方再做进一步的优化处理即可上市发行。","source":"_posts/版本控制概述.md","raw":"title: 版本控制概述\ntags:\n - SVN\nid: 120\ncategories:\n - Git\ndate: 2015-05-03 08:37:00\n---\n\n版本控制是一种软件工程技巧,指的是在软件开发过程中,确保由不同人所编辑的同一文件都得到跟新。版本控制的标准做法是通过文档控制来记录各个文件的改动,并未每次改动添加编号。\n\n版本控制系统指能够追踪、比较、回复、提交程序代码或文件改动的软件。\n\n### 版本控制术语\n\n仓库(Repository):是版本控制系统中存放项目文件及这些文件的全部历史的中心。它是版本控制系统策略的核心组件。仓库使用典型的文件和目录层次结构——树状结构来存储信息。在物理结构上它是版本控制系统的根目录。\n\n模块(Module):就是仓库里用一个用户版本控制系统管理起来的工程。\n\n导入(Import):添加文件到版本中控制系统的仓库中,为项目创建了一个模块。\n\n工作目录(Working directory):保存了从仓库中拿到的项目文件到本地复制。也叫工作空间(workspace)。开发人员可以再工作目录下修改其中的文件。\n\n检出(checkout):指的是从仓库中获取一个模块中的文件到本地的工作目录里,然后就可以再工作目录下,修改其中的文件。\n\n提交(commit):在本地的工作目录下,对工程中的文件进行修改,这些修改需要提交到版本控制系统的仓库。\n\n同步(Update):从仓库中的模块中下载被其他人修改过的文件。\n\n文件版本(Revision):指的是单个文件的版本,而不是整个项目的版本。基本上,每个文件每次修改,经过提交后,它的文件版本都会改变一次。单个文件的版本(Revision)与整个工程的版本(Version或Release)可以没有任何关系。\n\n发行版本(Release):整个产品的版本。\n\n标签(Tag):在工程开发过程的一个特定时期,对一个文件或者多个文件给的符号名,一般是有意义的字符串:如Beta_2_0,RC_3_0,GA_1_0等。tag是服务版本的一些文字含义。\n\n[各个版本的含义](http://www.blogjava.net/RomulusW/archive/2008/05/04/197985.html)\n\nAlpha:是内部测试版,一般不向外部发布,会有很多Bug.一般只有测试人员使用。\n\nBeta:也是测试版,这个阶段的版本会一直加入新的功能。在Alpha版之后推出。\n\nRC:(Release Candidate) 顾名思义么 ! 用在软件上就是候选版本。系统平台上就是发行候选版本。RC版不会再加入新的功能了,主要着重于除错。\n\n<span class=\"hilite1\"><span class=\"hilite1\">GA</span></span>:General Availability,正式发布的版本,在国外都是用<span class=\"hilite1\"><span class=\"hilite1\">GA</span></span>来说明release版本的。\n\nRTM:(Release to Manufacture)是给工厂大量压片的版本,内容跟正式版是一样的,不过RTM版也有出限制、评估版的。但是和正式版本的主要程序代码都是一样的。\n\nOEM:是给计算机厂商随着计算机贩卖的,也就是随机版。只能随机器出货,不能零售。只能全新安装,不能从旧有操作系统升级。包装不像零售版精美,通常只有一面CD和说明书(授权书)。\n\nRVL:号称是正式版,其实RVL根本不是版本的名称。它是中文版/英文版文档破解出来的。\n\nEVAL:而流通在网络上的EVAL版,与“评估版”类似,功能上和零售版没有区别。\n\nRTL:Retail(零售版)是真正的正式版,正式上架零售版。在安装盘的i386文件夹里有一个eula.txt,最后有一行EULAID,就是你的版本。比如简体中文正式版是EULAID:WX.4_PRO_RTL_CN,繁体中文正式版是WX.4_PRO_RTL_TW。其中:如果是WX.开头是正式版,WB.开头是测试版。_PRE,代表家庭版;_PRO,代表专业版。\n\nα、β、λ常用来表示<a target=\"_self\">软件测试</a>过程中的三个阶段,α是第一阶段,一般只供内部测试使用;β是第二个阶段,已经消除了软件中大部分的不完善之处,但仍有可能还存在缺陷和漏洞,一般只提供给特定的用户群来测试使用;λ是第三个阶段,此时产品已经相当成熟,只需在个别地方再做进一步的优化处理即可上市发行。","slug":"版本控制概述","published":1,"updated":"2015-12-02T04:39:35.634Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153ux000kc0tj8szyziuk"},{"title":"死锁及如何避免","id":"208","date":"2015-05-15T04:34:08.000Z","_content":"\n<span style=\"font-size:large;\">**什么是死锁,如何避免死锁?\n线程A需要资源X,而线程B需要资源Y,而双方都掌握有对方所要的资源,这种情况称为死锁(deadlock),或死亡拥抱(the deadly embrace)。\n**</span>\n\n<span style=\"font-size:large;\">**在并发程序设计中,死锁 (deadlock) 是一种十分常见的逻辑错误。通过采用正确的编程方式,死锁的发生不难避免。**</span>\n<div class=\"level2\">\n\n<span style=\"font-size:large;\">**在计算机专业的本科教材中,通常都会介绍死锁的四个必要条件。这四个条件缺一不可,或者说只要破坏了其中任何一个条件,死锁就不可能发生。我们来复习一下,这四个条件是:**</span>\n\n1. <div class=\"li\"><span style=\"font-size:large;\">**互斥(Mutual exclusion):存在这样一种资源,它在某个时刻只能被分配给一个执行绪(也称为线程)使用;**</span></div>\n2. <div class=\"li\"><span style=\"font-size:large;\">**持有(Hold and wait):当请求的资源已被占用从而导致执行绪阻塞时,资源占用者不但无需释放该资源,而且还可以继续请求更多资源;**</span></div>\n3. <div class=\"li\"><span style=\"font-size:large;\">**不可剥夺(No preemption):执行绪获得到的互斥资源不可被强行剥夺,换句话说,只有资源占用者自己才能释放资源;**</span></div>\n4. <div class=\"li\"><span style=\"font-size:large;\">**环形等待(Circular wait):若干执行绪以不同的次序获取互斥资源,从而形成环形等待的局面,想象在由多个执行绪组成的环形链中,每个执行绪都在等待下一个执行绪释放它持有的资源。**</span></div>\n</div>\n<span style=\"font-size:large;\">**不难看出,在死锁的四个必要条件中,第二、三和四项条件比较容易消除。通过引入事务机制,往往可以消除第二、三两项条件,方法是将所有上锁操作均作为事务对待,一旦开始上锁,即确保全部操作均可回退,同时通过锁管理器检测死锁,并剥夺资源(回退事务)。这种做法有时会造成较大开销,而且也需要对上锁模式进行较多改动。**</span>\n\n<span style=\"font-size:large;\">**消除第四项条件是比较容易且代价较低的办法。具体来说这种方法约定:上锁的顺序必须一致。具体来说,我们人为地给锁指定一种类似“水位”的方向性属性。无论已持有任何锁,该执行绪所有的上锁操作,必须按照一致的先后顺序从低到高(或从高到低)进行,且在一个系统中,只允许使用一种先后次序。**</span>\n\n<span style=\"font-size:large;\">**请注意,放锁的顺序并不会导致死锁。也就是说,尽管按照 锁A, 锁B, 放A, 放B 这样的顺序来进行锁操作看上去有些怪异,但是只要大家都按先A后B的顺序上锁,便不会导致死锁。**</span>\n\n<span style=\"color:#ff0000;font-size:large;\">**解决方法:**</span>\n\n<span style=\"font-size:large;\">**1 使用事务时,尽量缩短事务的逻辑处理过程,及早提交或回滚事务; (细化处理逻辑,执行一段逻辑后便回滚或者提交,然后再执行其它逻辑,直到事物执行完毕提交)\n2 设置死锁超时参数为合理范围,如:3分钟-10分种;超过时间,自动放弃本次操作,避免进程悬挂;\n3 优化程序,检查并避免死锁现象出现;\n4 .对所有的脚本和SP都要仔细测试,在正是版本之前。\n5 所有的SP都要有错误处理(通过@error)\n6 一般不要修改SQL SERVER事务的默认级别。不推荐强行加锁**</span>\n\n<span style=\"color:#0000ff;font-size:large;\">**另外参考的解决方法:**</span>\n\n<span style=\"font-size:large;\">**按同一顺序访问对象\n如果所有并发事务按同一顺序访问对象,则发生死锁的可能性会降低。例如,如果两个并发事务获得 Supplier 表上的锁,然后获得 Part 表上的锁,则在其中一个事务完成之前,另一个事务被阻塞在 Supplier 表上。第一个事务提交或回滚后,第二个事务继续进行。不发生死锁。将存储过程用于所有的数据修改可以标准化访问对象的顺序。**</span>\n\n<span style=\"font-size:large;\">**避免事务中的用户交互\n避免编写包含用户交互的事务,因为运行没有用户交互的批处理的速度要远远快于用户手动响应查询的速度,例如答复应用程序请求参数的提示。例如,如果事务正在等待用户输入,而用户去吃午餐了或者甚至回家过周末了,则用户将此事务挂起使之不能完成。这样将降低系统的吞吐量,因为事务持有的任何锁只有在事务提交或回滚时才会释放。即使不出现死锁的情况,访问同一资源的其它事务也会被阻塞,等待该事务完成。\n\n保持事务简短并在一个批处理中\n在同一数据库中并发执行多个需要长时间运行的事务时通常发生死锁。事务运行时间越长,其持有排它锁或更新锁的时间也就越长,从而堵塞了其它活动并可能导致死锁。保持事务在一个批处理中,可以最小化事务的网络通信往返量,减少完成事务可能的延迟并释放锁。\n\n使用低隔离级别\n确定事务是否能在更低的隔离级别上运行。执行提交读允许事务读取另一个事务已读取(未修改)的数据,而不必等待第一个事务完成。使用较低的隔离级别(例如提交读)而不使用较高的隔离级别(例如可串行读)可以缩短持有共享锁的时间,从而降低了锁定争夺。\n\n使用绑定连接\n使用绑定连接使同一应用程序所打开的两个或多个连接可以相互合作。次级连接所获得的任何锁可以象由主连接获得的锁那样持有,反之亦然,因此不会相互阻塞。**</span>\n\n### Java 防死锁\n\n1)尽量使用tryLock(long timeout, TimeUnit unit)的方法(ReentrantLock、ReentrantReadWriteLock),设置超时时间,超时可以退出防止死锁。\n2)尽量使用java.util.concurrent(jdk 1.5以上)包的并发类代替手写控制并发,比较常用的是ConcurrentHashMap、ConcurrentLinkedQueue、AtomicBoolean等等,实际应用中java.util.concurrent.atomic十分有用,简单方便且效率比使用Lock更高\n3)尽量降低锁的使用粒度,尽量不要几个功能用同一把锁\n4)尽量减少同步的代码块","source":"_posts/死锁及如何避免.md","raw":"title: 死锁及如何避免\ntags:\n - Deadlock\nid: 208\ncategories:\n - Java\ndate: 2015-05-15 12:34:08\n---\n\n<span style=\"font-size:large;\">**什么是死锁,如何避免死锁?\n线程A需要资源X,而线程B需要资源Y,而双方都掌握有对方所要的资源,这种情况称为死锁(deadlock),或死亡拥抱(the deadly embrace)。\n**</span>\n\n<span style=\"font-size:large;\">**在并发程序设计中,死锁 (deadlock) 是一种十分常见的逻辑错误。通过采用正确的编程方式,死锁的发生不难避免。**</span>\n<div class=\"level2\">\n\n<span style=\"font-size:large;\">**在计算机专业的本科教材中,通常都会介绍死锁的四个必要条件。这四个条件缺一不可,或者说只要破坏了其中任何一个条件,死锁就不可能发生。我们来复习一下,这四个条件是:**</span>\n\n1. <div class=\"li\"><span style=\"font-size:large;\">**互斥(Mutual exclusion):存在这样一种资源,它在某个时刻只能被分配给一个执行绪(也称为线程)使用;**</span></div>\n2. <div class=\"li\"><span style=\"font-size:large;\">**持有(Hold and wait):当请求的资源已被占用从而导致执行绪阻塞时,资源占用者不但无需释放该资源,而且还可以继续请求更多资源;**</span></div>\n3. <div class=\"li\"><span style=\"font-size:large;\">**不可剥夺(No preemption):执行绪获得到的互斥资源不可被强行剥夺,换句话说,只有资源占用者自己才能释放资源;**</span></div>\n4. <div class=\"li\"><span style=\"font-size:large;\">**环形等待(Circular wait):若干执行绪以不同的次序获取互斥资源,从而形成环形等待的局面,想象在由多个执行绪组成的环形链中,每个执行绪都在等待下一个执行绪释放它持有的资源。**</span></div>\n</div>\n<span style=\"font-size:large;\">**不难看出,在死锁的四个必要条件中,第二、三和四项条件比较容易消除。通过引入事务机制,往往可以消除第二、三两项条件,方法是将所有上锁操作均作为事务对待,一旦开始上锁,即确保全部操作均可回退,同时通过锁管理器检测死锁,并剥夺资源(回退事务)。这种做法有时会造成较大开销,而且也需要对上锁模式进行较多改动。**</span>\n\n<span style=\"font-size:large;\">**消除第四项条件是比较容易且代价较低的办法。具体来说这种方法约定:上锁的顺序必须一致。具体来说,我们人为地给锁指定一种类似“水位”的方向性属性。无论已持有任何锁,该执行绪所有的上锁操作,必须按照一致的先后顺序从低到高(或从高到低)进行,且在一个系统中,只允许使用一种先后次序。**</span>\n\n<span style=\"font-size:large;\">**请注意,放锁的顺序并不会导致死锁。也就是说,尽管按照 锁A, 锁B, 放A, 放B 这样的顺序来进行锁操作看上去有些怪异,但是只要大家都按先A后B的顺序上锁,便不会导致死锁。**</span>\n\n<span style=\"color:#ff0000;font-size:large;\">**解决方法:**</span>\n\n<span style=\"font-size:large;\">**1 使用事务时,尽量缩短事务的逻辑处理过程,及早提交或回滚事务; (细化处理逻辑,执行一段逻辑后便回滚或者提交,然后再执行其它逻辑,直到事物执行完毕提交)\n2 设置死锁超时参数为合理范围,如:3分钟-10分种;超过时间,自动放弃本次操作,避免进程悬挂;\n3 优化程序,检查并避免死锁现象出现;\n4 .对所有的脚本和SP都要仔细测试,在正是版本之前。\n5 所有的SP都要有错误处理(通过@error)\n6 一般不要修改SQL SERVER事务的默认级别。不推荐强行加锁**</span>\n\n<span style=\"color:#0000ff;font-size:large;\">**另外参考的解决方法:**</span>\n\n<span style=\"font-size:large;\">**按同一顺序访问对象\n如果所有并发事务按同一顺序访问对象,则发生死锁的可能性会降低。例如,如果两个并发事务获得 Supplier 表上的锁,然后获得 Part 表上的锁,则在其中一个事务完成之前,另一个事务被阻塞在 Supplier 表上。第一个事务提交或回滚后,第二个事务继续进行。不发生死锁。将存储过程用于所有的数据修改可以标准化访问对象的顺序。**</span>\n\n<span style=\"font-size:large;\">**避免事务中的用户交互\n避免编写包含用户交互的事务,因为运行没有用户交互的批处理的速度要远远快于用户手动响应查询的速度,例如答复应用程序请求参数的提示。例如,如果事务正在等待用户输入,而用户去吃午餐了或者甚至回家过周末了,则用户将此事务挂起使之不能完成。这样将降低系统的吞吐量,因为事务持有的任何锁只有在事务提交或回滚时才会释放。即使不出现死锁的情况,访问同一资源的其它事务也会被阻塞,等待该事务完成。\n\n保持事务简短并在一个批处理中\n在同一数据库中并发执行多个需要长时间运行的事务时通常发生死锁。事务运行时间越长,其持有排它锁或更新锁的时间也就越长,从而堵塞了其它活动并可能导致死锁。保持事务在一个批处理中,可以最小化事务的网络通信往返量,减少完成事务可能的延迟并释放锁。\n\n使用低隔离级别\n确定事务是否能在更低的隔离级别上运行。执行提交读允许事务读取另一个事务已读取(未修改)的数据,而不必等待第一个事务完成。使用较低的隔离级别(例如提交读)而不使用较高的隔离级别(例如可串行读)可以缩短持有共享锁的时间,从而降低了锁定争夺。\n\n使用绑定连接\n使用绑定连接使同一应用程序所打开的两个或多个连接可以相互合作。次级连接所获得的任何锁可以象由主连接获得的锁那样持有,反之亦然,因此不会相互阻塞。**</span>\n\n### Java 防死锁\n\n1)尽量使用tryLock(long timeout, TimeUnit unit)的方法(ReentrantLock、ReentrantReadWriteLock),设置超时时间,超时可以退出防止死锁。\n2)尽量使用java.util.concurrent(jdk 1.5以上)包的并发类代替手写控制并发,比较常用的是ConcurrentHashMap、ConcurrentLinkedQueue、AtomicBoolean等等,实际应用中java.util.concurrent.atomic十分有用,简单方便且效率比使用Lock更高\n3)尽量降低锁的使用粒度,尽量不要几个功能用同一把锁\n4)尽量减少同步的代码块","slug":"死锁及如何避免","published":1,"updated":"2015-12-02T04:39:35.633Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153v6000pc0tjellzbkh8"},{"title":"操纵Session","id":"144","date":"2015-05-04T21:28:31.000Z","_content":"\nSession接口可以说是Hibernate框架中使用最多的一个接口,它负责持久化工作、负责管理持久化对象的声明周期、提供第一级别的高级缓存来保证持久化对象的数据和数据库同步。\n\n1,Session的缓存\n\nJava中,缓存通常是指Java对象的属性占用的内存空间,一般使用集合类型的属性来作为缓存。Session这一级别的缓存通常称之为一级缓存,是由它的实现类SeeionImpl中的成员属性persistenceContext中定义的一系列Java集合(Map)属性构成。\n\n当程序调用Session的CRUD方法以及调用查询几口list(),iterate()和filter()方法时,如果Session缓存中不存在对象,则加入第一级缓存,如果Session中已经存在这个对象,则不需要去数据库架子而是直接调用缓存,减少数据库访问的频率,提高程序效率。\n\n当调用Transaction的commit()事务提交方法时,会自动进行缓存清理和数据库同步。\n\nSession的缓存一般交由Hibernate框架自动管理而无需程序员干预。\n\n2,持久化生命周期\n\n一个持久化类的实例,在持久化生命周期中会在不同状态之间转变。Hibernate定义四种状态。\n\n\n\n1,瞬时状态(transient)\n\n该实例是用new创建的,还没有被持久化,不处于任何Session的缓存中,它没有对象标识符。不跟任何一个Session关联,在数据库中没有对应的记录。\n\n2,持久化状态(persistent)\n\n已经被持久化,加入到Session缓存中。实例目前与某个Session关联。它拥有对象标识符值,并且可能在数据库中找到一个对应的行。Hibernate保证在同一个Session实例的缓存中,数据库中的每条记录只对应唯一一个持久化实例。持久化对象总是被一个Session实例关联。持久化实例和数据库中的相关记录对应,Session在清理缓存时,会根据持久化实例的属性数据变化,同步更新数据库。\n\n3,移除状态(removed)\n\n如果一个对象已经被计划在一个Session中结束时删除,它就处于移除状态,但仍然处于Session的缓存中,直到工作单元结束。\n\n4,托管(detached)\n\n已经被持久化过,但已经不处于Session的缓存中。不再位于Session的缓存中,但它拥有对象标识符。\n\nSession的基本操作\n\npublic Serializable save(Object obj) throws HibernateException:持久化瞬时实例,返回对象标识符。\n\npublic Object get(Class clazz, Serializable id) throws HibernateException:根据制定OID找到一个持久化类。\n\npublic Object loadClass clazz, Serializable id) throws HibernateException:类似于get\n\npublic void delete(Object object) throws HibernateException:把指定的持久化类实例变成顺时状态,并从数据库表中移除对应的记录。\n\npublic void update(Object object) throws HibernateException:重附托管对象,并把它的状态更新到数据库表中。\n\npublic void saveOrUpdate(Object obj) throws HibernateException: 同时具有save()和update()的功能\n\npublic Object merge(Object object) throws HibernateException:将给定实例的状态复制到具有相同标识符的持久化实例上,并返回这个持久化实例。","source":"_posts/操纵Session.md","raw":"title: 操纵Session\ntags:\n - Hibernate\n - Session\nid: 144\ncategories:\n - Hibernate\ndate: 2015-05-05 05:28:31\n---\n\nSession接口可以说是Hibernate框架中使用最多的一个接口,它负责持久化工作、负责管理持久化对象的声明周期、提供第一级别的高级缓存来保证持久化对象的数据和数据库同步。\n\n1,Session的缓存\n\nJava中,缓存通常是指Java对象的属性占用的内存空间,一般使用集合类型的属性来作为缓存。Session这一级别的缓存通常称之为一级缓存,是由它的实现类SeeionImpl中的成员属性persistenceContext中定义的一系列Java集合(Map)属性构成。\n\n当程序调用Session的CRUD方法以及调用查询几口list(),iterate()和filter()方法时,如果Session缓存中不存在对象,则加入第一级缓存,如果Session中已经存在这个对象,则不需要去数据库架子而是直接调用缓存,减少数据库访问的频率,提高程序效率。\n\n当调用Transaction的commit()事务提交方法时,会自动进行缓存清理和数据库同步。\n\nSession的缓存一般交由Hibernate框架自动管理而无需程序员干预。\n\n2,持久化生命周期\n\n一个持久化类的实例,在持久化生命周期中会在不同状态之间转变。Hibernate定义四种状态。\n\n\n\n1,瞬时状态(transient)\n\n该实例是用new创建的,还没有被持久化,不处于任何Session的缓存中,它没有对象标识符。不跟任何一个Session关联,在数据库中没有对应的记录。\n\n2,持久化状态(persistent)\n\n已经被持久化,加入到Session缓存中。实例目前与某个Session关联。它拥有对象标识符值,并且可能在数据库中找到一个对应的行。Hibernate保证在同一个Session实例的缓存中,数据库中的每条记录只对应唯一一个持久化实例。持久化对象总是被一个Session实例关联。持久化实例和数据库中的相关记录对应,Session在清理缓存时,会根据持久化实例的属性数据变化,同步更新数据库。\n\n3,移除状态(removed)\n\n如果一个对象已经被计划在一个Session中结束时删除,它就处于移除状态,但仍然处于Session的缓存中,直到工作单元结束。\n\n4,托管(detached)\n\n已经被持久化过,但已经不处于Session的缓存中。不再位于Session的缓存中,但它拥有对象标识符。\n\nSession的基本操作\n\npublic Serializable save(Object obj) throws HibernateException:持久化瞬时实例,返回对象标识符。\n\npublic Object get(Class clazz, Serializable id) throws HibernateException:根据制定OID找到一个持久化类。\n\npublic Object loadClass clazz, Serializable id) throws HibernateException:类似于get\n\npublic void delete(Object object) throws HibernateException:把指定的持久化类实例变成顺时状态,并从数据库表中移除对应的记录。\n\npublic void update(Object object) throws HibernateException:重附托管对象,并把它的状态更新到数据库表中。\n\npublic void saveOrUpdate(Object obj) throws HibernateException: 同时具有save()和update()的功能\n\npublic Object merge(Object object) throws HibernateException:将给定实例的状态复制到具有相同标识符的持久化实例上,并返回这个持久化实例。","slug":"操纵Session","published":1,"updated":"2015-12-02T04:39:35.633Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153vb000uc0tjy78l19cm"},{"title":"对象入门","id":"186","date":"2015-05-12T06:31:01.000Z","_content":"\nOOP(Object-oriented programming)\n\n1,抽象的进步\n\n所有的编程语言的最终目的都是提供一种“抽象”方法。汇编语言是对基础机器的少量抽象,后来许多“命令式”语言(FORTRAN,BASIC,C)是对汇编语言的抽象。与汇编语言相比,这些语言已有了长足的进步,但它们的抽象原理依然要求我们着重考虑计算机的结构,而非考虑问题本身的结构。\n\n我们将问题空间的元素以及它们在方案空间的表示物成为“对象”(Object)。SmallTalk的五大特征,这是第一种成功的面相对象的程序设计语言,也是Java语言的基础:\n\n1. 所有的东西都是对象。对象可以想象成一种新型的变量。\n2. 程序是一大堆对象的集合。通过消息传递,个对象知道自己该做些什么。为了面向对象发出请求,需向那个对象发送一条消息。\n3. 每个对象都有自己的存储空间,可容纳其他对象。或者说通过封装现有对象可制作出新型对象。\n4. 每个对象都有一种类型。每个对象都是某一个类的一个实例,其中Class 和 Type 是同义词。一个类的重要特征是“能够将什么消息发送给它”。\n5. 同一类的所有对象能够接受相同的信息。对象的“可替代性”\n2,对象的接口\n\n我们向对象发出的请求是通过它的的接口定义的,对象的类型和类则规定了它的接口形式。“类型”和“接口”的等价或对应关系是面向对象程序设计的基础。\n\n3,实现方案的隐藏\n\n客户程序员:收集一个充斥着各种类的编程工具箱,以便能够快速的开发符合自己要求的东西。\n\n类创建者:从头构建一个类,只向客户程序员开放有必要开放的东西(接口),其他所有细节都隐藏起来。\n\n“接口”(Interface)规定了可对一个特定的对象发出哪些请求。然而,必须在某个地方存放着一些代码以便满足这些请求。这些代码以及哪些隐藏起来的数据叫做“隐藏的实现”。\n\n若是任何人都能够使用一个类的所有成员,那么客户程序员可对那个类做任何事情,没有办法强制他们遵守任何约束。有两方面的原因促使我们控制成员的访问。\n\n防止程序员接触他们不该接触的东西,通常是内部数据类型的设计思想。\n\n允许库设计人员修改内部结构,不用担心它会对客户程序员造成什么影响。接口与实现方法早已分开,并分受到保护,用户只需要重新连接一下就好。\n\nJava采用三个显示(明确)关键字以及一个隐式(暗示)关键字来设置类边界:public, private, protected以及暗示性的friendly。若没有明确指定其他关键字,则默认为后者。这些关键字的使用和含义相当直观,它们决定了谁能够使用后续的定义内容。“public”意味着后续的定义任何人均可使用。“private”意味着除了自己、类型创建者以及那个类型的内部函数成员,其他任何人都不能访问后续的定义信息。private在你与客户程序员之间竖起了一堵墙。若有人想访问私有变量成员,就会得到一个编译错误。“friendly”涉及“包装”或“封装”的概念,若某样东西是友好的,意味着它只能在这个包装范围内使用(包装访问)。“protected”与“private”相似,只是一个继承的类可访问受保护的成员,但不能访问私有成员\n\n4,方案的重复使用\n\n代码或设计方案的重复使用是面向对象程序设计提供的最伟大的一种杠杆。\n\n在现有类的基础上组织一个新类----组织。新类的成员对象通常设为“私有”,使用这个类的客户程序员不能访问它们,这样我们可以不干扰客户代码的前提下,从容的修改那些成员。\n\n由于继承的重要性,所以在面向对象的程序设计中,它通常被重点强调。“继承应当随处可见”,沿用这种思想的设计将是非常笨拙的,会大大增加程序的复杂程度。相反,新建类的时候,首先考虑“组织”对象,这样做显得更加简单和灵活。\n\n5,继承:重新使用接口\n\n继承不完全等同于克隆。若原始类(基础类,父类,超类)发生变化,修改过的“克隆类”(继承类或子类)也会反映这些变化。通过extends关键字来实现。\n\n使用继承时,相当于创建了一个新类。这个新类不仅包含了现有类型的所有成员(尽管private 成员被隐藏 起来,且不能访问),但更重要的是,它复制了基础类的接口。\n\n5.1 改善基础类\n\n尽管extends 关键字暗示着我们要为接口“扩展”新功能,但实情并非肯定如此。为区分我们的新类,第二 个办法是改变基础类一个现有函数的行为。我们将其称作“改善”那个函数。 为改善一个函数,只需为衍生类的函数建立一个新定义即可。我们的目标是:“尽管使用的函数接口未变, 但它的新版本具有不同的表现”。\n\n5.2 等价于类似的关系\n\n我们通常认为基础类和衍生类之间存在一种“等价”关系——因为我们可以理直气壮地说:“圆 就是一种几何形状”。\n\n但在许多时候,我们必须为衍生类型加入新的接口元素。所以不仅扩展了接口,也创建了一种新类型。这种 新类型仍可替换成基础类型,但这种替换并不是完美的,因为不可在基础类里访问新函数。我们将其称作 “类似”关系;新类型拥有旧类型的接口,但也包含了其他函数,所以不能说它们是完全等价的。\n\n6,多形对象的互换作用\n\n通常,继承最终以创建一系列类收场,所有类都建立在统一的接口基础之上。\n\n我们将这种把衍生类当做它的基础类型处理的过程叫做Upcasting。其中cast是指根据一个想成的模型创建;而Up表明继承的方向是从上面来的。\n\n上溯造型的方法用来避免去调查准确类型的一个好办法。\n\n6.1 动态绑定\n\n将一条消息发送给对象时,如果并不知道对方的具体类型是什么,但采取的行动同样是正确的,这种情况就叫做“多形性”。对面向对象的程序设计语言来说,它们用以实现多形性的方法叫做“动态绑定”。\n\n6.2 抽象的基础类和接口\n\n我们经常希望基础类能够给自己的衍生类提供一个接口。使用“abstract”关键字,如果有人试图创建抽象类的一个对象,编译器会阻止他们。可以用“abstract”关键字描述一个尚未实现的方法,作为“根”使用。继承抽象类的衍生类必须实现abstract方法,不然也会变成抽象类。通过创建一个抽象方法,我们可以将一个方法置入接口中,不必再为那个方法提供可能毫无意义的主题代码。\n\nInterface(接口)关键字将抽象类的概念更延伸了一步,它完全禁止了所有的函数定义。“接口”是一种相当有效和常用的工具,另外如果自己愿意,可以将多个接口合并成在一起。\n\n7,对象的创建和存在的时间\n\n对象的创建及破坏方式,对象需要的数据在哪?如何控制对象的“存在时间”呢?\n\nC++ 认为程序的执行效率是最重要的一个问题,所以它允许程序员做出选择。为获得最快的运行速度,存储以及存在时间可在编写程序时指定,只需将对象放置在堆栈或者静态存储区域即可。这样便为存储空间的分配和释放提供了一个优先级。某种情况下这种优先级是非常有价值的。\n\n在一个内存池中动态的创建对象,该内存池也叫“堆”或“内存堆”。若采用这种方式,除非进入运行期,否则根本不知道到底需要多少个对象,也不知道它们的存在时间有多长,以及准确的类型是什么?\n\n存储空间的管理是在运行期动态进行的,所以在内存堆里分配存储空间的时间比在堆栈里创建的时间长的多。\n\nC++允许我们决定是在写程序时创建对象,还是在运行时创建对象,这种控制方法更加灵活。对象的生存时间“Lifttime”。若在堆栈或者静态存储空间里创建一个对象,编译器会判断对象的持续时间有多长,会到时自动“破坏”或者“清除”它。程序员可用两种方式破会一个对象:用程序话方法来决定何时破坏对象,或者利用由运行环境提供的一种“垃圾收集器”的特性,自动寻找那些不再使用的对象,并将其清除。\n\n7.1 集合与继承器\n\n集,队列,散列表,数,堆栈等等。所有的集合都提供了相应的读写功能。Push,Add功能。\n\n继承器(Iterator),它属于一种对象,负责选择集合内的元素,并把它们提供给继承器的用户。最早的标准继承器(Enumeration),java1.2中添加Iteration。\n\n根据具体的需求选择集合类型。\n\n7.2 单根结构\n\n在Java中所有类都继承于Object类,单根结构有很多优点:\n\n* 都有相同的类型\n* 不会判断不出一个对象的类型\n* 方便省事,适用于新手,我们可以更方便的实现一个垃圾收集器\n7.3 集合库与方便使用集合\n\n下塑造性与模板/通用性\n\nDowncasting。从一个集合中提取对象句柄时,必须用某些方法记住它,以保证下塑造性的正确进行。利用参数化类型,定制集合。\n\n7.4 对象清除\n\n在Java中,垃圾收集器在设计时已考虑到了内存的释放问题。垃圾收集器“知道”一个对象在什么时候不再使用,让后会自动释放那个对象占据的内存空间,采用这种方式,另外加上所有对象都从单根Object继承的事实,而且由于我们只能在内存堆中以一种方式创建对象,所以Java的编程要比C++ 的编程简单得多。\n\n垃圾收集器对效率的影响\n\nJava是在运行时动态的创建对象,C++则是在堆栈中创建对象。在堆栈中创建对象是为对象分配存储空间最有效的一种方式,也是释放那些空间最有效的一种方式。在内存堆(Heap)中创建对象可能要付出昂贵的代价,如果总是从同一基础类继承,并使用所有函数调用都具有“同质多形”特征,那么也不可避免地需要付出一定的代价。\n\n8 违例控制:解决错误\n\n“违例控制”是将错误控制方案内置到程序设计语言中,有时甚至内建到操作系统内。“Exception”特殊的对象,从产生错误的地方抛出。Java中的为例控制模块从一开始就封装好的,所以必须使用它。\n\n9 多线程\n\n在计算机编程中,一个最基本的概念就是同时对多个任务加以控制。最早是“中断服务例程”,主进程暂时通过硬件级的中断实现的。很难移植,造成了另一类的代价高昂的问题。中断对于那些实时性很强的任务来说是必要的。但还存在其他许多问题,,它们只要求将问题划分进入独立运行的程序片断中,使整个程序快速更迅速地响应用户的请求。在一个程序中,这些独立运行的片断叫做“线程”,利用它编程的概念叫做“多线程处理”。多线程处理一个常见的例子就是用户界面。利用线程,用户可以按下一个按钮,然后程序会立即做出响应,而不是让用户等待程序完成当前任务后再开始响应。最开始,线程只是用于分配单个处理器的处理时间的一种工具。但假如操作系统支持多个处理器,那么每个线程都可以分配给一个不同的处理器,真正进入“并行计算”状态。从程序设计语言的角度看,多线程操作最优价值的特性之一就是程序员不必关系到底使用多少个处理器。程序在逻辑意义上被划分出多个线程。多线程处理的问题:共享资源。一个线程可以将资源锁定,在完成了它的任务后,再解开这个锁,使其他线程可以接着使用同样的资源。\n\nJava的多线程机制已经内建在语言中了,这使一个可能较复杂的问题简单起来。对多线程支持是在对象这一级支持的,所以一个执行线程可以表达为一个对象。Java也提供了有限的资源锁定方案。它能锁定任何对象占用的内存,所以同一时间只能有一个线程使用特定的内存空间。未达到这个目的使用synchronized关键字。其他类型的资源必须有程序员明确锁定,这通常要求程序员创建一个对象,用它代表一种锁,所有线程在访问那个资源是都必须检查这个锁。\n\n10,永久性\n\n创建一个对象后,只要我们需要,它就会一直存在下去。但在程序的运行结束后,对象的生存期也宣告结束。\n\n11,分析与设计\n\n对象是什么?(怎样将自己的项目分割成组件)\n\n它们的接口是什么?(需要将什么消息发给每一个对象)\n\n阶段0 ,计划:决定后面的过程,有阶段性的工作任务。\n\n阶段1,要制作什么:建立需求分析和系统规格,估算出时间。\n\n阶段2,如何创建:必须拿出一套设计方案,并解释其中包含各类对象在外观上是什么样子,以及相互间是如何沟通的。此时用“UML”。\n\n阶段3,开始创建:先拿出一套较为全面的方案,使其尽可能的设想周全。\n\n阶段4,校订:改变。","source":"_posts/对象入门.md","raw":"title: 对象入门\nid: 186\ncategories:\n - Java\ndate: 2015-05-12 14:31:01\ntags:\n - OOP\n---\n\nOOP(Object-oriented programming)\n\n1,抽象的进步\n\n所有的编程语言的最终目的都是提供一种“抽象”方法。汇编语言是对基础机器的少量抽象,后来许多“命令式”语言(FORTRAN,BASIC,C)是对汇编语言的抽象。与汇编语言相比,这些语言已有了长足的进步,但它们的抽象原理依然要求我们着重考虑计算机的结构,而非考虑问题本身的结构。\n\n我们将问题空间的元素以及它们在方案空间的表示物成为“对象”(Object)。SmallTalk的五大特征,这是第一种成功的面相对象的程序设计语言,也是Java语言的基础:\n\n1. 所有的东西都是对象。对象可以想象成一种新型的变量。\n2. 程序是一大堆对象的集合。通过消息传递,个对象知道自己该做些什么。为了面向对象发出请求,需向那个对象发送一条消息。\n3. 每个对象都有自己的存储空间,可容纳其他对象。或者说通过封装现有对象可制作出新型对象。\n4. 每个对象都有一种类型。每个对象都是某一个类的一个实例,其中Class 和 Type 是同义词。一个类的重要特征是“能够将什么消息发送给它”。\n5. 同一类的所有对象能够接受相同的信息。对象的“可替代性”\n2,对象的接口\n\n我们向对象发出的请求是通过它的的接口定义的,对象的类型和类则规定了它的接口形式。“类型”和“接口”的等价或对应关系是面向对象程序设计的基础。\n\n3,实现方案的隐藏\n\n客户程序员:收集一个充斥着各种类的编程工具箱,以便能够快速的开发符合自己要求的东西。\n\n类创建者:从头构建一个类,只向客户程序员开放有必要开放的东西(接口),其他所有细节都隐藏起来。\n\n“接口”(Interface)规定了可对一个特定的对象发出哪些请求。然而,必须在某个地方存放着一些代码以便满足这些请求。这些代码以及哪些隐藏起来的数据叫做“隐藏的实现”。\n\n若是任何人都能够使用一个类的所有成员,那么客户程序员可对那个类做任何事情,没有办法强制他们遵守任何约束。有两方面的原因促使我们控制成员的访问。\n\n防止程序员接触他们不该接触的东西,通常是内部数据类型的设计思想。\n\n允许库设计人员修改内部结构,不用担心它会对客户程序员造成什么影响。接口与实现方法早已分开,并分受到保护,用户只需要重新连接一下就好。\n\nJava采用三个显示(明确)关键字以及一个隐式(暗示)关键字来设置类边界:public, private, protected以及暗示性的friendly。若没有明确指定其他关键字,则默认为后者。这些关键字的使用和含义相当直观,它们决定了谁能够使用后续的定义内容。“public”意味着后续的定义任何人均可使用。“private”意味着除了自己、类型创建者以及那个类型的内部函数成员,其他任何人都不能访问后续的定义信息。private在你与客户程序员之间竖起了一堵墙。若有人想访问私有变量成员,就会得到一个编译错误。“friendly”涉及“包装”或“封装”的概念,若某样东西是友好的,意味着它只能在这个包装范围内使用(包装访问)。“protected”与“private”相似,只是一个继承的类可访问受保护的成员,但不能访问私有成员\n\n4,方案的重复使用\n\n代码或设计方案的重复使用是面向对象程序设计提供的最伟大的一种杠杆。\n\n在现有类的基础上组织一个新类----组织。新类的成员对象通常设为“私有”,使用这个类的客户程序员不能访问它们,这样我们可以不干扰客户代码的前提下,从容的修改那些成员。\n\n由于继承的重要性,所以在面向对象的程序设计中,它通常被重点强调。“继承应当随处可见”,沿用这种思想的设计将是非常笨拙的,会大大增加程序的复杂程度。相反,新建类的时候,首先考虑“组织”对象,这样做显得更加简单和灵活。\n\n5,继承:重新使用接口\n\n继承不完全等同于克隆。若原始类(基础类,父类,超类)发生变化,修改过的“克隆类”(继承类或子类)也会反映这些变化。通过extends关键字来实现。\n\n使用继承时,相当于创建了一个新类。这个新类不仅包含了现有类型的所有成员(尽管private 成员被隐藏 起来,且不能访问),但更重要的是,它复制了基础类的接口。\n\n5.1 改善基础类\n\n尽管extends 关键字暗示着我们要为接口“扩展”新功能,但实情并非肯定如此。为区分我们的新类,第二 个办法是改变基础类一个现有函数的行为。我们将其称作“改善”那个函数。 为改善一个函数,只需为衍生类的函数建立一个新定义即可。我们的目标是:“尽管使用的函数接口未变, 但它的新版本具有不同的表现”。\n\n5.2 等价于类似的关系\n\n我们通常认为基础类和衍生类之间存在一种“等价”关系——因为我们可以理直气壮地说:“圆 就是一种几何形状”。\n\n但在许多时候,我们必须为衍生类型加入新的接口元素。所以不仅扩展了接口,也创建了一种新类型。这种 新类型仍可替换成基础类型,但这种替换并不是完美的,因为不可在基础类里访问新函数。我们将其称作 “类似”关系;新类型拥有旧类型的接口,但也包含了其他函数,所以不能说它们是完全等价的。\n\n6,多形对象的互换作用\n\n通常,继承最终以创建一系列类收场,所有类都建立在统一的接口基础之上。\n\n我们将这种把衍生类当做它的基础类型处理的过程叫做Upcasting。其中cast是指根据一个想成的模型创建;而Up表明继承的方向是从上面来的。\n\n上溯造型的方法用来避免去调查准确类型的一个好办法。\n\n6.1 动态绑定\n\n将一条消息发送给对象时,如果并不知道对方的具体类型是什么,但采取的行动同样是正确的,这种情况就叫做“多形性”。对面向对象的程序设计语言来说,它们用以实现多形性的方法叫做“动态绑定”。\n\n6.2 抽象的基础类和接口\n\n我们经常希望基础类能够给自己的衍生类提供一个接口。使用“abstract”关键字,如果有人试图创建抽象类的一个对象,编译器会阻止他们。可以用“abstract”关键字描述一个尚未实现的方法,作为“根”使用。继承抽象类的衍生类必须实现abstract方法,不然也会变成抽象类。通过创建一个抽象方法,我们可以将一个方法置入接口中,不必再为那个方法提供可能毫无意义的主题代码。\n\nInterface(接口)关键字将抽象类的概念更延伸了一步,它完全禁止了所有的函数定义。“接口”是一种相当有效和常用的工具,另外如果自己愿意,可以将多个接口合并成在一起。\n\n7,对象的创建和存在的时间\n\n对象的创建及破坏方式,对象需要的数据在哪?如何控制对象的“存在时间”呢?\n\nC++ 认为程序的执行效率是最重要的一个问题,所以它允许程序员做出选择。为获得最快的运行速度,存储以及存在时间可在编写程序时指定,只需将对象放置在堆栈或者静态存储区域即可。这样便为存储空间的分配和释放提供了一个优先级。某种情况下这种优先级是非常有价值的。\n\n在一个内存池中动态的创建对象,该内存池也叫“堆”或“内存堆”。若采用这种方式,除非进入运行期,否则根本不知道到底需要多少个对象,也不知道它们的存在时间有多长,以及准确的类型是什么?\n\n存储空间的管理是在运行期动态进行的,所以在内存堆里分配存储空间的时间比在堆栈里创建的时间长的多。\n\nC++允许我们决定是在写程序时创建对象,还是在运行时创建对象,这种控制方法更加灵活。对象的生存时间“Lifttime”。若在堆栈或者静态存储空间里创建一个对象,编译器会判断对象的持续时间有多长,会到时自动“破坏”或者“清除”它。程序员可用两种方式破会一个对象:用程序话方法来决定何时破坏对象,或者利用由运行环境提供的一种“垃圾收集器”的特性,自动寻找那些不再使用的对象,并将其清除。\n\n7.1 集合与继承器\n\n集,队列,散列表,数,堆栈等等。所有的集合都提供了相应的读写功能。Push,Add功能。\n\n继承器(Iterator),它属于一种对象,负责选择集合内的元素,并把它们提供给继承器的用户。最早的标准继承器(Enumeration),java1.2中添加Iteration。\n\n根据具体的需求选择集合类型。\n\n7.2 单根结构\n\n在Java中所有类都继承于Object类,单根结构有很多优点:\n\n* 都有相同的类型\n* 不会判断不出一个对象的类型\n* 方便省事,适用于新手,我们可以更方便的实现一个垃圾收集器\n7.3 集合库与方便使用集合\n\n下塑造性与模板/通用性\n\nDowncasting。从一个集合中提取对象句柄时,必须用某些方法记住它,以保证下塑造性的正确进行。利用参数化类型,定制集合。\n\n7.4 对象清除\n\n在Java中,垃圾收集器在设计时已考虑到了内存的释放问题。垃圾收集器“知道”一个对象在什么时候不再使用,让后会自动释放那个对象占据的内存空间,采用这种方式,另外加上所有对象都从单根Object继承的事实,而且由于我们只能在内存堆中以一种方式创建对象,所以Java的编程要比C++ 的编程简单得多。\n\n垃圾收集器对效率的影响\n\nJava是在运行时动态的创建对象,C++则是在堆栈中创建对象。在堆栈中创建对象是为对象分配存储空间最有效的一种方式,也是释放那些空间最有效的一种方式。在内存堆(Heap)中创建对象可能要付出昂贵的代价,如果总是从同一基础类继承,并使用所有函数调用都具有“同质多形”特征,那么也不可避免地需要付出一定的代价。\n\n8 违例控制:解决错误\n\n“违例控制”是将错误控制方案内置到程序设计语言中,有时甚至内建到操作系统内。“Exception”特殊的对象,从产生错误的地方抛出。Java中的为例控制模块从一开始就封装好的,所以必须使用它。\n\n9 多线程\n\n在计算机编程中,一个最基本的概念就是同时对多个任务加以控制。最早是“中断服务例程”,主进程暂时通过硬件级的中断实现的。很难移植,造成了另一类的代价高昂的问题。中断对于那些实时性很强的任务来说是必要的。但还存在其他许多问题,,它们只要求将问题划分进入独立运行的程序片断中,使整个程序快速更迅速地响应用户的请求。在一个程序中,这些独立运行的片断叫做“线程”,利用它编程的概念叫做“多线程处理”。多线程处理一个常见的例子就是用户界面。利用线程,用户可以按下一个按钮,然后程序会立即做出响应,而不是让用户等待程序完成当前任务后再开始响应。最开始,线程只是用于分配单个处理器的处理时间的一种工具。但假如操作系统支持多个处理器,那么每个线程都可以分配给一个不同的处理器,真正进入“并行计算”状态。从程序设计语言的角度看,多线程操作最优价值的特性之一就是程序员不必关系到底使用多少个处理器。程序在逻辑意义上被划分出多个线程。多线程处理的问题:共享资源。一个线程可以将资源锁定,在完成了它的任务后,再解开这个锁,使其他线程可以接着使用同样的资源。\n\nJava的多线程机制已经内建在语言中了,这使一个可能较复杂的问题简单起来。对多线程支持是在对象这一级支持的,所以一个执行线程可以表达为一个对象。Java也提供了有限的资源锁定方案。它能锁定任何对象占用的内存,所以同一时间只能有一个线程使用特定的内存空间。未达到这个目的使用synchronized关键字。其他类型的资源必须有程序员明确锁定,这通常要求程序员创建一个对象,用它代表一种锁,所有线程在访问那个资源是都必须检查这个锁。\n\n10,永久性\n\n创建一个对象后,只要我们需要,它就会一直存在下去。但在程序的运行结束后,对象的生存期也宣告结束。\n\n11,分析与设计\n\n对象是什么?(怎样将自己的项目分割成组件)\n\n它们的接口是什么?(需要将什么消息发给每一个对象)\n\n阶段0 ,计划:决定后面的过程,有阶段性的工作任务。\n\n阶段1,要制作什么:建立需求分析和系统规格,估算出时间。\n\n阶段2,如何创建:必须拿出一套设计方案,并解释其中包含各类对象在外观上是什么样子,以及相互间是如何沟通的。此时用“UML”。\n\n阶段3,开始创建:先拿出一套较为全面的方案,使其尽可能的设想周全。\n\n阶段4,校订:改变。","slug":"对象入门","published":1,"updated":"2015-12-02T04:39:35.633Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153vg0010c0tj0u5mckaw"},{"title":"Struts Tiles","id":"106","date":"2015-04-29T18:44:25.000Z","_content":"\nStruts Tiles 框架提供了一种模板机制,模板定义了网页的布局,同一模板可以被多个Web页面公用。Tiles框架还允许定义可重用的Tiles组件,它可以描述一个完整的网页,也可以描述网页的局部内容。\n<pre>iframe框架中也可以嵌入多个页面,但对于每个请求一个页面,服务器就要开启一个线程,也就是说,采用iframe框架,当用户第一次向服务器请求页面时,服务器要为这一次请求开启多个线程。而Tiles框架,将多个页面组合成一个页面,每次请求,服务器只要开启一个线程它既实现了iframe的布局功能,也解决了服务器负载问题\n</pre>\nTiles框架增强了基于组件的设计和Web UI设计中的模板概念。接触WebUI组件之间的耦合并重用它们。Tiles模板的优点:\n\n1,创建可重用的模板\n\n2,动态构建和装在页面\n\n3,定义可重用的Tiles组件\n\n4,支持国际化\n\nTiles建立在JSP的include指令的基础上,但比JSP的include指令更加强大。包括以下内容:\n\n* Tiles标签库\n* Tiles组件的配置文件\n* TilesPlugIn插件\nTiles的insert标签取代JSP include指令来创建复合式页面,还不能充分发挥Tiles框架的优势。将Tiles的组件代码移植到tiles-defs.xml文件中。\n\n集成Struts与Tiles\n\n1. 创建工程,设置Tiles环境\n2. 设置页面\n3. 设置XML文件在WEB-INF中添加tiles-defs.xml文件\n4. 修改index.jsp文件\n5. 在Struts-config.xml中配置TilesPlugin插件\n6. 发布运行\n如果Tiles组件代表完整的网页,可以通过Struts Action来调用Tiles组件。\n<pre><action-mappings>\n <action path=\"/index\" type=\"org.apache.struts.actions.ForwardAction\" parameter=\"index-definition\">\n </action>\n</action-mappings></pre>\nForwardAction把请求转发给名为index-definition的Tiles组件,能够充分利用Struts框架的流程控制功能,又能减少JSP文件的数目。","source":"_posts/struts-tiles.md","raw":"title: Struts Tiles\ntags:\n - struts\n - Tiles\nid: 106\ncategories:\n - Struts\ndate: 2015-04-30 02:44:25\n---\n\nStruts Tiles 框架提供了一种模板机制,模板定义了网页的布局,同一模板可以被多个Web页面公用。Tiles框架还允许定义可重用的Tiles组件,它可以描述一个完整的网页,也可以描述网页的局部内容。\n<pre>iframe框架中也可以嵌入多个页面,但对于每个请求一个页面,服务器就要开启一个线程,也就是说,采用iframe框架,当用户第一次向服务器请求页面时,服务器要为这一次请求开启多个线程。而Tiles框架,将多个页面组合成一个页面,每次请求,服务器只要开启一个线程它既实现了iframe的布局功能,也解决了服务器负载问题\n</pre>\nTiles框架增强了基于组件的设计和Web UI设计中的模板概念。接触WebUI组件之间的耦合并重用它们。Tiles模板的优点:\n\n1,创建可重用的模板\n\n2,动态构建和装在页面\n\n3,定义可重用的Tiles组件\n\n4,支持国际化\n\nTiles建立在JSP的include指令的基础上,但比JSP的include指令更加强大。包括以下内容:\n\n* Tiles标签库\n* Tiles组件的配置文件\n* TilesPlugIn插件\nTiles的insert标签取代JSP include指令来创建复合式页面,还不能充分发挥Tiles框架的优势。将Tiles的组件代码移植到tiles-defs.xml文件中。\n\n集成Struts与Tiles\n\n1. 创建工程,设置Tiles环境\n2. 设置页面\n3. 设置XML文件在WEB-INF中添加tiles-defs.xml文件\n4. 修改index.jsp文件\n5. 在Struts-config.xml中配置TilesPlugin插件\n6. 发布运行\n如果Tiles组件代表完整的网页,可以通过Struts Action来调用Tiles组件。\n<pre><action-mappings>\n <action path=\"/index\" type=\"org.apache.struts.actions.ForwardAction\" parameter=\"index-definition\">\n </action>\n</action-mappings></pre>\nForwardAction把请求转发给名为index-definition的Tiles组件,能够充分利用Struts框架的流程控制功能,又能减少JSP文件的数目。","slug":"struts-tiles","published":1,"updated":"2015-12-02T04:39:35.632Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153vm0014c0tjbsk9ns59"},{"title":"Struts Login Demo","id":"61","date":"2015-04-22T04:30:41.000Z","_content":"\n应用场景:当用户访问某一个应用程序之前,必须先进入登陆界面,进行登陆验证。\n\n\n\nStruts的核心功能是前端控制器,前端控制器是一个Servlet,在web.xml中配置所有Request都必须经过前端控制器。前端控制器的名字是ActionServlet,由框架来实现和管理。所有的视图和业务逻辑隔离都是因为这个ActionServlet,可以把它理解为分发器,Dispatcher。\n\nStruts中以XML配置代替硬编码配置信息。以前决定JSP往哪个Servlet提交,是要卸载JSP代码中,也就是说一点这个提交路径要改,就必须改写代码再重新编译。而Struts中编码的只是一个逻辑名字,它对应的class文件写进了xml配置文件中,这个配置文件记录着所有的映射关系,一旦需要改变路径只需要改变XML文件。这也就是Struts-config.xml文件的重用性。\n\n前端控制器从Struts-config.xml中查找与请求匹配的内容,然后进行相关操作。\n\npath值为/login,对应login.do的操作。当login.do的请求到来之后,用一个类型为LoginAction的对象来处理这个请求,在处理请求时需要用一个名为loginActionForm的对象来封装请求的内容。处理后的结构再提交给前端控制器,由前端控制器根据forward的值将相应的内容发送至客户端。\n\nAction为后端控制器,DispatchAction,DynaValidationAction.等等。都有一个execute()方法,用来处理业务逻辑,request , response, formBean, actionMapping4个对象,放回actionForward对象。\n\n在Struts中ActionServlet通过读取struts-config.xml中的配置信息来决定,用户的请求发送给哪个Action对象。每个Action的映射都是通过一个<Action>元素来配置。\n\n这些配置在系统启动时被读入内存,供Struts在运行期间使用。在内存中每个<action>元素对应一个struts.action.ActionMapping类的实例。\n\n1,Web应用启动初始化ActionServlet\n\n2,ActionServlet从struts-config.xml中读取配置信息,把它们存放到各个配置对象中。\n\n\n\n ","source":"_posts/struts-login-demo.md","raw":"title: Struts Login Demo\ntags:\n - Login\n - struts\nid: 61\ncategories:\n - Struts\ndate: 2015-04-22 12:30:41\n---\n\n应用场景:当用户访问某一个应用程序之前,必须先进入登陆界面,进行登陆验证。\n\n\n\nStruts的核心功能是前端控制器,前端控制器是一个Servlet,在web.xml中配置所有Request都必须经过前端控制器。前端控制器的名字是ActionServlet,由框架来实现和管理。所有的视图和业务逻辑隔离都是因为这个ActionServlet,可以把它理解为分发器,Dispatcher。\n\nStruts中以XML配置代替硬编码配置信息。以前决定JSP往哪个Servlet提交,是要卸载JSP代码中,也就是说一点这个提交路径要改,就必须改写代码再重新编译。而Struts中编码的只是一个逻辑名字,它对应的class文件写进了xml配置文件中,这个配置文件记录着所有的映射关系,一旦需要改变路径只需要改变XML文件。这也就是Struts-config.xml文件的重用性。\n\n前端控制器从Struts-config.xml中查找与请求匹配的内容,然后进行相关操作。\n\npath值为/login,对应login.do的操作。当login.do的请求到来之后,用一个类型为LoginAction的对象来处理这个请求,在处理请求时需要用一个名为loginActionForm的对象来封装请求的内容。处理后的结构再提交给前端控制器,由前端控制器根据forward的值将相应的内容发送至客户端。\n\nAction为后端控制器,DispatchAction,DynaValidationAction.等等。都有一个execute()方法,用来处理业务逻辑,request , response, formBean, actionMapping4个对象,放回actionForward对象。\n\n在Struts中ActionServlet通过读取struts-config.xml中的配置信息来决定,用户的请求发送给哪个Action对象。每个Action的映射都是通过一个<Action>元素来配置。\n\n这些配置在系统启动时被读入内存,供Struts在运行期间使用。在内存中每个<action>元素对应一个struts.action.ActionMapping类的实例。\n\n1,Web应用启动初始化ActionServlet\n\n2,ActionServlet从struts-config.xml中读取配置信息,把它们存放到各个配置对象中。\n\n\n\n ","slug":"struts-login-demo","published":1,"updated":"2015-12-02T04:39:35.632Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153vs001bc0tjtdpu045s"},{"title":"Struts components","id":"70","date":"2015-04-23T00:31:23.000Z","_content":"\n<table>\n<thead>\n<tr>\n<th>名称</th>\n<th>描述</th>\n</tr>\n</thead>\n<tbody>\n<tr>\n<td>Action</td>\n<td>控制器的一部分,用于模型的交互,执行状态改变或状态查询,以及告诉ActionServlet下一个选择的视图。</td>\n</tr>\n<tr>\n<td>ActionForm</td>\n<td>状态改变的数据</td>\n</tr>\n<tr>\n<td>ActionForward</td>\n<td>用户指向或视图选择</td>\n</tr>\n<tr>\n<td>ActionMapping</td>\n<td>状态改变事件</td>\n</tr>\n<tr>\n<td>ActionServlet</td>\n<td>控制器,接收用户请求或状态改变,以及发出视图选择</td>\n</tr>\n</tbody>\n</table>\n\n### 1,ActionServlet\n\nActionServlet的功能是将一个用户端的URI映射到一个相应的Action类,如果这个类是第一次被调用,那么实例化Action类放到内存中。\n<pre>initInternal();\ninitOther();\nintiServlet();\ngetServletContext().setAttribute();\ninitModuleConfigFactory();\nModuleConfig moduleConfig = initModuleConfig(\"\",cofing);\ninitModuleMessageResources(moduleConfig);\ninitModuleDataSources(moduleConfig);\ninitModulePlugIns(moduleConfig);\nmoduleCofing.freeze();</pre>\n\n### 2,ActionForm\n\nActionForm 提供想要的缓冲、校验、转换机制。本质上是一种JavaBean,是专门用来传递数据的DTO(Data Transfer Object)它用于表单数据验证的validate()方法和用于数据复位的reset()方法。\n\n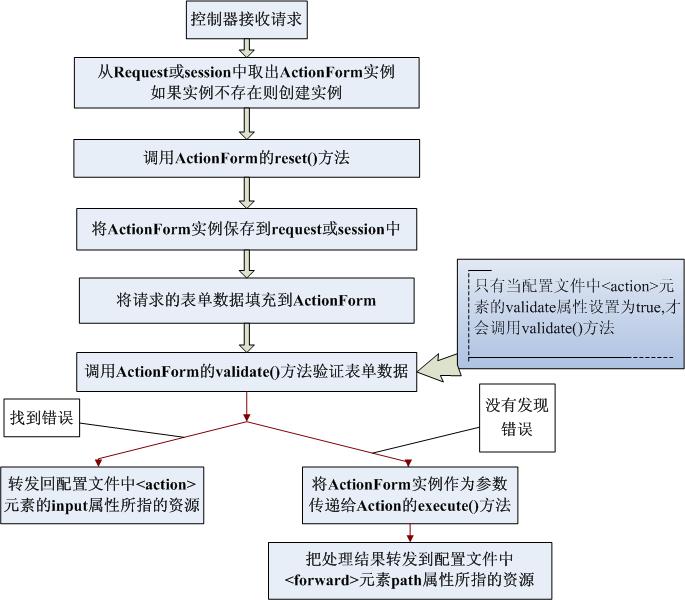\n\nActionForm有请求(request)和会话(session)两种作用域(scope).\n\n在验证ActionForm时,如果检测到一个或多个验证错误,Struts会返回在struts-config.xml中<action>定义的input属性指向的页面。\n\nDynaActionForm的目的就是减少ActionForm的数据,利用它用户不用创建一个个具体的ActionForm类,而在配置文件中配置出所需要的虚拟ActionForm。\n<pre><form-beans>\n<form-bean name=\"loginForm\" type=\"org.apache.struts.action.DynaActionForm\">\n<form-property name=\"actionClass\" type=\"java.lang.String\" />\n<form-property name=\"username\" type=\"java.lang.String\" />\n<form-property name=\"password\" type=\"java.lang.String\" />\n</form-bean> \n</form-beans></pre>\n<pre>String userName = (String) form.get('username');</pre>\n验证的部分后面讲\n\n### 3,ActionForward\n\n基类有四个属性:name, path, redirect, classname. ActionForward控制程序的走向。代表一个程序的URI。\n\n当redirect=false时,将保存存储在http请求和请求的上下文的所有内容,仅在同一个应用中可用。redirect=true是,Web客户端进行一次新的http请求,请求的资源可以在同一个应用中,也可以不在,原来的请求参数不再保存,原来的请求上下文也被消除,新http请求仅包含ActionForward的path属性里所包含的参数。\n\n### 4,ActionMapping\n\n<action-mappings>用来描述一组ActionMapping对象,当中的每一个<action>标签都对应一个ActionMapping对象,当客户端发出请求至RequestProcessor时,请求的URI对应于<action>中的path属性,而要呼吁的Action对象则是type属性所设定的对象,RequestProcessor会将请求的执行工作交给盖Action对象来执行。\n\n### 5,Action\n\n每个Action为客户完成某种操作。一旦正确的Action实例确定,就会调用RequestProcessor类的processActionPerform()方法。负责调用Action实例的execute()方法。\n\nForwardAction 类似于<jsp:forward>,将请求转发到其他的MVC组件,当仅仅是完成从一个页面到另一个页面的请求转发操作是,并不一定需要一个真正的Action,\n<pre><action path=\"/index\" name=\"loginActionForm\" scope=\"request\" tpye=\"org.apache.struts.action.ForwardAction\" parameter=\"/login.jsp\" validate=\"false\" imput=\"/login.jsp\"></action></pre>\nDispatchAction, 在一个Action中完成一组紧密相关的业务操作,从而减少重复性编程,使应用更加便于维护。parameter=method , method 对应于Action的具体方法。\n\nMappingDispatchAction类似于DispatchAction\n\nLookupDispatchAction, 必须重写getKeyMethodMap方法,该方法返回一个Map对象。\n\nIncludeAction,引入页面与ForwardAction类似\n\nSwitchAction,","source":"_posts/struts-components.md","raw":"title: Struts components\ntags:\n - component\n - struts\nid: 70\ncategories:\n - Struts\ndate: 2015-04-23 08:31:23\n---\n\n<table>\n<thead>\n<tr>\n<th>名称</th>\n<th>描述</th>\n</tr>\n</thead>\n<tbody>\n<tr>\n<td>Action</td>\n<td>控制器的一部分,用于模型的交互,执行状态改变或状态查询,以及告诉ActionServlet下一个选择的视图。</td>\n</tr>\n<tr>\n<td>ActionForm</td>\n<td>状态改变的数据</td>\n</tr>\n<tr>\n<td>ActionForward</td>\n<td>用户指向或视图选择</td>\n</tr>\n<tr>\n<td>ActionMapping</td>\n<td>状态改变事件</td>\n</tr>\n<tr>\n<td>ActionServlet</td>\n<td>控制器,接收用户请求或状态改变,以及发出视图选择</td>\n</tr>\n</tbody>\n</table>\n\n### 1,ActionServlet\n\nActionServlet的功能是将一个用户端的URI映射到一个相应的Action类,如果这个类是第一次被调用,那么实例化Action类放到内存中。\n<pre>initInternal();\ninitOther();\nintiServlet();\ngetServletContext().setAttribute();\ninitModuleConfigFactory();\nModuleConfig moduleConfig = initModuleConfig(\"\",cofing);\ninitModuleMessageResources(moduleConfig);\ninitModuleDataSources(moduleConfig);\ninitModulePlugIns(moduleConfig);\nmoduleCofing.freeze();</pre>\n\n### 2,ActionForm\n\nActionForm 提供想要的缓冲、校验、转换机制。本质上是一种JavaBean,是专门用来传递数据的DTO(Data Transfer Object)它用于表单数据验证的validate()方法和用于数据复位的reset()方法。\n\n\n\nActionForm有请求(request)和会话(session)两种作用域(scope).\n\n在验证ActionForm时,如果检测到一个或多个验证错误,Struts会返回在struts-config.xml中<action>定义的input属性指向的页面。\n\nDynaActionForm的目的就是减少ActionForm的数据,利用它用户不用创建一个个具体的ActionForm类,而在配置文件中配置出所需要的虚拟ActionForm。\n<pre><form-beans>\n<form-bean name=\"loginForm\" type=\"org.apache.struts.action.DynaActionForm\">\n<form-property name=\"actionClass\" type=\"java.lang.String\" />\n<form-property name=\"username\" type=\"java.lang.String\" />\n<form-property name=\"password\" type=\"java.lang.String\" />\n</form-bean> \n</form-beans></pre>\n<pre>String userName = (String) form.get('username');</pre>\n验证的部分后面讲\n\n### 3,ActionForward\n\n基类有四个属性:name, path, redirect, classname. ActionForward控制程序的走向。代表一个程序的URI。\n\n当redirect=false时,将保存存储在http请求和请求的上下文的所有内容,仅在同一个应用中可用。redirect=true是,Web客户端进行一次新的http请求,请求的资源可以在同一个应用中,也可以不在,原来的请求参数不再保存,原来的请求上下文也被消除,新http请求仅包含ActionForward的path属性里所包含的参数。\n\n### 4,ActionMapping\n\n<action-mappings>用来描述一组ActionMapping对象,当中的每一个<action>标签都对应一个ActionMapping对象,当客户端发出请求至RequestProcessor时,请求的URI对应于<action>中的path属性,而要呼吁的Action对象则是type属性所设定的对象,RequestProcessor会将请求的执行工作交给盖Action对象来执行。\n\n### 5,Action\n\n每个Action为客户完成某种操作。一旦正确的Action实例确定,就会调用RequestProcessor类的processActionPerform()方法。负责调用Action实例的execute()方法。\n\nForwardAction 类似于<jsp:forward>,将请求转发到其他的MVC组件,当仅仅是完成从一个页面到另一个页面的请求转发操作是,并不一定需要一个真正的Action,\n<pre><action path=\"/index\" name=\"loginActionForm\" scope=\"request\" tpye=\"org.apache.struts.action.ForwardAction\" parameter=\"/login.jsp\" validate=\"false\" imput=\"/login.jsp\"></action></pre>\nDispatchAction, 在一个Action中完成一组紧密相关的业务操作,从而减少重复性编程,使应用更加便于维护。parameter=method , method 对应于Action的具体方法。\n\nMappingDispatchAction类似于DispatchAction\n\nLookupDispatchAction, 必须重写getKeyMethodMap方法,该方法返回一个Map对象。\n\nIncludeAction,引入页面与ForwardAction类似\n\nSwitchAction,","slug":"struts-components","published":1,"updated":"2015-12-02T04:39:35.631Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153vv001gc0tjfqn2yaeh"},{"title":"Struts Advanced","id":"112","date":"2015-04-29T23:02:02.000Z","_content":"\n### 1,利用Token解决重复提交\n\n基本原理:服务器在处理到达的请求之前,会将请求中包含的令牌值与保存在当前用户会话中的令牌值进行比较,看是否匹配。在处理完请求后,且在响应发送给客户端之前,将会产生一个新的令牌值,该令牌值除了传给客户端以外,也会将会话中保存的旧的令牌值进行替换。这样如果用户后退到刚才的提交页面并重复提交的话,客户端传过来的令牌就和服务器端的令牌不一致,从而有效的防止了重复提交的发生。\n\n### 2,BeanUtils与PropertyUtils\n\nApache Jakarta Commons项目提供了很多流行的commons组件。\n\nBeanUtils提供了JAVA反射和自省API的包装。其主要目的是利用反射机制对JavaBean的属性进行处理。一个JavaBean通常包含了大量的属性,在很多情况下,对JavaBean的处理会导致大量getset代码堆积。\n\n如果用户有两个具有很多相同属性的JavaBean,一个很常见的现象就是Struts里的PO对象和对应的ActionForm\n\nBeanUtils.copyProperties(admin,adminForm),支持数据类型范围内的转换。\n\nBeanUtils不对这些属性进行处理,需要手动处理。admin.setAttrabuite。\n\nPropertyUtils工具类,提供copyProperties()方法,不支持数据类型转换,速度快。\n\n时间类型要被转化时,使用java.sql.Date,不要使用java.util.Date(不支持)。\n\n#### <span style=\"color:#ff0000;\">使用BeanUtils的成本很高,超过取数据,将其复制到对应的value 对象,以及通过串行化将其返回到远程客户机的时间的总和。不要滥用。</span>\n\n#### 3,Struts的上传和下载\n\nCommons-fileupload组件,struts上传组件。\n\nCommons-fileupload组件:\n\n配置Web.xml文件,action所对应是一个Servlet,而非Struts的action。编辑上传类,FileUploadServlet.java\n\nStruts上传文件组件:\n\n在form中enctpye的值一定要设置为multipart或form-data\n\n配置Struts-config.xml,formbean,action\n\nActionForm Bean中必须第一个名为file的属性,org.apache.struts.upload.FormFile类型。\n\n### 4,Null与“”的区别\n\nString str1 = null; Str 引用为空;没有被分配空间,不是对象;if(str1==null)\n\nString str2 = \"\"; str引用一个空串;分配的空间,是对象;if(str2.equal(\"\"))\n<pre>if(str==null||str.equal(\"\")){\n\n //先判断是不是对象,在判断是不是空字符串\n\n}</pre>\n\n### 5,struts处理中文乱码\n\n* ##### 页面中显示中文乱码\n\n* ##### 传递参数中文乱码\n\n* ##### 国际化资源文件乱码\n1,页面中文乱码\n<pre><% @page language=\"java\" import=\"java.util.\" pageEncoding=\"UTF-8\"%></pre>\n2,传递中文乱码\n\na,Tomcat目录中conf/server.xml中\n<pre><Connector port=\"8080\" protocol=\"HTTP/1.1\" connectionTimeout=\"2000\" redirectPort=\"8443\" URIEncoding=\"UTF-8\"></pre>\nb,添加过滤器Filter\n<pre>public class CharacterEncodingFilter implements Filter{\n public void destroy(){}\n public void doFilter(ServletRequest request, ServletResponse response FilterChain chain) throws Exceptions{\n request.setCharacterEncoding(\"utf-8\");\n chain.doFilter(request,response);\n }\npublic void init(FilterConfig arg0) throws ServletException{}\n}\n\nweb.xml\n<filter>\n<filter-name>characterEncoding</filter-name>\n<filter-class>org.napu.utils.CharacterEncodingFilter</filter-class>\n</filter>\n<filter-mapping>\n<filter-name>characterEncoding</filter-name>\n<url-pattern>/*</url-pattern>\n</filter-mapping>\n过滤的URL为“/*”,表示当前的request请求。</pre>\n3,国际化资源文件乱码\n\nnative2ascii --encoding gbk ApplicationResources_zh.properties bank.properties","source":"_posts/struts-advanced.md","raw":"title: Struts Advanced\ntags:\n - struts\n - Tokens\n - 中文乱码\nid: 112\ncategories:\n - Struts\ndate: 2015-04-30 07:02:02\n---\n\n### 1,利用Token解决重复提交\n\n基本原理:服务器在处理到达的请求之前,会将请求中包含的令牌值与保存在当前用户会话中的令牌值进行比较,看是否匹配。在处理完请求后,且在响应发送给客户端之前,将会产生一个新的令牌值,该令牌值除了传给客户端以外,也会将会话中保存的旧的令牌值进行替换。这样如果用户后退到刚才的提交页面并重复提交的话,客户端传过来的令牌就和服务器端的令牌不一致,从而有效的防止了重复提交的发生。\n\n### 2,BeanUtils与PropertyUtils\n\nApache Jakarta Commons项目提供了很多流行的commons组件。\n\nBeanUtils提供了JAVA反射和自省API的包装。其主要目的是利用反射机制对JavaBean的属性进行处理。一个JavaBean通常包含了大量的属性,在很多情况下,对JavaBean的处理会导致大量getset代码堆积。\n\n如果用户有两个具有很多相同属性的JavaBean,一个很常见的现象就是Struts里的PO对象和对应的ActionForm\n\nBeanUtils.copyProperties(admin,adminForm),支持数据类型范围内的转换。\n\nBeanUtils不对这些属性进行处理,需要手动处理。admin.setAttrabuite。\n\nPropertyUtils工具类,提供copyProperties()方法,不支持数据类型转换,速度快。\n\n时间类型要被转化时,使用java.sql.Date,不要使用java.util.Date(不支持)。\n\n#### <span style=\"color:#ff0000;\">使用BeanUtils的成本很高,超过取数据,将其复制到对应的value 对象,以及通过串行化将其返回到远程客户机的时间的总和。不要滥用。</span>\n\n#### 3,Struts的上传和下载\n\nCommons-fileupload组件,struts上传组件。\n\nCommons-fileupload组件:\n\n配置Web.xml文件,action所对应是一个Servlet,而非Struts的action。编辑上传类,FileUploadServlet.java\n\nStruts上传文件组件:\n\n在form中enctpye的值一定要设置为multipart或form-data\n\n配置Struts-config.xml,formbean,action\n\nActionForm Bean中必须第一个名为file的属性,org.apache.struts.upload.FormFile类型。\n\n### 4,Null与“”的区别\n\nString str1 = null; Str 引用为空;没有被分配空间,不是对象;if(str1==null)\n\nString str2 = \"\"; str引用一个空串;分配的空间,是对象;if(str2.equal(\"\"))\n<pre>if(str==null||str.equal(\"\")){\n\n //先判断是不是对象,在判断是不是空字符串\n\n}</pre>\n\n### 5,struts处理中文乱码\n\n* ##### 页面中显示中文乱码\n\n* ##### 传递参数中文乱码\n\n* ##### 国际化资源文件乱码\n1,页面中文乱码\n<pre><% @page language=\"java\" import=\"java.util.\" pageEncoding=\"UTF-8\"%></pre>\n2,传递中文乱码\n\na,Tomcat目录中conf/server.xml中\n<pre><Connector port=\"8080\" protocol=\"HTTP/1.1\" connectionTimeout=\"2000\" redirectPort=\"8443\" URIEncoding=\"UTF-8\"></pre>\nb,添加过滤器Filter\n<pre>public class CharacterEncodingFilter implements Filter{\n public void destroy(){}\n public void doFilter(ServletRequest request, ServletResponse response FilterChain chain) throws Exceptions{\n request.setCharacterEncoding(\"utf-8\");\n chain.doFilter(request,response);\n }\npublic void init(FilterConfig arg0) throws ServletException{}\n}\n\nweb.xml\n<filter>\n<filter-name>characterEncoding</filter-name>\n<filter-class>org.napu.utils.CharacterEncodingFilter</filter-class>\n</filter>\n<filter-mapping>\n<filter-name>characterEncoding</filter-name>\n<url-pattern>/*</url-pattern>\n</filter-mapping>\n过滤的URL为“/*”,表示当前的request请求。</pre>\n3,国际化资源文件乱码\n\nnative2ascii --encoding gbk ApplicationResources_zh.properties bank.properties","slug":"struts-advanced","published":1,"updated":"2015-12-02T04:39:35.631Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153vy001lc0tjcngee3c5"},{"title":"socket阻塞与非阻塞,同步与异步、I/O模型","id":"178","date":"2015-05-07T20:08:19.000Z","_content":"\n转载:\n\n# <span class=\"link_title\">[socket阻塞与非阻塞,同步与异步、I/O模型](http://blog.csdn.net/hguisu/article/details/7453390)</span>\n\n1\\. 概念理解\n\n 在进行网络编程时,我们常常见到同步(Sync)/异步(Async),阻塞(Block)/非阻塞(Unblock)四种调用方式:\n**同步:**\n所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。**也就是必须一件一件事做**<span lang=\"EN-US\">,</span>等前一件做完了才能做下一件事。\n\n例如普通B/S模式(同步):提交请求->等待服务器处理->处理完毕返回 这个期间客户端浏览器不能干任何事\n\n**异步:**\n异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。\n\n例如 ajax请求(异步)<span lang=\"EN-US\">: </span>请求通过事件触发<span lang=\"EN-US\">-></span>服务器处理(这是浏览器仍然可以作其他事情)<span lang=\"EN-US\">-></span>处理完毕\n\n**阻塞**\n阻塞调用是指调用结果返回之前,当前线程会被挂起(线程进入非可执行状态,在这个状态下,cpu不会给线程分配时间片,即线程暂停运行)。函数只有在得到结果之后才会返回。\n\n有人也许会把阻塞调用和同步调用等同起来,实际上他是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已。 例如,我们在socket中调用recv函数,如果缓冲区中没有数据,这个函数就会一直等待,直到有数据才返回。而此时,当前线程还会继续处理各种各样的消息。\n\n**快递的例子:**比如到你某个时候到A楼一层(假如是内核缓冲区)取快递,但是你不知道快递什么时候过来,你又不能干别的事,只能死等着。但你可以睡觉(进程处于休眠状态),因为你知道快递把货送来时一定会给你打个电话(假定一定能叫醒你)。\n\n**非阻塞**\n非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。\n\n还是等快递的例子:如果用忙轮询的方法,每隔5分钟到A楼一层(内核缓冲区)去看快递来了没有。如果没来,立即返回。而快递来了,就放在A楼一层,等你去取。\n对象的阻塞模式和阻塞函数调用\n对象是否处于阻塞模式和函数是不是阻塞调用有很强的相关性,但是并不是一一对应的。阻塞对象上可以有非阻塞的调用方式,我们可以通过一定的API去轮询状 态,在适当的时候调用阻塞函数,就可以避免阻塞。而对于非阻塞对象,调用特殊的函数也可以进入阻塞调用。函数select就是这样的一个例子。\n\n \n\n1\\. 同步,就是我调用一个功能,该功能没有结束前,我死等结果。\n2\\. 异步,就是我调用一个功能,不需要知道该功能结果,该功能有结果后通知我(回调通知)\n3\\. 阻塞, 就是调用我(函数),我(函数)没有接收完数据或者没有得到结果之前,我不会返回。\n4\\. 非阻塞, 就是调用我(函数),我(函数)立即返回,通过select通知调用者\n\n同步IO和异步IO的区别就在于:数据拷贝的时候进程是否阻塞!\n\n阻塞IO和非阻塞IO的区别就在于:应用程序的调用是否立即返回!\n\n \n\n对于举个简单c/s 模式:\n<div>同步:提交请求->等待服务器处理->处理完毕返回这个期间客户端浏览器不能干任何事\n异步:请求通过事件触发->服务器处理(这是浏览器仍然可以作其他事情)->处理完毕</div>\n<div>同步和异步都只针对于本机SOCKET而言的。</div>\n<div>\n\n同步和异步,阻塞和非阻塞,有些混用,其实它们完全不是一回事,而且它们修饰的对象也不相同。\n阻塞和非阻塞是指当进程访问的数据如果尚未就绪,进程是否需要等待,简单说这相当于函数内部的实现区别,也就是未就绪时是直接返回还是等待就绪;\n\n而同步和异步是指访问数据的机制,同步一般指主动请求并等待I/O操作完毕的方式,当数据就绪后在读写的时候必须阻塞(区别就绪与读写二个阶段,同步的读写必须阻塞),异步则指主动请求数据后便可以继续处理其它任务,随后等待I/O,操作完毕的通知,这可以使进程在数据读写时也不阻塞。(等待\"通知\")\n\nnode.js里面的描述:\n<div class=\"dp-highlighter bg_html\">\n\n1. 线程在执行中如果遇到磁盘读写或网络通信(统称为I/O 操作),通常要耗费较长的时间,这时操作系统会剥夺这个线程的CPU 控制权,使其暂停执行,同时将资源让给其他的工作线程,这种线程调度方式称为 阻塞。当I/O 操作完毕时,操作系统将这个线程的阻塞状态解除,恢复其对CPU的控制权,令其继续执行。这种I/O 模式就是通常的同步式I/O(Synchronous I/O)或阻塞式I/O (Blocking I/O)。\n2. 相应地,异步式I/O (Asynchronous I/O)或非阻塞式I/O (Non-blocking I/O)则针对所有I/O 操作不采用阻塞的策略。当线程遇到I/O 操作时,不会以阻塞的方式等待I/O 操作的完成或数据的返回,而只是将I/O 请求发送给操作系统,继续执行下一条语句。当操作系统完成I/O 操作时,以事件的形式通知执行I/O 操作的线程,线程会在特定时候处理这个事件。为了处理异步I/O,线程必须有事件循环,不断地检查有没有未处理的事件,依次予以处理。阻塞模式下,一个线程只能处理一项任务,要想提高吞吐量必须通过多线程。而非阻塞模式下,一个线程永远在执行计算操作,<span class=\"tag\"><</span><span class=\"tag-name\">span</span> <span class=\"attribute\">style</span>=<span class=\"attribute-value\">\"color:#ff0000;\"</span><span class=\"tag\">></span>这个线程所使用的CPU 核心利用率永远是100%<span class=\"tag\"></</span><span class=\"tag-name\">span</span><span class=\"tag\">></span>,I/O 以事件的方式通知。<span class=\"tag\"><</span><span class=\"tag-name\">span</span> <span class=\"attribute\">style</span>=<span class=\"attribute-value\">\"color:#ff0000;\"</span><span class=\"tag\">></span>在阻塞模式下,多线程往往能提高系统吞吐量,因为一个线程阻塞时还有其他线程在工作,多线程可以让CPU 资源不被阻塞中的线程浪费。<span class=\"tag\"></</span><span class=\"tag-name\">span</span><span class=\"tag\">></span>而在非阻塞模式下,线程不会被I/O 阻塞,永远在利用CPU。多线程带来的好处仅仅是在多核CPU 的情况下利用更多的核,而Node.js的单线程也能带来同样的好处。这就是为什么Node.js 使用了单线程、非阻塞的事件编程模式。\n</div>\n</div>\n\n## <a name=\"t1\"></a>\n\n2\\. Linux下的五种I/O模型\n\n<div>\n\n1)阻塞I/O(blocking I/O)\n2)非阻塞I/O (nonblocking I/O)\n3) I/O复用(select 和poll) (I/O multiplexing)\n4)信号驱动I/O (signal driven I/O (SIGIO))\n5)异步I/O (asynchronous I/O (the POSIX aio_functions))\n\n前四种都是同步,只有最后一种才是异步IO。\n\n#### <a name=\"t2\"></a>**阻塞I/O模型:**\n\n简介:进程会一直阻塞,直到数据拷贝完成\n\n应用程序调用一个IO函数,导致应用程序阻塞,等待数据准备好。 如果数据没有准备好,一直等待….数据准备好了,从内核拷贝到用户空间,IO函数返回成功指示。\n\n我们 第一次接触到的网络编程都是从 listen()、send()、recv()等接口开始的。使用这些接口可以很方便的构建服务器 /客户机的模型。\n\n**阻塞I/O模型图:**在调用recv()/recvfrom()函数时,发生在内核中等待数据和复制数据的过程。\n\n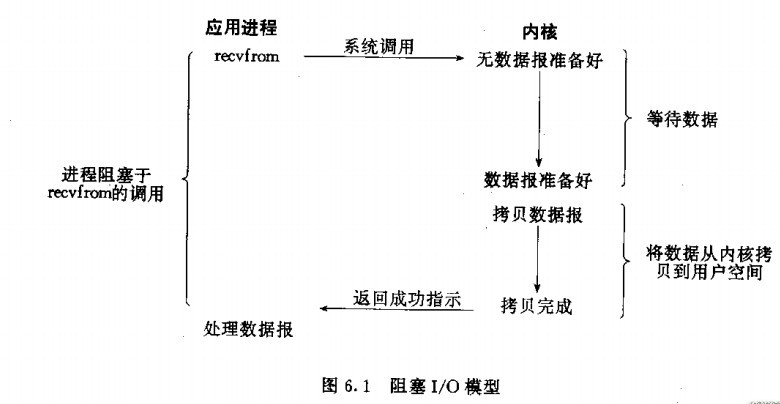\n\n当调用recv()函数时,系统首先查是否有准备好的数据。如果数据没有准备好,那么系统就处于等待状态。当数据准备好后,将数据从**系统缓冲区**复制到用户空间,然后该函数返回。在套接应用程序中,当调用recv()函数时,未必用户空间就已经存在数据,那么此时recv()函数就会处于等待状态。\n\n当使用socket()函数和WSASocket()函数创建套接字时,默认的套接字都是阻塞的。这意味着当调用Windows Sockets API不能立即完成时,线程处于等待状态,直到操作完成。\n\n并不是所有Windows Sockets API以阻塞套接字为参数调用都会发生阻塞。例如,以阻塞模式的套接字为参数调用bind()、listen()函数时,函数会立即返回。将可能阻塞套接字的Windows Sockets API调用分为以下四种:\n\n1.输入操作: recv()、recvfrom()、WSARecv()和WSARecvfrom()函数。以阻塞套接字为参数调用该函数接收数据。如果此时套接字缓冲区内没有数据可读,则调用线程在数据到来前一直睡眠。\n\n2.输出操作: send()、sendto()、WSASend()和WSASendto()函数。以阻塞套接字为参数调用该函数发送数据。如果套接字缓冲区没有可用空间,线程会一直睡眠,直到有空间。\n\n3.接受连接:accept()和WSAAcept()函数。以阻塞套接字为参数调用该函数,等待接受对方的连接请求。如果此时没有连接请求,线程就会进入睡眠状态。\n\n4.外出连接:connect()和WSAConnect()函数。对于TCP连接,客户端以阻塞套接字为参数,调用该函数向服务器发起连接。该函数在收到服务器的应答前,不会返回。这意味着TCP连接总会等待至少到服务器的一次往返时间。\n\n使用阻塞模式的套接字,开发网络程序比较简单,容易实现。当希望能够立即发送和接收数据,且处理的套接字数量比较少的情况下,使用阻塞模式来开发网络程序比较合适。\n\n阻塞模式套接字的不足表现为,在大量建立好的套接字线程之间进行通信时比较困难。当使用“生产者-消费者”模型开发网络程序时,为每个套接字都分别分配一个读线程、一个处理数据线程和一个用于同步的事件,那么这样无疑加大系统的开销。其最大的缺点是当希望同时处理大量套接字时,将无从下手,其扩展性很差.\n\n阻塞模式给网络编程带来了一个很大的问题,如在调用 send()的同时,线程将被阻塞,在此期间,线程将无法执行任何运算或响应任何的网络请求。这给多客户机、多业务逻辑的网络编程带来了挑战。这时,我们可能会选择多线程的方式来解决这个问题。\n\n应对多客户机的网络应用,最简单的解决方式是在服务器端使用多线程(或多进程)。多线程(或多进程)的目的是让每个连接都拥有独立的线程(或进程),这样任何一个连接的阻塞都不会影响其他的连接。\n\n具体使用多进程还是多线程,并没有一个特定的模式。传统意义上,进程的开销要远远大于线程,所以,如果需要同时为较多的客户机提供服务,则不推荐使用多进程;如果单个服务执行体需要消耗较多的 <span id=\"dc52mg8ruzd1_6\" class=\"dc52mg8ruzd1\">CPU</span> 资源,譬如需要进行大规模或长时间的数据运算或文件访问,则进程较为安全。通常,使用 pthread_create () 创建新线程,<span id=\"dc52mg8ruzd1_3\" class=\"dc52mg8ruzd1\">fork</span>() 创建新进程。\n\n多线程/进程服务器同时为多个客户机提供应答服务。模型如下:\n\n\n\n主线程持续等待客户端的连接请求,如果有连接,则创建新线程,并在新线程中提供为前例同样的问答服务。\n\n上述多线程的服务器模型似乎完美的解决了为多个客户机提供问答服务的要求,但其实并不尽然。如果要同时响应成百上千路的连接请求,则无论多线程还是多进程都会严重占据系统资源,降低系统对外界响应效率,而线程与进程本身也更容易进入假死状态。\n\n由此可能会考虑使用“**线程池**”或“**连接池**”。“线程池”旨在减少创建和销毁线程的频率,其维持一定合理数量的线程,并让空闲的线程重新承担新的执行任务。“连接池”维持连接的缓存池,尽量重用已有的连接、减少创建和关闭连接的频率。这两种技术都可以很好的降低系统开销,都被广泛应用很多大型系统,如apache,mysql数据库等。\n\n但是,“线程池”和“连接池”技术也只是在一定程度上缓解了频繁调用 IO 接口带来的资源占用。而且,所谓“池”始终有其上限,当请求大大超过上限时,“池”构成的系统对外界的响应并不比没有池的时候效果好多少。所以使用“池”必须考虑其面临的响应规模,并根据响应规模调整“池”的大小。\n\n对应上例中的所面临的可能同时出现的上千甚至上万次的客户端请求,“线程池”或“连接池”或许可以缓解部分压力,但是不能解决所有问题。\n\n#### <a name=\"t3\"></a>**非阻塞IO模型** :\n\n</div>\n<div> 简介:非阻塞IO通过进程反复调用IO函数(多次系统调用,并马上返回);在数据拷贝的过程中,进程是阻塞的;</div>\n \n\n我们把一个SOCKET接口设置为非阻塞就是告诉内核,当所请求的I/O操作无法完成时,**不要将进程睡眠**,而是返回一个错误。这样我们的I/O操作函数将不断的测试数据是否已经准备好,如果没有准备好,继续测试,直到数据准备好为止。在这个不断测试的过程中,会大量的占用CPU的时间。\n\n把SOCKET设置为非阻塞模式,即通知系统内核:在调用Windows Sockets API时,不要让线程睡眠,而应该让函数立即返回。在返回时,该函数返回一个错误代码。图所示,一个非阻塞模式套接字多次调用recv()函数的过程。前三次调用recv()函数时,内核数据还没有准备好。因此,该函数立即返回WSAEWOULDBLOCK错误代码。第四次调用recv()函数时,数据已经准备好,被复制到应用程序的缓冲区中,recv()函数返回成功指示,应用程序开始处理数据。\n\n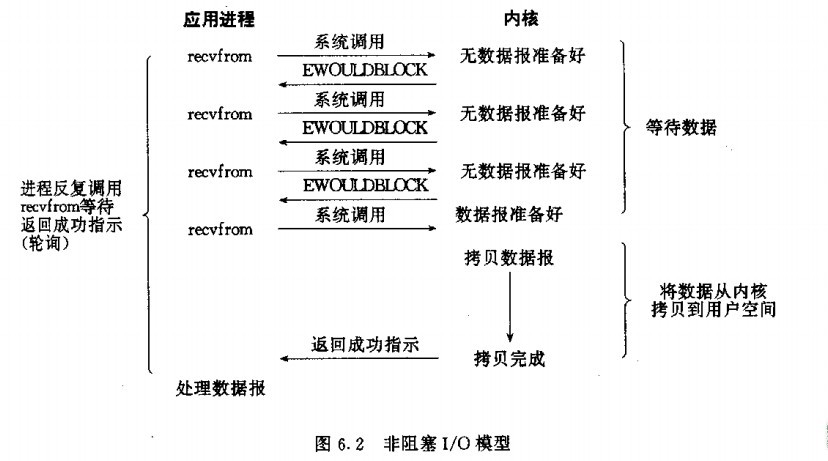\n\n当使用socket()函数和WSASocket()函数创建套接字时,默认都是阻塞的。在创建套接字之后,通过调用ioctlsocket()函数,将该套接字设置为非阻塞模式。Linux下的函数是:fcntl().\n套接字设置为非阻塞模式后,在调用Windows Sockets API函数时,调用函数会立即返回。大多数情况下,这些函数调用都会调用“失败”,并返回WSAEWOULDBLOCK错误代码。说明请求的操作在调用期间内没有时间完成。通常,应用程序需要重复调用该函数,直到获得成功返回代码。\n\n需要说明的是并非所有的Windows Sockets API在非阻塞模式下调用,都会返回WSAEWOULDBLOCK错误。例如,以非阻塞模式的套接字为参数调用bind()函数时,就不会返回该错误代码。当然,在调用WSAStartup()函数时更不会返回该错误代码,因为该函数是应用程序第一调用的函数,当然不会返回这样的错误代码。\n\n要将套接字设置为非阻塞模式,除了使用ioctlsocket()函数之外,还可以使用WSAAsyncselect()和WSAEventselect()函数。当调用该函数时,套接字会自动地设置为非阻塞方式。\n\n由于使用非阻塞套接字在调用函数时,会经常返回WSAEWOULDBLOCK错误。所以在任何时候,都应仔细检查返回代码并作好对“失败”的准备。应用程序连续不断地调用这个函数,直到它返回成功指示为止。上面的程序清单中,在While循环体内不断地调用recv()函数,以读入1024个字节的数据。这种做法很浪费系统资源。\n\n要完成这样的操作,有人使用MSG_PEEK标志调用recv()函数查看缓冲区中是否有数据可读。同样,这种方法也不好。因为该做法对系统造成的开销是很大的,并且应用程序至少要调用recv()函数两次,才能实际地读入数据。较好的做法是,使用套接字的“I/O模型”来判断非阻塞套接字是否可读可写。\n\n非阻塞模式套接字与阻塞模式套接字相比,不容易使用。使用非阻塞模式套接字,需要编写更多的代码,以便在每个Windows Sockets API函数调用中,对收到的WSAEWOULDBLOCK错误进行处理。因此,非阻塞套接字便显得有些难于使用。\n\n但是,非阻塞套接字在控制建立的多个连接,在数据的收发量不均,时间不定时,明显具有优势。这种套接字在使用上存在一定难度,但只要排除了这些困难,它在功能上还是非常强大的。通常情况下,可考虑使用套接字的“I/O模型”,它有助于应用程序通过异步方式,同时对一个或多个套接字的通信加以管理。\n\n \n\n### <a name=\"t4\"></a>**IO复用模型:**\n\n简介:主要是select和epoll;对一个IO端口,两次调用,两次返回,比阻塞IO并没有什么优越性;关键是能实现同时对多个IO端口进行监听;\n\nI/O复用模型会用到select、poll、epoll函数,这几个函数也会使进程阻塞,但是和阻塞I/O所不同的的,这两个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。\n\n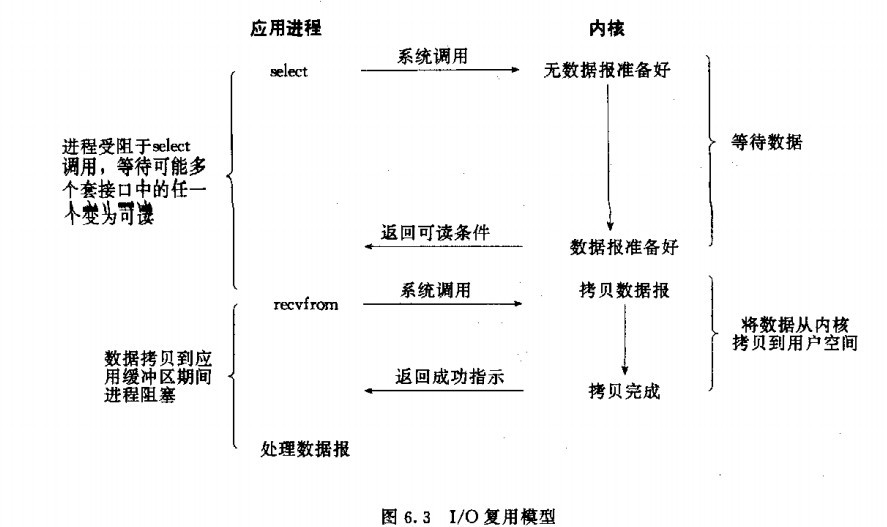\n\n### <a name=\"t5\"></a>**信号驱动IO**\n\n简介:两次调用,两次返回;\n\n首先我们允许套接口进行信号驱动I/O,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。\n\n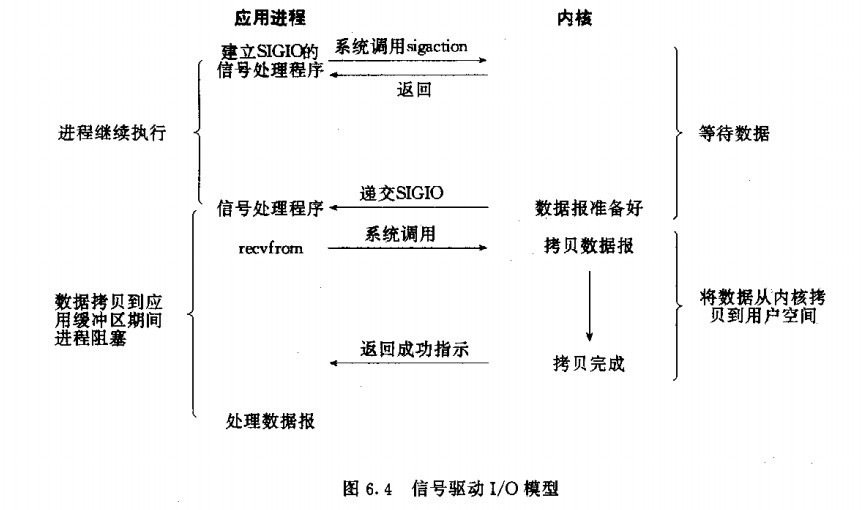\n\n### <a name=\"t6\"></a>**异步IO模型**\n\n简介:数据拷贝的时候进程无需阻塞。\n\n** **当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者的输入输出操作\n\n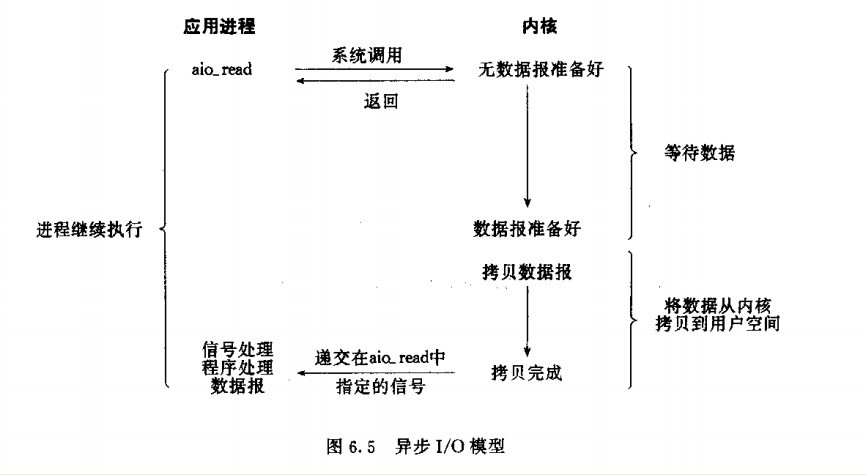\n\n同步IO引起进程阻塞,直至IO操作完成。\n异步IO不会引起进程阻塞。\nIO复用是先通过select调用阻塞。\n\n### <a name=\"t7\"></a>**5个I/O模型的比较:**\n\n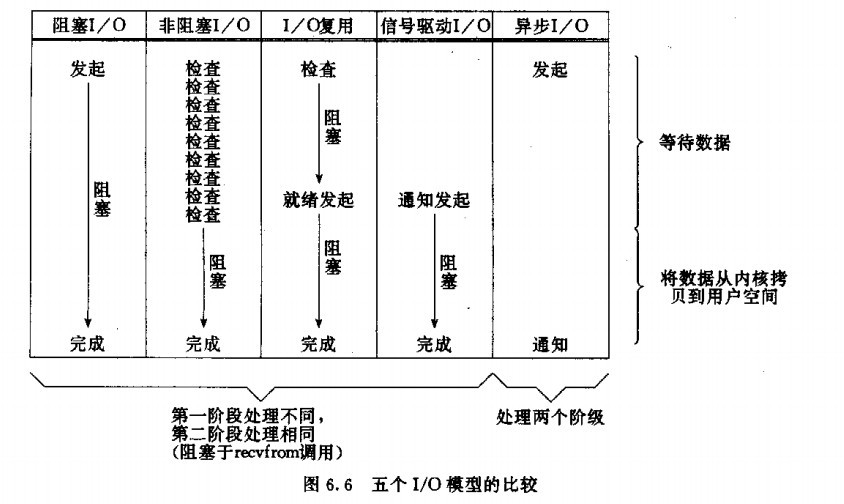\n\n## <a name=\"t8\"></a>\n\n3\\. select、poll、epoll简介\n\nepoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现\n\n**select:**\n\nselect本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是:\n\n1、 单个进程可监视的fd数量被限制,即能监听端口的大小有限。\n\n一般来说这个数目和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048.\n\n2、 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低:\n\n当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。\n\n3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大\n\n**poll:**\n\npoll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。\n\n它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:\n\n1、大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。 2、poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。\n\n**epoll:**\n\nepoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就需态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知\n\nepoll的优点:\n<div>**1、没有最大并发连接的限制,**能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);\n**2、效率提升**,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;\n即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。</div>\n<div>**3、 内存拷贝**,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。\n\n**select、poll、epoll 区别总结:**</div>\n1、支持一个进程所能打开的最大连接数\n<table border=\"1\" cellspacing=\"0\" cellpadding=\"0\">\n<tbody>\n<tr>\n<td width=\"111\">select</td>\n<td width=\"457\">单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是32*32,同理64位机器上FD_SETSIZE为32*64),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。</td>\n</tr>\n<tr>\n<td width=\"111\">poll</td>\n<td width=\"457\">poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的</td>\n</tr>\n<tr>\n<td width=\"111\">epoll</td>\n<td width=\"457\">虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接</td>\n</tr>\n</tbody>\n</table>\n2、FD剧增后带来的IO效率问题\n<table border=\"1\" cellspacing=\"0\" cellpadding=\"0\">\n<tbody>\n<tr>\n<td width=\"111\">select</td>\n<td width=\"457\">因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。</td>\n</tr>\n<tr>\n<td width=\"111\">poll</td>\n<td width=\"457\">同上</td>\n</tr>\n<tr>\n<td width=\"111\">epoll</td>\n<td width=\"457\">因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。</td>\n</tr>\n</tbody>\n</table>\n3、 消息传递方式\n<table border=\"1\" cellspacing=\"0\" cellpadding=\"0\">\n<tbody>\n<tr>\n<td width=\"111\">select</td>\n<td width=\"457\">内核需要将消息传递到用户空间,都需要内核拷贝动作</td>\n</tr>\n<tr>\n<td width=\"111\">poll</td>\n<td width=\"457\">同上</td>\n</tr>\n<tr>\n<td width=\"111\">epoll</td>\n<td width=\"457\">epoll通过内核和用户空间共享一块内存来实现的。</td>\n</tr>\n</tbody>\n</table>\n**总结:**\n\n综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。\n\n1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。\n\n2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善","source":"_posts/socket blocking noblocking IO model.md","raw":"title: socket阻塞与非阻塞,同步与异步、I/O模型\nid: 178\ncategories:\n - socket\ndate: 2015-05-08 04:08:19\ntags:\n---\n\n转载:\n\n# <span class=\"link_title\">[socket阻塞与非阻塞,同步与异步、I/O模型](http://blog.csdn.net/hguisu/article/details/7453390)</span>\n\n1\\. 概念理解\n\n 在进行网络编程时,我们常常见到同步(Sync)/异步(Async),阻塞(Block)/非阻塞(Unblock)四种调用方式:\n**同步:**\n所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。**也就是必须一件一件事做**<span lang=\"EN-US\">,</span>等前一件做完了才能做下一件事。\n\n例如普通B/S模式(同步):提交请求->等待服务器处理->处理完毕返回 这个期间客户端浏览器不能干任何事\n\n**异步:**\n异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。\n\n例如 ajax请求(异步)<span lang=\"EN-US\">: </span>请求通过事件触发<span lang=\"EN-US\">-></span>服务器处理(这是浏览器仍然可以作其他事情)<span lang=\"EN-US\">-></span>处理完毕\n\n**阻塞**\n阻塞调用是指调用结果返回之前,当前线程会被挂起(线程进入非可执行状态,在这个状态下,cpu不会给线程分配时间片,即线程暂停运行)。函数只有在得到结果之后才会返回。\n\n有人也许会把阻塞调用和同步调用等同起来,实际上他是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已。 例如,我们在socket中调用recv函数,如果缓冲区中没有数据,这个函数就会一直等待,直到有数据才返回。而此时,当前线程还会继续处理各种各样的消息。\n\n**快递的例子:**比如到你某个时候到A楼一层(假如是内核缓冲区)取快递,但是你不知道快递什么时候过来,你又不能干别的事,只能死等着。但你可以睡觉(进程处于休眠状态),因为你知道快递把货送来时一定会给你打个电话(假定一定能叫醒你)。\n\n**非阻塞**\n非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。\n\n还是等快递的例子:如果用忙轮询的方法,每隔5分钟到A楼一层(内核缓冲区)去看快递来了没有。如果没来,立即返回。而快递来了,就放在A楼一层,等你去取。\n对象的阻塞模式和阻塞函数调用\n对象是否处于阻塞模式和函数是不是阻塞调用有很强的相关性,但是并不是一一对应的。阻塞对象上可以有非阻塞的调用方式,我们可以通过一定的API去轮询状 态,在适当的时候调用阻塞函数,就可以避免阻塞。而对于非阻塞对象,调用特殊的函数也可以进入阻塞调用。函数select就是这样的一个例子。\n\n \n\n1\\. 同步,就是我调用一个功能,该功能没有结束前,我死等结果。\n2\\. 异步,就是我调用一个功能,不需要知道该功能结果,该功能有结果后通知我(回调通知)\n3\\. 阻塞, 就是调用我(函数),我(函数)没有接收完数据或者没有得到结果之前,我不会返回。\n4\\. 非阻塞, 就是调用我(函数),我(函数)立即返回,通过select通知调用者\n\n同步IO和异步IO的区别就在于:数据拷贝的时候进程是否阻塞!\n\n阻塞IO和非阻塞IO的区别就在于:应用程序的调用是否立即返回!\n\n \n\n对于举个简单c/s 模式:\n<div>同步:提交请求->等待服务器处理->处理完毕返回这个期间客户端浏览器不能干任何事\n异步:请求通过事件触发->服务器处理(这是浏览器仍然可以作其他事情)->处理完毕</div>\n<div>同步和异步都只针对于本机SOCKET而言的。</div>\n<div>\n\n同步和异步,阻塞和非阻塞,有些混用,其实它们完全不是一回事,而且它们修饰的对象也不相同。\n阻塞和非阻塞是指当进程访问的数据如果尚未就绪,进程是否需要等待,简单说这相当于函数内部的实现区别,也就是未就绪时是直接返回还是等待就绪;\n\n而同步和异步是指访问数据的机制,同步一般指主动请求并等待I/O操作完毕的方式,当数据就绪后在读写的时候必须阻塞(区别就绪与读写二个阶段,同步的读写必须阻塞),异步则指主动请求数据后便可以继续处理其它任务,随后等待I/O,操作完毕的通知,这可以使进程在数据读写时也不阻塞。(等待\"通知\")\n\nnode.js里面的描述:\n<div class=\"dp-highlighter bg_html\">\n\n1. 线程在执行中如果遇到磁盘读写或网络通信(统称为I/O 操作),通常要耗费较长的时间,这时操作系统会剥夺这个线程的CPU 控制权,使其暂停执行,同时将资源让给其他的工作线程,这种线程调度方式称为 阻塞。当I/O 操作完毕时,操作系统将这个线程的阻塞状态解除,恢复其对CPU的控制权,令其继续执行。这种I/O 模式就是通常的同步式I/O(Synchronous I/O)或阻塞式I/O (Blocking I/O)。\n2. 相应地,异步式I/O (Asynchronous I/O)或非阻塞式I/O (Non-blocking I/O)则针对所有I/O 操作不采用阻塞的策略。当线程遇到I/O 操作时,不会以阻塞的方式等待I/O 操作的完成或数据的返回,而只是将I/O 请求发送给操作系统,继续执行下一条语句。当操作系统完成I/O 操作时,以事件的形式通知执行I/O 操作的线程,线程会在特定时候处理这个事件。为了处理异步I/O,线程必须有事件循环,不断地检查有没有未处理的事件,依次予以处理。阻塞模式下,一个线程只能处理一项任务,要想提高吞吐量必须通过多线程。而非阻塞模式下,一个线程永远在执行计算操作,<span class=\"tag\"><</span><span class=\"tag-name\">span</span> <span class=\"attribute\">style</span>=<span class=\"attribute-value\">\"color:#ff0000;\"</span><span class=\"tag\">></span>这个线程所使用的CPU 核心利用率永远是100%<span class=\"tag\"></</span><span class=\"tag-name\">span</span><span class=\"tag\">></span>,I/O 以事件的方式通知。<span class=\"tag\"><</span><span class=\"tag-name\">span</span> <span class=\"attribute\">style</span>=<span class=\"attribute-value\">\"color:#ff0000;\"</span><span class=\"tag\">></span>在阻塞模式下,多线程往往能提高系统吞吐量,因为一个线程阻塞时还有其他线程在工作,多线程可以让CPU 资源不被阻塞中的线程浪费。<span class=\"tag\"></</span><span class=\"tag-name\">span</span><span class=\"tag\">></span>而在非阻塞模式下,线程不会被I/O 阻塞,永远在利用CPU。多线程带来的好处仅仅是在多核CPU 的情况下利用更多的核,而Node.js的单线程也能带来同样的好处。这就是为什么Node.js 使用了单线程、非阻塞的事件编程模式。\n</div>\n</div>\n\n## <a name=\"t1\"></a>\n\n2\\. Linux下的五种I/O模型\n\n<div>\n\n1)阻塞I/O(blocking I/O)\n2)非阻塞I/O (nonblocking I/O)\n3) I/O复用(select 和poll) (I/O multiplexing)\n4)信号驱动I/O (signal driven I/O (SIGIO))\n5)异步I/O (asynchronous I/O (the POSIX aio_functions))\n\n前四种都是同步,只有最后一种才是异步IO。\n\n#### <a name=\"t2\"></a>**阻塞I/O模型:**\n\n简介:进程会一直阻塞,直到数据拷贝完成\n\n应用程序调用一个IO函数,导致应用程序阻塞,等待数据准备好。 如果数据没有准备好,一直等待….数据准备好了,从内核拷贝到用户空间,IO函数返回成功指示。\n\n我们 第一次接触到的网络编程都是从 listen()、send()、recv()等接口开始的。使用这些接口可以很方便的构建服务器 /客户机的模型。\n\n**阻塞I/O模型图:**在调用recv()/recvfrom()函数时,发生在内核中等待数据和复制数据的过程。\n\n\n\n当调用recv()函数时,系统首先查是否有准备好的数据。如果数据没有准备好,那么系统就处于等待状态。当数据准备好后,将数据从**系统缓冲区**复制到用户空间,然后该函数返回。在套接应用程序中,当调用recv()函数时,未必用户空间就已经存在数据,那么此时recv()函数就会处于等待状态。\n\n当使用socket()函数和WSASocket()函数创建套接字时,默认的套接字都是阻塞的。这意味着当调用Windows Sockets API不能立即完成时,线程处于等待状态,直到操作完成。\n\n并不是所有Windows Sockets API以阻塞套接字为参数调用都会发生阻塞。例如,以阻塞模式的套接字为参数调用bind()、listen()函数时,函数会立即返回。将可能阻塞套接字的Windows Sockets API调用分为以下四种:\n\n1.输入操作: recv()、recvfrom()、WSARecv()和WSARecvfrom()函数。以阻塞套接字为参数调用该函数接收数据。如果此时套接字缓冲区内没有数据可读,则调用线程在数据到来前一直睡眠。\n\n2.输出操作: send()、sendto()、WSASend()和WSASendto()函数。以阻塞套接字为参数调用该函数发送数据。如果套接字缓冲区没有可用空间,线程会一直睡眠,直到有空间。\n\n3.接受连接:accept()和WSAAcept()函数。以阻塞套接字为参数调用该函数,等待接受对方的连接请求。如果此时没有连接请求,线程就会进入睡眠状态。\n\n4.外出连接:connect()和WSAConnect()函数。对于TCP连接,客户端以阻塞套接字为参数,调用该函数向服务器发起连接。该函数在收到服务器的应答前,不会返回。这意味着TCP连接总会等待至少到服务器的一次往返时间。\n\n使用阻塞模式的套接字,开发网络程序比较简单,容易实现。当希望能够立即发送和接收数据,且处理的套接字数量比较少的情况下,使用阻塞模式来开发网络程序比较合适。\n\n阻塞模式套接字的不足表现为,在大量建立好的套接字线程之间进行通信时比较困难。当使用“生产者-消费者”模型开发网络程序时,为每个套接字都分别分配一个读线程、一个处理数据线程和一个用于同步的事件,那么这样无疑加大系统的开销。其最大的缺点是当希望同时处理大量套接字时,将无从下手,其扩展性很差.\n\n阻塞模式给网络编程带来了一个很大的问题,如在调用 send()的同时,线程将被阻塞,在此期间,线程将无法执行任何运算或响应任何的网络请求。这给多客户机、多业务逻辑的网络编程带来了挑战。这时,我们可能会选择多线程的方式来解决这个问题。\n\n应对多客户机的网络应用,最简单的解决方式是在服务器端使用多线程(或多进程)。多线程(或多进程)的目的是让每个连接都拥有独立的线程(或进程),这样任何一个连接的阻塞都不会影响其他的连接。\n\n具体使用多进程还是多线程,并没有一个特定的模式。传统意义上,进程的开销要远远大于线程,所以,如果需要同时为较多的客户机提供服务,则不推荐使用多进程;如果单个服务执行体需要消耗较多的 <span id=\"dc52mg8ruzd1_6\" class=\"dc52mg8ruzd1\">CPU</span> 资源,譬如需要进行大规模或长时间的数据运算或文件访问,则进程较为安全。通常,使用 pthread_create () 创建新线程,<span id=\"dc52mg8ruzd1_3\" class=\"dc52mg8ruzd1\">fork</span>() 创建新进程。\n\n多线程/进程服务器同时为多个客户机提供应答服务。模型如下:\n\n\n\n主线程持续等待客户端的连接请求,如果有连接,则创建新线程,并在新线程中提供为前例同样的问答服务。\n\n上述多线程的服务器模型似乎完美的解决了为多个客户机提供问答服务的要求,但其实并不尽然。如果要同时响应成百上千路的连接请求,则无论多线程还是多进程都会严重占据系统资源,降低系统对外界响应效率,而线程与进程本身也更容易进入假死状态。\n\n由此可能会考虑使用“**线程池**”或“**连接池**”。“线程池”旨在减少创建和销毁线程的频率,其维持一定合理数量的线程,并让空闲的线程重新承担新的执行任务。“连接池”维持连接的缓存池,尽量重用已有的连接、减少创建和关闭连接的频率。这两种技术都可以很好的降低系统开销,都被广泛应用很多大型系统,如apache,mysql数据库等。\n\n但是,“线程池”和“连接池”技术也只是在一定程度上缓解了频繁调用 IO 接口带来的资源占用。而且,所谓“池”始终有其上限,当请求大大超过上限时,“池”构成的系统对外界的响应并不比没有池的时候效果好多少。所以使用“池”必须考虑其面临的响应规模,并根据响应规模调整“池”的大小。\n\n对应上例中的所面临的可能同时出现的上千甚至上万次的客户端请求,“线程池”或“连接池”或许可以缓解部分压力,但是不能解决所有问题。\n\n#### <a name=\"t3\"></a>**非阻塞IO模型** :\n\n</div>\n<div> 简介:非阻塞IO通过进程反复调用IO函数(多次系统调用,并马上返回);在数据拷贝的过程中,进程是阻塞的;</div>\n \n\n我们把一个SOCKET接口设置为非阻塞就是告诉内核,当所请求的I/O操作无法完成时,**不要将进程睡眠**,而是返回一个错误。这样我们的I/O操作函数将不断的测试数据是否已经准备好,如果没有准备好,继续测试,直到数据准备好为止。在这个不断测试的过程中,会大量的占用CPU的时间。\n\n把SOCKET设置为非阻塞模式,即通知系统内核:在调用Windows Sockets API时,不要让线程睡眠,而应该让函数立即返回。在返回时,该函数返回一个错误代码。图所示,一个非阻塞模式套接字多次调用recv()函数的过程。前三次调用recv()函数时,内核数据还没有准备好。因此,该函数立即返回WSAEWOULDBLOCK错误代码。第四次调用recv()函数时,数据已经准备好,被复制到应用程序的缓冲区中,recv()函数返回成功指示,应用程序开始处理数据。\n\n\n\n当使用socket()函数和WSASocket()函数创建套接字时,默认都是阻塞的。在创建套接字之后,通过调用ioctlsocket()函数,将该套接字设置为非阻塞模式。Linux下的函数是:fcntl().\n套接字设置为非阻塞模式后,在调用Windows Sockets API函数时,调用函数会立即返回。大多数情况下,这些函数调用都会调用“失败”,并返回WSAEWOULDBLOCK错误代码。说明请求的操作在调用期间内没有时间完成。通常,应用程序需要重复调用该函数,直到获得成功返回代码。\n\n需要说明的是并非所有的Windows Sockets API在非阻塞模式下调用,都会返回WSAEWOULDBLOCK错误。例如,以非阻塞模式的套接字为参数调用bind()函数时,就不会返回该错误代码。当然,在调用WSAStartup()函数时更不会返回该错误代码,因为该函数是应用程序第一调用的函数,当然不会返回这样的错误代码。\n\n要将套接字设置为非阻塞模式,除了使用ioctlsocket()函数之外,还可以使用WSAAsyncselect()和WSAEventselect()函数。当调用该函数时,套接字会自动地设置为非阻塞方式。\n\n由于使用非阻塞套接字在调用函数时,会经常返回WSAEWOULDBLOCK错误。所以在任何时候,都应仔细检查返回代码并作好对“失败”的准备。应用程序连续不断地调用这个函数,直到它返回成功指示为止。上面的程序清单中,在While循环体内不断地调用recv()函数,以读入1024个字节的数据。这种做法很浪费系统资源。\n\n要完成这样的操作,有人使用MSG_PEEK标志调用recv()函数查看缓冲区中是否有数据可读。同样,这种方法也不好。因为该做法对系统造成的开销是很大的,并且应用程序至少要调用recv()函数两次,才能实际地读入数据。较好的做法是,使用套接字的“I/O模型”来判断非阻塞套接字是否可读可写。\n\n非阻塞模式套接字与阻塞模式套接字相比,不容易使用。使用非阻塞模式套接字,需要编写更多的代码,以便在每个Windows Sockets API函数调用中,对收到的WSAEWOULDBLOCK错误进行处理。因此,非阻塞套接字便显得有些难于使用。\n\n但是,非阻塞套接字在控制建立的多个连接,在数据的收发量不均,时间不定时,明显具有优势。这种套接字在使用上存在一定难度,但只要排除了这些困难,它在功能上还是非常强大的。通常情况下,可考虑使用套接字的“I/O模型”,它有助于应用程序通过异步方式,同时对一个或多个套接字的通信加以管理。\n\n \n\n### <a name=\"t4\"></a>**IO复用模型:**\n\n简介:主要是select和epoll;对一个IO端口,两次调用,两次返回,比阻塞IO并没有什么优越性;关键是能实现同时对多个IO端口进行监听;\n\nI/O复用模型会用到select、poll、epoll函数,这几个函数也会使进程阻塞,但是和阻塞I/O所不同的的,这两个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。\n\n\n\n### <a name=\"t5\"></a>**信号驱动IO**\n\n简介:两次调用,两次返回;\n\n首先我们允许套接口进行信号驱动I/O,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。\n\n\n\n### <a name=\"t6\"></a>**异步IO模型**\n\n简介:数据拷贝的时候进程无需阻塞。\n\n** **当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者的输入输出操作\n\n\n\n同步IO引起进程阻塞,直至IO操作完成。\n异步IO不会引起进程阻塞。\nIO复用是先通过select调用阻塞。\n\n### <a name=\"t7\"></a>**5个I/O模型的比较:**\n\n\n\n## <a name=\"t8\"></a>\n\n3\\. select、poll、epoll简介\n\nepoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现\n\n**select:**\n\nselect本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是:\n\n1、 单个进程可监视的fd数量被限制,即能监听端口的大小有限。\n\n一般来说这个数目和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048.\n\n2、 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低:\n\n当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。\n\n3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大\n\n**poll:**\n\npoll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。\n\n它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:\n\n1、大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。 2、poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。\n\n**epoll:**\n\nepoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就需态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知\n\nepoll的优点:\n<div>**1、没有最大并发连接的限制,**能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);\n**2、效率提升**,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;\n即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。</div>\n<div>**3、 内存拷贝**,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。\n\n**select、poll、epoll 区别总结:**</div>\n1、支持一个进程所能打开的最大连接数\n<table border=\"1\" cellspacing=\"0\" cellpadding=\"0\">\n<tbody>\n<tr>\n<td width=\"111\">select</td>\n<td width=\"457\">单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是32*32,同理64位机器上FD_SETSIZE为32*64),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。</td>\n</tr>\n<tr>\n<td width=\"111\">poll</td>\n<td width=\"457\">poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的</td>\n</tr>\n<tr>\n<td width=\"111\">epoll</td>\n<td width=\"457\">虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接</td>\n</tr>\n</tbody>\n</table>\n2、FD剧增后带来的IO效率问题\n<table border=\"1\" cellspacing=\"0\" cellpadding=\"0\">\n<tbody>\n<tr>\n<td width=\"111\">select</td>\n<td width=\"457\">因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。</td>\n</tr>\n<tr>\n<td width=\"111\">poll</td>\n<td width=\"457\">同上</td>\n</tr>\n<tr>\n<td width=\"111\">epoll</td>\n<td width=\"457\">因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。</td>\n</tr>\n</tbody>\n</table>\n3、 消息传递方式\n<table border=\"1\" cellspacing=\"0\" cellpadding=\"0\">\n<tbody>\n<tr>\n<td width=\"111\">select</td>\n<td width=\"457\">内核需要将消息传递到用户空间,都需要内核拷贝动作</td>\n</tr>\n<tr>\n<td width=\"111\">poll</td>\n<td width=\"457\">同上</td>\n</tr>\n<tr>\n<td width=\"111\">epoll</td>\n<td width=\"457\">epoll通过内核和用户空间共享一块内存来实现的。</td>\n</tr>\n</tbody>\n</table>\n**总结:**\n\n综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。\n\n1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。\n\n2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善","slug":"socket blocking noblocking IO model","published":1,"updated":"2015-12-02T04:39:35.631Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153w2001sc0tj0onkw57r"},{"title":"Python Scrapy+MongoDB","id":"85","date":"2015-04-26T09:12:11.000Z","_content":"\n用户想用一个Python程序从StackOverflow抓取数据,获取新的问题(问题标题和URL),抓取的数据应当存入MongoDB。\n\n在开始抓取工作前,一定要先查看该网站的使用/服务条款,要尊重robots.txt文件。抓取行为应当遵守道德,不要在很短的时间内发起大量请求,从而导致网站遭受泛洪攻击。\n\n本文安装运行环境:windows 7 Enterprise 64bit\n\n安装:\n\n[Scrapy](http://scrapy.org/),[PyMongo ](https://api.mongodb.org/python/current/),[MongoDB](https://www.mongodb.org/),[Pywin32](http://sourceforge.net/projects/pywin32/files/pywin32/)\n<pre>pip install Scrapy\npip install pymongo\nscrapy startproject stack\nProblem:NO module name service_identity\nsolution:pip install service_identity</pre>\n[Github](https://github.com/zhaohuizhang/ScrapySpider)","source":"_posts/python-scrapymongodb.md","raw":"title: Python Scrapy+MongoDB\ntags:\n - crawler\n - mongodb\n - Scrapy\nid: 85\ncategories:\n - Python\ndate: 2015-04-26 17:12:11\n---\n\n用户想用一个Python程序从StackOverflow抓取数据,获取新的问题(问题标题和URL),抓取的数据应当存入MongoDB。\n\n在开始抓取工作前,一定要先查看该网站的使用/服务条款,要尊重robots.txt文件。抓取行为应当遵守道德,不要在很短的时间内发起大量请求,从而导致网站遭受泛洪攻击。\n\n本文安装运行环境:windows 7 Enterprise 64bit\n\n安装:\n\n[Scrapy](http://scrapy.org/),[PyMongo ](https://api.mongodb.org/python/current/),[MongoDB](https://www.mongodb.org/),[Pywin32](http://sourceforge.net/projects/pywin32/files/pywin32/)\n<pre>pip install Scrapy\npip install pymongo\nscrapy startproject stack\nProblem:NO module name service_identity\nsolution:pip install service_identity</pre>\n[Github](https://github.com/zhaohuizhang/ScrapySpider)","slug":"python-scrapymongodb","published":1,"updated":"2015-12-02T04:39:35.630Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153w5001vc0tjxs9cp28z"},{"title":"python scrapy","id":"7","date":"2015-04-14T05:41:23.000Z","_content":"\n# [python网络爬虫入门](http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=206006839&idx=1&sn=568201291c68761da6cf873c1a7c5ef4&scene=1&key=2e5b2e802b7041cff91e825029c4e8dffd7e57e0850ce3f6ceddf95fa83fc9ef1a791f79976a57d5d12b17ba4373880d&ascene=1&uin=NTQ2NzM3NjAw&devicetype=webwx&version=70000001&pass_ticket=JB%2FEpXYFNKiCkydl90TMnZcFgfueNnKbRfxBhEiBP5NJ5bt3KKdkREjW664WzO%2Fs \"python网络爬虫入门\")\n\n## **学习要求**\n\n1. 基本的爬虫工作原理;\n2. 基本的http抓取工具,scrapy\n3. Bloom Filter: Bloom\n4. 分布式爬虫:[python-rq](https://github.com/nvie/rq)\n5. rq和Scrapy的结合:[scrapy-redis](https://github.com/darkrho/scrapy-redis)\n6. 后续处理,网页分析:[python-goose](https://github.com/grangier/python-goose)\n\n### 爬虫的工作原理\n\n以人民日报为例:http://www.renminribao.com\n\n基本流程如下:伪代码\n<pre>import Queue\n\ninitial_page = \"http://www.renminribao.com\"\nurl_open = Queue.Queue()\nseen = set()\nseen.insert(initial_page)\nurl_queue.put(initial_page)\n\nwhile(True):\n if url_queue.size()>0:\n current_url = url_queue.get()\n store(current_url)\n for next_url in extract_urls(current_url):\n if next_url not in seen:\n seen.put(next_url)\n url_queue.put(next_url)\n else:\n break</pre>\n\n### 效率\n\nN个网络链接,判重的复杂度N*log(N),python的set实现是hash,太慢\n\n通常的判重,Bloom Filter。它是一种hash的方法,但是它的特点是,它可以使用固定的内存(不随URL的数量而增长)以O(1)的效率判定URL是否已经在set中。[实例](http://billmill.org/bloomfilter-tutorial/)\n\n### 集群化抓取\n\nslave master模式,url_queue 放到master上,所有的slave都可以通过网络跟master通信,每当一个slave完成下载一个网页,就向master请求一个新的网页来抓取,每次slave新抓取到一个网页,就把这个网页上所有链接送到master的queue里去。同样,bloom filter也放到master上,但是master只发送确定没有被访问过的URL给slave。Bloom Filter放到master的内存里,而被访问过的URL放到master上的Redis里,这样保证所有操作都是O(1),[LINSERT – Redis](http://redis.io/documentation)\n\n在各个slave上装好scrapy,在master装好Redis和rq作为分布式队列。\n<pre>#slave.py\ncurrent_url = request_from_master()\nto_send = []\nfor next_url in extract_urls(current_url):\n to_send.append(next_url)\nstore(current_url)\nsend_to_master(to_send)\n\n#master.py\n\ndistributed_queue = DistributedQueue()\nbf = BloomFilter()\n\ninitial_pages = 'www.renminribao.com'\n\nwhile(True):\n if request == 'GET'\n if distributed_queue.size()>0:\n send(distributed_queue.get())\n else:\n break\n elif request == 'POST'\n bf.put(request.url)</pre>\n已经有现成的例子:[<span class=\"author\">arkrho</span><span class=\"path-divider\">/</span>**scrapy-redis**](https://github.com/darkrho/scrapy-redis)\n\n### 展望及后处理\n\n1,有效地存储(数据库应该怎样安排)\n\n2,有效的判重(网页内容判重)\n\n3,有效的信息提取(抽取有用信息)\n\n4,及时更新(预测网页多久更新一次)","source":"_posts/python scrapy.md","raw":"title: python scrapy\nid: 7\ntags:\n - python\n - srcapy\ncategories:\n - Python\ndate: 2015-04-14 13:41:23\n\n---\n\n# [python网络爬虫入门](http://mp.weixin.qq.com/s?__biz=MzA4MjEyNTA5Mw==&mid=206006839&idx=1&sn=568201291c68761da6cf873c1a7c5ef4&scene=1&key=2e5b2e802b7041cff91e825029c4e8dffd7e57e0850ce3f6ceddf95fa83fc9ef1a791f79976a57d5d12b17ba4373880d&ascene=1&uin=NTQ2NzM3NjAw&devicetype=webwx&version=70000001&pass_ticket=JB%2FEpXYFNKiCkydl90TMnZcFgfueNnKbRfxBhEiBP5NJ5bt3KKdkREjW664WzO%2Fs \"python网络爬虫入门\")\n\n## **学习要求**\n\n1. 基本的爬虫工作原理;\n2. 基本的http抓取工具,scrapy\n3. Bloom Filter: Bloom\n4. 分布式爬虫:[python-rq](https://github.com/nvie/rq)\n5. rq和Scrapy的结合:[scrapy-redis](https://github.com/darkrho/scrapy-redis)\n6. 后续处理,网页分析:[python-goose](https://github.com/grangier/python-goose)\n\n### 爬虫的工作原理\n\n以人民日报为例:http://www.renminribao.com\n\n基本流程如下:伪代码\n<pre>import Queue\n\ninitial_page = \"http://www.renminribao.com\"\nurl_open = Queue.Queue()\nseen = set()\nseen.insert(initial_page)\nurl_queue.put(initial_page)\n\nwhile(True):\n if url_queue.size()>0:\n current_url = url_queue.get()\n store(current_url)\n for next_url in extract_urls(current_url):\n if next_url not in seen:\n seen.put(next_url)\n url_queue.put(next_url)\n else:\n break</pre>\n\n### 效率\n\nN个网络链接,判重的复杂度N*log(N),python的set实现是hash,太慢\n\n通常的判重,Bloom Filter。它是一种hash的方法,但是它的特点是,它可以使用固定的内存(不随URL的数量而增长)以O(1)的效率判定URL是否已经在set中。[实例](http://billmill.org/bloomfilter-tutorial/)\n\n### 集群化抓取\n\nslave master模式,url_queue 放到master上,所有的slave都可以通过网络跟master通信,每当一个slave完成下载一个网页,就向master请求一个新的网页来抓取,每次slave新抓取到一个网页,就把这个网页上所有链接送到master的queue里去。同样,bloom filter也放到master上,但是master只发送确定没有被访问过的URL给slave。Bloom Filter放到master的内存里,而被访问过的URL放到master上的Redis里,这样保证所有操作都是O(1),[LINSERT – Redis](http://redis.io/documentation)\n\n在各个slave上装好scrapy,在master装好Redis和rq作为分布式队列。\n<pre>#slave.py\ncurrent_url = request_from_master()\nto_send = []\nfor next_url in extract_urls(current_url):\n to_send.append(next_url)\nstore(current_url)\nsend_to_master(to_send)\n\n#master.py\n\ndistributed_queue = DistributedQueue()\nbf = BloomFilter()\n\ninitial_pages = 'www.renminribao.com'\n\nwhile(True):\n if request == 'GET'\n if distributed_queue.size()>0:\n send(distributed_queue.get())\n else:\n break\n elif request == 'POST'\n bf.put(request.url)</pre>\n已经有现成的例子:[<span class=\"author\">arkrho</span><span class=\"path-divider\">/</span>**scrapy-redis**](https://github.com/darkrho/scrapy-redis)\n\n### 展望及后处理\n\n1,有效地存储(数据库应该怎样安排)\n\n2,有效的判重(网页内容判重)\n\n3,有效的信息提取(抽取有用信息)\n\n4,及时更新(预测网页多久更新一次)","slug":"python scrapy","published":1,"updated":"2015-12-02T04:39:35.630Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153wc0024c0tjjkwspgan"},{"title":"Producer Consumer Problem","id":"234","date":"2015-06-14T23:44:08.000Z","_content":"\n### 问题描述\n\n假设我们有两个进程或者线程。他们是工厂里一条流水线上的两个车间。其中线程A生产的部件要交给下一个线程B来做进一步的处理。这个时候,线程A就相当于一个生产者,而线程B就相当于一个消费者。在生产者产生了一个不见后,它们会通过一个传送带传递这个部件。也就是说,线程A负责传送带上面放部件,而线程B负责在传送带上面取部件。这样,两个线程在各自运行的时候需要访问同一个资源。\n\n### 解决方法\n\n我们可以将两个线程之间要共同访问的部分定义为一个数组。那么,对于两个线程来说,他们在一定程度上是独立的。一个线程可以向共享资源队列里面放东西,一个线程从里面取东西。对于Producer线程来说,它需要考虑的就是如果我往资源队列里放东西时,队列满了,那么我必须要等待consumer线程取走一部分元素,这样才能继续进行。另外,和其他线程访问同一个资源队列的时候,还要保证访问时线程安全的。同样,对于consumer线程来说,如果资源队列里面是空的,那么就必须等待producer线程将产生的元素放入队列。\n\n我们的问题核心就是在于怎样使得一个线程和另外一个线程互斥的访问同一资源呢?另外,如果一个线程发现目前的资源状况不适合自己,又该怎样停止自己而让其他线程来运行呢?\n\n#### (1)wait notify\n\n在java里面。如果我们希望一个线程在已经占有资源锁的情况下先中止自己的执行并释放锁,那么就需要wait。如果我们已经完成自己那部分的操作,需要释放锁并要其他的线程来继续执行,我们通过调用notify和notifyAll方法来通知其他原因资源被枷锁之后处于阻塞状态的线程。\n\n一个producer的执行过程如下:\n\n1. 如果资源队列满了,则调用wait方法释放锁,一直等待到资源队列有空缺。\n2. 在资源队列里面加入新的元素。\n3. 调用notify和notifyAll方法来唤醒其他等待的线程。\n<pre>import java.util.Date;\nimport java.util.LinkedList;\n\npublic class EventStorage {\n private int maxSize;\n private LinkedList<Date> storage;\n\n public EventStorage() {\n maxSize = 10;\n storage = new LinkedList<>();\n }\n\n public synchronized void set() {\n while(storage.size() == maxSize) {\n try {\n wait();\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n }\n storage.offer(new Date());\n System.out.printf(\"Set: %d\", storage.size());\n notifyAll();\n }\n\n public synchronized void get() {\n while(storage.size() == 0) {\n try {\n wait();\n } catch(InterruptedException e) {\n e.printStackTrace();\n }\n }\n System.out.printf(\"Get: %d: %s\", storage.size(), storage.poll());\n notifyAll();\n }\n}\n\npublic class Consumer implements Runnable {\n\n /**\n * Store to work with\n */\n private EventStorage storage;\n\n /**\n * Constructor of the class. Initialize the storage\n * @param storage The store to work with\n */\n public Consumer(EventStorage storage){\n this.storage=storage;\n }\n\n /**\n * Core method for the consumer. Consume 100 events\n */\n @Override\n public void run() {\n for (int i=0; i<100; i++){\n storage.get();\n }\n }\n\n}\n\npublic class Producer implements Runnable {\n\n /**\n * Store to work with\n */\n private EventStorage storage;\n\n /**\n * Constructor of the class. Initialize the storage.\n * @param storage The store to work with\n */\n public Producer(EventStorage storage){\n this.storage=storage;\n }\n\n /**\n * Core method of the producer. Generates 100 events.\n */\n @Override\n public void run() {\n for (int i=0; i<100; i++){\n storage.set();\n }\n }\n}\n\npublic class Main {\n\n /**\n * Main method of the class. Create and star two initialization tasks\n * and wait for their finish\n * @param args\n */\n public static void main(String[] args) {\n EventStorage storage = new EventStorage();\n\n Producer producer = new Producer(storage);\n Thread thread1 = new Thread(producer);\n\n Consumer consumer = new Consumer(storage);\n Thread thread2 = new Thread(consumer);\n\n thread2.start();\n thread1.start();\n }\n}</pre>\nsynchronized对于线程访问,每次只能有一个线程能够获得这个锁进入这个方法。使用wait方法,能够在获得这个锁的情况下释放锁。\n\n### BlockingQueue\n\nJava中有一些数据结构包含有互斥锁,BlockingQueue定义了一个借口,具体实现包括:ArrayBlockingQueue,LinkedBlockingQueue.\n<pre> import java.util.concurrent.BlockingQueue;\nimport java.util.concurrent.ArrayBlockingQueue;\n\nclass Producer implements Runnable{\n\n private BlockingQueue<Message> queue;\n\n public Producer(BlockingQueue<Message> q){\n\n this.queue = q;\n }\n\n @Override\n public void run(){\n\n for(int i=0; i<100; i++){\n\n Message msg = new Message(\"\"+i);\n try{\n Thread.sleep(i);\n queue.put(msg);\n System.out.println(\"Produced \"+msg.getMsg());\n }catch(InterruptedException e){\n e.printStackTrace();\n }\n }\n\n Message msg = new Message(\"exit\");\n try{\n queue.put(msg);\n }catch(InterruptedExcetpion e){\n e.printStackTrace();\n }\n }\n}\n\nclass Consumer implements Runnable{\n\n private BlockingQueue<Message> queue;\n public Consumer(BlockingQueue<Message> q){\n\n this.queue = q;\n }\n\n @Override\n public void run(){\n\n try{\n Message msg;\n while((msg = queue.take()).getMsg()!=\"exit\"){\n\n Thread.sleep(i);\n System.out.println(\"Consumed \"+msg.getMsg());\n }\n }catch(InterruptedException e){\n e.printStackTrace();\n }\n }\n}\n\npublic class ProducerConsumerService{\n public static void main(String args[]){\n\n BlockingQueue<Message> queue = new ArrayBlockingQueue<>(10);\n Producer producer = new Producer(queue);\n Consumer consumer = new Consumer(queue);\n\n new Thread(producer).start();\n new Thread(consumer).start();\n\n System.out.println(\"Producer and consumer has been started!\");\n }\n\n}</pre>","source":"_posts/producer-consumer-problem.md","raw":"title: Producer Consumer Problem\ntags:\n - concurrent\n - java\n - multiThread\nid: 234\ncategories:\n - Java\ndate: 2015-06-15 07:44:08\n---\n\n### 问题描述\n\n假设我们有两个进程或者线程。他们是工厂里一条流水线上的两个车间。其中线程A生产的部件要交给下一个线程B来做进一步的处理。这个时候,线程A就相当于一个生产者,而线程B就相当于一个消费者。在生产者产生了一个不见后,它们会通过一个传送带传递这个部件。也就是说,线程A负责传送带上面放部件,而线程B负责在传送带上面取部件。这样,两个线程在各自运行的时候需要访问同一个资源。\n\n### 解决方法\n\n我们可以将两个线程之间要共同访问的部分定义为一个数组。那么,对于两个线程来说,他们在一定程度上是独立的。一个线程可以向共享资源队列里面放东西,一个线程从里面取东西。对于Producer线程来说,它需要考虑的就是如果我往资源队列里放东西时,队列满了,那么我必须要等待consumer线程取走一部分元素,这样才能继续进行。另外,和其他线程访问同一个资源队列的时候,还要保证访问时线程安全的。同样,对于consumer线程来说,如果资源队列里面是空的,那么就必须等待producer线程将产生的元素放入队列。\n\n我们的问题核心就是在于怎样使得一个线程和另外一个线程互斥的访问同一资源呢?另外,如果一个线程发现目前的资源状况不适合自己,又该怎样停止自己而让其他线程来运行呢?\n\n#### (1)wait notify\n\n在java里面。如果我们希望一个线程在已经占有资源锁的情况下先中止自己的执行并释放锁,那么就需要wait。如果我们已经完成自己那部分的操作,需要释放锁并要其他的线程来继续执行,我们通过调用notify和notifyAll方法来通知其他原因资源被枷锁之后处于阻塞状态的线程。\n\n一个producer的执行过程如下:\n\n1. 如果资源队列满了,则调用wait方法释放锁,一直等待到资源队列有空缺。\n2. 在资源队列里面加入新的元素。\n3. 调用notify和notifyAll方法来唤醒其他等待的线程。\n<pre>import java.util.Date;\nimport java.util.LinkedList;\n\npublic class EventStorage {\n private int maxSize;\n private LinkedList<Date> storage;\n\n public EventStorage() {\n maxSize = 10;\n storage = new LinkedList<>();\n }\n\n public synchronized void set() {\n while(storage.size() == maxSize) {\n try {\n wait();\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n }\n storage.offer(new Date());\n System.out.printf(\"Set: %d\", storage.size());\n notifyAll();\n }\n\n public synchronized void get() {\n while(storage.size() == 0) {\n try {\n wait();\n } catch(InterruptedException e) {\n e.printStackTrace();\n }\n }\n System.out.printf(\"Get: %d: %s\", storage.size(), storage.poll());\n notifyAll();\n }\n}\n\npublic class Consumer implements Runnable {\n\n /**\n * Store to work with\n */\n private EventStorage storage;\n\n /**\n * Constructor of the class. Initialize the storage\n * @param storage The store to work with\n */\n public Consumer(EventStorage storage){\n this.storage=storage;\n }\n\n /**\n * Core method for the consumer. Consume 100 events\n */\n @Override\n public void run() {\n for (int i=0; i<100; i++){\n storage.get();\n }\n }\n\n}\n\npublic class Producer implements Runnable {\n\n /**\n * Store to work with\n */\n private EventStorage storage;\n\n /**\n * Constructor of the class. Initialize the storage.\n * @param storage The store to work with\n */\n public Producer(EventStorage storage){\n this.storage=storage;\n }\n\n /**\n * Core method of the producer. Generates 100 events.\n */\n @Override\n public void run() {\n for (int i=0; i<100; i++){\n storage.set();\n }\n }\n}\n\npublic class Main {\n\n /**\n * Main method of the class. Create and star two initialization tasks\n * and wait for their finish\n * @param args\n */\n public static void main(String[] args) {\n EventStorage storage = new EventStorage();\n\n Producer producer = new Producer(storage);\n Thread thread1 = new Thread(producer);\n\n Consumer consumer = new Consumer(storage);\n Thread thread2 = new Thread(consumer);\n\n thread2.start();\n thread1.start();\n }\n}</pre>\nsynchronized对于线程访问,每次只能有一个线程能够获得这个锁进入这个方法。使用wait方法,能够在获得这个锁的情况下释放锁。\n\n### BlockingQueue\n\nJava中有一些数据结构包含有互斥锁,BlockingQueue定义了一个借口,具体实现包括:ArrayBlockingQueue,LinkedBlockingQueue.\n<pre> import java.util.concurrent.BlockingQueue;\nimport java.util.concurrent.ArrayBlockingQueue;\n\nclass Producer implements Runnable{\n\n private BlockingQueue<Message> queue;\n\n public Producer(BlockingQueue<Message> q){\n\n this.queue = q;\n }\n\n @Override\n public void run(){\n\n for(int i=0; i<100; i++){\n\n Message msg = new Message(\"\"+i);\n try{\n Thread.sleep(i);\n queue.put(msg);\n System.out.println(\"Produced \"+msg.getMsg());\n }catch(InterruptedException e){\n e.printStackTrace();\n }\n }\n\n Message msg = new Message(\"exit\");\n try{\n queue.put(msg);\n }catch(InterruptedExcetpion e){\n e.printStackTrace();\n }\n }\n}\n\nclass Consumer implements Runnable{\n\n private BlockingQueue<Message> queue;\n public Consumer(BlockingQueue<Message> q){\n\n this.queue = q;\n }\n\n @Override\n public void run(){\n\n try{\n Message msg;\n while((msg = queue.take()).getMsg()!=\"exit\"){\n\n Thread.sleep(i);\n System.out.println(\"Consumed \"+msg.getMsg());\n }\n }catch(InterruptedException e){\n e.printStackTrace();\n }\n }\n}\n\npublic class ProducerConsumerService{\n public static void main(String args[]){\n\n BlockingQueue<Message> queue = new ArrayBlockingQueue<>(10);\n Producer producer = new Producer(queue);\n Consumer consumer = new Consumer(queue);\n\n new Thread(producer).start();\n new Thread(consumer).start();\n\n System.out.println(\"Producer and consumer has been started!\");\n }\n\n}</pre>","slug":"producer-consumer-problem","published":1,"updated":"2015-12-02T04:39:35.630Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153wf002ac0tjpf4la3j1"},{"title":"markdown","date":"2015-11-27T10:12:40.000Z","_content":"\n# [MarkDown](http://www.appinn.com/markdown/)\n","source":"_posts/markdown.md","raw":"title: markdown\ndate: 2015-11-27 18:12:40\ntags: markdown\n---\n\n# [MarkDown](http://www.appinn.com/markdown/)\n","slug":"markdown","published":1,"updated":"2015-12-02T04:39:35.629Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153wk002ic0tjko7nnifq"},{"title":"Java Object Method","id":"200","date":"2015-05-14T00:06:34.000Z","_content":"\nJava.lang.Object\n\njava.lang 包在使用的时候无需显示导入,编译时由编译器自动导入。\n\nObject类是类层次结构的根,Java类所有的类从根本上都是继承于这个类\n\nObject是唯一没有父类的类\n\nObject 类中的方法\n\n\n\n1,getClass\n\npublic final Class<?extends Object> getClass()\n\n返回一个对象的运行时类。该Class对象是由所表示类的static synchronized方法锁定的对象。\n\n2,hashCode\n\npublic int hashCode()\n\n返回该对象的哈希码值。支持该方法是为哈希表提供一些优点,例如:java.util.Hashtable提供的哈希表。\n\n`hashCode` 的常规协定是:\n\n* 在 Java 应用程序执行期间,在同一对象上多次调用 <tt>hashCode</tt> 方法时,必须一致地返回相同的整数,前提是对象上 <tt>equals</tt> 比较中所用的信息没有被修改。从某一应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致。\n* 如果根据 <tt>equals(Object)</tt> 方法,两个对象是相等的,那么在两个对象中的每个对象上调用 `hashCode` 方法都必须生成相同的整数结果。\n* 以下情况_不_ 是必需的:如果根据 [`equals(java.lang.Object)`](/java%20tools/jdk1.5%E5%B8%AE%E5%8A%A9%E6%96%87%E6%A1%A3/java/lang/Object.html#equals(java.lang.Object)) 方法,两个对象不相等,那么在两个对象中的任一对象上调用 <tt>hashCode</tt> 方法必定会生成不同的整数结果。但是,程序员应该知道,为不相等的对象生成不同整数结果可以提高哈希表的性能。\n实际上,由 <tt>Object</tt> 类定义的 hashCode 方法确实会针对不同的对象返回不同的整数。(这一般是通过将该对象的内部地址转换成一个整数来实现的,但是 Java<sup>TM</sup> 编程语言不需要这种实现技巧。)\n\n3,equals\n\npublic boolean equals(Object obj)\n\n判断某个对象是否与当前对象相等。\n\n`equals` 方法在非空对象引用上实现相等关系:\n\n* _自反性_:对于任何非空引用值 `x`,`x.equals(x)` 都应返回 `true`。\n* _对称性_:对于任何非空引用值 `x` 和 `y`,当且仅当 `y.equals(x)` 返回 `true` 时,`x.equals(y)` 才应返回 `true`。\n* _传递性_:对于任何非空引用值 `x`、`y` 和 `z`,如果 `x.equals(y)` 返回 `true`,并且 `y.equals(z)` 返回 `true`,那么 `x.equals(z)` 应返回 `true`。\n* _一致性_:对于任何非空引用值 `x` 和 `y`,多次调用 <tt>x.equals(y)</tt> 始终返回 `true` 或始终返回 `false`,前提是对象上 `equals` 比较中所用的信息没有被修改。\n* 对于任何非空引用值 `x`,`x.equals(null)` 都应返回 `false`。\n`Object` 类的 <tt>equals</tt> 方法实现对象上差别可能性最大的相等关系;即,对于任何非空引用值 `x` 和 `y`,当且仅当 `x` 和 `y` 引用同一个对象时,此方法才返回 `true`(`x == y` 具有值`true`)。\n\n注意:当此方法被重写时,通常有必要重写 <tt>hashCode</tt> 方法,以维护 <tt>hashCode</tt> 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。\n\n<dl><dt>**参数:**</dt><dd>`obj` - 要与之比较的引用对象。</dd><dt>**返回:**</dt><dd>如果此对象与 obj 参数相同,则返回 `true`;否则返回 `false`。</dd></dl>\n\n4,clone\n\nprotected Object clone() throws CloneNotSupportedExcetption\n\n创建并返回此对象的一个副本。\n\n<tt>Object</tt> 类的 <tt>clone</tt> 方法执行特定的克隆操作。首先,如果此对象的类不能实现接口 <tt>Cloneable</tt>,则会抛出 <tt>CloneNotSupportedException</tt>。注意:所有的数组都被视为实现接口<tt>Cloneable</tt>。否则,此方法会创建此对象的类的一个新实例,并像通过分配那样,严格使用此对象相应字段的内容初始化该对象的所有字段;这些字段的内容没有被自我克隆。所以,此方法执行的是该对象的“浅表复制”,而不“深层复制”操作。\n\n<tt>Object</tt> 类本身不实现接口 <tt>Cloneable</tt>,所以在类为 <tt>Object</tt> 的对象上调用 <tt>clone</tt> 方法将会导致在运行时抛出异常。\n\n<dl><dt>**返回:**</dt><dd>此实例的一个克隆。</dd><dt>**抛出:**</dt><dd>`[CloneNotSupportedException](/java%20tools/jdk1.5%E5%B8%AE%E5%8A%A9%E6%96%87%E6%A1%A3/java/lang/CloneNotSupportedException.html \"java.lang 中的类\")` - 如果对象的类不支持 `Cloneable` 接口,则重写 `clone` 方法的子类也会抛出此异常,以指示无法克隆某个实例。</dd></dl>\n\n5,toString\n\npublic String toString()\n\nreturn getClass().getName()+\"@\"+Integer.toHexString(hashCode())\n\n6,notify\n\npublic final void notify()\n\n唤醒在此对象监视器上等待的单个线程。如果所有线程都在此对象上等待,则会选择唤醒其中一个线程。选择是任意性的,并在对实现做出决定时发生。线程通过调用其中一个`wait` 方法,在对象的监视器上等待。\n\n7,notifyAll\n\npublic final void notifAll()\n\n唤醒在此对象监视器上等待的所有线程。线程通过调用其中一个 `wait` 方法,在对象的监视器上等待。\n\n8,finalize\n\nprotected void finalize() throws Throwable\n\n当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。子类重写 `finalize` 方法,以配置系统资源或执行其他清除。\n\n<tt>finalize</tt> 的常规协定是:当 Java<sup>TM</sup> 虚拟机已确定尚未终止的任何线程无法再通过任何方法访问此对象时,将调用此方法,除非由于准备终止的其他某个对象或类的终结操作执行了某个操作。<tt>finalize</tt> 方法可以采取任何操作,其中包括再次使此对象对其他线程可用;不过,<tt>finalize</tt> 的主要目的是在不可撤消地丢弃对象之前执行清除操作。例如,表示输入/输出连接的对象的 finalize 方法可执行显式 I/O 事务,以便在永久丢弃对象之前中断连接。\n\n<tt>Object</tt> 类的 <tt>finalize</tt> 方法执行非特殊性操作;它仅执行一些常规返回。<tt>Object</tt> 的子类可以重写此定义。\n\nJava 编程语言不保证哪个线程将调用某个给定对象的 <tt>finalize</tt> 方法。但可以保证在调用 finalize 时,调用 finalize 的线程将不会持有任何用户可见的同步锁定。如果 finalize 方法抛出未捕获的异常,那么该异常将被忽略,并且该对象的终结操作将终止。\n\n在启用某个对象的 <tt>finalize</tt> 方法后,将不会执行进一步操作,直到 Java 虚拟机再次确定尚未终止的任何线程无法再通过任何方法访问此对象,其中包括由准备终止的其他对象或类执行的可能操作,在执行该操作时,对象可能被丢弃。\n\n对于任何给定对象,Java 虚拟机最多只调用一次 <tt>finalize</tt> 方法。\n\n`finalize` 方法抛出的任何异常都会导致此对象的终结操作停止,但可以通过其他方法忽略它。\n\n<dl><dt>**抛出:**</dt><dd>`[Throwable](/java%20tools/jdk1.5%E5%B8%AE%E5%8A%A9%E6%96%87%E6%A1%A3/java/lang/Throwable.html \"java.lang 中的类\")` - 此方法抛出的 `Exception`</dd><dd></dd></dl>\n\n9,wait\n\npublic final void wait(long time) throws InterruptedException\n\n导致当前的线程等待,直到其他线程调用此对象的 `notify()` 方法或 `notifyAll()` 方法,或者超过指定的时间量。","source":"_posts/java-object-method.md","raw":"title: Java Object Method\nid: 200\ncategories:\n - Java\ndate: 2015-05-14 08:06:34\ntags:\n---\n\nJava.lang.Object\n\njava.lang 包在使用的时候无需显示导入,编译时由编译器自动导入。\n\nObject类是类层次结构的根,Java类所有的类从根本上都是继承于这个类\n\nObject是唯一没有父类的类\n\nObject 类中的方法\n\n\n\n1,getClass\n\npublic final Class<?extends Object> getClass()\n\n返回一个对象的运行时类。该Class对象是由所表示类的static synchronized方法锁定的对象。\n\n2,hashCode\n\npublic int hashCode()\n\n返回该对象的哈希码值。支持该方法是为哈希表提供一些优点,例如:java.util.Hashtable提供的哈希表。\n\n`hashCode` 的常规协定是:\n\n* 在 Java 应用程序执行期间,在同一对象上多次调用 <tt>hashCode</tt> 方法时,必须一致地返回相同的整数,前提是对象上 <tt>equals</tt> 比较中所用的信息没有被修改。从某一应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致。\n* 如果根据 <tt>equals(Object)</tt> 方法,两个对象是相等的,那么在两个对象中的每个对象上调用 `hashCode` 方法都必须生成相同的整数结果。\n* 以下情况_不_ 是必需的:如果根据 [`equals(java.lang.Object)`](/java%20tools/jdk1.5%E5%B8%AE%E5%8A%A9%E6%96%87%E6%A1%A3/java/lang/Object.html#equals(java.lang.Object)) 方法,两个对象不相等,那么在两个对象中的任一对象上调用 <tt>hashCode</tt> 方法必定会生成不同的整数结果。但是,程序员应该知道,为不相等的对象生成不同整数结果可以提高哈希表的性能。\n实际上,由 <tt>Object</tt> 类定义的 hashCode 方法确实会针对不同的对象返回不同的整数。(这一般是通过将该对象的内部地址转换成一个整数来实现的,但是 Java<sup>TM</sup> 编程语言不需要这种实现技巧。)\n\n3,equals\n\npublic boolean equals(Object obj)\n\n判断某个对象是否与当前对象相等。\n\n`equals` 方法在非空对象引用上实现相等关系:\n\n* _自反性_:对于任何非空引用值 `x`,`x.equals(x)` 都应返回 `true`。\n* _对称性_:对于任何非空引用值 `x` 和 `y`,当且仅当 `y.equals(x)` 返回 `true` 时,`x.equals(y)` 才应返回 `true`。\n* _传递性_:对于任何非空引用值 `x`、`y` 和 `z`,如果 `x.equals(y)` 返回 `true`,并且 `y.equals(z)` 返回 `true`,那么 `x.equals(z)` 应返回 `true`。\n* _一致性_:对于任何非空引用值 `x` 和 `y`,多次调用 <tt>x.equals(y)</tt> 始终返回 `true` 或始终返回 `false`,前提是对象上 `equals` 比较中所用的信息没有被修改。\n* 对于任何非空引用值 `x`,`x.equals(null)` 都应返回 `false`。\n`Object` 类的 <tt>equals</tt> 方法实现对象上差别可能性最大的相等关系;即,对于任何非空引用值 `x` 和 `y`,当且仅当 `x` 和 `y` 引用同一个对象时,此方法才返回 `true`(`x == y` 具有值`true`)。\n\n注意:当此方法被重写时,通常有必要重写 <tt>hashCode</tt> 方法,以维护 <tt>hashCode</tt> 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。\n\n<dl><dt>**参数:**</dt><dd>`obj` - 要与之比较的引用对象。</dd><dt>**返回:**</dt><dd>如果此对象与 obj 参数相同,则返回 `true`;否则返回 `false`。</dd></dl>\n\n4,clone\n\nprotected Object clone() throws CloneNotSupportedExcetption\n\n创建并返回此对象的一个副本。\n\n<tt>Object</tt> 类的 <tt>clone</tt> 方法执行特定的克隆操作。首先,如果此对象的类不能实现接口 <tt>Cloneable</tt>,则会抛出 <tt>CloneNotSupportedException</tt>。注意:所有的数组都被视为实现接口<tt>Cloneable</tt>。否则,此方法会创建此对象的类的一个新实例,并像通过分配那样,严格使用此对象相应字段的内容初始化该对象的所有字段;这些字段的内容没有被自我克隆。所以,此方法执行的是该对象的“浅表复制”,而不“深层复制”操作。\n\n<tt>Object</tt> 类本身不实现接口 <tt>Cloneable</tt>,所以在类为 <tt>Object</tt> 的对象上调用 <tt>clone</tt> 方法将会导致在运行时抛出异常。\n\n<dl><dt>**返回:**</dt><dd>此实例的一个克隆。</dd><dt>**抛出:**</dt><dd>`[CloneNotSupportedException](/java%20tools/jdk1.5%E5%B8%AE%E5%8A%A9%E6%96%87%E6%A1%A3/java/lang/CloneNotSupportedException.html \"java.lang 中的类\")` - 如果对象的类不支持 `Cloneable` 接口,则重写 `clone` 方法的子类也会抛出此异常,以指示无法克隆某个实例。</dd></dl>\n\n5,toString\n\npublic String toString()\n\nreturn getClass().getName()+\"@\"+Integer.toHexString(hashCode())\n\n6,notify\n\npublic final void notify()\n\n唤醒在此对象监视器上等待的单个线程。如果所有线程都在此对象上等待,则会选择唤醒其中一个线程。选择是任意性的,并在对实现做出决定时发生。线程通过调用其中一个`wait` 方法,在对象的监视器上等待。\n\n7,notifyAll\n\npublic final void notifAll()\n\n唤醒在此对象监视器上等待的所有线程。线程通过调用其中一个 `wait` 方法,在对象的监视器上等待。\n\n8,finalize\n\nprotected void finalize() throws Throwable\n\n当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。子类重写 `finalize` 方法,以配置系统资源或执行其他清除。\n\n<tt>finalize</tt> 的常规协定是:当 Java<sup>TM</sup> 虚拟机已确定尚未终止的任何线程无法再通过任何方法访问此对象时,将调用此方法,除非由于准备终止的其他某个对象或类的终结操作执行了某个操作。<tt>finalize</tt> 方法可以采取任何操作,其中包括再次使此对象对其他线程可用;不过,<tt>finalize</tt> 的主要目的是在不可撤消地丢弃对象之前执行清除操作。例如,表示输入/输出连接的对象的 finalize 方法可执行显式 I/O 事务,以便在永久丢弃对象之前中断连接。\n\n<tt>Object</tt> 类的 <tt>finalize</tt> 方法执行非特殊性操作;它仅执行一些常规返回。<tt>Object</tt> 的子类可以重写此定义。\n\nJava 编程语言不保证哪个线程将调用某个给定对象的 <tt>finalize</tt> 方法。但可以保证在调用 finalize 时,调用 finalize 的线程将不会持有任何用户可见的同步锁定。如果 finalize 方法抛出未捕获的异常,那么该异常将被忽略,并且该对象的终结操作将终止。\n\n在启用某个对象的 <tt>finalize</tt> 方法后,将不会执行进一步操作,直到 Java 虚拟机再次确定尚未终止的任何线程无法再通过任何方法访问此对象,其中包括由准备终止的其他对象或类执行的可能操作,在执行该操作时,对象可能被丢弃。\n\n对于任何给定对象,Java 虚拟机最多只调用一次 <tt>finalize</tt> 方法。\n\n`finalize` 方法抛出的任何异常都会导致此对象的终结操作停止,但可以通过其他方法忽略它。\n\n<dl><dt>**抛出:**</dt><dd>`[Throwable](/java%20tools/jdk1.5%E5%B8%AE%E5%8A%A9%E6%96%87%E6%A1%A3/java/lang/Throwable.html \"java.lang 中的类\")` - 此方法抛出的 `Exception`</dd><dd></dd></dl>\n\n9,wait\n\npublic final void wait(long time) throws InterruptedException\n\n导致当前的线程等待,直到其他线程调用此对象的 `notify()` 方法或 `notifyAll()` 方法,或者超过指定的时间量。","slug":"java-object-method","published":1,"updated":"2015-12-02T04:39:35.629Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153wo002lc0tj7ebu0pkt"},{"title":"Java Exception","id":"239","date":"2015-06-22T05:36:42.000Z","_content":"\nException控制的目的:用尽可能精简的代码创建大型、可靠的应用程序,同时排除程序里那些不能控制的错误。\n\n准则:\n\n(1) 解决问题并再次调用造成违例的方法。\n(2) 平息事态的发展,并在不重新尝试方法的前提下继续。\n(3) 计算另一些结果,而不是希望方法产生的结果。\n(4) 在当前环境中尽可能解决问题,以及将相同的违例重新“掷”出一个更高级的环境。\n(5) 在当前环境中尽可能解决问题,以及将不同的违例重新“掷”出一个更高级的环境。\n(6) 中止程序执行。\n(7) 简化编码。若违例方案使事情变得更加复杂,那就会令人非常烦恼,不如不用。\n(8) 使自己的库和程序变得更加安全。这既是一种“短期投资”(便于调试),也是一种“长期投资”(改善应用程序的健壮性)。\n\n \n\n1. 打开一个不存在的文件、网络连接中断、数组下标越界、正在加载的类文件丢失等都会引发异常。\n2. Java中的异常类定义了程序中遇到的轻微的错误条件。\n3. Java中的错误类定义了程序中不能恢复的严重错误条件。如内存溢出、类文件格式错误等。这一类错误由Java运行系统处理,不需要我们去处理。\n4. Java程序在执行过程中如出现异常,会自动生成一个异常类对象,该异常对象将被提交给Java运行时系统,这个过程称为抛出(throw)异常。\n5. 当Java运行时系统接收到异常对象时,会寻找能处理这一异常的代码并把当前异常对象交给其处理,这一过程称为捕获(catch)异常。\n6. 如果Java运行时系统找不到可以捕获异常的方法,则运行时系统将终止,相应的Java程序也将退出。\n7. try/catch/finally语句。\n8. 对于RuntimeException,通常不需要我们去捕获,这类异常由Java运行系统自动抛出并自动处理。\n9. 如果父类中的方法抛出多个异常,则子类中的覆盖方法要么抛出相同的异常,要么抛出异常的子类,但不能抛出新的异常(注:构造方法除外)。\n10. 我们可以在方法声明时,声明一个不会抛出的异常,Java编译器就会强迫方法的使用者对异常进行处理。这种方式通常应用于abstract base class和interface中。","source":"_posts/java-exception.md","raw":"title: Java Exception\ntags:\n - Exception\nid: 239\ncategories:\n - Java\ndate: 2015-06-22 13:36:42\n---\n\nException控制的目的:用尽可能精简的代码创建大型、可靠的应用程序,同时排除程序里那些不能控制的错误。\n\n准则:\n\n(1) 解决问题并再次调用造成违例的方法。\n(2) 平息事态的发展,并在不重新尝试方法的前提下继续。\n(3) 计算另一些结果,而不是希望方法产生的结果。\n(4) 在当前环境中尽可能解决问题,以及将相同的违例重新“掷”出一个更高级的环境。\n(5) 在当前环境中尽可能解决问题,以及将不同的违例重新“掷”出一个更高级的环境。\n(6) 中止程序执行。\n(7) 简化编码。若违例方案使事情变得更加复杂,那就会令人非常烦恼,不如不用。\n(8) 使自己的库和程序变得更加安全。这既是一种“短期投资”(便于调试),也是一种“长期投资”(改善应用程序的健壮性)。\n\n \n\n1. 打开一个不存在的文件、网络连接中断、数组下标越界、正在加载的类文件丢失等都会引发异常。\n2. Java中的异常类定义了程序中遇到的轻微的错误条件。\n3. Java中的错误类定义了程序中不能恢复的严重错误条件。如内存溢出、类文件格式错误等。这一类错误由Java运行系统处理,不需要我们去处理。\n4. Java程序在执行过程中如出现异常,会自动生成一个异常类对象,该异常对象将被提交给Java运行时系统,这个过程称为抛出(throw)异常。\n5. 当Java运行时系统接收到异常对象时,会寻找能处理这一异常的代码并把当前异常对象交给其处理,这一过程称为捕获(catch)异常。\n6. 如果Java运行时系统找不到可以捕获异常的方法,则运行时系统将终止,相应的Java程序也将退出。\n7. try/catch/finally语句。\n8. 对于RuntimeException,通常不需要我们去捕获,这类异常由Java运行系统自动抛出并自动处理。\n9. 如果父类中的方法抛出多个异常,则子类中的覆盖方法要么抛出相同的异常,要么抛出异常的子类,但不能抛出新的异常(注:构造方法除外)。\n10. 我们可以在方法声明时,声明一个不会抛出的异常,Java编译器就会强迫方法的使用者对异常进行处理。这种方式通常应用于abstract base class和interface中。","slug":"java-exception","published":1,"updated":"2015-12-02T04:39:35.629Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153wq002nc0tj4aqmiyc1"},{"title":"java-environment","date":"2016-03-15T01:52:10.000Z","_content":"\n# Java环境介绍\n\n## Java语言、JVM和生态系统\nJava编译环境出现于20世纪90年代末,由Java语言和运行时组成。运行时也叫Java虚拟机(Java Virtual Machine, JVM)。\n\n### 1.1 JVM 是什么\nJVM是一个程序,提供了运行Java程序所需要的运行时环境。如果某个硬件和操作系统平台没有响应的JVM,就不能运行Java程序。\n\n提供给JVM运行的程序不是Java语言源码,源码必须转换成一种称为Java字节码的格式。提供给JVM的Java字节码必须是类文件格式,扩展名为'.Class'。\n\nJVM是字节码格式程序的解释器,一次只执行字节码中的一个指令。JVM和用户提供的程序都能派生额外的线程,所以用户提供的程序中可能同时运行着多个不同的函数。\n\nJVM的目的\n> * 包含一个容器,让应用代码运行其中\n> * 较之C/C++,提供了一个安全的执行环境\n> * 代开发者管理内存\n> * 提供了一个跨平台的执行环境\n> * JVM使用运行时信息进行自我管理\n\n## Java和JVM简史\n\n* Java 1.0 (1996年)\n> 这是Java的第一个公开发行版,只包含212个类,分别放在八个包中。Java平台始终关注向后兼容性,所以使用Java 1.0 编写的代码,不用修改或者重新编译,依旧能在新的Java 8中运行。\n* Java 1.1 (1997年)\n> 这一版Java平台是原来的两倍多,并且引入了“内部类”和第一版反射API。\n* Java 1.2 (1998年)\n> 这是Java一个非常重要的版本。这一版Java平台是原先的三倍,并且首次出现了集合API(包括 Set,Map和List)。1.2版增加的新功能过多,SUN不得不把平台重新命名为“Java 2 Platform”。这里的JAVA 2是商标。\n* Java 1.3 (2000年)\n> 这其实是一个维护版本,主要用于修正缺陷,解决稳定性,并提升性能。这一版还引入了HotSpot Java虚拟机。这个虚拟机现在还在使用(不过有大量的修改和改进)。\n* Java 1.4 (2002年)\n> 这也是一个重要的版本,增加了一些重要的功能,例如高性能底层I/O API,处理文本的正则表达式、XML和XSLT库、SSL支持、日志API和加密支持。\n* Java 5 (2004年)\n> 这一版Java的更新幅度很大,对核心语句做了很多改动,引入了泛型、枚举类型、注解、变长参数方法、自动装包和新版for循环。\n* Java 6 (2006年)\n> 这一版也主要是维护和提升性能,引入了编译器API,扩展了注解的用法和试用范围,还提供了绑定,允许脚本语言和Java交互。这一版对JVM和Swing GUI技术进行了缺陷修正和改进。\n* Java 7 (2011年)\n> 这是Oracle公司接管Java后发布的第一个版本,包括语言和平台的对象重要升级。这一版本引入了处理资源的try语句和NIO.2 API,让开发者编写的资源和I/O 处理代码更加安全不易出错。方法句柄API是反射API的替代品,更简单也更安全,而且打开了动态调用(invokedynamic)的大门。\n* Java 8 (2014年)\n> 这是最新版的Java, 变动的幅度是自Java 5以来最大第一次。这一版引入的lambda表达式有望显著提升开发者的效率;集合API也升级了,改用lambda实现,为此,Java的面向对象实现方式也发生了根本性变化。其他重要更新包括:实现运行在JVM中的JavaScript(Nashorn),新的日期和时间支持,以及Java配置。\n\n## Java的生命周期\n整个流程冲Java的源码开始,经过javac程序处理后得到类文件,这个文件中保存的是编译源码后得到的Java字节码。类文件是Java平台能处理的最小功能单位,也是把新代码传给运行中程序的唯一方式。\n","source":"_posts/java-environment.md","raw":"title: java-environment\ndate: 2016-03-15 09:52:10\ntags: Java\n---\n\n# Java环境介绍\n\n## Java语言、JVM和生态系统\nJava编译环境出现于20世纪90年代末,由Java语言和运行时组成。运行时也叫Java虚拟机(Java Virtual Machine, JVM)。\n\n### 1.1 JVM 是什么\nJVM是一个程序,提供了运行Java程序所需要的运行时环境。如果某个硬件和操作系统平台没有响应的JVM,就不能运行Java程序。\n\n提供给JVM运行的程序不是Java语言源码,源码必须转换成一种称为Java字节码的格式。提供给JVM的Java字节码必须是类文件格式,扩展名为'.Class'。\n\nJVM是字节码格式程序的解释器,一次只执行字节码中的一个指令。JVM和用户提供的程序都能派生额外的线程,所以用户提供的程序中可能同时运行着多个不同的函数。\n\nJVM的目的\n> * 包含一个容器,让应用代码运行其中\n> * 较之C/C++,提供了一个安全的执行环境\n> * 代开发者管理内存\n> * 提供了一个跨平台的执行环境\n> * JVM使用运行时信息进行自我管理\n\n## Java和JVM简史\n\n* Java 1.0 (1996年)\n> 这是Java的第一个公开发行版,只包含212个类,分别放在八个包中。Java平台始终关注向后兼容性,所以使用Java 1.0 编写的代码,不用修改或者重新编译,依旧能在新的Java 8中运行。\n* Java 1.1 (1997年)\n> 这一版Java平台是原来的两倍多,并且引入了“内部类”和第一版反射API。\n* Java 1.2 (1998年)\n> 这是Java一个非常重要的版本。这一版Java平台是原先的三倍,并且首次出现了集合API(包括 Set,Map和List)。1.2版增加的新功能过多,SUN不得不把平台重新命名为“Java 2 Platform”。这里的JAVA 2是商标。\n* Java 1.3 (2000年)\n> 这其实是一个维护版本,主要用于修正缺陷,解决稳定性,并提升性能。这一版还引入了HotSpot Java虚拟机。这个虚拟机现在还在使用(不过有大量的修改和改进)。\n* Java 1.4 (2002年)\n> 这也是一个重要的版本,增加了一些重要的功能,例如高性能底层I/O API,处理文本的正则表达式、XML和XSLT库、SSL支持、日志API和加密支持。\n* Java 5 (2004年)\n> 这一版Java的更新幅度很大,对核心语句做了很多改动,引入了泛型、枚举类型、注解、变长参数方法、自动装包和新版for循环。\n* Java 6 (2006年)\n> 这一版也主要是维护和提升性能,引入了编译器API,扩展了注解的用法和试用范围,还提供了绑定,允许脚本语言和Java交互。这一版对JVM和Swing GUI技术进行了缺陷修正和改进。\n* Java 7 (2011年)\n> 这是Oracle公司接管Java后发布的第一个版本,包括语言和平台的对象重要升级。这一版本引入了处理资源的try语句和NIO.2 API,让开发者编写的资源和I/O 处理代码更加安全不易出错。方法句柄API是反射API的替代品,更简单也更安全,而且打开了动态调用(invokedynamic)的大门。\n* Java 8 (2014年)\n> 这是最新版的Java, 变动的幅度是自Java 5以来最大第一次。这一版引入的lambda表达式有望显著提升开发者的效率;集合API也升级了,改用lambda实现,为此,Java的面向对象实现方式也发生了根本性变化。其他重要更新包括:实现运行在JVM中的JavaScript(Nashorn),新的日期和时间支持,以及Java配置。\n\n## Java的生命周期\n整个流程冲Java的源码开始,经过javac程序处理后得到类文件,这个文件中保存的是编译源码后得到的Java字节码。类文件是Java平台能处理的最小功能单位,也是把新代码传给运行中程序的唯一方式。\n","slug":"java-environment","published":1,"updated":"2016-03-15T05:26:32.837Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153wt002rc0tjulh9w1qc"},{"title":"java-I/O-1","date":"2015-11-27T10:26:10.000Z","_content":"\n# Java 的 I/O 演进之路(1)\n\nJava 是 Sun Microsystems 公司在1995年首先发布的编程语言和计算平台。\nJava 之所以能够得到如此广泛的应用,除了摆脱硬件平台的依赖具有“一次编写、到处运行”的平台无关性之外,另一个重要原因是:丰富而强大的类库以及众多第三方开源类库,使得开发Java程序更加简单和便捷。\n \n## 1.1 I/O 基础入门\nJava 1.4 之前的早期版本,Java 对 I/O 的支持并不完整,开发人员在开发高性能I/O程序的时候,会面临一些巨大的挑战和困难,主要问题如下:\n \n* 没有数据缓冲区,I/O性能存在问题;\n* 没有C或者C++中的Channel概念,只有输入和输出流;\n* 同步阻塞式I/O通信(BIO),通常会导致线程被长时间阻塞;\n* 支持的字符集有限,硬件可移植性不好。\n\n### 1.1.1 Linux 网络I/O模型\nLinux的内核将所有外部设备都当成一个文件来操作,对一个文件的操作会调用内核提供的系统命令,返回一个file(fd,文件描述符)。而对一个socket的读写,也会有相应的描述符,成为socketfd,描述符就是一个数字,他指向内核的一个结构体(文件属性,数据区等一些属性)。\n \n根据UNIX网络编程对I/O模型的分类,UNIX提供5种I/O模型,分别如下:\n* 阻塞I/O模型:缺省条件下都是阻塞I/O模型,所有的文件操作都是阻塞的。以套接字接口为例:在进程空间中调用recvfrom,其系统调用制动数据包到达且被复制到应用进程的缓冲区中或者发生错误时才返回,在此期间一直会等待,进程从调用recvfrom开始到它返回的整段时间内都是被阻塞的,因此被称为阻塞I/O。\n* 非阻塞I/O模型:recvfrom从应用层到内核的时候,如果该缓冲区没有数据的话,就直接返回一个EWOULDBLOCK错误,一般都对非阻塞I/O模型进行轮询检查这个状态,看内核是否有数据过来。\n* I/O复用模型:Linux提供select/poll,进程通过将一个或多个fd传递给select或者poll系统调用,阻塞在select操作上,这样select/poll可以帮我们侦测多个fd是否处于就绪状态。select/poll是顺序扫描fd是否就绪,而且支持的fd数量有限,因此它的使用受到了一些制约。Linux还提供了一个epoll系统调用,epoll使用基于事件驱动方式代替顺序扫描,当有fd就绪时,立即回调函数rollback。\n* 信号驱动I/O模型:首先开启套接口信号驱动I/O功能,并通过系统调用sigaction执行一个信号处理函数(此系统调用立即返回,进程继续工作,它是非阻塞的)。当数据准备就绪是,就为该进程生成一个SIGIO信号,通过信号回调通知应用程序调用recvfrom来读取数据,并通知主循环函数处理数据。\n* 异步I/O:告知内核启动某个操作,不让内核在整个操作完成后通知我们。与信号驱动模型区别:喜好驱动I/O由内核通知我们何时可以开始一个I/O操作;异步I/O模型由内核通知我们I/O操作何时已经完成。\n\n### 1.1.2 I/O多路复用技术\n在I/O编程过程中,当需要同时处理多个客户端接入请求时,可以利用多路线程或者I/O多路复用技术来处理。I/O多路复用把多个I/O阻塞复用到同一个select的阻塞上,从而使得系统在单线程的情况下同时处理多个客户端的请求。与传统的多线程/多线程模型比,I/O复用的最大优势是系统开销小,系统不需要创建新的额外的进程或者线程,也不需要维护这些线程或进程的运行,降低了系统的维护工作量,节省了系统资源,I/O多路复用的主要应用场景如下:\n1. 服务器需要同时处理多个处于监听状态或者多个连接状态的套接字;\n2. 服务器需要同时处理都中网络协议的套接字;\n\n目前支持I/O多路复用的系统调用有select, pselect, poll, epoll,在Linux网络编程中,很长一段时间都使用select做轮询和网络事件通知,Linux的新版本用epoll。起改进如下:\n* 一个进程打开的socket描述符(FD)不受限制,仅受限于操作系统的最大文件句柄数。\nselect最大的缺陷就是单个进程所打开的FD是有一定限制的,它由FD_SETSIZE设置,默认是1024.对于那些需要支持上万个TCP链接的大型服务器来说显然是太少了。可以选择修改这个宏然后重新编译内核,不过这会带来网络效率的下降。我们也可以通过选择多进程的方案(传统的Apache方案)解决这个问题,不过虽然在Linux上创建进程的代价比较小,但人就是不可忽视的,另外,进程的数据交换非常麻烦,对于Java由于没有共享内存,需要通过Socket通信或者其他方式进行数据同步,这带来了额外的系能损耗,增加了程序复杂度,所以也不是一种完美的解决方案。epoll并没有这个限制,它所支持的FD上限是操作系统的最大文件句柄数,这个数字远大于1024.cat /proc/sys/fs/file-max,这个值跟系统的内存有关。\n* I/O的效率不会随着FD数目的增加而直线下降\n传统的select/poll另一个知名的弱点就是当你拥有一个很大的socket集合,由于网络延迟时或者链路空闲,任意时刻只有少部分的socket是“活跃”的,但是select/poll每次都是扫描全部集合,导致效率的线性下降。epoll不存在这个问题,它只会对“活跃”的socket进行操作-这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的,那么,只有“活跃”的socket才会主动去调用callback函数,其他idle状态socket则不会。epoll实现了一个伪AIO。\n* 使用mmap加速内核与用户空间的消息传递\n无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存负值就显得非常重要,epoll是通过内核和用户mmap同一块内存实现。\n* epoll 的API更加简单\n","source":"_posts/java-I-O.md","raw":"title: java-I/O-1\ndate: 2015-11-27 18:26:10\ntags: javaIO\n---\n\n# Java 的 I/O 演进之路(1)\n\nJava 是 Sun Microsystems 公司在1995年首先发布的编程语言和计算平台。\nJava 之所以能够得到如此广泛的应用,除了摆脱硬件平台的依赖具有“一次编写、到处运行”的平台无关性之外,另一个重要原因是:丰富而强大的类库以及众多第三方开源类库,使得开发Java程序更加简单和便捷。\n \n## 1.1 I/O 基础入门\nJava 1.4 之前的早期版本,Java 对 I/O 的支持并不完整,开发人员在开发高性能I/O程序的时候,会面临一些巨大的挑战和困难,主要问题如下:\n \n* 没有数据缓冲区,I/O性能存在问题;\n* 没有C或者C++中的Channel概念,只有输入和输出流;\n* 同步阻塞式I/O通信(BIO),通常会导致线程被长时间阻塞;\n* 支持的字符集有限,硬件可移植性不好。\n\n### 1.1.1 Linux 网络I/O模型\nLinux的内核将所有外部设备都当成一个文件来操作,对一个文件的操作会调用内核提供的系统命令,返回一个file(fd,文件描述符)。而对一个socket的读写,也会有相应的描述符,成为socketfd,描述符就是一个数字,他指向内核的一个结构体(文件属性,数据区等一些属性)。\n \n根据UNIX网络编程对I/O模型的分类,UNIX提供5种I/O模型,分别如下:\n* 阻塞I/O模型:缺省条件下都是阻塞I/O模型,所有的文件操作都是阻塞的。以套接字接口为例:在进程空间中调用recvfrom,其系统调用制动数据包到达且被复制到应用进程的缓冲区中或者发生错误时才返回,在此期间一直会等待,进程从调用recvfrom开始到它返回的整段时间内都是被阻塞的,因此被称为阻塞I/O。\n* 非阻塞I/O模型:recvfrom从应用层到内核的时候,如果该缓冲区没有数据的话,就直接返回一个EWOULDBLOCK错误,一般都对非阻塞I/O模型进行轮询检查这个状态,看内核是否有数据过来。\n* I/O复用模型:Linux提供select/poll,进程通过将一个或多个fd传递给select或者poll系统调用,阻塞在select操作上,这样select/poll可以帮我们侦测多个fd是否处于就绪状态。select/poll是顺序扫描fd是否就绪,而且支持的fd数量有限,因此它的使用受到了一些制约。Linux还提供了一个epoll系统调用,epoll使用基于事件驱动方式代替顺序扫描,当有fd就绪时,立即回调函数rollback。\n* 信号驱动I/O模型:首先开启套接口信号驱动I/O功能,并通过系统调用sigaction执行一个信号处理函数(此系统调用立即返回,进程继续工作,它是非阻塞的)。当数据准备就绪是,就为该进程生成一个SIGIO信号,通过信号回调通知应用程序调用recvfrom来读取数据,并通知主循环函数处理数据。\n* 异步I/O:告知内核启动某个操作,不让内核在整个操作完成后通知我们。与信号驱动模型区别:喜好驱动I/O由内核通知我们何时可以开始一个I/O操作;异步I/O模型由内核通知我们I/O操作何时已经完成。\n\n### 1.1.2 I/O多路复用技术\n在I/O编程过程中,当需要同时处理多个客户端接入请求时,可以利用多路线程或者I/O多路复用技术来处理。I/O多路复用把多个I/O阻塞复用到同一个select的阻塞上,从而使得系统在单线程的情况下同时处理多个客户端的请求。与传统的多线程/多线程模型比,I/O复用的最大优势是系统开销小,系统不需要创建新的额外的进程或者线程,也不需要维护这些线程或进程的运行,降低了系统的维护工作量,节省了系统资源,I/O多路复用的主要应用场景如下:\n1. 服务器需要同时处理多个处于监听状态或者多个连接状态的套接字;\n2. 服务器需要同时处理都中网络协议的套接字;\n\n目前支持I/O多路复用的系统调用有select, pselect, poll, epoll,在Linux网络编程中,很长一段时间都使用select做轮询和网络事件通知,Linux的新版本用epoll。起改进如下:\n* 一个进程打开的socket描述符(FD)不受限制,仅受限于操作系统的最大文件句柄数。\nselect最大的缺陷就是单个进程所打开的FD是有一定限制的,它由FD_SETSIZE设置,默认是1024.对于那些需要支持上万个TCP链接的大型服务器来说显然是太少了。可以选择修改这个宏然后重新编译内核,不过这会带来网络效率的下降。我们也可以通过选择多进程的方案(传统的Apache方案)解决这个问题,不过虽然在Linux上创建进程的代价比较小,但人就是不可忽视的,另外,进程的数据交换非常麻烦,对于Java由于没有共享内存,需要通过Socket通信或者其他方式进行数据同步,这带来了额外的系能损耗,增加了程序复杂度,所以也不是一种完美的解决方案。epoll并没有这个限制,它所支持的FD上限是操作系统的最大文件句柄数,这个数字远大于1024.cat /proc/sys/fs/file-max,这个值跟系统的内存有关。\n* I/O的效率不会随着FD数目的增加而直线下降\n传统的select/poll另一个知名的弱点就是当你拥有一个很大的socket集合,由于网络延迟时或者链路空闲,任意时刻只有少部分的socket是“活跃”的,但是select/poll每次都是扫描全部集合,导致效率的线性下降。epoll不存在这个问题,它只会对“活跃”的socket进行操作-这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的,那么,只有“活跃”的socket才会主动去调用callback函数,其他idle状态socket则不会。epoll实现了一个伪AIO。\n* 使用mmap加速内核与用户空间的消息传递\n无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存负值就显得非常重要,epoll是通过内核和用户mmap同一块内存实现。\n* epoll 的API更加简单\n","slug":"java-I-O","published":1,"updated":"2015-12-02T04:39:35.629Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153wv002uc0tjcmxta03d"},{"title":"java-I/O-2","date":"2015-11-30T06:17:03.000Z","_content":"\n## 1.2 Java 的 I/O演进(2)\n在JDK1.4退出JavaNIO 之前,基于Java的所有Socket通信都采用了同步阻塞模式(BIO),这种一请求一应答的通信模型简化了上层的阴功开发,但是在性能和可靠性方面却存在着巨大的瓶颈。因此,在很长一段时间里,大型的应用服务器都采用C或者C++语言开发,因为他们可以直接使用操作系统提供的异步I/O或者AIO能力。当并发访问量增大、响应时间延迟增大之后,采用Java BIO开发的服务端软件只能通过硬件的不断扩容来满足高并发和低延迟。\n \n正是由于Java传统BIO的劣势,才使得Java支持非阻塞I/O的呼声渐高,最终JDK1.4版本中提供了新的NIO类库。\n \n### Java的I/O简史\n2002年发布的JDK1.4时,NIO以JSR-51的身份正是随着JDK发布。它增加了java.nio包,提供了很多进行异步I/O开发的API和类库,主要的接口如下:\n* 进行异步I/O操作的缓冲区ByteBuffer;\n* 进行异步I/O操作的管道Pipe;\n* 进行各种I/O操作(异步或同步)的Channel,包括ServerSocketChannel和SocketChannel;\n* 多种字符集的编码能力和解码能力;\n* 实现非阻塞I/O操作的多路复用器Selector;\n* 基于流行了Perl实现正则表达式类库;\n* 文件通道FileChannel。\n \n新的NIO类库的提供,极大地促进了基于Java的异步非阻塞编程的发展和应用,但是,它依然有不完善的地方,特别是对文件系统的处理能力仍显不足,主要问题如下:\n* 没有统一的文件属性;\n* API能力比较弱,例如目录的级联创建和递归遍历,往往需要自己实现;\n* 底层存储系统的一些高级API无法使用;\n* 所有的文件操作都是同步阻塞调用,不支持异步文件读写操作。\n \n2011年7月28日,JDK1.7 正是发布。它的一个比较大亮点就是将原来的NIO类库进行了升级,被称为NIO2.0,有JSR-203演进而来,它主要提供了如下三个方面的改进。\n* 提供能够批量获取文件属性的API,这些API具有平台无关性,不与特性的文件系统耦合,另外它还提供了标准文件系统的SPI,供各个服务提供商扩展实现;\n* 提供AIO功能,支持基于文件的异步I/O操作和针对网络套接字的异步操作;\n* 完成JSR-51 定义的通道功能,包括对配置和多播数据包的支持等。\n\n","source":"_posts/java-I-O-2.md","raw":"title: java-I/O-2\ndate: 2015-11-30 14:17:03\ntags: JavaIO\n---\n\n## 1.2 Java 的 I/O演进(2)\n在JDK1.4退出JavaNIO 之前,基于Java的所有Socket通信都采用了同步阻塞模式(BIO),这种一请求一应答的通信模型简化了上层的阴功开发,但是在性能和可靠性方面却存在着巨大的瓶颈。因此,在很长一段时间里,大型的应用服务器都采用C或者C++语言开发,因为他们可以直接使用操作系统提供的异步I/O或者AIO能力。当并发访问量增大、响应时间延迟增大之后,采用Java BIO开发的服务端软件只能通过硬件的不断扩容来满足高并发和低延迟。\n \n正是由于Java传统BIO的劣势,才使得Java支持非阻塞I/O的呼声渐高,最终JDK1.4版本中提供了新的NIO类库。\n \n### Java的I/O简史\n2002年发布的JDK1.4时,NIO以JSR-51的身份正是随着JDK发布。它增加了java.nio包,提供了很多进行异步I/O开发的API和类库,主要的接口如下:\n* 进行异步I/O操作的缓冲区ByteBuffer;\n* 进行异步I/O操作的管道Pipe;\n* 进行各种I/O操作(异步或同步)的Channel,包括ServerSocketChannel和SocketChannel;\n* 多种字符集的编码能力和解码能力;\n* 实现非阻塞I/O操作的多路复用器Selector;\n* 基于流行了Perl实现正则表达式类库;\n* 文件通道FileChannel。\n \n新的NIO类库的提供,极大地促进了基于Java的异步非阻塞编程的发展和应用,但是,它依然有不完善的地方,特别是对文件系统的处理能力仍显不足,主要问题如下:\n* 没有统一的文件属性;\n* API能力比较弱,例如目录的级联创建和递归遍历,往往需要自己实现;\n* 底层存储系统的一些高级API无法使用;\n* 所有的文件操作都是同步阻塞调用,不支持异步文件读写操作。\n \n2011年7月28日,JDK1.7 正是发布。它的一个比较大亮点就是将原来的NIO类库进行了升级,被称为NIO2.0,有JSR-203演进而来,它主要提供了如下三个方面的改进。\n* 提供能够批量获取文件属性的API,这些API具有平台无关性,不与特性的文件系统耦合,另外它还提供了标准文件系统的SPI,供各个服务提供商扩展实现;\n* 提供AIO功能,支持基于文件的异步I/O操作和针对网络套接字的异步操作;\n* 完成JSR-51 定义的通道功能,包括对配置和多播数据包的支持等。\n\n","slug":"java-I-O-2","published":1,"updated":"2015-12-02T04:39:35.628Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153wy002xc0tjn6l7ulhg"},{"title":"java 集合类","id":"225","date":"2015-06-10T00:56:44.000Z","_content":"\n[](https://napuzhang.files.wordpress.com/2015/06/qqe59bbee7898720150610153630.png)\n\n \n\n虚线标识“interface”,点线框标识“abstract”类,实线框代表实际的类。\n\n利用iterator()方法,所有集合都能生成一个“反复器”(Iterator)。反复器其实就象一个“枚举”\n(Enumeration),是后者的一个替代物,只是:\n(1) 它采用了一个历史上默认、而且早在OOP 中得到广泛采纳的名字(反复器)。\n(2) 采用了比Enumeration 更短的名字:hasNext()代替了hasMoreElement(),而next()代替了\nnextElement()。\n(3) 添加了一个名为remove()的新方法,可删除由Iterator 生成的上一个元素。所以每次调用next()的时候,只需调用remove()一次。\n\n### Collections\n\n<pre>Method:\n\nBoolean add(Object)\n\nBoolean addAll(Collection)\n\nvoid clear()\n\nBoolean contians(Object)\n\nBoolean containsAll(Collection)\n\nBoolean isEmpty()\n\nIterator iterator()\n\nBoolean remove(Object)\n\nBoolean removeAll(Collection)\n\nBoolean retianAll(Collection)\n\nint size()\n\nObject[] toArray()\n\nObject[] toArray(Object[] a)\n</pre>\n\n### Lists\n\nArrayList:用于替代原先的Vector,允许我们快速的访问元素,但在从列表中删除和添加元素时,速度慢。\n\nLinkedList:提供优化的顺序访问性能,同时可以高效地子列表中部插入和删除操作。但随即访问时,速度慢。\n\n### SETs\n\nSet拥有与Collection完全相同的接口,一个Set只允许每个对象存在一个实例\n\nHashSet:用于除非常小的以外的所有Set。对象也必须定义hashCode()。\n\nArraySet:面向非常小的Set 设计,特别是那些需要频繁创建和删除的。对于小Set,与HashSet 相比,ArraySet 创建和反复所需付出的代价都要小得多。但随着Set 的增大,它的性能也会大打折扣。不需要HashCode()。\n\nTreeSet:由一个“红黑树”后推得到的顺序Set。\n\n### Map\n\nMap(接口) 维持“键-值”对应关系(对),以便通过一个键查找相应的值\n\nHashMap:基于一个散列表实现。针对“键值对”的插入和检索,这种形式具有最稳定的性能。\n\nArrayMap:有一个ArrayList后推得到Map。对反复的顺序提供了精确的控制。面向非常小的Map 设计,特别是那些需要经常创建和删除的。对于非常小的Map,创建和反复所付出的代价要比HashMap 低得多。但在Map 变大以后,性能也会相应地大幅度降低。\n\nTreeMap:在一个“红-黑”树的基础上实现。查看键或者“键-值”对时,它们会按固定的顺序排列(取决于Comparable 或Comparator,稍后即会讲到)。TreeMap 最大的好处就是我们得到的是已排好序的结果。TreeMap 是含有subMap()方法的唯一一种Map,利用它可以返回树的一部分。\n\n选择List:\n\n[](https://napuzhang.files.wordpress.com/2015/06/qqe688aae59bbe20150610162659.png)\n\n \n\n选择Set:\n\n[](https://napuzhang.files.wordpress.com/2015/06/qqe688aae59bbe20150610162829.png)\n\n \n\n选择Map:\n\n[](https://napuzhang.files.wordpress.com/2015/06/qqe688aae59bbe20150610162957.png)\n\n \n\n(1) 数组包含了对象的数字化索引。它容纳的是一种已知类型的对象,所以在查找一个对象时,不必对结果进行造型处理。数组可以是多维的,而且能够容纳基本数据类型。但是,一旦把它创建好以后,大小便不能变化了。\n(2) Vector(矢量)也包含了对象的数字索引——可将数组和Vector 想象成随机访问集合。当我们加入更多的元素时,Vector 能够自动改变自身的大小。但Vector 只能容纳对象的句柄,所以它不可包含基本数据类型;而且将一个对象句柄从集合中取出来的时候,必须对结果进行造型处理。\n(3) Hashtable(散列表)属于Dictionary(字典)的一种类型,是一种将对象(而不是数字)同其他对象关联到一起的方式。散列表也支持对对象的随机访问,事实上,它的整个设计方案都在突出访问的“高速度”。\n(4) Stack(堆栈)是一种“后入先出”(LIFO)的队列。","source":"_posts/java 集合类.md","raw":"title: java 集合类\ntags:\n - Collections\n - java\nid: 225\ncategories:\n - Java\ndate: 2015-06-10 08:56:44\n---\n\n[](https://napuzhang.files.wordpress.com/2015/06/qqe59bbee7898720150610153630.png)\n\n \n\n虚线标识“interface”,点线框标识“abstract”类,实线框代表实际的类。\n\n利用iterator()方法,所有集合都能生成一个“反复器”(Iterator)。反复器其实就象一个“枚举”\n(Enumeration),是后者的一个替代物,只是:\n(1) 它采用了一个历史上默认、而且早在OOP 中得到广泛采纳的名字(反复器)。\n(2) 采用了比Enumeration 更短的名字:hasNext()代替了hasMoreElement(),而next()代替了\nnextElement()。\n(3) 添加了一个名为remove()的新方法,可删除由Iterator 生成的上一个元素。所以每次调用next()的时候,只需调用remove()一次。\n\n### Collections\n\n<pre>Method:\n\nBoolean add(Object)\n\nBoolean addAll(Collection)\n\nvoid clear()\n\nBoolean contians(Object)\n\nBoolean containsAll(Collection)\n\nBoolean isEmpty()\n\nIterator iterator()\n\nBoolean remove(Object)\n\nBoolean removeAll(Collection)\n\nBoolean retianAll(Collection)\n\nint size()\n\nObject[] toArray()\n\nObject[] toArray(Object[] a)\n</pre>\n\n### Lists\n\nArrayList:用于替代原先的Vector,允许我们快速的访问元素,但在从列表中删除和添加元素时,速度慢。\n\nLinkedList:提供优化的顺序访问性能,同时可以高效地子列表中部插入和删除操作。但随即访问时,速度慢。\n\n### SETs\n\nSet拥有与Collection完全相同的接口,一个Set只允许每个对象存在一个实例\n\nHashSet:用于除非常小的以外的所有Set。对象也必须定义hashCode()。\n\nArraySet:面向非常小的Set 设计,特别是那些需要频繁创建和删除的。对于小Set,与HashSet 相比,ArraySet 创建和反复所需付出的代价都要小得多。但随着Set 的增大,它的性能也会大打折扣。不需要HashCode()。\n\nTreeSet:由一个“红黑树”后推得到的顺序Set。\n\n### Map\n\nMap(接口) 维持“键-值”对应关系(对),以便通过一个键查找相应的值\n\nHashMap:基于一个散列表实现。针对“键值对”的插入和检索,这种形式具有最稳定的性能。\n\nArrayMap:有一个ArrayList后推得到Map。对反复的顺序提供了精确的控制。面向非常小的Map 设计,特别是那些需要经常创建和删除的。对于非常小的Map,创建和反复所付出的代价要比HashMap 低得多。但在Map 变大以后,性能也会相应地大幅度降低。\n\nTreeMap:在一个“红-黑”树的基础上实现。查看键或者“键-值”对时,它们会按固定的顺序排列(取决于Comparable 或Comparator,稍后即会讲到)。TreeMap 最大的好处就是我们得到的是已排好序的结果。TreeMap 是含有subMap()方法的唯一一种Map,利用它可以返回树的一部分。\n\n选择List:\n\n[](https://napuzhang.files.wordpress.com/2015/06/qqe688aae59bbe20150610162659.png)\n\n \n\n选择Set:\n\n[](https://napuzhang.files.wordpress.com/2015/06/qqe688aae59bbe20150610162829.png)\n\n \n\n选择Map:\n\n[](https://napuzhang.files.wordpress.com/2015/06/qqe688aae59bbe20150610162957.png)\n\n \n\n(1) 数组包含了对象的数字化索引。它容纳的是一种已知类型的对象,所以在查找一个对象时,不必对结果进行造型处理。数组可以是多维的,而且能够容纳基本数据类型。但是,一旦把它创建好以后,大小便不能变化了。\n(2) Vector(矢量)也包含了对象的数字索引——可将数组和Vector 想象成随机访问集合。当我们加入更多的元素时,Vector 能够自动改变自身的大小。但Vector 只能容纳对象的句柄,所以它不可包含基本数据类型;而且将一个对象句柄从集合中取出来的时候,必须对结果进行造型处理。\n(3) Hashtable(散列表)属于Dictionary(字典)的一种类型,是一种将对象(而不是数字)同其他对象关联到一起的方式。散列表也支持对对象的随机访问,事实上,它的整个设计方案都在突出访问的“高速度”。\n(4) Stack(堆栈)是一种“后入先出”(LIFO)的队列。","slug":"java 集合类","published":1,"updated":"2015-12-02T04:39:35.628Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153x00030c0tjnji0fzpo"},{"title":"java 打印素数","id":"218","date":"2015-05-20T00:08:22.000Z","_content":"\n<pre> public static void main(String args[]){\n\n for(int i=2; i<100; i++){\n\n int factor = 0;\n for(int j=1; j<(i+2)/2; j++){\n\n if((i%j)==0){\n\n factor++;\n }\n }\n if(factor < 2)\n System.out.println(i+\" is a prime\");\n\n }\n }</pre>","source":"_posts/java 打印素数.md","raw":"title: java 打印素数\nid: 218\ncategories:\n - Java\ndate: 2015-05-20 08:08:22\ntags:\n---\n\n<pre> public static void main(String args[]){\n\n for(int i=2; i<100; i++){\n\n int factor = 0;\n for(int j=1; j<(i+2)/2; j++){\n\n if((i%j)==0){\n\n factor++;\n }\n }\n if(factor < 2)\n System.out.println(i+\" is a prime\");\n\n }\n }</pre>","slug":"java 打印素数","published":1,"updated":"2015-12-02T04:39:35.627Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153x40035c0tjn0nveav1"},{"title":"How to remove duplicates elements from ArrayList in Java","id":"210","date":"2015-05-15T05:24:29.000Z","_content":"\nHow to Remove Duplicates from Array without using Java Collection API\n\nRead more: [http://javarevisited.blogspot.com/2014/01/how-to-remove-duplicates-from-array-java-without-collection-API.html#ixzz3aD7lSsgh](http://javarevisited.blogspot.com/2014/01/how-to-remove-duplicates-from-array-java-without-collection-API.html#ixzz3aD7lSsgh)\n<pre>import java.util.Arrays;\n\npublic class RemoveDupFromArray{\n private static void main(String args[]){\n** int**[][] test = **new** **int**[][]{\n {**1**, **1**, **2**, **2**, **3**, **4**, **5**},\n {**1**, **1**, **1**, **1**, **1**, **1**, **1**},\n {**1**, **2**, **3**, **4**, **5**, **6**, **7**},\n {**1**, **2**, **1**, **1**, **1**, **1**, **1**},};\n\n for (int[] input : test){\n System.out.println(\"Array with Duplicates :\"+Arrays.toString(input));\n System.out.println(\"Array without Duplicates :\"+ Arrays.toString(removeDuplicates(input)));\n }\n }\n public static int[] removeDuplicates(int[] input){\n\n Arrays.sort(input);\n int[] result = new int[input.length];\n int pre = input[0];\n result[0] = pre;\n for(int i=1;i<input.length;i++){\n int ch = input[i];\n if(pre != ch){\n result[i] = ch\n }\n pre = ch;\n }\n return result;\n\n }\n}</pre>\nUse Collection API\n<pre>import java.util.ArrayList;\nimport java.util.Arrays;\nimport java.util.LinkedHashSet;\nimport java.util.List;\n\npublic class RemoveDuplicatesFromArray{\n\npublic static void main(String[] args){\nList<String> duplicatesList = (List<String>) Arrays.asList(\"Android\" , \"Android\", \"iOS\", \"Windows mobile\");\n\nSystem.out.println(\"size:\"+duplicatesList.size());\nSystem.out.println(\"String:\"+duplicatesList);\n\nLinkedHashSet<String> linkHash = new LinkedHashSet<String>(duplicatesList);\n\nList<String> removDup = new ArrayList<String>(linkHash);\n\nSystem.out.println(\"size:\"+removDup.size());\nSystem.out.println(\"String:\"+removDup);\n\n}\n\n}\n</pre>","source":"_posts/how-to-remove-duplicates-elements-from-arraylist-in-java.md","raw":"title: How to remove duplicates elements from ArrayList in Java\ntags:\n - Duplicate from Array\nid: 210\ncategories:\n - Java\ndate: 2015-05-15 13:24:29\n---\n\nHow to Remove Duplicates from Array without using Java Collection API\n\nRead more: [http://javarevisited.blogspot.com/2014/01/how-to-remove-duplicates-from-array-java-without-collection-API.html#ixzz3aD7lSsgh](http://javarevisited.blogspot.com/2014/01/how-to-remove-duplicates-from-array-java-without-collection-API.html#ixzz3aD7lSsgh)\n<pre>import java.util.Arrays;\n\npublic class RemoveDupFromArray{\n private static void main(String args[]){\n** int**[][] test = **new** **int**[][]{\n {**1**, **1**, **2**, **2**, **3**, **4**, **5**},\n {**1**, **1**, **1**, **1**, **1**, **1**, **1**},\n {**1**, **2**, **3**, **4**, **5**, **6**, **7**},\n {**1**, **2**, **1**, **1**, **1**, **1**, **1**},};\n\n for (int[] input : test){\n System.out.println(\"Array with Duplicates :\"+Arrays.toString(input));\n System.out.println(\"Array without Duplicates :\"+ Arrays.toString(removeDuplicates(input)));\n }\n }\n public static int[] removeDuplicates(int[] input){\n\n Arrays.sort(input);\n int[] result = new int[input.length];\n int pre = input[0];\n result[0] = pre;\n for(int i=1;i<input.length;i++){\n int ch = input[i];\n if(pre != ch){\n result[i] = ch\n }\n pre = ch;\n }\n return result;\n\n }\n}</pre>\nUse Collection API\n<pre>import java.util.ArrayList;\nimport java.util.Arrays;\nimport java.util.LinkedHashSet;\nimport java.util.List;\n\npublic class RemoveDuplicatesFromArray{\n\npublic static void main(String[] args){\nList<String> duplicatesList = (List<String>) Arrays.asList(\"Android\" , \"Android\", \"iOS\", \"Windows mobile\");\n\nSystem.out.println(\"size:\"+duplicatesList.size());\nSystem.out.println(\"String:\"+duplicatesList);\n\nLinkedHashSet<String> linkHash = new LinkedHashSet<String>(duplicatesList);\n\nList<String> removDup = new ArrayList<String>(linkHash);\n\nSystem.out.println(\"size:\"+removDup.size());\nSystem.out.println(\"String:\"+removDup);\n\n}\n\n}\n</pre>","slug":"how-to-remove-duplicates-elements-from-arraylist-in-java","published":1,"updated":"2015-12-02T04:39:35.627Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153x60037c0tjm55j25qm"},{"title":"Hexo-commands","date":"2015-11-27T09:52:48.000Z","_content":"\n# [Hexo](http://www.readseek.com/docs/commands.html)\n\n\n\n","source":"_posts/hexo-commands.md","raw":"title: Hexo-commands\ndate: 2015-11-27 17:52:48\ntags: Hexo\n---\n\n# [Hexo](http://www.readseek.com/docs/commands.html)\n\n\n\n","slug":"hexo-commands","published":1,"updated":"2015-12-02T04:39:35.627Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153x8003bc0tjvh748tx4"},{"title":"Flask Mysql Migrate","id":"101","date":"2015-04-28T19:38:42.000Z","_content":"\n<pre>from app import app,db\nfrom flask.ext.script import Manager\nfrom flask.ext.migrate import Migrate, MigrateCommand\n\nmigrate = Migrate(app, db)\n\nmanager = Manager(app)\nmanager.add_command('db', MigrateCommand)\nif __name__ == '__main__':\nmanager.run()</pre>\n<pre>$ python app.py db init</pre>\n<pre>$ python app.py db migrate</pre>\n<pre>$ python app.py db upgrade</pre>\n[Github](https://github.com/zhaohuizhang/aaronx)\n\n[Flask-migrate](https://flask-migrate.readthedocs.org/en/latest/)","source":"_posts/flask-mysql-migrate.md","raw":"title: Flask Mysql Migrate\ntags:\n - Flask migrate\n - python\nid: 101\ncategories:\n - Flask\ndate: 2015-04-29 03:38:42\n---\n\n<pre>from app import app,db\nfrom flask.ext.script import Manager\nfrom flask.ext.migrate import Migrate, MigrateCommand\n\nmigrate = Migrate(app, db)\n\nmanager = Manager(app)\nmanager.add_command('db', MigrateCommand)\nif __name__ == '__main__':\nmanager.run()</pre>\n<pre>$ python app.py db init</pre>\n<pre>$ python app.py db migrate</pre>\n<pre>$ python app.py db upgrade</pre>\n[Github](https://github.com/zhaohuizhang/aaronx)\n\n[Flask-migrate](https://flask-migrate.readthedocs.org/en/latest/)","slug":"flask-mysql-migrate","published":1,"updated":"2015-12-02T04:39:35.626Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153xa003ec0tjpf9d1sbo"},{"title":"Fibonacci","id":"202","date":"2015-05-15T03:59:44.000Z","_content":"\n```\nimport java.util.Scanner;\n\n/**\n*@author napu.zhang\n*/\npublic class Fibonacci{\n\n public static int fibonacciRecusion(int num){\n if(num == 1 || num ==2){\n return 1;\n }\n return fibonacciRecusion(num-1)+fibonacciRecusion(num-2);\n }\n\n public static int fibonacciLoop(int num){\n\n if(num == 1||num ==2){\n return 1;\n }\n int fibo1=1,fibo2=1,fibonacci=1;\n for(int i=3;i<=num;i++){\n fibonacci = fibo1 + fibo2;\n fibo1 = fibo2;\n fibo2 = fibonacci;\n }\n return fibonacci;\n }\n\n public static void main(String args[]){\n System.out.println(\"Enter num\")\n int number = new Scanner(System.In).nextInt();\n System.out.println(\"Fibonacci series upto \"+number+\"numbers:\");\n for(int i=1;i<=number; i++){\n System.out.print(fibonacciRecusion(i)+\"\" );\n }\n }\n}\n```\n","source":"_posts/fibonacci.md","raw":"title: Fibonacci\nid: 202\ncategories:\n - fibonacci\ndate: 2015-05-15 11:59:44\ntags:\n---\n\n```\nimport java.util.Scanner;\n\n/**\n*@author napu.zhang\n*/\npublic class Fibonacci{\n\n public static int fibonacciRecusion(int num){\n if(num == 1 || num ==2){\n return 1;\n }\n return fibonacciRecusion(num-1)+fibonacciRecusion(num-2);\n }\n\n public static int fibonacciLoop(int num){\n\n if(num == 1||num ==2){\n return 1;\n }\n int fibo1=1,fibo2=1,fibonacci=1;\n for(int i=3;i<=num;i++){\n fibonacci = fibo1 + fibo2;\n fibo1 = fibo2;\n fibo2 = fibonacci;\n }\n return fibonacci;\n }\n\n public static void main(String args[]){\n System.out.println(\"Enter num\")\n int number = new Scanner(System.In).nextInt();\n System.out.println(\"Fibonacci series upto \"+number+\"numbers:\");\n for(int i=1;i<=number; i++){\n System.out.print(fibonacciRecusion(i)+\"\" );\n }\n }\n}\n```\n","slug":"fibonacci","published":1,"updated":"2015-12-02T04:39:35.626Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153xe003kc0tjfly9vy31"},{"title":"Fibonacci","id":"237","date":"2015-06-15T00:55:39.000Z","_content":"\n<pre>public class Fibonacci{\n\n public static int fibonacci(int n){\n\n if(n==1 || n==2){\n\n return 1;\n }\n return fibonacci(n-1)+fibonacci(n-2);\n }\n public static int fibonacci2(int n){\n\n if(n==1 || n==2){\n\n return 1;\n }\n\n int n1 = 1, n2 = 1, fibo = 1;\n for(int i=3; i<=n; i++){\n\n fibo = n1 + n2;\n n1 = n2;\n n2 = fibo;\n\n }\n return fibo;\n }\n\n public static void main(String args[]){\n\n for(int i=1; i<=10; i++){\n System.out.print(Fibonacci.fibonacci2(i) +\" \");\n }\n\n }\n}</pre>","source":"_posts/fibonacci-2.md","raw":"title: Fibonacci\ntags:\n - java\nid: 237\ncategories:\n - Java\ndate: 2015-06-15 08:55:39\n---\n\n<pre>public class Fibonacci{\n\n public static int fibonacci(int n){\n\n if(n==1 || n==2){\n\n return 1;\n }\n return fibonacci(n-1)+fibonacci(n-2);\n }\n public static int fibonacci2(int n){\n\n if(n==1 || n==2){\n\n return 1;\n }\n\n int n1 = 1, n2 = 1, fibo = 1;\n for(int i=3; i<=n; i++){\n\n fibo = n1 + n2;\n n1 = n2;\n n2 = fibo;\n\n }\n return fibo;\n }\n\n public static void main(String args[]){\n\n for(int i=1; i<=10; i++){\n System.out.print(Fibonacci.fibonacci2(i) +\" \");\n }\n\n }\n}</pre>","slug":"fibonacci-2","published":1,"updated":"2015-12-02T04:39:35.625Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153xi003nc0tjs1cc3b4w"},{"title":"check-linux-version","date":"2015-12-18T04:03:14.000Z","_content":"\n### 电脑以及操作系统的相关信息\n```\nuname -a\n```\n\n### 正在运行的内核版本\n```\ncat /proc/version\n```\n\n### 显示发行版本信息\n```\ncat /etc/issue\n```\n","source":"_posts/check-linux-version.md","raw":"title: check-linux-version\ndate: 2015-12-18 12:03:14\ntags: Linux\n---\n\n### 电脑以及操作系统的相关信息\n```\nuname -a\n```\n\n### 正在运行的内核版本\n```\ncat /proc/version\n```\n\n### 显示发行版本信息\n```\ncat /etc/issue\n```\n","slug":"check-linux-version","published":1,"updated":"2015-12-18T05:55:28.513Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153xm003qc0tjnuljqpbf"},{"title":"XML Schema 和 DTD的区别","id":"204","date":"2015-05-15T04:12:23.000Z","_content":"\n# [Schema和DTD的区别](http://www.cnblogs.com/zhaozhan/archive/2010/01/04/1639194.html)\n\n<div class=\"clear\"></div>\n<div class=\"postBody\">\n<div id=\"cnblogs_post_body\">\n\n Schema是对XML文档结构的定义和描述,其主要的作用是用来约束XML文件,并验证XML文件有效性。DTD的作用是定义XML的合法构建模块,它使用一系列的合法元素来定义文档结构。它们之间的区别有下面几点:\n\n1、Schema本身也是XML文档,DTD定义跟XML没有什么关系,Schema在理解和实际应用有很多的好处。\n\n2、DTD文档的结构是“平铺型”的,如果定义复杂的XML文档,很难把握各元素之间的嵌套关系;Schema文档结构性强,各元素之间的嵌套关系非常直观。\n\n3、DTD只能指定元素含有文本,不能定义元素文本的具体类型,如字符型、整型、日期型、自定义类型等。Schema在这方面比DTD强大。\n\n4、Schema支持元素节点顺序的描述,DTD没有提供无序情况的描述,要定义无序必需穷举排列的所有情况。Schema可以利用xs:all来表示无序的情况。\n\n5、对命名空间的支持。DTD无法利用XML的命名空间,Schema很好满足命名空间。并且,Schema还提供了include和import两种引用命名空间的方法。\n\n</div>\n<div class=\"clear\"></div>\n<div id=\"blog_post_info_block\">\n<div id=\"BlogPostCategory\">分类: [XML](http://www.cnblogs.com/zhaozhan/category/209171.html)</div>\n</div>\n</div>","source":"_posts/XML Schema 和 DTD的区别.md","raw":"title: XML Schema 和 DTD的区别\ntags:\n - DTD\n - Schema\n - XML\nid: 204\ncategories:\n - Java\ndate: 2015-05-15 12:12:23\n---\n\n# [Schema和DTD的区别](http://www.cnblogs.com/zhaozhan/archive/2010/01/04/1639194.html)\n\n<div class=\"clear\"></div>\n<div class=\"postBody\">\n<div id=\"cnblogs_post_body\">\n\n Schema是对XML文档结构的定义和描述,其主要的作用是用来约束XML文件,并验证XML文件有效性。DTD的作用是定义XML的合法构建模块,它使用一系列的合法元素来定义文档结构。它们之间的区别有下面几点:\n\n1、Schema本身也是XML文档,DTD定义跟XML没有什么关系,Schema在理解和实际应用有很多的好处。\n\n2、DTD文档的结构是“平铺型”的,如果定义复杂的XML文档,很难把握各元素之间的嵌套关系;Schema文档结构性强,各元素之间的嵌套关系非常直观。\n\n3、DTD只能指定元素含有文本,不能定义元素文本的具体类型,如字符型、整型、日期型、自定义类型等。Schema在这方面比DTD强大。\n\n4、Schema支持元素节点顺序的描述,DTD没有提供无序情况的描述,要定义无序必需穷举排列的所有情况。Schema可以利用xs:all来表示无序的情况。\n\n5、对命名空间的支持。DTD无法利用XML的命名空间,Schema很好满足命名空间。并且,Schema还提供了include和import两种引用命名空间的方法。\n\n</div>\n<div class=\"clear\"></div>\n<div id=\"blog_post_info_block\">\n<div id=\"BlogPostCategory\">分类: [XML](http://www.cnblogs.com/zhaozhan/category/209171.html)</div>\n</div>\n</div>","slug":"XML Schema 和 DTD的区别","published":1,"updated":"2015-12-02T04:39:35.625Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153xp003tc0tjc3fqx62t"},{"title":"Sublime Text 2 插件安装","id":"88","date":"2015-04-26T19:43:17.000Z","_content":"\n[Sublime Text 2安装插件有两种方法:](http://www.cnblogs.com/dolphin0520/archive/2013/04/29/3046237.html)\n\n1)离线安装,先下载好安装包,解压之后放到Packages文件夹下,重启Sublime即可。\n\n2)在线安装,在线安装之前,需要安装”Packages Control“这个包管理插件,安装方法是:\n\n选择”查看“—>”显示控制台“,然后在下面弹出的框中输入:\n<div class=\"cnblogs_code\">\n<pre>import urllib2,os;pf='Package Control.sublime-package';ipp=sublime.installed_packages_path();os.makedirs(ipp) if not os.path.exists(ipp) else None;open(os.path.join(ipp,pf),'wb').write(urllib2.urlopen('http://sublime.wbond.net/'+pf.replace(' ','%20')).read())</pre>\n</div>\n然后回车确认,安装完毕之后重启sublime,如果发现在Perferences中看到package control这一项,则安装成功。\n\n然后就可以通过”Ctrl+Shift+P“打开命令面板,输入”install“命令,就可以看到安装包列表了。\n\n下面推荐几款必备的常用插件:\n\n1.Tag插件\n\nTag插件可以为web开发者提供html和css标签,很方便快捷,对于web前端设计者非常实用。\n\n\n\n2.Prefixr插件\n\n为css3提供一些前缀,比如\n\n\n\n3.Terminal插件\n\nTerminal插件可以允许在Sublime Text2中打开cmd命令窗口,很实用的一个插件,安装好该插件好,打开cmd命令窗口的快捷键是\n\nCtrl+Shift+T。\n\n4.SublimeTmpl插件\n\n这个插件允许用户定义文件的模板,比如在写一个html文件时,老是重复文件头的一些引入信息很繁琐,可以定义一个模板直接生成必须的信息,具体的SublimeTmpl插件用法请自行百度。\n\n5.SideBarEnhancements插件\n\n一个增强侧边栏文件夹浏览功能的插件,比较不错。\n\n6.DocBlockr插件\n\n用来生成注释块的插件,安装好之后直接输入\"/*\",然后再按回车键,即可生成代码注释块。\n\n7.SublimeCodeIntel插件\n\n智能提示插件,这个插件的智能提示功能非常强大,可以自定义提示的内容库,我的Python智能提示设置(配置文件路径为packages\\SublimeCodeIntel-master\\.codeintel\\config)为:\n<div class=\"cnblogs_code\">\n<div class=\"cnblogs_code_toolbar\"><span class=\"cnblogs_code_copy\"><a title=\"复制代码\"></a></span></div>\n<pre>{\n \"Python\": {\n \"python\":'D:/Program Files/Python26/python.exe',\n \"pythonExtraPaths\": ['D:/Program Files/Python26','D:/Program Files/Python26/DLLs','D:/Program Files/Python26/Lib','D:/Program Files/Python26/Lib/plat-win','D:/Program Files/Python26/Lib/lib-tk','D:/Program Files/Python26/Lib/site-packages']\n }\n}</pre>\n<div class=\"cnblogs_code_toolbar\"><span class=\"cnblogs_code_copy\"><a title=\"复制代码\"></a></span></div>\n</div>\n其中“pythonExtraPaths”就是需要智能提示所需要用到的内容库。\n\n8.AndyPython插件\n\n一款针对Python语言的智能提示插件,其需要提示的关键字和函数可以在Packages\\AndyPython\\PythonCompletions.py中设置。\n\n9.AndyJS2插件\n\n一款针对Javsscript和jquery智能提示的插件。\n\n10.jquery插件\n\njquery提示库。\n\n11.Ctags插件\n\n该插件可以实现快速定位到函数定义的地方。\n\n12.为了避免打开含中文字符的文件出现乱码,需要先安装GBK Encoding Support这个插件,再安装ConvertToUTF8插件即可。\n\n如果有朋友觉得没有注册有时候会有弹窗比较讨厌,这里介绍一种破解办法:\n\n用一种十六进制编辑器(我这里用的UltraEdit)打开sublime text 2安装目录下的文件sublime_text.exe,在此之前最好备份一下,如果没有破解成功可以恢复,然后定位到000CBB70这一行,找到8A C3,将其修改为B0 01,然后保存即可,这是破解注册成功的界面:\n\n","source":"_posts/Sublime Text 2 插件安装.md","raw":"title: Sublime Text 2 插件安装\ntags:\n - Sublime Text2 Plugins install\nid: 88\ncategories:\n - Tools\ndate: 2015-04-27 03:43:17\n---\n\n[Sublime Text 2安装插件有两种方法:](http://www.cnblogs.com/dolphin0520/archive/2013/04/29/3046237.html)\n\n1)离线安装,先下载好安装包,解压之后放到Packages文件夹下,重启Sublime即可。\n\n2)在线安装,在线安装之前,需要安装”Packages Control“这个包管理插件,安装方法是:\n\n选择”查看“—>”显示控制台“,然后在下面弹出的框中输入:\n<div class=\"cnblogs_code\">\n<pre>import urllib2,os;pf='Package Control.sublime-package';ipp=sublime.installed_packages_path();os.makedirs(ipp) if not os.path.exists(ipp) else None;open(os.path.join(ipp,pf),'wb').write(urllib2.urlopen('http://sublime.wbond.net/'+pf.replace(' ','%20')).read())</pre>\n</div>\n然后回车确认,安装完毕之后重启sublime,如果发现在Perferences中看到package control这一项,则安装成功。\n\n然后就可以通过”Ctrl+Shift+P“打开命令面板,输入”install“命令,就可以看到安装包列表了。\n\n下面推荐几款必备的常用插件:\n\n1.Tag插件\n\nTag插件可以为web开发者提供html和css标签,很方便快捷,对于web前端设计者非常实用。\n\n\n\n2.Prefixr插件\n\n为css3提供一些前缀,比如\n\n\n\n3.Terminal插件\n\nTerminal插件可以允许在Sublime Text2中打开cmd命令窗口,很实用的一个插件,安装好该插件好,打开cmd命令窗口的快捷键是\n\nCtrl+Shift+T。\n\n4.SublimeTmpl插件\n\n这个插件允许用户定义文件的模板,比如在写一个html文件时,老是重复文件头的一些引入信息很繁琐,可以定义一个模板直接生成必须的信息,具体的SublimeTmpl插件用法请自行百度。\n\n5.SideBarEnhancements插件\n\n一个增强侧边栏文件夹浏览功能的插件,比较不错。\n\n6.DocBlockr插件\n\n用来生成注释块的插件,安装好之后直接输入\"/*\",然后再按回车键,即可生成代码注释块。\n\n7.SublimeCodeIntel插件\n\n智能提示插件,这个插件的智能提示功能非常强大,可以自定义提示的内容库,我的Python智能提示设置(配置文件路径为packages\\SublimeCodeIntel-master\\.codeintel\\config)为:\n<div class=\"cnblogs_code\">\n<div class=\"cnblogs_code_toolbar\"><span class=\"cnblogs_code_copy\"><a title=\"复制代码\"></a></span></div>\n<pre>{\n \"Python\": {\n \"python\":'D:/Program Files/Python26/python.exe',\n \"pythonExtraPaths\": ['D:/Program Files/Python26','D:/Program Files/Python26/DLLs','D:/Program Files/Python26/Lib','D:/Program Files/Python26/Lib/plat-win','D:/Program Files/Python26/Lib/lib-tk','D:/Program Files/Python26/Lib/site-packages']\n }\n}</pre>\n<div class=\"cnblogs_code_toolbar\"><span class=\"cnblogs_code_copy\"><a title=\"复制代码\"></a></span></div>\n</div>\n其中“pythonExtraPaths”就是需要智能提示所需要用到的内容库。\n\n8.AndyPython插件\n\n一款针对Python语言的智能提示插件,其需要提示的关键字和函数可以在Packages\\AndyPython\\PythonCompletions.py中设置。\n\n9.AndyJS2插件\n\n一款针对Javsscript和jquery智能提示的插件。\n\n10.jquery插件\n\njquery提示库。\n\n11.Ctags插件\n\n该插件可以实现快速定位到函数定义的地方。\n\n12.为了避免打开含中文字符的文件出现乱码,需要先安装GBK Encoding Support这个插件,再安装ConvertToUTF8插件即可。\n\n如果有朋友觉得没有注册有时候会有弹窗比较讨厌,这里介绍一种破解办法:\n\n用一种十六进制编辑器(我这里用的UltraEdit)打开sublime text 2安装目录下的文件sublime_text.exe,在此之前最好备份一下,如果没有破解成功可以恢复,然后定位到000CBB70这一行,找到8A C3,将其修改为B0 01,然后保存即可,这是破解注册成功的界面:\n\n","slug":"Sublime Text 2 插件安装","published":1,"updated":"2015-12-02T04:39:35.624Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153xu0041c0tj2phh3t2x"},{"title":"Struts (V-1.3.8) 应用概述","id":"51","date":"2015-04-21T06:19:59.000Z","_content":"\nstruts 为 Apache Jakarta项目的组成部分。项目的创立者希望通过对该项目的研究,改进和提高Java Server Pages(JSP), Servlet、标签库以及面向对象的技术水准。\n\nStruts名字来源于建筑和旧式飞机中使用的支持金属架。它的目的是为了减少运用MVC设计模式开发Web应用的时间。混合使用Servlets和JSP的优点来建立可扩展的应用。\n\nFramework, 软件架构的建立是一个复杂而又持续改进的过程,开发者要尽量重用以前的框架。\n\nMVC是Model-View-Controller是一种常用的设计模式。MVC减弱了业务逻辑接口和数据接口之间的耦合\n\n\n\nStruts是MVC的一种实现,他将Servlet和JSP标记用作实现的一部分。\n\n\n\nController:有一个XML文件Struts-config.xml,与之相关联的是Controller,在Struts中,承担MVC中Controller角色的是一个Servlet,叫ActionServlet。ActionServlet是一个通用的控制组件,这个控制组件提供了处理所有发送到Struts的HTTP请求的入口点。它截取和分发这些请求到相应的动作类(这些动作类都是Action类的子类)。另外控制组件也负责用相应的请求参数填充ActionForm(FormBean),并传给动作类(ActionBean)。动作类用于实现核心商业逻辑,可以访问JavaBean或调用EJB。最后动作类把控制权传给后续的JSP文件,后者生成视图。所有这些控制逻辑利用Struts-config.xml文件来配置。\n\nView:主要由JSP生成页面完成视图,Struts提供了丰富的JSP标签库:HTML,Bean,Logic,Template等,这有利于充分表现逻辑和程序逻辑。\n\nModel:模型以一个或多个JavaBean的形式存在。这些Bean分为三类:Action Form,Action,JavaBean or EJB。Action Form通常称为FormBean,封装了来自于Client的请求信息,如表单信息。Action通常称为ActionBean,获取从ActionServlet传来的FormBean,取出并处理FormBean中的相关信息,一般是调用Java Bean 或 EJB等。\n\n在Struts中,用户的请求一般以*.do作为请求服务名,所有的*.do请求均被指向ActionSevlet, ActionServlet根据Struts-config.xml中配置信息,将用户请求封装成一个指定名称的FormBean,并将此FormBean传至指定名称的ActionBean,由ActionBean完成相应的业务操作,如文件操作、数据库操作等。每一个*.do均有对应的FormBean名称和ActionBean名称,这些在Struts-config.xml中配置。\n\nStruts和核心是ActionServlet,ActionSevlet的核心是struts-config.xml.\n\n当请求来临之时,系统如何知晓要用哪个ActionForm来封装请求数据,又是如何知晓要用哪个Action来处理数据,最后又是如何来应答的呢?找struts-config.xml\n\nStruts用配置文件来定义应用的一些内容,包括连接的逻辑名称。Struts在启动时读入配置文件,以创建一个所需要的对象数据库。各种Struts组件都引用这个数据库来提供框架的各种服务。","source":"_posts/Struts (V-1.3.8) 应用概述.md","raw":"title: Struts (V-1.3.8) 应用概述\ntags:\n - MVC\n - struts\nid: 51\ncategories:\n - Struts\ndate: 2015-04-21 14:19:59\n---\n\nstruts 为 Apache Jakarta项目的组成部分。项目的创立者希望通过对该项目的研究,改进和提高Java Server Pages(JSP), Servlet、标签库以及面向对象的技术水准。\n\nStruts名字来源于建筑和旧式飞机中使用的支持金属架。它的目的是为了减少运用MVC设计模式开发Web应用的时间。混合使用Servlets和JSP的优点来建立可扩展的应用。\n\nFramework, 软件架构的建立是一个复杂而又持续改进的过程,开发者要尽量重用以前的框架。\n\nMVC是Model-View-Controller是一种常用的设计模式。MVC减弱了业务逻辑接口和数据接口之间的耦合\n\n\n\nStruts是MVC的一种实现,他将Servlet和JSP标记用作实现的一部分。\n\n\n\nController:有一个XML文件Struts-config.xml,与之相关联的是Controller,在Struts中,承担MVC中Controller角色的是一个Servlet,叫ActionServlet。ActionServlet是一个通用的控制组件,这个控制组件提供了处理所有发送到Struts的HTTP请求的入口点。它截取和分发这些请求到相应的动作类(这些动作类都是Action类的子类)。另外控制组件也负责用相应的请求参数填充ActionForm(FormBean),并传给动作类(ActionBean)。动作类用于实现核心商业逻辑,可以访问JavaBean或调用EJB。最后动作类把控制权传给后续的JSP文件,后者生成视图。所有这些控制逻辑利用Struts-config.xml文件来配置。\n\nView:主要由JSP生成页面完成视图,Struts提供了丰富的JSP标签库:HTML,Bean,Logic,Template等,这有利于充分表现逻辑和程序逻辑。\n\nModel:模型以一个或多个JavaBean的形式存在。这些Bean分为三类:Action Form,Action,JavaBean or EJB。Action Form通常称为FormBean,封装了来自于Client的请求信息,如表单信息。Action通常称为ActionBean,获取从ActionServlet传来的FormBean,取出并处理FormBean中的相关信息,一般是调用Java Bean 或 EJB等。\n\n在Struts中,用户的请求一般以*.do作为请求服务名,所有的*.do请求均被指向ActionSevlet, ActionServlet根据Struts-config.xml中配置信息,将用户请求封装成一个指定名称的FormBean,并将此FormBean传至指定名称的ActionBean,由ActionBean完成相应的业务操作,如文件操作、数据库操作等。每一个*.do均有对应的FormBean名称和ActionBean名称,这些在Struts-config.xml中配置。\n\nStruts和核心是ActionServlet,ActionSevlet的核心是struts-config.xml.\n\n当请求来临之时,系统如何知晓要用哪个ActionForm来封装请求数据,又是如何知晓要用哪个Action来处理数据,最后又是如何来应答的呢?找struts-config.xml\n\nStruts用配置文件来定义应用的一些内容,包括连接的逻辑名称。Struts在启动时读入配置文件,以创建一个所需要的对象数据库。各种Struts组件都引用这个数据库来提供框架的各种服务。","slug":"Struts (V-1.3.8) 应用概述","published":1,"updated":"2015-12-02T04:39:35.624Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153xw0046c0tjy8kvnxdx"},{"title":"Struts 标签","id":"80","date":"2015-04-24T00:34:10.000Z","_content":"\nStrust 提供了5个标签库:HTML标签库,Bean标签库,Logic标签库,Template标签库,Nested标签库。\n<table>\n<thead>\n<tr>\n<th>标签库</th>\n<th>描述</th>\n</tr>\n</thead>\n<tbody>\n<tr>\n<td>HTML标签</td>\n<td>用来创建能够和Struts框架以及其他相应的HTML标签交互的语言环境标签</td>\n</tr>\n<tr>\n<td>Bean标签</td>\n<td>在访问JavaBean及其属性,以及定义一个新的bean时使用</td>\n</tr>\n<tr>\n<td>Logic标签</td>\n<td>管理条件产生的输出和对象集产生的循环</td>\n</tr>\n<tr>\n<td>Template标签</td>\n<td>很少使用,都用Tiles啦</td>\n</tr>\n<tr>\n<td>Nested标签</td>\n<td>增强对其他Struts标签的嵌套使用能力</td>\n</tr>\n</tbody>\n</table>\n1,Struts HTML标签\n\n<html:html>,<html:base>,<html:img>,<html:link>,<html:errors>,<html:form>,<html:password>,<html:select>,<html:option>,\n\n2,Bean标签\n\n操作JavaBean相关的对象,cookie,header,parameter,define,write,message,include,page,resource,size,struts等。\n\n3,Logic标签\n\n比较运算符标签;循环遍历标签;字符串匹配标签;判断指定内容是否存在标签;判断空标签;转发与重定向标签\n\n<logic:equal>,<logic:greaterThan>,<logic:greaterEqual>,<logic:lessThan>,<logic:lessEqual>,<lgoic:iterate>,<logic:match>,<logic:notmatch>,<logic:present>,<logic:notpresent>\n\nSample:\n<pre><% pageContext.setAttribute(\"test\",\"helloworld\");%>\n<logic:match value=\"hello\" name=\"test\">\nhello is component of test\n</logic:match></pre>","source":"_posts/Struts 标签.md","raw":"title: Struts 标签\ntags:\n - struts\n - Tag\nid: 80\ncategories:\n - Struts\ndate: 2015-04-24 08:34:10\n---\n\nStrust 提供了5个标签库:HTML标签库,Bean标签库,Logic标签库,Template标签库,Nested标签库。\n<table>\n<thead>\n<tr>\n<th>标签库</th>\n<th>描述</th>\n</tr>\n</thead>\n<tbody>\n<tr>\n<td>HTML标签</td>\n<td>用来创建能够和Struts框架以及其他相应的HTML标签交互的语言环境标签</td>\n</tr>\n<tr>\n<td>Bean标签</td>\n<td>在访问JavaBean及其属性,以及定义一个新的bean时使用</td>\n</tr>\n<tr>\n<td>Logic标签</td>\n<td>管理条件产生的输出和对象集产生的循环</td>\n</tr>\n<tr>\n<td>Template标签</td>\n<td>很少使用,都用Tiles啦</td>\n</tr>\n<tr>\n<td>Nested标签</td>\n<td>增强对其他Struts标签的嵌套使用能力</td>\n</tr>\n</tbody>\n</table>\n1,Struts HTML标签\n\n<html:html>,<html:base>,<html:img>,<html:link>,<html:errors>,<html:form>,<html:password>,<html:select>,<html:option>,\n\n2,Bean标签\n\n操作JavaBean相关的对象,cookie,header,parameter,define,write,message,include,page,resource,size,struts等。\n\n3,Logic标签\n\n比较运算符标签;循环遍历标签;字符串匹配标签;判断指定内容是否存在标签;判断空标签;转发与重定向标签\n\n<logic:equal>,<logic:greaterThan>,<logic:greaterEqual>,<logic:lessThan>,<logic:lessEqual>,<lgoic:iterate>,<logic:match>,<logic:notmatch>,<logic:present>,<logic:notpresent>\n\nSample:\n<pre><% pageContext.setAttribute(\"test\",\"helloworld\");%>\n<logic:match value=\"hello\" name=\"test\">\nhello is component of test\n</logic:match></pre>","slug":"Struts 标签","published":1,"updated":"2015-12-02T04:39:35.624Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153y0004bc0tjhlkkcj12"},{"title":"Struts 工作原理","id":"66","date":"2015-04-22T05:14:27.000Z","_content":"\n\n\n1,读取配置(初始化ModuleConfig对象)\n\n采用Struts框架的Web应用,在Web应用启动时就会加载ActionServlet,在ActionServlet初始化ModuleConfig的时候,调用initModuleConfigFactory()初始化配置工厂,然后由配置工厂通过initModuleConfig('',cofing)获得ModuleConfig对象。\n<pre>initModuleMessageResources(moduleConfig);\ninitModuleDataSources(moduleConfig);\ninitModulePlugIns(moduleCofig);</pre>\n这些方法的功能就是:容器在加载Struts应用程序时,会先加载web.xml中与Struts相关的一些参数,找到Struts-config.xml文件,通过循环来读取此文件和解析里面的内容,并初始化相关对象。\n\n2,用户请求\n\n用户提交表单或调用URL向Web应用程序服务器提交一个请求,请求数据用HTTP协议上传给Web服务器。\n\n3,填充FormBean\n\n填充FormBean的过程包括实例化,复位,填充数据,校验,保存等操作。根据*.do请求从ActionConfig中找出对应该请求的Action子类,如有对应的Action且这个Action有一个相应的ActionForm,则ActionForm被实例化并用HTTP请求的数据填充其属性,并保存在ServletContext中,这样它们就可以被其他的Action对象或者JSP调用。\n\n4,转发请求\n\n控制器根据ActionConfig将请求发送到具体的Action,与请求一起的FormBean也一并传给这个Action对象。\n\n5,处理业务\n\nAction一般包含一个execute()方法,负责业务逻辑,执行完毕后返回一个ActionForward对象,控制器通过ActionForward对象进行转发工作。\n\n6,返回响应\n\nAction根据不同的结果返回一个响应给总的控制器,该目标响应对象对应一个具体的JSP页面或另一个Action。\n\n7,查找响应\n\n总控制器根据业务功能Action返回的目标响应对象找到相应的资源对象,通常是一个具体的JSP页面。\n\n8,响应用户\n\n目标相应对象将结果展现给用户目标响应对象,即具体的JSP页面,这样客户就得到响应的结果。","source":"_posts/Struts 工作原理.md","raw":"title: Struts 工作原理\ntags:\n - struts\n - work principal\nid: 66\ncategories:\n - Struts\ndate: 2015-04-22 13:14:27\n---\n\n\n\n1,读取配置(初始化ModuleConfig对象)\n\n采用Struts框架的Web应用,在Web应用启动时就会加载ActionServlet,在ActionServlet初始化ModuleConfig的时候,调用initModuleConfigFactory()初始化配置工厂,然后由配置工厂通过initModuleConfig('',cofing)获得ModuleConfig对象。\n<pre>initModuleMessageResources(moduleConfig);\ninitModuleDataSources(moduleConfig);\ninitModulePlugIns(moduleCofig);</pre>\n这些方法的功能就是:容器在加载Struts应用程序时,会先加载web.xml中与Struts相关的一些参数,找到Struts-config.xml文件,通过循环来读取此文件和解析里面的内容,并初始化相关对象。\n\n2,用户请求\n\n用户提交表单或调用URL向Web应用程序服务器提交一个请求,请求数据用HTTP协议上传给Web服务器。\n\n3,填充FormBean\n\n填充FormBean的过程包括实例化,复位,填充数据,校验,保存等操作。根据*.do请求从ActionConfig中找出对应该请求的Action子类,如有对应的Action且这个Action有一个相应的ActionForm,则ActionForm被实例化并用HTTP请求的数据填充其属性,并保存在ServletContext中,这样它们就可以被其他的Action对象或者JSP调用。\n\n4,转发请求\n\n控制器根据ActionConfig将请求发送到具体的Action,与请求一起的FormBean也一并传给这个Action对象。\n\n5,处理业务\n\nAction一般包含一个execute()方法,负责业务逻辑,执行完毕后返回一个ActionForward对象,控制器通过ActionForward对象进行转发工作。\n\n6,返回响应\n\nAction根据不同的结果返回一个响应给总的控制器,该目标响应对象对应一个具体的JSP页面或另一个Action。\n\n7,查找响应\n\n总控制器根据业务功能Action返回的目标响应对象找到相应的资源对象,通常是一个具体的JSP页面。\n\n8,响应用户\n\n目标相应对象将结果展现给用户目标响应对象,即具体的JSP页面,这样客户就得到响应的结果。","slug":"Struts 工作原理","published":1,"updated":"2015-12-02T04:39:35.623Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153y2004gc0tje3k6542s"},{"title":"Struts validate验证框架配置使用","id":"97","date":"2015-04-27T19:20:57.000Z","_content":"\n1,struts-config.xml文件中配置\n<pre><action path=\"/login\" name=\"loginForm\" scope=\"request\"\n type=\"org.napu.action.LoginForm\"\n validate=\"true\" input=\"/login.jsp\">\n <forward name=\"succ\" path=\"/success.jsp\"/>\n <forward name=\"error\" path=\"/error.jsp\"/>\n</action></pre>\nvalidate的值为true。\n<pre><struts-config>\n....\n<message-resouses parameter=\"AppliactionResource.property\" />\n<plug-in className=\"org.apache.struts.validator.ValidatorPlugin\">\n <set-property value=\"/WEB-INF/validator-rules.xml,/WEB-INF/validation.xml\" property=\"pathnames\">\n</plug-in>\n</struts-config></pre>\n2,在WEB-INF目录中新建validation.xml文件。\n<pre><form-validation>\n<global></global>\n<formset>\n<form name=\"LoginForm\">\n<field property=\"username\" depends=\"required,minlength,maxlength\">\n<arg0 key=\"userform.username\"/>\n<arg1 name=\"minlength\" key=\"${var:min}\" resource=\"false\"/>\n<arg2 name=\"maxlength\" key=\"${var:max}\" resource=\"true\"/>\n<var>\n<var-name>min</var-name>\n<var-value>6</var-value>\n</var>\n<var>\n<var-name>max</var-name>\n<var-value>20</var-value>\n</var> \n</field>\n</form>\n</formset>\n</form-validation></pre>\n3,把validator框架使用的消息文本添加到应用的ResourceBundle中,在ApplicationResource.properties中添加内容。\n\n4,将Form的extends ActionForm 改为extends ValidatorForm\n\n5,在JSP页面中添加<html:errors property=\"key\"/>。这里property对应Form中的定义的属性。\n\n \n\n### 自定义的验证\n\n1,创建一个实现规则接口的静态方法的类。\n\n2,在validator-rules.xml中的global元素中添加validator子元素\n\n3,在资源属性文件中添加error信息。\n\n4,在validation.xml中添加配置。","source":"_posts/Struts validate验证框架配置使用.md","raw":"title: Struts validate验证框架配置使用\ntags:\n - struts\n - Validation\nid: 97\ncategories:\n - Struts\ndate: 2015-04-28 03:20:57\n---\n\n1,struts-config.xml文件中配置\n<pre><action path=\"/login\" name=\"loginForm\" scope=\"request\"\n type=\"org.napu.action.LoginForm\"\n validate=\"true\" input=\"/login.jsp\">\n <forward name=\"succ\" path=\"/success.jsp\"/>\n <forward name=\"error\" path=\"/error.jsp\"/>\n</action></pre>\nvalidate的值为true。\n<pre><struts-config>\n....\n<message-resouses parameter=\"AppliactionResource.property\" />\n<plug-in className=\"org.apache.struts.validator.ValidatorPlugin\">\n <set-property value=\"/WEB-INF/validator-rules.xml,/WEB-INF/validation.xml\" property=\"pathnames\">\n</plug-in>\n</struts-config></pre>\n2,在WEB-INF目录中新建validation.xml文件。\n<pre><form-validation>\n<global></global>\n<formset>\n<form name=\"LoginForm\">\n<field property=\"username\" depends=\"required,minlength,maxlength\">\n<arg0 key=\"userform.username\"/>\n<arg1 name=\"minlength\" key=\"${var:min}\" resource=\"false\"/>\n<arg2 name=\"maxlength\" key=\"${var:max}\" resource=\"true\"/>\n<var>\n<var-name>min</var-name>\n<var-value>6</var-value>\n</var>\n<var>\n<var-name>max</var-name>\n<var-value>20</var-value>\n</var> \n</field>\n</form>\n</formset>\n</form-validation></pre>\n3,把validator框架使用的消息文本添加到应用的ResourceBundle中,在ApplicationResource.properties中添加内容。\n\n4,将Form的extends ActionForm 改为extends ValidatorForm\n\n5,在JSP页面中添加<html:errors property=\"key\"/>。这里property对应Form中的定义的属性。\n\n \n\n### 自定义的验证\n\n1,创建一个实现规则接口的静态方法的类。\n\n2,在validator-rules.xml中的global元素中添加validator子元素\n\n3,在资源属性文件中添加error信息。\n\n4,在validation.xml中添加配置。","slug":"Struts validate验证框架配置使用","published":1,"updated":"2015-12-02T04:39:35.623Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153y5004lc0tj15jkrh3o"},{"title":"Singleton","date":"2015-12-28T01:52:28.000Z","_content":"\n## 目的\n确定某个类只有一个实例,并且为之提供一个全局访问点,为了防止其他工作人员实例化我们的类。\n\n## 方法\n为该类创建唯一一个构造器,并将构造器设置为私有。不能有有其他非私有构造器,或者根本又有为该类提供构造器,其他人员任然能够实例化我们的类。\n\n## java里面通常有两种方法实现\n* 饿汉模式: 指全局的单例实例在类装载时构建,急切初始化。\n* 懒汉模式: 指全局的单例实例在第一次被使用时构建,延迟初始化。\n\n## 饿汉模式\n采用饿汉模式可以避免线程安全问题,但是任何对Singleton类的访问,比如类中有另外一个static方法被访问,将会引起jvm去初始化instance,而此时我们的本意是不想加载单例类。同时又因为没有延迟加载,最明显的缺点就是如果构造器内的方法比较耗时,则加载过程会比较长。对于一般的应用,构造方法内的代码不涉及到读取配置,远程调用,初始化IOC容器等长时间执行的情况,这种方法最简单。\n```\npublic class Singleton{\n private Singleton(){}\n private static Singleton instance = new Singleton();\n public static Singleton getInstance(){\n return instance;\n }\n}\n```\n## 懒汉模式\n单线程下没有问题,但多线程情况下可能会出现两个或以上的instance实例的情况。\n```\npublic class Singleton{\n private Singleton(){}\n private static Singleton instance = null;\n public static Singleton getInstance(){\n if(instance==null){\n instance = new Singleton();\n }\n return instance;\n }\n}\n```\n问题:线程1在判断instance=null为真,执行new 操作之前,判断为真之后,线程2正好执行判断操作,这是instance还是null。因此线程2也会执行new操作。\n改进代码\n```\npublic class Singleton{\n private Singleton(){}\n private static Singleton instance = null;\n public static synchronized Singleton getInstance(){\n if(instance == null){\n instance = new Singleton();\n }\n return instance;\n }\n}\n```\ngetInstance 会被外部线程比较频繁的调用,同步比非同步要消耗更多昂贵的资源,因此这样的做法存在很大的额外性能消耗。因此产生如下双检查写法:\n```\npublic class Singleton{\n private Singleton(){}\n private static Singleton instance = null;\n public static Singleton getInstance(){\n if(instance == null){\n synchronized(Singleton.class){\n if(instance == null){\n instance == new Singleton();\n }\n }\n }\n return instance;\n }\n}\n```\ninstance = new Singleton(), 对于编译器来说,分两步走,首先初始化一个instance 对象并随意赋一个值,然后调用Singleton类的构造器赋值。因此在第一步完成之后instance==null这一步已经不成立了,但此时instance只是一个临时值。如果线程2此时进入getInstance,就会把这个instance给返回。\n可以用一个容器类来解决这个问题。即可以使用延迟加载,让类在被使用的时候才加载,又避免额外的同步调用开销,同时还不使用双检查的模式。\n```\npublic class Singleton{\n private static class SingletonHolder{\n static Singleton instance = new Singleton();\n }\n public static Singleton getInstance(){\n return SingletonHolder.instance;\n }\n private Signleton(){}\n}\n```\njava中,只有一个类被用到的时候才被初始化。在getInstance方法被调用的时候,如果SingletonHolder类没有被加载,就会去加载,起到延迟加载的作用,同时也能保持多线程下的语义正确性。\n","source":"_posts/Singleton.md","raw":"title: Singleton\ndate: 2015-12-28 09:52:28\ntags: Java-Singleton\n---\n\n## 目的\n确定某个类只有一个实例,并且为之提供一个全局访问点,为了防止其他工作人员实例化我们的类。\n\n## 方法\n为该类创建唯一一个构造器,并将构造器设置为私有。不能有有其他非私有构造器,或者根本又有为该类提供构造器,其他人员任然能够实例化我们的类。\n\n## java里面通常有两种方法实现\n* 饿汉模式: 指全局的单例实例在类装载时构建,急切初始化。\n* 懒汉模式: 指全局的单例实例在第一次被使用时构建,延迟初始化。\n\n## 饿汉模式\n采用饿汉模式可以避免线程安全问题,但是任何对Singleton类的访问,比如类中有另外一个static方法被访问,将会引起jvm去初始化instance,而此时我们的本意是不想加载单例类。同时又因为没有延迟加载,最明显的缺点就是如果构造器内的方法比较耗时,则加载过程会比较长。对于一般的应用,构造方法内的代码不涉及到读取配置,远程调用,初始化IOC容器等长时间执行的情况,这种方法最简单。\n```\npublic class Singleton{\n private Singleton(){}\n private static Singleton instance = new Singleton();\n public static Singleton getInstance(){\n return instance;\n }\n}\n```\n## 懒汉模式\n单线程下没有问题,但多线程情况下可能会出现两个或以上的instance实例的情况。\n```\npublic class Singleton{\n private Singleton(){}\n private static Singleton instance = null;\n public static Singleton getInstance(){\n if(instance==null){\n instance = new Singleton();\n }\n return instance;\n }\n}\n```\n问题:线程1在判断instance=null为真,执行new 操作之前,判断为真之后,线程2正好执行判断操作,这是instance还是null。因此线程2也会执行new操作。\n改进代码\n```\npublic class Singleton{\n private Singleton(){}\n private static Singleton instance = null;\n public static synchronized Singleton getInstance(){\n if(instance == null){\n instance = new Singleton();\n }\n return instance;\n }\n}\n```\ngetInstance 会被外部线程比较频繁的调用,同步比非同步要消耗更多昂贵的资源,因此这样的做法存在很大的额外性能消耗。因此产生如下双检查写法:\n```\npublic class Singleton{\n private Singleton(){}\n private static Singleton instance = null;\n public static Singleton getInstance(){\n if(instance == null){\n synchronized(Singleton.class){\n if(instance == null){\n instance == new Singleton();\n }\n }\n }\n return instance;\n }\n}\n```\ninstance = new Singleton(), 对于编译器来说,分两步走,首先初始化一个instance 对象并随意赋一个值,然后调用Singleton类的构造器赋值。因此在第一步完成之后instance==null这一步已经不成立了,但此时instance只是一个临时值。如果线程2此时进入getInstance,就会把这个instance给返回。\n可以用一个容器类来解决这个问题。即可以使用延迟加载,让类在被使用的时候才加载,又避免额外的同步调用开销,同时还不使用双检查的模式。\n```\npublic class Singleton{\n private static class SingletonHolder{\n static Singleton instance = new Singleton();\n }\n public static Singleton getInstance(){\n return SingletonHolder.instance;\n }\n private Signleton(){}\n}\n```\njava中,只有一个类被用到的时候才被初始化。在getInstance方法被调用的时候,如果SingletonHolder类没有被加载,就会去加载,起到延迟加载的作用,同时也能保持多线程下的语义正确性。\n","slug":"Singleton","published":1,"updated":"2015-12-28T05:16:02.346Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153y9004qc0tjjk0i9kcm"},{"title":"Python 工具总结","id":"29","date":"2015-04-20T18:08:57.000Z","_content":"\n## 一、Python网页爬虫工具集\n\n自己动手获取数据\n\n### 1,Scrapy\n\nScrapy, a fast high-level screen scraping and web crawling framework for Python.\n\n《Scrapy轻松定制网络爬虫》\n\n[官网](http://scrapy.org/),[Github代码](https://github.com/scrapy/scrapy)\n\n### 2,Beautiful Soup\n\nYou didn't write that awful page. You're just trying to get some data out of it. Beautiful Soup is here to help. Since 2004, it's been saving programmers hours or days of week on quick-turnaround screen scraping projects.\n\n配合urllib使用,数据分析,清洗和获取的工具\n\n[官网](http://www.crummy.com/software/BeautifulSoup/)\n\n### 3,Python-Goose\n\nHtml Content/Article Extractor, web scrapping lib in Python\n\nGoose最早是用Java写,现在用Scala重写,是一个Scala项目,Python-Goose用Python重写,依赖于Beautiful Soup。\n\n[Github](https://github.com/grangier/python-goose)地址\n\n## 二、Python文本处理工具集\n\n网页爬取数据之后进行基本的文本处理,譬如对于英文来说要最基本的tokenize,对于中文,则需要中文分词,进一步的话,词性标注,句法分析,关键词提取,文本分类,情感分析。\n\n### 1,NLTK-Natural Language Toolkit\n\nNLTK is a leading platform for building Python programs to work with human language data. It provide easy-to-use interface to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic, reasoning, and an active discussion forum.\n\n《Natural Language Processing with Python》 《Python Text Processing with NLTK 2.0 Cookbook》\n\n[官网](http://www.nltk.org/),[Github](https://github.com/nltk/nltk)\n\n### 2,Pattern\n\nPattern is a web mining module for the Python programming language. It has tools for data mining, natural language processing, machine learning, network analysis and canvas visualization.\n\nPattern由比利时安特卫普大学CLiPS实验室出品,客观的说,Pattern不仅仅是一套文本处理工具,它更是一套web数据挖掘工具,囊括了数据抓取模块(包括Google, Twitter, 维基百科的API,以及爬虫和HTML分析器),文本处理模块(词性标注,情感分析等),机器学习模块(VSM, 聚类,SVM)以及可视化模块等,可以说,Pattern的这一整套逻辑也是这篇文章的组织逻辑. 使用的是它的英文处理模块Pattern.en, 有很多很不错的文本处理功能,包括基础的tokenize, 词性标注,句子切分,语法检查,拼写纠错,情感分析,句法分析等,相当不错。\n\n[官网](http://www.clips.ua.ac.be/pattern)\n\n### 3,TextBlob: Simplified Text Processing\n\nTextBlob is a Python library for processing textual data. It provides a simple API for diving into common natural language processing(NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.\n\nTextBlob是一个很有意思的Python文本处理工具包,它其实是基于上面两个Python工具包NLKT和Pattern做了封装(TextBlob stands on the giant shoulders of NLTK and pattern, and plays nicely with both),同时提供了很多文本处理功能的接口,包括词性标注,名词短语提取,情感分析,文本分类,拼写检查等,甚至包括翻译和语言检测,不过这个是基于Google的API的,有调用次数限制。TextBlob相对比较年轻,有兴趣的同学可以关注。\n\n[官网](http://textblob.readthedocs.org/en/dev/),[Github](https://github.com/sloria/textblob)\n\n### 4,MBSP for Python\n\nMBSP is a text analysis system based on the TiMBL and MBT memory based learning applications developed at CLiPS and ILK. It provides tools for Tokenization and Sentence Splitting, Part of Speech Tagging, Chunking, Lemmatization, Relation Finding and Prepositional Phrase Attachment.\n\nMBSP与Pattern同源,同出自比利时安特卫普大学CLiPS实验室,提供了Word Tokenization, 句子切分,词性标注,Chunking, Lemmatization,句法分析等基本的文本处理功能,感兴趣的同学可以关注。\n\n[官网](http://www.clips.ua.ac.be/pages/MBSP)\n\n### 5,Gensim: Topic modeling for humans\n\nGensim是一个相当专业的Python包,无论是代码还是文档。\n\n[官网](http://radimrehurek.com/gensim/index.html),[Github](https://github.com/piskvorky/gensim)\n\n### 6,langid.py: Stand-alone language identification system\n\n语言检测是一个很有意思的话题,不过相对比较成熟,这方面的解决方案很多,也有很多不错的开源工具包,不过对于Python来说。langid目前支持97种语言的检测,提供了很多易用的功能,包括可以启动一个建议的server,通过json调用其API,可定制训练自己的语言检测模型等,可以说是“麻雀虽小,五脏俱全”。\n\n[Github](https://github.com/saffsd/langid.py)\n\n### 7,Jieba: 结巴中文分词\n\n结巴分词,其功能包括支持三种分词模式(精确模式、全模式、搜索引擎模式),支持繁体分词,支持自定义词典等,是目前一个非常不错的Python中文分词解决方案。\n\n[Github](https://github.com/fxsjy/jieba)\n\n## 三、Python科学计算工具包\n\nMATLAB = NumPy+SciPy+Matplotlib+iPython\n\n《Python科学计算》\n\n### 1,NumPy\n\nNumPy几乎是一个无法回避的科学计算工具包,最常用的也许是它的N维数组对象,其他还包括一些成熟的函数库,用于整合C/C++和Fortran代码的工具包,线性代数、傅里叶变换和随机数生成函数等。NumPy提供了两种基本的对象:ndarray(N-dimensional array object)和 ufunc(universal function object)。ndarray是存储单一数据类型的多维数组,而ufunc则是能够对数组进行处理的函数。\n\n[官网](http://www.numpy.org/)\n\n### 2,SciPy: Scientific Computing Tools for Python\n\nSciPy是一个开源的Python算法库和数学工具包,SciPy包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。其功能与软件MATLAB、Scilab和GNU Octave类似。 Numpy和Scipy常常结合着使用,Python大多数机器学习库都依赖于这两个模块。”—-引用自“Python机器学习库”\n\n[官网](http://www.scipy.org/)\n\n### 3,Matplotlib\n\nmatplotlib is a python 2D plotting library which produces publication quality figures in a variety of hardcopy formats and interactive environments across platforms.\n\n[官网](http://matplotlib.org/)\n\n### 4,iPython\n\n“iPython 是一个Python 的交互式Shell,比默认的Python Shell 好用得多,功能也更强大。 她支持语法高亮、自动完成、代码调试、对象自省,支持 Bash Shell 命令,内置了许多很有用的功能和函式等,非常容易使用。 ” 启动iPython的时候用这个命令“ipython –pylab”,默认开启了matploblib的绘图交互,用起来很方便。\n\n[官网](http://ipython.org/)\n\n## 四、Python 机器学习、数据挖掘\n\n### 1,scikit-learn: Machine Learning in Python\n\nscikit-learn is an open source machine learning library for the python programming language. It features various classification, regression and clustering algorithms including support vector machines, logistic regression, naive Bayes, random forests, gradient boosting, k-meams and DBSCAN is designed to interoperate with the python numerical and scientific libraries NumPy and SciPy.\n\nscikit-learn是一个基于NumPy,SciPy, Matplotlib的开源机器学习工具包,主要涵盖分类,回归和聚类算法,例如SVM,逻辑回归,朴素贝叶斯,随机森林,k-means等算法,代码和文档都非常不错,在许多Python项目中都有应用。\n\n[官网](http://scikit-learn.org)\n\n### 2,Pandas: Python Data Analysis Library\n\nPandas is a software library written for the Python programming language for data manipulation and analysis. In particular, it offers data structures and operations for manipulating numerical tables and time series.\n\nPandas也是基于NumPy和Matplotlib开发的,主要用于数据分析和数据可视化,它的数据结构DataFrame和R语言里的data.frame很像,特别是对于时间序列数据有自己的一套分析机制,非常不错。这里推荐一本书《Python for Data Analysis》,作者是Pandas的主力开发,依次介绍了iPython, NumPy, Pandas里的相关功能,数据可视化,数据清洗和加工,时间数据处理等,案例包括金融股票数据挖掘等,相当不错。\n\n[官网](http://pandas.pydata.org/)\n\n### 3,mlpy\n\nmlpy is a Python module for Machine Learning built on top of NumPy/SciPy and the GNU Scientific Libraries.\n\nmlpy provide a wide range of state-of-the-art machine learning methods for supervised and unsupervised problems and it is aimed at finding a reasonable compromise among modularity, maintainability, reproducibility, usability and efficiency. mlpy is multiplatform, it is Open Source, distributed under the GNU General Public License version 3.\n\n[官网](http://mlpy.sourceforge.net/)\n\n### 4,MDP:The Modular toolkit for Data Processing\n\nModular toolkit for Data Processing (MDP) is a Python data processing framework.\nFrom the user’s perspective, MDP is a collection of supervised and unsupervised learning algorithms and other data processing units that can be combined into data processing sequences and more complex feed-forward network architectures.\nFrom the scientific developer’s perspective, MDP is a modular framework, which can easily be expanded. The implementation of new algorithms is easy and intuitive. The new implemented units are then automatically integrated with the rest of the library.\nThe base of available algorithms is steadily increasing and includes signal processing methods (Principal Component Analysis, Independent Component Analysis, Slow Feature Analysis), manifold learning methods ([Hessian] Locally Linear Embedding), several classifiers, probabilistic methods (Factor Analysis, RBM), data pre-processing methods, and many others.\n\n[官网](http://mdp-toolkit.sourceforge.net/)\n\n### 5,PyBrain\n\nPyBrain is a modular Machine Learning Library for Python. Its goal is to offer flexible, easy-to-use yet still powerful algorithms for Machine Learning Tasks and a variety of predefined environments to test and compare your algorithms.\n\nPyBrain is short for Python-Based Reinforcement Learning, Artificial Intelligence and Neural Network Library. In fact, we came up with the name first and later reverse-engineered this quite descriptive “Backronym”.\n\nPyBrain正如其名,包括神经网络、强化学习(及二者结合)、无监督学习、进化算法。因为目前的许多问题需要处理连续态和行为空间,必须使用函数逼近(如神经网络)以应对高维数据。PyBrain以神经网络为核心,所有的训练方法都以神经网络为一个实例。\n\n[官网](http://www.pybrain.org/)\n\n### 6,PyML-machine Learning in Python\n\n“PyML是一个Python机器学习工具包,为各分类和回归方法提供灵活的架构。它主要提供特征选择、模型选择、组合分类器、分类评估等功能。”\n\n[官网](http://pyml.sourceforge.net/)\n\n### 7,Milk: Machine learning toolkit in Python\n\nIts focus is on supervised classification with several classifiers available: SVMs (based on libsvm), k-NN, random forests, decision trees. It also performs feature selection. These classifiers can be combined in many ways to form different classification systems.\n\n[官网](http://luispedro.org/software/milk)\n\n### 8,PyMVPA:MulitVariate Pattern Analysis(MVPA) in Python\n\nPyMVPA is a Python package intended to ease statistical learning analyses of large datasets. It offers an extensible framework with a high-level interface to a broad range of algorithms for classification, regression, feature selection, data import and export. It is designed to integrate well with related software packages, such as scikit-learn, and MDP. While it is not limited to the neuroimaging domain, it is eminently suited for such datasets. PyMVPA is free software and requires nothing but free-software to run.\n\n[官网](http://www.pymvpa.org/)\n\n### 9,Pyrallel-Parallel Data Analytics in Python\n\n“Pyrallel(Parallel Data Analytics in Python)基于分布式计算模式的机器学习和半交互式的试验项目,可在小型集群上运行”\n\n[Github](http://github.com/pydata/pyrallel)\n\n### 10,Monte - gradient based learning in Python\n\n“Monte (machine learning in pure Python)是一个纯Python机器学习库。它可以迅速构建神经网络、条件随机场、逻辑回归等模型,使用inline-C优化,极易使用和扩展。”\n\n[官网](http://montepython.sourceforge.net)\n\n### 11,Theano\n\n“Theano 是一个 Python 库,用来定义、优化和模拟数学表达式计算,用于高效的解决多维数组的计算问题。Theano的特点:紧密集成Numpy;高效的数据密集型GPU计算;高效的符号微分运算;高速和稳定的优化;动态生成c代码;广泛的单元测试和自我验证。自2007年以来,Theano已被广泛应用于科学运算。theano使得构建深度学习模型更加容易,可以快速实现多种模型。\n\n[官网](http://deeplearning.net/software/theano/),[Github](https://github.com/Theano/Theano)\n\n### 12,Pylearn2\n\n“Pylearn2建立在theano上,部分依赖scikit-learn上,目前Pylearn2正处于开发中,将可以处理向量、图像、视频等数据,提供MLP、RBM、SDA等深度学习模型。\n\n[官网](http://deeplearning.net/software/pylearn2/)","source":"_posts/Python 工具总结.md","raw":"title: Python 工具总结\ntags:\n - 科学计算\n - 网络爬虫\n - 全栈工程师\n - 数据挖掘\n - 文本处理\n - 机器学习\nid: 29\ncategories:\n - Python\ndate: 2015-04-21 02:08:57\n---\n\n## 一、Python网页爬虫工具集\n\n自己动手获取数据\n\n### 1,Scrapy\n\nScrapy, a fast high-level screen scraping and web crawling framework for Python.\n\n《Scrapy轻松定制网络爬虫》\n\n[官网](http://scrapy.org/),[Github代码](https://github.com/scrapy/scrapy)\n\n### 2,Beautiful Soup\n\nYou didn't write that awful page. You're just trying to get some data out of it. Beautiful Soup is here to help. Since 2004, it's been saving programmers hours or days of week on quick-turnaround screen scraping projects.\n\n配合urllib使用,数据分析,清洗和获取的工具\n\n[官网](http://www.crummy.com/software/BeautifulSoup/)\n\n### 3,Python-Goose\n\nHtml Content/Article Extractor, web scrapping lib in Python\n\nGoose最早是用Java写,现在用Scala重写,是一个Scala项目,Python-Goose用Python重写,依赖于Beautiful Soup。\n\n[Github](https://github.com/grangier/python-goose)地址\n\n## 二、Python文本处理工具集\n\n网页爬取数据之后进行基本的文本处理,譬如对于英文来说要最基本的tokenize,对于中文,则需要中文分词,进一步的话,词性标注,句法分析,关键词提取,文本分类,情感分析。\n\n### 1,NLTK-Natural Language Toolkit\n\nNLTK is a leading platform for building Python programs to work with human language data. It provide easy-to-use interface to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic, reasoning, and an active discussion forum.\n\n《Natural Language Processing with Python》 《Python Text Processing with NLTK 2.0 Cookbook》\n\n[官网](http://www.nltk.org/),[Github](https://github.com/nltk/nltk)\n\n### 2,Pattern\n\nPattern is a web mining module for the Python programming language. It has tools for data mining, natural language processing, machine learning, network analysis and canvas visualization.\n\nPattern由比利时安特卫普大学CLiPS实验室出品,客观的说,Pattern不仅仅是一套文本处理工具,它更是一套web数据挖掘工具,囊括了数据抓取模块(包括Google, Twitter, 维基百科的API,以及爬虫和HTML分析器),文本处理模块(词性标注,情感分析等),机器学习模块(VSM, 聚类,SVM)以及可视化模块等,可以说,Pattern的这一整套逻辑也是这篇文章的组织逻辑. 使用的是它的英文处理模块Pattern.en, 有很多很不错的文本处理功能,包括基础的tokenize, 词性标注,句子切分,语法检查,拼写纠错,情感分析,句法分析等,相当不错。\n\n[官网](http://www.clips.ua.ac.be/pattern)\n\n### 3,TextBlob: Simplified Text Processing\n\nTextBlob is a Python library for processing textual data. It provides a simple API for diving into common natural language processing(NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.\n\nTextBlob是一个很有意思的Python文本处理工具包,它其实是基于上面两个Python工具包NLKT和Pattern做了封装(TextBlob stands on the giant shoulders of NLTK and pattern, and plays nicely with both),同时提供了很多文本处理功能的接口,包括词性标注,名词短语提取,情感分析,文本分类,拼写检查等,甚至包括翻译和语言检测,不过这个是基于Google的API的,有调用次数限制。TextBlob相对比较年轻,有兴趣的同学可以关注。\n\n[官网](http://textblob.readthedocs.org/en/dev/),[Github](https://github.com/sloria/textblob)\n\n### 4,MBSP for Python\n\nMBSP is a text analysis system based on the TiMBL and MBT memory based learning applications developed at CLiPS and ILK. It provides tools for Tokenization and Sentence Splitting, Part of Speech Tagging, Chunking, Lemmatization, Relation Finding and Prepositional Phrase Attachment.\n\nMBSP与Pattern同源,同出自比利时安特卫普大学CLiPS实验室,提供了Word Tokenization, 句子切分,词性标注,Chunking, Lemmatization,句法分析等基本的文本处理功能,感兴趣的同学可以关注。\n\n[官网](http://www.clips.ua.ac.be/pages/MBSP)\n\n### 5,Gensim: Topic modeling for humans\n\nGensim是一个相当专业的Python包,无论是代码还是文档。\n\n[官网](http://radimrehurek.com/gensim/index.html),[Github](https://github.com/piskvorky/gensim)\n\n### 6,langid.py: Stand-alone language identification system\n\n语言检测是一个很有意思的话题,不过相对比较成熟,这方面的解决方案很多,也有很多不错的开源工具包,不过对于Python来说。langid目前支持97种语言的检测,提供了很多易用的功能,包括可以启动一个建议的server,通过json调用其API,可定制训练自己的语言检测模型等,可以说是“麻雀虽小,五脏俱全”。\n\n[Github](https://github.com/saffsd/langid.py)\n\n### 7,Jieba: 结巴中文分词\n\n结巴分词,其功能包括支持三种分词模式(精确模式、全模式、搜索引擎模式),支持繁体分词,支持自定义词典等,是目前一个非常不错的Python中文分词解决方案。\n\n[Github](https://github.com/fxsjy/jieba)\n\n## 三、Python科学计算工具包\n\nMATLAB = NumPy+SciPy+Matplotlib+iPython\n\n《Python科学计算》\n\n### 1,NumPy\n\nNumPy几乎是一个无法回避的科学计算工具包,最常用的也许是它的N维数组对象,其他还包括一些成熟的函数库,用于整合C/C++和Fortran代码的工具包,线性代数、傅里叶变换和随机数生成函数等。NumPy提供了两种基本的对象:ndarray(N-dimensional array object)和 ufunc(universal function object)。ndarray是存储单一数据类型的多维数组,而ufunc则是能够对数组进行处理的函数。\n\n[官网](http://www.numpy.org/)\n\n### 2,SciPy: Scientific Computing Tools for Python\n\nSciPy是一个开源的Python算法库和数学工具包,SciPy包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。其功能与软件MATLAB、Scilab和GNU Octave类似。 Numpy和Scipy常常结合着使用,Python大多数机器学习库都依赖于这两个模块。”—-引用自“Python机器学习库”\n\n[官网](http://www.scipy.org/)\n\n### 3,Matplotlib\n\nmatplotlib is a python 2D plotting library which produces publication quality figures in a variety of hardcopy formats and interactive environments across platforms.\n\n[官网](http://matplotlib.org/)\n\n### 4,iPython\n\n“iPython 是一个Python 的交互式Shell,比默认的Python Shell 好用得多,功能也更强大。 她支持语法高亮、自动完成、代码调试、对象自省,支持 Bash Shell 命令,内置了许多很有用的功能和函式等,非常容易使用。 ” 启动iPython的时候用这个命令“ipython –pylab”,默认开启了matploblib的绘图交互,用起来很方便。\n\n[官网](http://ipython.org/)\n\n## 四、Python 机器学习、数据挖掘\n\n### 1,scikit-learn: Machine Learning in Python\n\nscikit-learn is an open source machine learning library for the python programming language. It features various classification, regression and clustering algorithms including support vector machines, logistic regression, naive Bayes, random forests, gradient boosting, k-meams and DBSCAN is designed to interoperate with the python numerical and scientific libraries NumPy and SciPy.\n\nscikit-learn是一个基于NumPy,SciPy, Matplotlib的开源机器学习工具包,主要涵盖分类,回归和聚类算法,例如SVM,逻辑回归,朴素贝叶斯,随机森林,k-means等算法,代码和文档都非常不错,在许多Python项目中都有应用。\n\n[官网](http://scikit-learn.org)\n\n### 2,Pandas: Python Data Analysis Library\n\nPandas is a software library written for the Python programming language for data manipulation and analysis. In particular, it offers data structures and operations for manipulating numerical tables and time series.\n\nPandas也是基于NumPy和Matplotlib开发的,主要用于数据分析和数据可视化,它的数据结构DataFrame和R语言里的data.frame很像,特别是对于时间序列数据有自己的一套分析机制,非常不错。这里推荐一本书《Python for Data Analysis》,作者是Pandas的主力开发,依次介绍了iPython, NumPy, Pandas里的相关功能,数据可视化,数据清洗和加工,时间数据处理等,案例包括金融股票数据挖掘等,相当不错。\n\n[官网](http://pandas.pydata.org/)\n\n### 3,mlpy\n\nmlpy is a Python module for Machine Learning built on top of NumPy/SciPy and the GNU Scientific Libraries.\n\nmlpy provide a wide range of state-of-the-art machine learning methods for supervised and unsupervised problems and it is aimed at finding a reasonable compromise among modularity, maintainability, reproducibility, usability and efficiency. mlpy is multiplatform, it is Open Source, distributed under the GNU General Public License version 3.\n\n[官网](http://mlpy.sourceforge.net/)\n\n### 4,MDP:The Modular toolkit for Data Processing\n\nModular toolkit for Data Processing (MDP) is a Python data processing framework.\nFrom the user’s perspective, MDP is a collection of supervised and unsupervised learning algorithms and other data processing units that can be combined into data processing sequences and more complex feed-forward network architectures.\nFrom the scientific developer’s perspective, MDP is a modular framework, which can easily be expanded. The implementation of new algorithms is easy and intuitive. The new implemented units are then automatically integrated with the rest of the library.\nThe base of available algorithms is steadily increasing and includes signal processing methods (Principal Component Analysis, Independent Component Analysis, Slow Feature Analysis), manifold learning methods ([Hessian] Locally Linear Embedding), several classifiers, probabilistic methods (Factor Analysis, RBM), data pre-processing methods, and many others.\n\n[官网](http://mdp-toolkit.sourceforge.net/)\n\n### 5,PyBrain\n\nPyBrain is a modular Machine Learning Library for Python. Its goal is to offer flexible, easy-to-use yet still powerful algorithms for Machine Learning Tasks and a variety of predefined environments to test and compare your algorithms.\n\nPyBrain is short for Python-Based Reinforcement Learning, Artificial Intelligence and Neural Network Library. In fact, we came up with the name first and later reverse-engineered this quite descriptive “Backronym”.\n\nPyBrain正如其名,包括神经网络、强化学习(及二者结合)、无监督学习、进化算法。因为目前的许多问题需要处理连续态和行为空间,必须使用函数逼近(如神经网络)以应对高维数据。PyBrain以神经网络为核心,所有的训练方法都以神经网络为一个实例。\n\n[官网](http://www.pybrain.org/)\n\n### 6,PyML-machine Learning in Python\n\n“PyML是一个Python机器学习工具包,为各分类和回归方法提供灵活的架构。它主要提供特征选择、模型选择、组合分类器、分类评估等功能。”\n\n[官网](http://pyml.sourceforge.net/)\n\n### 7,Milk: Machine learning toolkit in Python\n\nIts focus is on supervised classification with several classifiers available: SVMs (based on libsvm), k-NN, random forests, decision trees. It also performs feature selection. These classifiers can be combined in many ways to form different classification systems.\n\n[官网](http://luispedro.org/software/milk)\n\n### 8,PyMVPA:MulitVariate Pattern Analysis(MVPA) in Python\n\nPyMVPA is a Python package intended to ease statistical learning analyses of large datasets. It offers an extensible framework with a high-level interface to a broad range of algorithms for classification, regression, feature selection, data import and export. It is designed to integrate well with related software packages, such as scikit-learn, and MDP. While it is not limited to the neuroimaging domain, it is eminently suited for such datasets. PyMVPA is free software and requires nothing but free-software to run.\n\n[官网](http://www.pymvpa.org/)\n\n### 9,Pyrallel-Parallel Data Analytics in Python\n\n“Pyrallel(Parallel Data Analytics in Python)基于分布式计算模式的机器学习和半交互式的试验项目,可在小型集群上运行”\n\n[Github](http://github.com/pydata/pyrallel)\n\n### 10,Monte - gradient based learning in Python\n\n“Monte (machine learning in pure Python)是一个纯Python机器学习库。它可以迅速构建神经网络、条件随机场、逻辑回归等模型,使用inline-C优化,极易使用和扩展。”\n\n[官网](http://montepython.sourceforge.net)\n\n### 11,Theano\n\n“Theano 是一个 Python 库,用来定义、优化和模拟数学表达式计算,用于高效的解决多维数组的计算问题。Theano的特点:紧密集成Numpy;高效的数据密集型GPU计算;高效的符号微分运算;高速和稳定的优化;动态生成c代码;广泛的单元测试和自我验证。自2007年以来,Theano已被广泛应用于科学运算。theano使得构建深度学习模型更加容易,可以快速实现多种模型。\n\n[官网](http://deeplearning.net/software/theano/),[Github](https://github.com/Theano/Theano)\n\n### 12,Pylearn2\n\n“Pylearn2建立在theano上,部分依赖scikit-learn上,目前Pylearn2正处于开发中,将可以处理向量、图像、视频等数据,提供MLP、RBM、SDA等深度学习模型。\n\n[官网](http://deeplearning.net/software/pylearn2/)","slug":"Python 工具总结","published":1,"updated":"2015-12-02T04:39:35.623Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153yb004tc0tjmze0mv4g"},{"title":"Path ClassPath 的区别","id":"206","date":"2015-05-15T04:24:25.000Z","_content":"\nClassNotFoundException(所需要的支持类库放错了地方,并没有放在类路径CLASSPATH里面)\n\nNoClassDefFoundError(运行函数没有放在path中).\n\n**1.path的作用**\n\n** ** path是系统用来指定可执行文件的完整路径,即使不在path中设置JDK的路径也可执行JAVA文件,但必须把完整的路径写出来,如C:\\Program Files\\Java\\jdk1.6.0_10\\bin\\javac TheClass.java。path是用来搜索所执行的可执行文件路径的,如果执行的可执行文件不在当前目录下,那就会依次搜索path中设置的路径;而java的各种操作命令是在其安装路径中的bin目录下,所以在path中设置了JDK的安装目录后就不用再把java文件的完整路径写出来了,它会自动去path中设置的路径中去找;\n\n**2.classpath的作用**\n\n** **classpath是指定你在程序中所使用的类(.class)文件所在的位置,就如在引入一个类时:import javax.swing.JTable这句话是告诉编译器要引入javax.swing这个包下的JTable类,而classpath就是告诉编译器该到哪里去找到这个类(前提是你在classpath中设置了这个类的路径);如果你想要编译在当前目录下找,就加上“.”,如:.;C:\\Program Files\\Java\\jdk\\,这样编译器就会到当前目录和C:\\Program Files\\Java\\jdk\\去找javax.swing.JTable这个类;还提下:大多数人都是用Eclipse写程序,不设classpath也没关系,因为Eclipse有相关的配置;\n\npath是os用\nclasspath java用\npath里面不光有Java的bin,还可以包含许多其他的,tc啊,masm阿,只要在path中设了这些环境的路径,你在dos下的任何路径上都可以调用这些路径下的命令。\nclasspath是java专用的查找类的路径\n\n系统变量是环境变量的一种,环境变量一种仅本用户适用,另一种即系统变量整个系统的用户都适用,两者都可以在使用应用程序时提供快捷.一般在编辑java文件或者C#文件时需要修改,设计到多个文件夹之间的切换时也可以根据自己的需要设置.\n简单的说就是,如果设置系统变量和用户变量,都叫做设置环境变量,设置系统变量时,该系统的所有帐号的用户都可以使用,但是设置用户变量时,其他的帐号登陆时就不一定可以使用。\n\n下面以java环境变量为例设置方法:\n1、如果是Win95/98,在\\autoexec.bat的最后面添加如下3行语句:\nJAVA_HOME=c:\\j2sdk1.4.1\nPATH=%JAVA_HOME%\\bin;%PATH%\nCLASSPATH=.;%JAVA_HOME%\\lib\n看好了CLASSPATH中第一个\".\",这个代表当前目录,很多人HelloWorld没有运行起来大多是这个原因。\n\n2、如果是Win2000或者XP,使用鼠标右击\"我的电脑\"->属性->高级->环境变量\n系统变量->新建->变量名:JAVA_HOME 变量值:c:\\j2sdk1.4.1\n系统变量->新建->变量名:CLASSPATH 变量值:.;%JAVA_HOME%\\lib\n系统变量->编辑->变量名:Path 在变量值的最前面加上:%JAVA_HOME%\\bin;\nCLASSPATH前面的那个\".\"和上面的意义是一样的。\n\n3、如果是Linux用户\n在你的环境中,通常我加在.bashrc文件中,你可以加在你的Profile文件中。\n/usr/local/jdk 为你安装jdk的目录。\nexport JAVA_HOME=/usr/local/jdk\nexport CLASSPATH=.:$JAVA_HOME/lib\nexport PATH=$PATH:$JAVA_HOME/bin","source":"_posts/Path ClassPath 的区别.md","raw":"title: Path ClassPath 的区别\ntags:\n - Classpath\n - Path\nid: 206\ncategories:\n - Java\ndate: 2015-05-15 12:24:25\n---\n\nClassNotFoundException(所需要的支持类库放错了地方,并没有放在类路径CLASSPATH里面)\n\nNoClassDefFoundError(运行函数没有放在path中).\n\n**1.path的作用**\n\n** ** path是系统用来指定可执行文件的完整路径,即使不在path中设置JDK的路径也可执行JAVA文件,但必须把完整的路径写出来,如C:\\Program Files\\Java\\jdk1.6.0_10\\bin\\javac TheClass.java。path是用来搜索所执行的可执行文件路径的,如果执行的可执行文件不在当前目录下,那就会依次搜索path中设置的路径;而java的各种操作命令是在其安装路径中的bin目录下,所以在path中设置了JDK的安装目录后就不用再把java文件的完整路径写出来了,它会自动去path中设置的路径中去找;\n\n**2.classpath的作用**\n\n** **classpath是指定你在程序中所使用的类(.class)文件所在的位置,就如在引入一个类时:import javax.swing.JTable这句话是告诉编译器要引入javax.swing这个包下的JTable类,而classpath就是告诉编译器该到哪里去找到这个类(前提是你在classpath中设置了这个类的路径);如果你想要编译在当前目录下找,就加上“.”,如:.;C:\\Program Files\\Java\\jdk\\,这样编译器就会到当前目录和C:\\Program Files\\Java\\jdk\\去找javax.swing.JTable这个类;还提下:大多数人都是用Eclipse写程序,不设classpath也没关系,因为Eclipse有相关的配置;\n\npath是os用\nclasspath java用\npath里面不光有Java的bin,还可以包含许多其他的,tc啊,masm阿,只要在path中设了这些环境的路径,你在dos下的任何路径上都可以调用这些路径下的命令。\nclasspath是java专用的查找类的路径\n\n系统变量是环境变量的一种,环境变量一种仅本用户适用,另一种即系统变量整个系统的用户都适用,两者都可以在使用应用程序时提供快捷.一般在编辑java文件或者C#文件时需要修改,设计到多个文件夹之间的切换时也可以根据自己的需要设置.\n简单的说就是,如果设置系统变量和用户变量,都叫做设置环境变量,设置系统变量时,该系统的所有帐号的用户都可以使用,但是设置用户变量时,其他的帐号登陆时就不一定可以使用。\n\n下面以java环境变量为例设置方法:\n1、如果是Win95/98,在\\autoexec.bat的最后面添加如下3行语句:\nJAVA_HOME=c:\\j2sdk1.4.1\nPATH=%JAVA_HOME%\\bin;%PATH%\nCLASSPATH=.;%JAVA_HOME%\\lib\n看好了CLASSPATH中第一个\".\",这个代表当前目录,很多人HelloWorld没有运行起来大多是这个原因。\n\n2、如果是Win2000或者XP,使用鼠标右击\"我的电脑\"->属性->高级->环境变量\n系统变量->新建->变量名:JAVA_HOME 变量值:c:\\j2sdk1.4.1\n系统变量->新建->变量名:CLASSPATH 变量值:.;%JAVA_HOME%\\lib\n系统变量->编辑->变量名:Path 在变量值的最前面加上:%JAVA_HOME%\\bin;\nCLASSPATH前面的那个\".\"和上面的意义是一样的。\n\n3、如果是Linux用户\n在你的环境中,通常我加在.bashrc文件中,你可以加在你的Profile文件中。\n/usr/local/jdk 为你安装jdk的目录。\nexport JAVA_HOME=/usr/local/jdk\nexport CLASSPATH=.:$JAVA_HOME/lib\nexport PATH=$PATH:$JAVA_HOME/bin","slug":"Path ClassPath 的区别","published":1,"updated":"2015-12-02T04:39:35.623Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153yh0056c0tj57sgq6qs"},{"title":"PYTHON YIELD 使用浅析","id":"92","date":"2015-04-26T20:15:54.000Z","_content":"\n<div id=\"dwc-exp-a\" class=\"dw-article-sidebar dw-bluemix\">\n<div id=\"ibm-leadspace-body\">\n\n### [PYTHON YIELD ](http://www.ibm.com/developerworks/cn/opensource/os-cn-python-yield/)\n\n</div>\n<div id=\"dw-summary-area\" class=\"dw-summary-columns\">\n<div class=\"ibm-col-6-4\">\n\n初学 Python 的开发者经常会发现很多 Python 函数中用到了 yield 关键字,然而,带有 yield 的函数执行流程却和普通函数不一样,yield 到底用来做什么,为什么要设计 yield ?本文将由浅入深地讲解 yield 的概念和用法,帮助读者体会 Python 里 yield 简单而强大的功能。\n\n</div>\n</div>\n</div>\n您可能听说过,带有 yield 的函数在 Python 中被称之为 generator(生成器),何谓 generator ?\n\n我们先抛开 generator,以一个常见的编程题目来展示 yield 的概念。\n\n## 如何生成斐波那契數列\n\n斐波那契(Fibonacci)數列是一个非常简单的递归数列,除第一个和第二个数外,任意一个数都可由前两个数相加得到。用计算机程序输出斐波那契數列的前 N 个数是一个非常简单的问题,许多初学者都可以轻易写出如下函数:\n\n##### 清单 1\\. 简单输出斐波那契數列前 N 个数\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> def fab(max): \n n, a, b = 0, 0, 1 \n while n < max: \n print b \n a, b = b, a + b \n n = n + 1</pre>\n</div>\n执行 fab(5),我们可以得到如下输出:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> fab(5) \n 1 \n 1 \n 2 \n 3 \n 5</pre>\n</div>\n结果没有问题,但有经验的开发者会指出,直接在 fab 函数中用 print 打印数字会导致该函数可复用性较差,因为 fab 函数返回 None,其他函数无法获得该函数生成的数列。\n\n要提高 fab 函数的可复用性,最好不要直接打印出数列,而是返回一个 List。以下是 fab 函数改写后的第二个版本:\n\n##### 清单 2\\. 输出斐波那契數列前 N 个数第二版\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> def fab(max): \n n, a, b = 0, 0, 1 \n L = [] \n while n < max: \n L.append(b) \n a, b = b, a + b \n n = n + 1 \n return L</pre>\n</div>\n可以使用如下方式打印出 fab 函数返回的 List:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> for n in fab(5): \n ... print n \n ... \n 1 \n 1 \n 2 \n 3 \n 5</pre>\n</div>\n改写后的 fab 函数通过返回 List 能满足复用性的要求,但是更有经验的开发者会指出,该函数在运行中占用的内存会随着参数 max 的增大而增大,如果要控制内存占用,最好不要用 List\n\n来保存中间结果,而是通过 iterable 对象来迭代。例如,在 Python2.x 中,代码:\n\n##### 清单 3\\. 通过 iterable 对象来迭代\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> for i in range(1000): pass</pre>\n</div>\n会导致生成一个 1000 个元素的 List,而代码:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> for i in xrange(1000): pass</pre>\n</div>\n则不会生成一个 1000 个元素的 List,而是在每次迭代中返回下一个数值,内存空间占用很小。因为 xrange 不返回 List,而是返回一个 iterable 对象。\n\n利用 iterable 我们可以把 fab 函数改写为一个支持 iterable 的 class,以下是第三个版本的 Fab:\n\n##### 清单 4\\. 第三个版本\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> class Fab(object): \n\n def __init__(self, max): \n self.max = max \n self.n, self.a, self.b = 0, 0, 1 \n\n def __iter__(self): \n return self \n\n def next(self): \n if self.n < self.max: \n r = self.b \n self.a, self.b = self.b, self.a + self.b \n self.n = self.n + 1 \n return r \n raise StopIteration()</pre>\n</div>\nFab 类通过 next() 不断返回数列的下一个数,内存占用始终为常数:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> for n in Fab(5): \n ... print n \n ... \n 1 \n 1 \n 2 \n 3 \n 5</pre>\n</div>\n然而,使用 class 改写的这个版本,代码远远没有第一版的 fab 函数来得简洁。如果我们想要保持第一版 fab 函数的简洁性,同时又要获得 iterable 的效果,yield 就派上用场了:\n\n##### 清单 5\\. 使用 yield 的第四版\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> def fab(max): \n n, a, b = 0, 0, 1 \n while n < max: \n yield b \n # print b \n a, b = b, a + b \n n = n + 1 \n\n'''</pre>\n</div>\n第四个版本的 fab 和第一版相比,仅仅把 print b 改为了 yield b,就在保持简洁性的同时获得了 iterable 的效果。\n\n调用第四版的 fab 和第二版的 fab 完全一致:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> for n in fab(5): \n ... print n \n ... \n 1 \n 1 \n 2 \n 3 \n 5</pre>\n</div>\n简单地讲,yield 的作用就是把一个函数变成一个 generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator,调用 fab(5) 不会执行 fab 函数,而是返回一个 iterable 对象!在 for 循环执行时,每次循环都会执行 fab 函数内部的代码,执行到 yield b 时,fab 函数就返回一个迭代值,下次迭代时,代码从 yield b 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到 yield。\n\n也可以手动调用 fab(5) 的 next() 方法(因为 fab(5) 是一个 generator 对象,该对象具有 next() 方法),这样我们就可以更清楚地看到 fab 的执行流程:\n\n##### 清单 6\\. 执行流程\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> f = fab(5) \n >>> f.next() \n 1 \n >>> f.next() \n 1 \n >>> f.next() \n 2 \n >>> f.next() \n 3 \n >>> f.next() \n 5 \n >>> f.next() \n Traceback (most recent call last): \n File \"<stdin>\", line 1, in <module> \n StopIteration</pre>\n</div>\n当函数执行结束时,generator 自动抛出 StopIteration 异常,表示迭代完成。在 for 循环里,无需处理 StopIteration 异常,循环会正常结束。\n\n我们可以得出以下结论:\n\n一个带有 yield 的函数就是一个 generator,它和普通函数不同,生成一个 generator 看起来像函数调用,但不会执行任何函数代码,直到对其调用 next()(在 for 循环中会自动调用 next())才开始执行。虽然执行流程仍按函数的流程执行,但每执行到一个 yield 语句就会中断,并返回一个迭代值,下次执行时从 yield 的下一个语句继续执行。看起来就好像一个函数在正常执行的过程中被 yield 中断了数次,每次中断都会通过 yield 返回当前的迭代值。\n\nyield 的好处是显而易见的,把一个函数改写为一个 generator 就获得了迭代能力,比起用类的实例保存状态来计算下一个 next() 的值,不仅代码简洁,而且执行流程异常清晰。\n\n如何判断一个函数是否是一个特殊的 generator 函数?可以利用 isgeneratorfunction 判断:\n\n##### 清单 7\\. 使用 isgeneratorfunction 判断\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> from inspect import isgeneratorfunction \n >>> isgeneratorfunction(fab) \n True</pre>\n</div>\n要注意区分 fab 和 fab(5),fab 是一个 generator function,而 fab(5) 是调用 fab 返回的一个 generator,好比类的定义和类的实例的区别:\n\n##### 清单 8\\. 类的定义和类的实例\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> import types \n >>> isinstance(fab, types.GeneratorType) \n False \n >>> isinstance(fab(5), types.GeneratorType) \n True</pre>\n</div>\nfab 是无法迭代的,而 fab(5) 是可迭代的:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> from collections import Iterable \n >>> isinstance(fab, Iterable) \n False \n >>> isinstance(fab(5), Iterable) \n True</pre>\n</div>\n每次调用 fab 函数都会生成一个新的 generator 实例,各实例互不影响:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> f1 = fab(3) \n >>> f2 = fab(5) \n >>> print 'f1:', f1.next() \n f1: 1 \n >>> print 'f2:', f2.next() \n f2: 1 \n >>> print 'f1:', f1.next() \n f1: 1 \n >>> print 'f2:', f2.next() \n f2: 1 \n >>> print 'f1:', f1.next() \n f1: 2 \n >>> print 'f2:', f2.next() \n f2: 2 \n >>> print 'f2:', f2.next() \n f2: 3 \n >>> print 'f2:', f2.next() \n f2: 5</pre>\n</div>\n<div class=\"ibm-alternate-rule\"></div>\n\n[回页首](http://www.ibm.com/developerworks/cn/opensource/os-cn-python-yield/#ibm-pcon)\n\n## return 的作用\n\n在一个 generator function 中,如果没有 return,则默认执行至函数完毕,如果在执行过程中 return,则直接抛出 StopIteration 终止迭代。\n<div class=\"ibm-alternate-rule\"></div>\n\n[回页首](http://www.ibm.com/developerworks/cn/opensource/os-cn-python-yield/#ibm-pcon)\n\n## 另一个例子\n\n另一个 yield 的例子来源于文件读取。如果直接对文件对象调用 read() 方法,会导致不可预测的内存占用。好的方法是利用固定长度的缓冲区来不断读取文件内容。通过 yield,我们不再需要编写读文件的迭代类,就可以轻松实现文件读取:\n\n##### 清单 9\\. 另一个 yield 的例子\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> def read_file(fpath): \n BLOCK_SIZE = 1024 \n with open(fpath, 'rb') as f: \n while True: \n block = f.read(BLOCK_SIZE) \n if block: \n yield block \n else: \n return</pre>\n</div>\n以上仅仅简单介绍了 yield 的基本概念和用法,yield 在 Python 3 中还有更强大的用法,我们会在后续文章中讨论。\n\n注:本文的代码均在 Python 2.7 中调试通过","source":"_posts/PYTHON YIELD 使用浅析.md","raw":"title: PYTHON YIELD 使用浅析\ntags:\n - python yield\n - study\nid: 92\ncategories:\n - Python\ndate: 2015-04-27 04:15:54\n---\n\n<div id=\"dwc-exp-a\" class=\"dw-article-sidebar dw-bluemix\">\n<div id=\"ibm-leadspace-body\">\n\n### [PYTHON YIELD ](http://www.ibm.com/developerworks/cn/opensource/os-cn-python-yield/)\n\n</div>\n<div id=\"dw-summary-area\" class=\"dw-summary-columns\">\n<div class=\"ibm-col-6-4\">\n\n初学 Python 的开发者经常会发现很多 Python 函数中用到了 yield 关键字,然而,带有 yield 的函数执行流程却和普通函数不一样,yield 到底用来做什么,为什么要设计 yield ?本文将由浅入深地讲解 yield 的概念和用法,帮助读者体会 Python 里 yield 简单而强大的功能。\n\n</div>\n</div>\n</div>\n您可能听说过,带有 yield 的函数在 Python 中被称之为 generator(生成器),何谓 generator ?\n\n我们先抛开 generator,以一个常见的编程题目来展示 yield 的概念。\n\n## 如何生成斐波那契數列\n\n斐波那契(Fibonacci)數列是一个非常简单的递归数列,除第一个和第二个数外,任意一个数都可由前两个数相加得到。用计算机程序输出斐波那契數列的前 N 个数是一个非常简单的问题,许多初学者都可以轻易写出如下函数:\n\n##### 清单 1\\. 简单输出斐波那契數列前 N 个数\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> def fab(max): \n n, a, b = 0, 0, 1 \n while n < max: \n print b \n a, b = b, a + b \n n = n + 1</pre>\n</div>\n执行 fab(5),我们可以得到如下输出:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> fab(5) \n 1 \n 1 \n 2 \n 3 \n 5</pre>\n</div>\n结果没有问题,但有经验的开发者会指出,直接在 fab 函数中用 print 打印数字会导致该函数可复用性较差,因为 fab 函数返回 None,其他函数无法获得该函数生成的数列。\n\n要提高 fab 函数的可复用性,最好不要直接打印出数列,而是返回一个 List。以下是 fab 函数改写后的第二个版本:\n\n##### 清单 2\\. 输出斐波那契數列前 N 个数第二版\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> def fab(max): \n n, a, b = 0, 0, 1 \n L = [] \n while n < max: \n L.append(b) \n a, b = b, a + b \n n = n + 1 \n return L</pre>\n</div>\n可以使用如下方式打印出 fab 函数返回的 List:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> for n in fab(5): \n ... print n \n ... \n 1 \n 1 \n 2 \n 3 \n 5</pre>\n</div>\n改写后的 fab 函数通过返回 List 能满足复用性的要求,但是更有经验的开发者会指出,该函数在运行中占用的内存会随着参数 max 的增大而增大,如果要控制内存占用,最好不要用 List\n\n来保存中间结果,而是通过 iterable 对象来迭代。例如,在 Python2.x 中,代码:\n\n##### 清单 3\\. 通过 iterable 对象来迭代\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> for i in range(1000): pass</pre>\n</div>\n会导致生成一个 1000 个元素的 List,而代码:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> for i in xrange(1000): pass</pre>\n</div>\n则不会生成一个 1000 个元素的 List,而是在每次迭代中返回下一个数值,内存空间占用很小。因为 xrange 不返回 List,而是返回一个 iterable 对象。\n\n利用 iterable 我们可以把 fab 函数改写为一个支持 iterable 的 class,以下是第三个版本的 Fab:\n\n##### 清单 4\\. 第三个版本\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> class Fab(object): \n\n def __init__(self, max): \n self.max = max \n self.n, self.a, self.b = 0, 0, 1 \n\n def __iter__(self): \n return self \n\n def next(self): \n if self.n < self.max: \n r = self.b \n self.a, self.b = self.b, self.a + self.b \n self.n = self.n + 1 \n return r \n raise StopIteration()</pre>\n</div>\nFab 类通过 next() 不断返回数列的下一个数,内存占用始终为常数:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> for n in Fab(5): \n ... print n \n ... \n 1 \n 1 \n 2 \n 3 \n 5</pre>\n</div>\n然而,使用 class 改写的这个版本,代码远远没有第一版的 fab 函数来得简洁。如果我们想要保持第一版 fab 函数的简洁性,同时又要获得 iterable 的效果,yield 就派上用场了:\n\n##### 清单 5\\. 使用 yield 的第四版\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> def fab(max): \n n, a, b = 0, 0, 1 \n while n < max: \n yield b \n # print b \n a, b = b, a + b \n n = n + 1 \n\n'''</pre>\n</div>\n第四个版本的 fab 和第一版相比,仅仅把 print b 改为了 yield b,就在保持简洁性的同时获得了 iterable 的效果。\n\n调用第四版的 fab 和第二版的 fab 完全一致:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> for n in fab(5): \n ... print n \n ... \n 1 \n 1 \n 2 \n 3 \n 5</pre>\n</div>\n简单地讲,yield 的作用就是把一个函数变成一个 generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator,调用 fab(5) 不会执行 fab 函数,而是返回一个 iterable 对象!在 for 循环执行时,每次循环都会执行 fab 函数内部的代码,执行到 yield b 时,fab 函数就返回一个迭代值,下次迭代时,代码从 yield b 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到 yield。\n\n也可以手动调用 fab(5) 的 next() 方法(因为 fab(5) 是一个 generator 对象,该对象具有 next() 方法),这样我们就可以更清楚地看到 fab 的执行流程:\n\n##### 清单 6\\. 执行流程\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> f = fab(5) \n >>> f.next() \n 1 \n >>> f.next() \n 1 \n >>> f.next() \n 2 \n >>> f.next() \n 3 \n >>> f.next() \n 5 \n >>> f.next() \n Traceback (most recent call last): \n File \"<stdin>\", line 1, in <module> \n StopIteration</pre>\n</div>\n当函数执行结束时,generator 自动抛出 StopIteration 异常,表示迭代完成。在 for 循环里,无需处理 StopIteration 异常,循环会正常结束。\n\n我们可以得出以下结论:\n\n一个带有 yield 的函数就是一个 generator,它和普通函数不同,生成一个 generator 看起来像函数调用,但不会执行任何函数代码,直到对其调用 next()(在 for 循环中会自动调用 next())才开始执行。虽然执行流程仍按函数的流程执行,但每执行到一个 yield 语句就会中断,并返回一个迭代值,下次执行时从 yield 的下一个语句继续执行。看起来就好像一个函数在正常执行的过程中被 yield 中断了数次,每次中断都会通过 yield 返回当前的迭代值。\n\nyield 的好处是显而易见的,把一个函数改写为一个 generator 就获得了迭代能力,比起用类的实例保存状态来计算下一个 next() 的值,不仅代码简洁,而且执行流程异常清晰。\n\n如何判断一个函数是否是一个特殊的 generator 函数?可以利用 isgeneratorfunction 判断:\n\n##### 清单 7\\. 使用 isgeneratorfunction 判断\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> from inspect import isgeneratorfunction \n >>> isgeneratorfunction(fab) \n True</pre>\n</div>\n要注意区分 fab 和 fab(5),fab 是一个 generator function,而 fab(5) 是调用 fab 返回的一个 generator,好比类的定义和类的实例的区别:\n\n##### 清单 8\\. 类的定义和类的实例\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> import types \n >>> isinstance(fab, types.GeneratorType) \n False \n >>> isinstance(fab(5), types.GeneratorType) \n True</pre>\n</div>\nfab 是无法迭代的,而 fab(5) 是可迭代的:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> from collections import Iterable \n >>> isinstance(fab, Iterable) \n False \n >>> isinstance(fab(5), Iterable) \n True</pre>\n</div>\n每次调用 fab 函数都会生成一个新的 generator 实例,各实例互不影响:\n<div class=\"codesection\">\n<pre class=\"displaycode\"> >>> f1 = fab(3) \n >>> f2 = fab(5) \n >>> print 'f1:', f1.next() \n f1: 1 \n >>> print 'f2:', f2.next() \n f2: 1 \n >>> print 'f1:', f1.next() \n f1: 1 \n >>> print 'f2:', f2.next() \n f2: 1 \n >>> print 'f1:', f1.next() \n f1: 2 \n >>> print 'f2:', f2.next() \n f2: 2 \n >>> print 'f2:', f2.next() \n f2: 3 \n >>> print 'f2:', f2.next() \n f2: 5</pre>\n</div>\n<div class=\"ibm-alternate-rule\"></div>\n\n[回页首](http://www.ibm.com/developerworks/cn/opensource/os-cn-python-yield/#ibm-pcon)\n\n## return 的作用\n\n在一个 generator function 中,如果没有 return,则默认执行至函数完毕,如果在执行过程中 return,则直接抛出 StopIteration 终止迭代。\n<div class=\"ibm-alternate-rule\"></div>\n\n[回页首](http://www.ibm.com/developerworks/cn/opensource/os-cn-python-yield/#ibm-pcon)\n\n## 另一个例子\n\n另一个 yield 的例子来源于文件读取。如果直接对文件对象调用 read() 方法,会导致不可预测的内存占用。好的方法是利用固定长度的缓冲区来不断读取文件内容。通过 yield,我们不再需要编写读文件的迭代类,就可以轻松实现文件读取:\n\n##### 清单 9\\. 另一个 yield 的例子\n\n<div class=\"codesection\">\n<pre class=\"displaycode\"> def read_file(fpath): \n BLOCK_SIZE = 1024 \n with open(fpath, 'rb') as f: \n while True: \n block = f.read(BLOCK_SIZE) \n if block: \n yield block \n else: \n return</pre>\n</div>\n以上仅仅简单介绍了 yield 的基本概念和用法,yield 在 Python 3 中还有更强大的用法,我们会在后续文章中讨论。\n\n注:本文的代码均在 Python 2.7 中调试通过","slug":"PYTHON YIELD 使用浅析","published":1,"updated":"2015-12-02T04:39:35.622Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153yj005cc0tjuufgjlx1"},{"title":"ORM(Object Relation Mapping)","id":"123","date":"2015-05-03T01:38:47.000Z","_content":"\n## 前言\n\n对象关系映射,是一种完成对象模型到关系模型的映射技术。就是一种把应用程序的对象数据持久化到关系数据库表的一种技术。\n\n* 把对象的数据转储到关系型数据库表中时就会发生如下不匹配的问题。\n* 对象模型中对象之间的关联关系与关系模型中数据库表之间的关系无法一一对应。\n* 对象模型中对象的继承关系在关系模型中无法直接表示。\n* 对象模型中对象的等值性在关系模型数据库表中表示困难。\n* 对象模型中有关联的对象之间的导航访问在关系模型中无法直接实现。\nORM 来解决上述问题。它能用面向对象的思想开发基于关系型数据库的应用程序。\n\n### Hibernate\n\nJBoss公司著名架构师Gavin King设计,开发的一个开源的ORM框架。\n\n* 它是连接Java应用程序和关系数据库的中间件。\n* 它对JDBC API进行了封装,负责Java对象的持久化。\n* 在分层的软件框架中它位于持久化层,封装的所有的数据访问细节,使业务逻辑层可以专注于实现业务逻辑。\n* 它是一种ORM工具,能够建立面相对象的域模型和关系模型的映射。\n\n### hibernate 的核心类和接口\n\n#### 1,Configuration类\n\nConfiguration类是Hibernate的入口,它负责配置并启动Hibernate。Hibernate框架通过Configuration实例加载配置文件信息,然后读取指定对象关系文件的内容并创建SessionFactory实例。\n\n#### 2,SessionFactory接口\n\nSessionFactory接口负责初始化Hibernate,一个SessionFactory实例对应一个数据存储源(一般就是指一个数据库)。应用程序从SessionFactory中获取Session实例。SessionFactory具有以下几个特点:\n\n* 线程安全,即同一个SessionFactory实例可以被应用的多个线程共享。\n* 它是重量级的,因为它需要一个很大的缓存,用来存放预定义的SQL语句以及映射元数据。\n所以说,如果一个应用程序只访问一个数据库,则只需要创建一个全局的SessionFactory实例。\n\n#### 3,Session接口\n\nSession是Hibernate中应用最频繁的接口。Session也被称为持久化管理器。他负责管理所有与持久化相关的操作:存储、更新、删除和加载对象等。Session具有以下特点。\n\n单线程,非共享的对象。线程不安全,在设计软件架构时,应该避免多个线程共享同一个Session实例。\n\nSession实例是轻量级的,它的创建和销毁不需要消耗太多的资源。可以为每个请求分配一个Session实例,在每次请求过程中及时创建和销毁Session实例。\n\nSession有一个缓存,他存放当前工作单元加载的对象。Session的缓存被称为Hibernate的第一级缓存。\n\n#### 4,Transaction接口\n\nTransaction接口是Hibernate框架的事务接口。它对底层事务接口做了封装,包括:JDBC API和JTA。这样,使得Hibernate应用可通过一致的Transaction接口来声明事务边界,这有助于应用程序在不同环境和容器中移植。\n\n#### 5,Query和Criteria接口\n\n他们是Hibernate的查询接口,用于从数据库存储源查询对象以及控制执行查询的过程。Query包装了一个HQL的查询语句;而Criteria接口完全封装了基于字符串形式的查询语句,比Query更加面相对象,Criteria接口擅长执行动态查询。\n\n### Hibernate的工作过程\n\n","source":"_posts/ORM(Object Relation Mapping).md","raw":"title: ORM(Object Relation Mapping)\ntags:\n - Hibernate\n - ORM\nid: 123\ncategories:\n - Java\ndate: 2015-05-03 09:38:47\n---\n\n## 前言\n\n对象关系映射,是一种完成对象模型到关系模型的映射技术。就是一种把应用程序的对象数据持久化到关系数据库表的一种技术。\n\n* 把对象的数据转储到关系型数据库表中时就会发生如下不匹配的问题。\n* 对象模型中对象之间的关联关系与关系模型中数据库表之间的关系无法一一对应。\n* 对象模型中对象的继承关系在关系模型中无法直接表示。\n* 对象模型中对象的等值性在关系模型数据库表中表示困难。\n* 对象模型中有关联的对象之间的导航访问在关系模型中无法直接实现。\nORM 来解决上述问题。它能用面向对象的思想开发基于关系型数据库的应用程序。\n\n### Hibernate\n\nJBoss公司著名架构师Gavin King设计,开发的一个开源的ORM框架。\n\n* 它是连接Java应用程序和关系数据库的中间件。\n* 它对JDBC API进行了封装,负责Java对象的持久化。\n* 在分层的软件框架中它位于持久化层,封装的所有的数据访问细节,使业务逻辑层可以专注于实现业务逻辑。\n* 它是一种ORM工具,能够建立面相对象的域模型和关系模型的映射。\n\n### hibernate 的核心类和接口\n\n#### 1,Configuration类\n\nConfiguration类是Hibernate的入口,它负责配置并启动Hibernate。Hibernate框架通过Configuration实例加载配置文件信息,然后读取指定对象关系文件的内容并创建SessionFactory实例。\n\n#### 2,SessionFactory接口\n\nSessionFactory接口负责初始化Hibernate,一个SessionFactory实例对应一个数据存储源(一般就是指一个数据库)。应用程序从SessionFactory中获取Session实例。SessionFactory具有以下几个特点:\n\n* 线程安全,即同一个SessionFactory实例可以被应用的多个线程共享。\n* 它是重量级的,因为它需要一个很大的缓存,用来存放预定义的SQL语句以及映射元数据。\n所以说,如果一个应用程序只访问一个数据库,则只需要创建一个全局的SessionFactory实例。\n\n#### 3,Session接口\n\nSession是Hibernate中应用最频繁的接口。Session也被称为持久化管理器。他负责管理所有与持久化相关的操作:存储、更新、删除和加载对象等。Session具有以下特点。\n\n单线程,非共享的对象。线程不安全,在设计软件架构时,应该避免多个线程共享同一个Session实例。\n\nSession实例是轻量级的,它的创建和销毁不需要消耗太多的资源。可以为每个请求分配一个Session实例,在每次请求过程中及时创建和销毁Session实例。\n\nSession有一个缓存,他存放当前工作单元加载的对象。Session的缓存被称为Hibernate的第一级缓存。\n\n#### 4,Transaction接口\n\nTransaction接口是Hibernate框架的事务接口。它对底层事务接口做了封装,包括:JDBC API和JTA。这样,使得Hibernate应用可通过一致的Transaction接口来声明事务边界,这有助于应用程序在不同环境和容器中移植。\n\n#### 5,Query和Criteria接口\n\n他们是Hibernate的查询接口,用于从数据库存储源查询对象以及控制执行查询的过程。Query包装了一个HQL的查询语句;而Criteria接口完全封装了基于字符串形式的查询语句,比Query更加面相对象,Criteria接口擅长执行动态查询。\n\n### Hibernate的工作过程\n\n","slug":"ORM(Object Relation Mapping)","published":1,"updated":"2015-12-02T04:39:35.622Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153yn005ic0tjp5s98c69"},{"title":"NIO-library","date":"2015-12-02T05:15:50.000Z","_content":"\n## NIO 类库简介\n\n### 缓冲区Buffer\nBuffer是一个对象,它包含一些要读出或写入的数据。在NIO库中,所有数据都是用缓冲区处理的。任何时候访问数据都是通过缓冲区进行的。\n\n缓冲区实质上是一个数组。通常它是一个字节数组(ByteBuffer),也可以使用其他种类的数组。\n* ByteBuffer\n* CharBuffer\n* ShortBuffer\n* IntBuffer\n* LongBuffer\n* FloatBuffer\n* DoubleBuffer\n每一个Buffer类都是Buffer接口的子实例。除了ByteBuffer,每一个Buffer类都有完全一样的操作。\n\n### 通道Channel\nChannel是一个通道,可以通过它读取和写入数据。通道与流不同之处在于通道是双向的,流只是在一个方向上移动(一个流必须是InputStream或者是OutputStream的子类)。\n\n因为通道是全双工的,所以它可以更好的映射操作系统底层的API。特别是UNIX网络编程模型中,底层操作系统通道都是全双工的。从类图上看Channel可以分为两大类;分别是用于网络读写的SelectableChannel和用于文件操作的FileChannel。\n\nSocketChannel和ServerSocketChannel都是SelectableChannel的子类。\n\n### 多路复用器Selector\n多路复用器提供已经就绪的任务的能力。简单的讲Selector不断轮询注册在其上的Channel,如果某个Channel上面有新的TCP接入、读或者写事件,这个Channel就处于就绪状态,会被Selector轮询出来,然后通过SelectionKey可以获取就绪Channel的集合,进行后续I/O操作。\n\n一个多路复用器Selector可以轮询多个Channel,由于JDK采用epoll()代替传统的select实现,所以它并没有最大连接句柄的限制。\n\n## NIO服务器主要创建过程\n* 打开ServerSocketChannel,用于监听客户端请求连接,它是所有客户端连接的父管道\n```\nServerSocketChannel acceptorSvr = ServerSocketChannel.open();\n```\n* 绑定监听端口,设置连接为非阻塞模式\n```\nacceptorSvr.socket().bind(new InetSocketAddress(InetAddress.getByName(\"IP\"),port));\nacceptorSvr.configureBlocking(false);\n```\n* 创建Reactor线程,创建多路复用器并启动线程\n```\nSeletor selector = Selector.open();\nNew Tread(new ReactorTask()).start();\n```\n* 将ServerSocketChannel注册到Reactor线程的多路复用器Selector上,监听ACCEPT事件\n```\nSelectionKey key = acceptorSvr.register(selector, SelectionKey.OP_ACCEPT,ioHandler);\n```\n* 多路复用器在线程run方法的无限循环体内轮询准备就绪的Key\n```\nint num = selector.select();\nSet selectedKeys = selector.selectedKeys();\nIterator it = selectedKeys.iterator();\nwhile(it.hasNext()){\n SelectionKey key = (SelectionKey) it.next();\n //TODO deal with I/O event\n}\n```\n* 多路复用器监听到所有新的客户端接入,处理新的接入请求,完成TCP三次握手,建立物理链路\n```\nSocketChannel channel = svrChannel.accept();\n```\n* 设置客户端链路为非阻塞模式\n```\nchannel.configureBlocking(false);\nchannel.socket().setReuseAddress(true);\n```\n* 将新的客户端连接注册到Reactor线程的多路复用器上,监听读操作,用来读取客户端发送的网络消息\n```\nSelectionKey key = socketChannel.register(selector, SelectionKey.OP_READ, ioHandler);\n```\n* 异步读取客户端请求消息到缓冲区\n```\nint readNumber = channel.read(receivedBuffer);\n```\n* 对ByteBuffer进行编解码,如果有半包指针reset,继续读取后续的报文,将解码成功的消息封装成Task,投递到业务线程池中,进行业务逻辑的编排\n```\nObject message = null;\nwhile(buffer.hasRemain()){\n byteBuffer.mark();\n Object message = decode(ByteBuffer);\n if(message == null){\n byteBuffer.reset();\n break;\n }\n messageList.add(message);\n}\nif(!byteBuffer.hasRemain()){\n byteBuffer.clear();\n}else{\n byteBuffer.compact();\n}\nif(messageList != null & !messageList.isEmpty()){\n for(Object messageE : messageList){\n handlerTask(messageE);\n }\n}\n```\n* 将POJO对象encode成ByteBuffer,调用SocketChannel的异步write接口,将消息异步发送给客户端\n```\nsocketChannel.write(buffer);\n```\n\n## NIO 客户端创建\n* 打开SocketChannel,绑定客户端本地地址\n```\nSocketChannel clientChannel = SocketChannel.open();\n```\n* 设置SocketChannel为非阻塞模式,同时设置客户端连接的TCP参数\n```\nclientChannel.configureBlocking(false);\nsocket.setReuseAddress(true);\nsocket.setReceiveBufferSize(BUFFER_SIZE);\nsocket.setSendBufferSize(BUFFER_SIZE);\n```\n* 异步连接服务器\n```\nboolean connectioned = clientChannel.connect(new InetSocketAddress(\"IP\").port);\n```\n* 判断连接是否成功,如果连接成功,则直接注册读状态位到多路复用器中,如果当前没有连接成功(异步连接,返回false,说明客户端已经发送sync包,服务端没有返回ack包,物理链路没有建立)\n```\nif(connectioned){\n clientChannel.register(selector, SelectorKey.OP_READ, ioHandler);\n}else{\n clientChannel.register(selector, SelectorKey.OP_CONNECT,ioHandler);\n}\n```\n* 向Reactor线程的多路复用器注册OP_CONNECT状态位,监听服务端的TCP ACK应答\n```\nclientChannel.register(selector, SelectorKey.OP_CONNECT, ioHandler);\n```\n* 创建Reactor线程,创建多路复用器并启动线程\n```\nSelector selector = Selector.open();\nNew Thread(new ReactorTask()).start();\n```\n* 多路复用器在线程run方法的无限循环内轮询准备就绪的Key\n```\nint num = selector.select();\nSet selectedKeys = selector.selectedKeys();\nIterator it = selectedKeys.iterator();\nwhile(it.hasNext()){\n SelectionKey key= (SelectionKey) it.next();\n // TODO deal with I/O event\n}\n```\n* 接收connect事件进行处理\n```\nif(key.isConnectable()){\n //handlerConnect();\n}\n```\n* 判断连接结果,如果连接成功,注册读事件到多路复用器\n```\nif(channel.finishConnect()){\n registerRead();\n}\n```\n* 注册事件到多路复用器\n```\nclientChannel.register(selector, SelectionKey.OP_READ,ioHandler);\n```\n* 异步读取客户端请求消息到缓冲区\n```\nint readNumber = channel.read(recevicedBuffer);\n```\n* 对ByteBuffer进行编解码,如果有半包消息接收缓冲区Reset,继续读取后续的报文,将解码成功的消息封装成Task,投递到业务线程池中\n```\nObject message = null;\nwhile(buffer.hasRemain){\n byteBuffer.mark();\n Object message = decode(byteBuffer);\n if(message == null){\n byteBuffer.reset();\n break;\n }\n messageList.add(message);\n}\nif(!byteBuffer.hasRemain()){\n byteBuffer.clear();\n}else{\n byteBuffer.compact();\n}\nif(messageList != null && !messageList.isEmpty()){\n for(Object messageE : messageList){\n handlerTask(messageE);\n }\n}\n```\n* 将POJO对象encode成ByteBuffer,调用SocketChannel的异步write接口,将消息异步发送给客户端\n```\nsocketChannel.write(buffer);\n```\n### NIO 编程的优点\n* 客户端连接都是异步的,可以通过多路复用器注册OP_CONNECT等待后续结果,不需要像之前的客户端那样被同步阻塞。\n* SocketChannel的读写操作都是异步的,如果没有可读写的数据,它不会同步等待,直接返回,这样I/O通信线程可以处理其他的链路,不需要同步等待这个链路可用。\n* 线程模型的优化,由于JDK的Selector在Linux等主流操作系统上通过epoll实现,它没有连接句柄数的限制,这就意味着一个Selector可以处理成千上万的客户端连接,而且性能不会随着客户端的增加而下降。\n","source":"_posts/NIO-library.md","raw":"title: NIO-library\ndate: 2015-12-02 13:15:50\ntags: NIO\n---\n\n## NIO 类库简介\n\n### 缓冲区Buffer\nBuffer是一个对象,它包含一些要读出或写入的数据。在NIO库中,所有数据都是用缓冲区处理的。任何时候访问数据都是通过缓冲区进行的。\n\n缓冲区实质上是一个数组。通常它是一个字节数组(ByteBuffer),也可以使用其他种类的数组。\n* ByteBuffer\n* CharBuffer\n* ShortBuffer\n* IntBuffer\n* LongBuffer\n* FloatBuffer\n* DoubleBuffer\n每一个Buffer类都是Buffer接口的子实例。除了ByteBuffer,每一个Buffer类都有完全一样的操作。\n\n### 通道Channel\nChannel是一个通道,可以通过它读取和写入数据。通道与流不同之处在于通道是双向的,流只是在一个方向上移动(一个流必须是InputStream或者是OutputStream的子类)。\n\n因为通道是全双工的,所以它可以更好的映射操作系统底层的API。特别是UNIX网络编程模型中,底层操作系统通道都是全双工的。从类图上看Channel可以分为两大类;分别是用于网络读写的SelectableChannel和用于文件操作的FileChannel。\n\nSocketChannel和ServerSocketChannel都是SelectableChannel的子类。\n\n### 多路复用器Selector\n多路复用器提供已经就绪的任务的能力。简单的讲Selector不断轮询注册在其上的Channel,如果某个Channel上面有新的TCP接入、读或者写事件,这个Channel就处于就绪状态,会被Selector轮询出来,然后通过SelectionKey可以获取就绪Channel的集合,进行后续I/O操作。\n\n一个多路复用器Selector可以轮询多个Channel,由于JDK采用epoll()代替传统的select实现,所以它并没有最大连接句柄的限制。\n\n## NIO服务器主要创建过程\n* 打开ServerSocketChannel,用于监听客户端请求连接,它是所有客户端连接的父管道\n```\nServerSocketChannel acceptorSvr = ServerSocketChannel.open();\n```\n* 绑定监听端口,设置连接为非阻塞模式\n```\nacceptorSvr.socket().bind(new InetSocketAddress(InetAddress.getByName(\"IP\"),port));\nacceptorSvr.configureBlocking(false);\n```\n* 创建Reactor线程,创建多路复用器并启动线程\n```\nSeletor selector = Selector.open();\nNew Tread(new ReactorTask()).start();\n```\n* 将ServerSocketChannel注册到Reactor线程的多路复用器Selector上,监听ACCEPT事件\n```\nSelectionKey key = acceptorSvr.register(selector, SelectionKey.OP_ACCEPT,ioHandler);\n```\n* 多路复用器在线程run方法的无限循环体内轮询准备就绪的Key\n```\nint num = selector.select();\nSet selectedKeys = selector.selectedKeys();\nIterator it = selectedKeys.iterator();\nwhile(it.hasNext()){\n SelectionKey key = (SelectionKey) it.next();\n //TODO deal with I/O event\n}\n```\n* 多路复用器监听到所有新的客户端接入,处理新的接入请求,完成TCP三次握手,建立物理链路\n```\nSocketChannel channel = svrChannel.accept();\n```\n* 设置客户端链路为非阻塞模式\n```\nchannel.configureBlocking(false);\nchannel.socket().setReuseAddress(true);\n```\n* 将新的客户端连接注册到Reactor线程的多路复用器上,监听读操作,用来读取客户端发送的网络消息\n```\nSelectionKey key = socketChannel.register(selector, SelectionKey.OP_READ, ioHandler);\n```\n* 异步读取客户端请求消息到缓冲区\n```\nint readNumber = channel.read(receivedBuffer);\n```\n* 对ByteBuffer进行编解码,如果有半包指针reset,继续读取后续的报文,将解码成功的消息封装成Task,投递到业务线程池中,进行业务逻辑的编排\n```\nObject message = null;\nwhile(buffer.hasRemain()){\n byteBuffer.mark();\n Object message = decode(ByteBuffer);\n if(message == null){\n byteBuffer.reset();\n break;\n }\n messageList.add(message);\n}\nif(!byteBuffer.hasRemain()){\n byteBuffer.clear();\n}else{\n byteBuffer.compact();\n}\nif(messageList != null & !messageList.isEmpty()){\n for(Object messageE : messageList){\n handlerTask(messageE);\n }\n}\n```\n* 将POJO对象encode成ByteBuffer,调用SocketChannel的异步write接口,将消息异步发送给客户端\n```\nsocketChannel.write(buffer);\n```\n\n## NIO 客户端创建\n* 打开SocketChannel,绑定客户端本地地址\n```\nSocketChannel clientChannel = SocketChannel.open();\n```\n* 设置SocketChannel为非阻塞模式,同时设置客户端连接的TCP参数\n```\nclientChannel.configureBlocking(false);\nsocket.setReuseAddress(true);\nsocket.setReceiveBufferSize(BUFFER_SIZE);\nsocket.setSendBufferSize(BUFFER_SIZE);\n```\n* 异步连接服务器\n```\nboolean connectioned = clientChannel.connect(new InetSocketAddress(\"IP\").port);\n```\n* 判断连接是否成功,如果连接成功,则直接注册读状态位到多路复用器中,如果当前没有连接成功(异步连接,返回false,说明客户端已经发送sync包,服务端没有返回ack包,物理链路没有建立)\n```\nif(connectioned){\n clientChannel.register(selector, SelectorKey.OP_READ, ioHandler);\n}else{\n clientChannel.register(selector, SelectorKey.OP_CONNECT,ioHandler);\n}\n```\n* 向Reactor线程的多路复用器注册OP_CONNECT状态位,监听服务端的TCP ACK应答\n```\nclientChannel.register(selector, SelectorKey.OP_CONNECT, ioHandler);\n```\n* 创建Reactor线程,创建多路复用器并启动线程\n```\nSelector selector = Selector.open();\nNew Thread(new ReactorTask()).start();\n```\n* 多路复用器在线程run方法的无限循环内轮询准备就绪的Key\n```\nint num = selector.select();\nSet selectedKeys = selector.selectedKeys();\nIterator it = selectedKeys.iterator();\nwhile(it.hasNext()){\n SelectionKey key= (SelectionKey) it.next();\n // TODO deal with I/O event\n}\n```\n* 接收connect事件进行处理\n```\nif(key.isConnectable()){\n //handlerConnect();\n}\n```\n* 判断连接结果,如果连接成功,注册读事件到多路复用器\n```\nif(channel.finishConnect()){\n registerRead();\n}\n```\n* 注册事件到多路复用器\n```\nclientChannel.register(selector, SelectionKey.OP_READ,ioHandler);\n```\n* 异步读取客户端请求消息到缓冲区\n```\nint readNumber = channel.read(recevicedBuffer);\n```\n* 对ByteBuffer进行编解码,如果有半包消息接收缓冲区Reset,继续读取后续的报文,将解码成功的消息封装成Task,投递到业务线程池中\n```\nObject message = null;\nwhile(buffer.hasRemain){\n byteBuffer.mark();\n Object message = decode(byteBuffer);\n if(message == null){\n byteBuffer.reset();\n break;\n }\n messageList.add(message);\n}\nif(!byteBuffer.hasRemain()){\n byteBuffer.clear();\n}else{\n byteBuffer.compact();\n}\nif(messageList != null && !messageList.isEmpty()){\n for(Object messageE : messageList){\n handlerTask(messageE);\n }\n}\n```\n* 将POJO对象encode成ByteBuffer,调用SocketChannel的异步write接口,将消息异步发送给客户端\n```\nsocketChannel.write(buffer);\n```\n### NIO 编程的优点\n* 客户端连接都是异步的,可以通过多路复用器注册OP_CONNECT等待后续结果,不需要像之前的客户端那样被同步阻塞。\n* SocketChannel的读写操作都是异步的,如果没有可读写的数据,它不会同步等待,直接返回,这样I/O通信线程可以处理其他的链路,不需要同步等待这个链路可用。\n* 线程模型的优化,由于JDK的Selector在Linux等主流操作系统上通过epoll实现,它没有连接句柄数的限制,这就意味着一个Selector可以处理成千上万的客户端连接,而且性能不会随着客户端的增加而下降。\n","slug":"NIO-library","published":1,"updated":"2015-12-03T01:49:56.728Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153yq005nc0tju2kopxp5"},{"title":"NIO-Programing","date":"2015-12-10T02:57:35.000Z","_content":"\n## NIO 开发步骤\n* 创建ServerSocketChannel,配置他为非阻塞模式;\n* 绑定监听,配置TCP参数,backlog的大小;\n* 创建一个独立的I/O线程,用于轮询多路复用器Selector;\n* 创建Selector,将之前创建的ServerSocketChannel 注册到Selector上,监听SelectorKey.ACCEPT;\n* 启动I/O线程,在循环体中执行Selector。select()方法,轮询就绪的Channel;\n* 当轮询到就绪状态的Channel时,需要进行判断,如果是OP_ACCEPT状态,说明是新接入的客户端,则调用ServerSocketChannel.accept()方法接受新的客户端;\n* 设置新接入的客户端链路SocketChannel为非阻塞模式,配置其他的一些TCP参数;\n* 将SocketChannel注册到Selector,监听OP_READ操作位;\n* 如果轮询的Channel为OP_READ,则说明SocketChannel中有就绪的数据包需要读取,则构造ByteBuffer对象,读入数据包;\n* 如果轮询的Channel为OP_WRITE,说明还有数据没有发送完成,需要继续发送。\n","source":"_posts/NIO-Programing.md","raw":"title: NIO-Programing\ndate: 2015-12-10 10:57:35\ntags: NIO\n---\n\n## NIO 开发步骤\n* 创建ServerSocketChannel,配置他为非阻塞模式;\n* 绑定监听,配置TCP参数,backlog的大小;\n* 创建一个独立的I/O线程,用于轮询多路复用器Selector;\n* 创建Selector,将之前创建的ServerSocketChannel 注册到Selector上,监听SelectorKey.ACCEPT;\n* 启动I/O线程,在循环体中执行Selector。select()方法,轮询就绪的Channel;\n* 当轮询到就绪状态的Channel时,需要进行判断,如果是OP_ACCEPT状态,说明是新接入的客户端,则调用ServerSocketChannel.accept()方法接受新的客户端;\n* 设置新接入的客户端链路SocketChannel为非阻塞模式,配置其他的一些TCP参数;\n* 将SocketChannel注册到Selector,监听OP_READ操作位;\n* 如果轮询的Channel为OP_READ,则说明SocketChannel中有就绪的数据包需要读取,则构造ByteBuffer对象,读入数据包;\n* 如果轮询的Channel为OP_WRITE,说明还有数据没有发送完成,需要继续发送。\n","slug":"NIO-Programing","published":1,"updated":"2015-12-10T03:11:30.259Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153yt005qc0tjnlh2xv8c"},{"title":"NIO-Introduce-Abstractly","date":"2015-11-30T07:07:51.000Z","_content":"\n# NIO 入门\n\n## 传统的BIO编程\n\n网络编程的基本模型是Client/Server模型,也就是两个进程之间进行相互通信,其中服务端提供位置信息,客户端通过连接操作向服务器端监听的地址发送连接请求,通过三次握手简历连接,如果连接简历成功,双发就可以通过网络套接字(Socket)进行通信。\n\n在基于传统同步阻塞模型开发中,ServerSocket负责绑定IP地址,启动监听端口;Socket负责发起连接操作。连接成功之后,双发通过输入输出流进行同步阻塞式通信。\n\n在传统的BIO通信模型的服务端,通常由一个独立的Acceptor线程负责监听客户端的连接,它接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。最大的缺点是,当客户端访问量增大之后,服务端的线程个数和客户端的并发访问量呈1:1 的正比关系,由于线程是Java虚拟机非常宝贵的系统资源,当线程膨胀之后,系统的性能将急剧下降,系统会出现线程堆栈溢出、创建线程失败等问题。\n\n为了改进一线程一连接模型,后来又演进出了一种通过线程池或者消息队列实现1个或者多个线程处理N个客户端的模型,由于它的底层通信机制依然使用同步阻塞I/O,所以被称为“伪异步”。\n\n## 伪异步I/O编程\n\n后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数M:线程池最大线程数N的比例关系,其中M远大于N,通过线程池可以灵活调配线程资源,设置线程最大值,防止海量并发接入导致线程耗尽。\n\n当有新的客户端接入的时候,将客户端的Socket封装成一个Task投递到后端线程池中进行处理,JDK的线程池维护一个消息队列和N个活跃线程对消息队列中的消息进行处理。由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少客户端并发访问,都不会导致资源的耗尽和宕机。\n\n伪异步I/O通信框架采用了线程池实现,因此避免了为每个请求都创建一个独立线程造成的线程资源耗尽的问题。但是它底层通信仍采用同步阻塞模型,因此无法从根本上解决问题。\n\nJava输入流 InputStream\n```\npublic int read(byte b[]) throws Exception{\n\treturn read(b, 0, b.length);\n}\n```\n\n当对Socket输入流进行读取时,操作一直会阻塞下去,直到发生如下几件事情:\n* 有数据可读;\n* 可用数据以读取完毕;\n* 发生空指针或者I/O异常。\n\n当对方发送消息或者应答消息比较缓慢、或者网络传输较慢时,读取输入流一方的通信线程将长时间阻塞。\n\nJava输出流 OutputStream\n```\npublic void write(byte b[]) throws IOException\n```\n\n当调用OutputStream 的write方法时,它将会被阻塞,直到所有要发送的字节全部写入完毕,或者发生异常。\n\n通过分析输入和输出流的API文档,我们发现读和写操作都是同步阻塞的,阻塞时间取决于对方的I/O线程处理速度和网络I/O的传播速度。\n\n## Non block I/O\n与Socket和SocketServer类相对应,NIO 也提供的SocketChannel和ServerSocketChannel两种不同的套接字通道实现.这两种新增的通道都支持阻塞和非阻塞两种模式。阻塞模式使用非常简单,但是性能和可靠性都不好。\n非阻塞模式恰好相反。\n","source":"_posts/NIO-Introduce-Abstractly.md","raw":"title: NIO-Introduce-Abstractly\ndate: 2015-11-30 15:07:51\ntags: NIO\n---\n\n# NIO 入门\n\n## 传统的BIO编程\n\n网络编程的基本模型是Client/Server模型,也就是两个进程之间进行相互通信,其中服务端提供位置信息,客户端通过连接操作向服务器端监听的地址发送连接请求,通过三次握手简历连接,如果连接简历成功,双发就可以通过网络套接字(Socket)进行通信。\n\n在基于传统同步阻塞模型开发中,ServerSocket负责绑定IP地址,启动监听端口;Socket负责发起连接操作。连接成功之后,双发通过输入输出流进行同步阻塞式通信。\n\n在传统的BIO通信模型的服务端,通常由一个独立的Acceptor线程负责监听客户端的连接,它接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。最大的缺点是,当客户端访问量增大之后,服务端的线程个数和客户端的并发访问量呈1:1 的正比关系,由于线程是Java虚拟机非常宝贵的系统资源,当线程膨胀之后,系统的性能将急剧下降,系统会出现线程堆栈溢出、创建线程失败等问题。\n\n为了改进一线程一连接模型,后来又演进出了一种通过线程池或者消息队列实现1个或者多个线程处理N个客户端的模型,由于它的底层通信机制依然使用同步阻塞I/O,所以被称为“伪异步”。\n\n## 伪异步I/O编程\n\n后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数M:线程池最大线程数N的比例关系,其中M远大于N,通过线程池可以灵活调配线程资源,设置线程最大值,防止海量并发接入导致线程耗尽。\n\n当有新的客户端接入的时候,将客户端的Socket封装成一个Task投递到后端线程池中进行处理,JDK的线程池维护一个消息队列和N个活跃线程对消息队列中的消息进行处理。由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少客户端并发访问,都不会导致资源的耗尽和宕机。\n\n伪异步I/O通信框架采用了线程池实现,因此避免了为每个请求都创建一个独立线程造成的线程资源耗尽的问题。但是它底层通信仍采用同步阻塞模型,因此无法从根本上解决问题。\n\nJava输入流 InputStream\n```\npublic int read(byte b[]) throws Exception{\n\treturn read(b, 0, b.length);\n}\n```\n\n当对Socket输入流进行读取时,操作一直会阻塞下去,直到发生如下几件事情:\n* 有数据可读;\n* 可用数据以读取完毕;\n* 发生空指针或者I/O异常。\n\n当对方发送消息或者应答消息比较缓慢、或者网络传输较慢时,读取输入流一方的通信线程将长时间阻塞。\n\nJava输出流 OutputStream\n```\npublic void write(byte b[]) throws IOException\n```\n\n当调用OutputStream 的write方法时,它将会被阻塞,直到所有要发送的字节全部写入完毕,或者发生异常。\n\n通过分析输入和输出流的API文档,我们发现读和写操作都是同步阻塞的,阻塞时间取决于对方的I/O线程处理速度和网络I/O的传播速度。\n\n## Non block I/O\n与Socket和SocketServer类相对应,NIO 也提供的SocketChannel和ServerSocketChannel两种不同的套接字通道实现.这两种新增的通道都支持阻塞和非阻塞两种模式。阻塞模式使用非常简单,但是性能和可靠性都不好。\n非阻塞模式恰好相反。\n","slug":"NIO-Introduce-Abstractly","published":1,"updated":"2015-12-02T04:48:02.085Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153yu005sc0tji5u1cacq"},{"title":"Java中的一些概念(updating)","id":"212","date":"2015-05-16T18:28:40.000Z","_content":"\n1,别名现象\n\n主要出现在赋值上面。对于基本数据类型的复制时很简单的,基本数据类型存储了实际的数值,而并非指向一个对象的引用,所以在赋值的时候,是将一个地方的内容复制到另一个地方。例如:对于基本数据类型使用a=b,那么b的内容复制给了a。若修改a的值,b根本不会受这些修改的影响。\n\n但是对一个对象进行操作时,我们真正操作的是对象的引用。所以倘若“将一个对象赋值给另一个对象”,实际是将“引用”从一个地方复制到另一个地方。这意味着假若对对象使用c=d,那么c和d都指向原本只有d指向的那个对象。\n\n2,短路\n\n当使用逻辑运算符时会出现的一种现象。即如果能够明确无误的计算表达式的值,那么就不再计算表达式余下的部分。因此整个逻辑表达式靠后的部分有可能不会被运算。\n\n3,按位操作符\n\n对于布尔值,按位操作符与逻辑操作符有相同的效果,只是它们中途不会短路。\n\n4,位移操作符\n\n只能用来处理整数类型。左移操作符“<<”能按照操作符右侧指定的位数将操作符左面的操作数向左移动(低位补0);右移操作符“>>”能够按照操作符右侧的位数将操作符左侧的操作数向右移动,“有符号”使用“符号扩展”:若符号为正,则在高位插入0,若符号为负,则在高位插入1.。java中加入一种无符号右移操作符“>>>”,无论正负,高位置0。\n\n对于char, byte, short进行位移操作符,首先转换为int型。结果也是一个int值。\n\n5,窄化转换(narrowing conversion)\n\n将能容纳更多信息的数据类型转换成无法容纳那么多信息的数据类型,有可能面临信息丢失的危险。\n\n6,扩展转换(widening conversion)\n\n不必显式的地进行类型转换,因为新类型肯定能容纳原来类型的信息,不会造成任何信息的丢失。\n\n7,截尾和舍入\n\nfloat int 时,截尾\n\n舍入(Java.lang.Math round()方法)\n\n8,逗号操作符\n\nJava里面唯一用到逗号操作符的地方就是for循环的控制表达式。在控制表达式的初始化和步进控制部分,可以用一系列的逗号分隔的语句,这些语句可以独立执行。\n\n9,return,break,continue\n\n在任何的迭代语句的主体部分,都可以用break和continue控制循环的流程。\n\n10,无穷循环for(;;)\n\n11,标签\n\nlabel:,在java中需要使用标签的唯一理由是因为循环嵌套存在,而且想从多层嵌套中break,continue。\n\n12,this\n\n尽管用this可以调用一个构造器,但却不能调用两个。此外构造器调用必须置于初始处,否则编译出错。除构造器外,编译器禁止其他任何方法中调用构造器。\n\n ","source":"_posts/Java中的一些概念.md","raw":"title: Java中的一些概念(updating)\nid: 212\ncategories:\n - Java\ndate: 2015-05-17 02:28:40\ntags:\n---\n\n1,别名现象\n\n主要出现在赋值上面。对于基本数据类型的复制时很简单的,基本数据类型存储了实际的数值,而并非指向一个对象的引用,所以在赋值的时候,是将一个地方的内容复制到另一个地方。例如:对于基本数据类型使用a=b,那么b的内容复制给了a。若修改a的值,b根本不会受这些修改的影响。\n\n但是对一个对象进行操作时,我们真正操作的是对象的引用。所以倘若“将一个对象赋值给另一个对象”,实际是将“引用”从一个地方复制到另一个地方。这意味着假若对对象使用c=d,那么c和d都指向原本只有d指向的那个对象。\n\n2,短路\n\n当使用逻辑运算符时会出现的一种现象。即如果能够明确无误的计算表达式的值,那么就不再计算表达式余下的部分。因此整个逻辑表达式靠后的部分有可能不会被运算。\n\n3,按位操作符\n\n对于布尔值,按位操作符与逻辑操作符有相同的效果,只是它们中途不会短路。\n\n4,位移操作符\n\n只能用来处理整数类型。左移操作符“<<”能按照操作符右侧指定的位数将操作符左面的操作数向左移动(低位补0);右移操作符“>>”能够按照操作符右侧的位数将操作符左侧的操作数向右移动,“有符号”使用“符号扩展”:若符号为正,则在高位插入0,若符号为负,则在高位插入1.。java中加入一种无符号右移操作符“>>>”,无论正负,高位置0。\n\n对于char, byte, short进行位移操作符,首先转换为int型。结果也是一个int值。\n\n5,窄化转换(narrowing conversion)\n\n将能容纳更多信息的数据类型转换成无法容纳那么多信息的数据类型,有可能面临信息丢失的危险。\n\n6,扩展转换(widening conversion)\n\n不必显式的地进行类型转换,因为新类型肯定能容纳原来类型的信息,不会造成任何信息的丢失。\n\n7,截尾和舍入\n\nfloat int 时,截尾\n\n舍入(Java.lang.Math round()方法)\n\n8,逗号操作符\n\nJava里面唯一用到逗号操作符的地方就是for循环的控制表达式。在控制表达式的初始化和步进控制部分,可以用一系列的逗号分隔的语句,这些语句可以独立执行。\n\n9,return,break,continue\n\n在任何的迭代语句的主体部分,都可以用break和continue控制循环的流程。\n\n10,无穷循环for(;;)\n\n11,标签\n\nlabel:,在java中需要使用标签的唯一理由是因为循环嵌套存在,而且想从多层嵌套中break,continue。\n\n12,this\n\n尽管用this可以调用一个构造器,但却不能调用两个。此外构造器调用必须置于初始处,否则编译出错。除构造器外,编译器禁止其他任何方法中调用构造器。\n\n ","slug":"Java中的一些概念","published":1,"updated":"2015-12-02T04:39:35.621Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153yw005uc0tjfugudirl"},{"title":"Java 终结处理&垃圾回收","id":"222","date":"2015-06-09T23:05:49.000Z","_content":"\n1,finalize()方法\n\n一旦垃圾回收器准备释放对象占用的存储空间,将首先调用其finalize()方法,并且在下一次来垃圾回收动作发生时,才会真正回收对象占用的内存。\n\n* 对象可能不会被回收;\n* 垃圾回收不等于“析构”;\n* 垃圾回收只与内存有关;\n2,垃圾回收\n\n如果JVM并未面临内存耗尽的情形,它是不会浪费时间去执行垃圾回收已恢复内存的。\n\n3,垃圾回收器如何工作\n\n垃圾回收器对于提高对象的创建速度具有明显的效果。\n\n* stop-and-copy\n* Mark-and-sweep","source":"_posts/Java 终结处理&垃圾回收.md","raw":"title: Java 终结处理&垃圾回收\nid: 222\ncategories:\n - Java\ndate: 2015-06-10 07:05:49\ntags:\n---\n\n1,finalize()方法\n\n一旦垃圾回收器准备释放对象占用的存储空间,将首先调用其finalize()方法,并且在下一次来垃圾回收动作发生时,才会真正回收对象占用的内存。\n\n* 对象可能不会被回收;\n* 垃圾回收不等于“析构”;\n* 垃圾回收只与内存有关;\n2,垃圾回收\n\n如果JVM并未面临内存耗尽的情形,它是不会浪费时间去执行垃圾回收已恢复内存的。\n\n3,垃圾回收器如何工作\n\n垃圾回收器对于提高对象的创建速度具有明显的效果。\n\n* stop-and-copy\n* Mark-and-sweep","slug":"Java 终结处理&垃圾回收","published":1,"updated":"2015-12-02T04:39:35.621Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153yz005wc0tjputioah2"},{"title":"JAVA-NIO-Netty","date":"2015-12-09T08:32:04.000Z","_content":"\n## Java NIO 问题\n* NIO 的类库和API繁琐,使用麻烦,需要熟练掌握Selector、ServerSocketChannel、SocketChannel、ByteBuffer等。\n\n* 需要具备其他的额外技能做铺垫,例如熟悉Java多线程编程。因为NIO编程涉及到Reactor模式。\n\n* 可靠性能力补齐、工作量大、难度大。例如客户端面临断连重连、网络闪断、半包读写、失败缓存、网络拥塞和异常码流的处理能力等问题。\n\n* JDK NIO的BUG。例如epoll bug。它会导致Selector空轮询,最终导致CPU 100%。\n\n## Netty\n\n* API 简单,开发门槛低;\n\n* 功能强大,预设置了多种编码能力,支持多种主流协议;\n\n* 定制能力强,可以通过ChannelHandler对通信框架进行灵活地扩展;\n\n* 性能高,通过与其他业界主流的NIO框架对比,Netty的综合能力最优;\n\n* 成熟、稳定、Netty修复了已经发现的所有JDK NIO BUG,业务人员不需要再为NIO 的BUG烦恼;\n\n* 社区活跃,版本迭代周期短,发现的BUG可以被及时修复,同时,更新的新功能会加入;\n\n* 经历了大规模的商业应用考验,质量得到保证。\n","source":"_posts/JAVA-NIO-Netty.md","raw":"title: JAVA-NIO-Netty\ndate: 2015-12-09 16:32:04\ntags: NIO\n---\n\n## Java NIO 问题\n* NIO 的类库和API繁琐,使用麻烦,需要熟练掌握Selector、ServerSocketChannel、SocketChannel、ByteBuffer等。\n\n* 需要具备其他的额外技能做铺垫,例如熟悉Java多线程编程。因为NIO编程涉及到Reactor模式。\n\n* 可靠性能力补齐、工作量大、难度大。例如客户端面临断连重连、网络闪断、半包读写、失败缓存、网络拥塞和异常码流的处理能力等问题。\n\n* JDK NIO的BUG。例如epoll bug。它会导致Selector空轮询,最终导致CPU 100%。\n\n## Netty\n\n* API 简单,开发门槛低;\n\n* 功能强大,预设置了多种编码能力,支持多种主流协议;\n\n* 定制能力强,可以通过ChannelHandler对通信框架进行灵活地扩展;\n\n* 性能高,通过与其他业界主流的NIO框架对比,Netty的综合能力最优;\n\n* 成熟、稳定、Netty修复了已经发现的所有JDK NIO BUG,业务人员不需要再为NIO 的BUG烦恼;\n\n* 社区活跃,版本迭代周期短,发现的BUG可以被及时修复,同时,更新的新功能会加入;\n\n* 经历了大规模的商业应用考验,质量得到保证。\n","slug":"JAVA-NIO-Netty","published":1,"updated":"2015-12-10T02:56:33.053Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153z1005yc0tjrf76wpw6"},{"title":"IO-Contrast","date":"2015-12-03T09:37:25.000Z","_content":"\n## 4中I/O对比\n\n### 异步非阻塞I/O\n在早期JDK1.4 和 1.5 Update10版本之前,JDK的Selector基于select/poll模型实现,它是基于I/O复用技术的非阻塞I/O,不是异步I/O。在JDK1.5 Update 10 和 Linux core 2.6 以上版本,Sun优化了Selector实现,它在底层使用epoll替换了selector/poll,上层的API没有变化。\n由于 JDK1.7 提供的NIO2.0,新增了异步套接字通道,它是真正的异步I/O,在异步I/O操作的时候可以传递信号变量,当操作完成后悔调用相关的方法,异步I/O被称为AIO。\nNIO类库支持非阻塞读和写,相比于之前的同步阻塞读和写,它是异步的,因此习惯称NIO为异步非阻塞I/O。\n\n### 多路复用器Selector\nJAVA NIO的实现关键是多路复用I/O技术,多路复用的核心就是通过Selector轮询注册在其上Channel,当发现某个或者多个Channel处于就绪状态后,从阻塞状态返回就绪的Channel的选择键集合,进行I/O操作。由于多路复用器是NIO实现非阻塞IO的关键,它又是主要通过Selector实现的。\n\n### 伪异步I/O\n伪异步I/O的概念来源于实践,在JDK NIO编程没有流行之前,为了解决Tomcat通信线程同步I/O导致业务线程被挂住的问题,大家想了一个方法:在通信线程和业务线程之间做一个缓冲区,这个缓冲区用于隔离I/O线程和业务线程间的直接访问,这样业务线程就不会被I/O线程阻塞。对于后端业务来说,将消息或者Task放到线程池后就返回了,它不再直接访问I/O线程或进行I/O读写,这样就不会被同步阻塞。类似的设计还包含前端启动一组线程,将接收的客户端封装成Task,放到后端的线程池执行,用于解决一连接一线程的问题。\n\n## 不同I/O模型对比\n表 1 几种I/O模型的功能和特性对比\n| 模型 | 同步阻塞I/O(BIO) | 伪异步I/O | 非阻塞I/O(NIO) | 异步I/O(AIO)|\n| :----- | :---- | :---- | :---- | :---- |\n| 客户端个数:I/O线程 | 1:1 | M:N(其中M可以大于N) | M:1(1个I/O线程处理多个客户端连接) | M:0(不需要启动额外线程,被动调用) |\n| I/O类型(阻塞) | 阻塞I/O | 阻塞I/O | 非阻塞I/O | 非阻塞I/O |\n| I/O类型(同步) | 同步I/O | 同步I/O | 同步I/O(I/O多路复用)| 异步I/O |\n| API使用难度 | 简单 | 简单 | 非常复杂 | 复杂 |\n| 调度难度 | 简单 | 简单 | 复杂 | 复杂|\n| 可靠性 | 非常差 | 差 | 高 | 高 |\n| 吞吐量 | 低 | 中 | 高 | 高|\n","source":"_posts/IO-Contrast.md","raw":"title: IO-Contrast\ndate: 2015-12-03 17:37:25\ntags: NIO\n---\n\n## 4中I/O对比\n\n### 异步非阻塞I/O\n在早期JDK1.4 和 1.5 Update10版本之前,JDK的Selector基于select/poll模型实现,它是基于I/O复用技术的非阻塞I/O,不是异步I/O。在JDK1.5 Update 10 和 Linux core 2.6 以上版本,Sun优化了Selector实现,它在底层使用epoll替换了selector/poll,上层的API没有变化。\n由于 JDK1.7 提供的NIO2.0,新增了异步套接字通道,它是真正的异步I/O,在异步I/O操作的时候可以传递信号变量,当操作完成后悔调用相关的方法,异步I/O被称为AIO。\nNIO类库支持非阻塞读和写,相比于之前的同步阻塞读和写,它是异步的,因此习惯称NIO为异步非阻塞I/O。\n\n### 多路复用器Selector\nJAVA NIO的实现关键是多路复用I/O技术,多路复用的核心就是通过Selector轮询注册在其上Channel,当发现某个或者多个Channel处于就绪状态后,从阻塞状态返回就绪的Channel的选择键集合,进行I/O操作。由于多路复用器是NIO实现非阻塞IO的关键,它又是主要通过Selector实现的。\n\n### 伪异步I/O\n伪异步I/O的概念来源于实践,在JDK NIO编程没有流行之前,为了解决Tomcat通信线程同步I/O导致业务线程被挂住的问题,大家想了一个方法:在通信线程和业务线程之间做一个缓冲区,这个缓冲区用于隔离I/O线程和业务线程间的直接访问,这样业务线程就不会被I/O线程阻塞。对于后端业务来说,将消息或者Task放到线程池后就返回了,它不再直接访问I/O线程或进行I/O读写,这样就不会被同步阻塞。类似的设计还包含前端启动一组线程,将接收的客户端封装成Task,放到后端的线程池执行,用于解决一连接一线程的问题。\n\n## 不同I/O模型对比\n表 1 几种I/O模型的功能和特性对比\n| 模型 | 同步阻塞I/O(BIO) | 伪异步I/O | 非阻塞I/O(NIO) | 异步I/O(AIO)|\n| :----- | :---- | :---- | :---- | :---- |\n| 客户端个数:I/O线程 | 1:1 | M:N(其中M可以大于N) | M:1(1个I/O线程处理多个客户端连接) | M:0(不需要启动额外线程,被动调用) |\n| I/O类型(阻塞) | 阻塞I/O | 阻塞I/O | 非阻塞I/O | 非阻塞I/O |\n| I/O类型(同步) | 同步I/O | 同步I/O | 同步I/O(I/O多路复用)| 异步I/O |\n| API使用难度 | 简单 | 简单 | 非常复杂 | 复杂 |\n| 调度难度 | 简单 | 简单 | 复杂 | 复杂|\n| 可靠性 | 非常差 | 差 | 高 | 高 |\n| 吞吐量 | 低 | 中 | 高 | 高|\n","slug":"IO-Contrast","published":1,"updated":"2015-12-07T07:45:26.580Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153z40060c0tjw4flbmvg"},{"title":"Hibernate高级映射","id":"148","date":"2015-05-05T06:49:44.000Z","_content":"\n### 集合映射\n\n<set java.util.Set or java.util.SortSet><list java.util.List><bag java.util.Collection><idbag><map java.util.Map or java.util.SortMap><primitive-array><array>\n\n### 组件映射\n\n<component>\n\n1,组件类作为持久化类的单个属性\n\n2,组件类作为持久化类的集合属性:集合映射中的类\n\n3,组件类作为持久化类的对象标识符属性:数据库采用联合主键\n\n### 管理关系映射\n\n关联关系是在领域模型建模中经常使用到的一种关系,它是对现实世界中事物之间的关系最基本的表示。\n\n管联关系指的是不同持久化类之间的一种结构关系,简单地说,关联关系描述某个对象在一段时间内一直知道另一个对象的存在。\n\n关联关系包括多样性关联和方向性关联。多样性(一对多,多对多),方向性(单项关联,双向关联)\n\n映射关联关系就是把对象模型中类之间的关联关系映射成关系模型中数据库表之间的外键引用关系。在映射设计时,考虑两个问题:一是如何将对象模型中的对象之间的关系保存在关系模型的数据库表中,二是如何从关系模型的数据库表中检索出对象模型中的关联的对象。\n\n1,单向多对一\n\n多个员工属于同一部门\n\nDepartment.hbm.xml\n\nEmployee.hbm.xml\n\n<many-to-one name=\"dept\" column=\"dept_id\">\n\n2,单向一对一\n\nCitizen.hbm.xml\n\n<many-to-one name=\"idCard\" column=\"idcard_id\" unique=\"true\" cascade=\"all\">\n\nIdCard.hbm.xml\n\n每个公民只有一张身份证,这就是典型的一对一关联关系。\n\n3,双向一对一\n\n基于唯一外键的一对一双向关联\n\nCitizen.hbm.xml\n\n<many-to-one name=\"idCard\" column=\"idcard_id\" unique=\"true\" cascade=\"all\"/>\n\nIDCard.hbm.xml\n\n<one-to-one name=\"citizen\" property-ref=\"idCard\"/>\n\n基于主键的双向一对一关联\n\nCitizen.hbm.xml\n\n<generator class=\"foreign\"><param name=\"property\">idCard</param></generator>\n\n<one-to-one name=\"idCard\" constrained=\"true\" cascade=\"all\"/>\n\nIDCard.hbm.xml\n\n<one-to-one name=\"citizen\"/>\n\n4,单向一对多\n\n一个账号可以有多个订单\n<pre>//Order.java\npublic class Order{\n private Long id;\n private String orderNo;\n private Date createdTime;\n public Order(){}\n}\n//Account.java\npublic class Account{\n private Long id;\n private String loginName;\n private Set<Order> orderSet;\n public Account(){}\n}\n//Account.hbm.xml\n<set name=\"orderSet\" cascade=\"save-update\">\n <key column=\"account_id\"/>\n <one-to-many class=\"org.napu.Order\">\n<set></pre>\n5,双向一对多(多对一)\n<pre>//Order.java\npublic class Order{\n private Long id;\n private String orderNo;\n private Date createdTime;\n private Account account;\n public Order(){}\n}\n//Account.java\npublic class Account{\n private Long id;\n private String loginName;\n private Set<Order> orderSet;\n public Account(){}\n}\n//Order.hbm.xml\n<many-to-one name=\"account\" column=\"account_id\" not-null=\"true\"/>\n//Account.hbm.xml\n<Set name=\"orderSet\" cascade=\"all\" inverse=\"true\">\n <key column=\"account_id\"/>\n <one-to-many class=\"org.napu.Order\">\n</Set></pre>\n6,单向多对多\n\n大学生和课程之间的关系\n<pre>//Student.java\npublic class Student{\n private Long id;\n private String name;\n private String grade;\n private Set<Course> courses;\n public Student(){}\n}\n//Course.java\npublic class Course{\n private Long id;\n private String name;\n private Double creditHours;\n public Course(){}\n}\n//Student.hbm.xml\n<set name=\"courses\" table=\"student_course\">\n <key column=\"student_id\"/>\n <many-to-many column=\"course_id\" class=\"org.napu.Course\">\n<set></pre>\n7,双向多对多\n<pre>//Student.java\npublic class Student{\n private Long id;\n private String name;\n private String grade;\n private Set<Course> courses;\n public Student(){}\n}\n//Course.java\npublic class Course{\n private Long id;\n private String name;\n private Double creditHours;\n private Set<Student> students;\n public Course(){}\n}\n//Student.hbm.xml\n<set name=\"courses\" table=\"student_course\">\n <key column=\"student_id\"/>\n <many-to-many column=\"course_id\" class=\"org.napu.Course\"/>\n<set>\n//Course.hbm.xml\n<set name=\"\"students table=\"students_course\" inverse=\"true\">\n <key column=\"course_id\"/>\n <many-to-many column=\"student_id\" class=\"org.napu.Student\"/>\n</set></pre>\n\n### 继承关系映射\n\n继承在对象模型中是is a(是一个)的关系,在关系模型中,实体之间只有has a(有一个)的关系。\n\nHibernate提供了3中继承映射的方法。\n<pre>//Singer.java\npublic class Singer{\n private Long id;\n private String name;\n private String region;\n private String description;\n pubic Singer(){}\n}\n//SingleSinger.java\npublic class SingleSinger extends Singer{\n private Character gender;\n public SingleSinger(){}\n}\n//Bands.java\npublic class Bands extends Singer{\n private String leader;\n public Bands(){}\n}</pre>\n1,整个继承层次一张表\n<pre>//Singer.hbm.xml\n<hibernate-mapping>\n <class name=\"org.napu.Singer\" table=\"singer\">\n <id name=\"id\" column=\"id\" type=\"long\"><generator class=\"native\"/></id>\n <discriminator column=\"type\" type=\"string\"/>\n <property name=\"name\"/>\n <property name=\"region\"/>\n <property name=\"description\"/>\n <subclass name=\"org.napu.SingleSinger\" discriminator-value=\"S\">\n <property name=\"gender\"/>\n </subclass>\n <subclass name=\"org.napu.Bands\" discriminator-value=\"B\">\n <property name=\"leader\"/>\n </subclass>\n </class>\n</hibernate-mapping></pre>\n2,每个子类一张表\n<pre><joined-subclass name=\"org.napu.SingleSinger\" table=\"single_singer\">\n <key column=\"singler_id\"/>\n <property name=\"gender\"/>\n</joined-subclass>\n...</pre>\n3,每个具体类一张表\n<pre><union-subclass name=\"org.napu.SingleSinger\" table=\"single_singer\">\n <property name=\"gender\"/>\n</union-subclass>\n...</pre>\n一些经验:\n\n* 如果不需要多态查询:使用每个具体类一张表。\n* 一定要使用多态查询:子类中的属性相对较少,使用每个层次一张表。\n* 子类中属性较多,使用每个子类一张表。\n* 简单的问题一般选择每个层次继承一张表,复杂案例一般选择每个子类一张表","source":"_posts/Hibernate高级映射.md","raw":"title: Hibernate高级映射\ntags:\n - Hibernate\n - 对象映射\nid: 148\ncategories:\n - Hibernate\ndate: 2015-05-05 14:49:44\n---\n\n### 集合映射\n\n<set java.util.Set or java.util.SortSet><list java.util.List><bag java.util.Collection><idbag><map java.util.Map or java.util.SortMap><primitive-array><array>\n\n### 组件映射\n\n<component>\n\n1,组件类作为持久化类的单个属性\n\n2,组件类作为持久化类的集合属性:集合映射中的类\n\n3,组件类作为持久化类的对象标识符属性:数据库采用联合主键\n\n### 管理关系映射\n\n关联关系是在领域模型建模中经常使用到的一种关系,它是对现实世界中事物之间的关系最基本的表示。\n\n管联关系指的是不同持久化类之间的一种结构关系,简单地说,关联关系描述某个对象在一段时间内一直知道另一个对象的存在。\n\n关联关系包括多样性关联和方向性关联。多样性(一对多,多对多),方向性(单项关联,双向关联)\n\n映射关联关系就是把对象模型中类之间的关联关系映射成关系模型中数据库表之间的外键引用关系。在映射设计时,考虑两个问题:一是如何将对象模型中的对象之间的关系保存在关系模型的数据库表中,二是如何从关系模型的数据库表中检索出对象模型中的关联的对象。\n\n1,单向多对一\n\n多个员工属于同一部门\n\nDepartment.hbm.xml\n\nEmployee.hbm.xml\n\n<many-to-one name=\"dept\" column=\"dept_id\">\n\n2,单向一对一\n\nCitizen.hbm.xml\n\n<many-to-one name=\"idCard\" column=\"idcard_id\" unique=\"true\" cascade=\"all\">\n\nIdCard.hbm.xml\n\n每个公民只有一张身份证,这就是典型的一对一关联关系。\n\n3,双向一对一\n\n基于唯一外键的一对一双向关联\n\nCitizen.hbm.xml\n\n<many-to-one name=\"idCard\" column=\"idcard_id\" unique=\"true\" cascade=\"all\"/>\n\nIDCard.hbm.xml\n\n<one-to-one name=\"citizen\" property-ref=\"idCard\"/>\n\n基于主键的双向一对一关联\n\nCitizen.hbm.xml\n\n<generator class=\"foreign\"><param name=\"property\">idCard</param></generator>\n\n<one-to-one name=\"idCard\" constrained=\"true\" cascade=\"all\"/>\n\nIDCard.hbm.xml\n\n<one-to-one name=\"citizen\"/>\n\n4,单向一对多\n\n一个账号可以有多个订单\n<pre>//Order.java\npublic class Order{\n private Long id;\n private String orderNo;\n private Date createdTime;\n public Order(){}\n}\n//Account.java\npublic class Account{\n private Long id;\n private String loginName;\n private Set<Order> orderSet;\n public Account(){}\n}\n//Account.hbm.xml\n<set name=\"orderSet\" cascade=\"save-update\">\n <key column=\"account_id\"/>\n <one-to-many class=\"org.napu.Order\">\n<set></pre>\n5,双向一对多(多对一)\n<pre>//Order.java\npublic class Order{\n private Long id;\n private String orderNo;\n private Date createdTime;\n private Account account;\n public Order(){}\n}\n//Account.java\npublic class Account{\n private Long id;\n private String loginName;\n private Set<Order> orderSet;\n public Account(){}\n}\n//Order.hbm.xml\n<many-to-one name=\"account\" column=\"account_id\" not-null=\"true\"/>\n//Account.hbm.xml\n<Set name=\"orderSet\" cascade=\"all\" inverse=\"true\">\n <key column=\"account_id\"/>\n <one-to-many class=\"org.napu.Order\">\n</Set></pre>\n6,单向多对多\n\n大学生和课程之间的关系\n<pre>//Student.java\npublic class Student{\n private Long id;\n private String name;\n private String grade;\n private Set<Course> courses;\n public Student(){}\n}\n//Course.java\npublic class Course{\n private Long id;\n private String name;\n private Double creditHours;\n public Course(){}\n}\n//Student.hbm.xml\n<set name=\"courses\" table=\"student_course\">\n <key column=\"student_id\"/>\n <many-to-many column=\"course_id\" class=\"org.napu.Course\">\n<set></pre>\n7,双向多对多\n<pre>//Student.java\npublic class Student{\n private Long id;\n private String name;\n private String grade;\n private Set<Course> courses;\n public Student(){}\n}\n//Course.java\npublic class Course{\n private Long id;\n private String name;\n private Double creditHours;\n private Set<Student> students;\n public Course(){}\n}\n//Student.hbm.xml\n<set name=\"courses\" table=\"student_course\">\n <key column=\"student_id\"/>\n <many-to-many column=\"course_id\" class=\"org.napu.Course\"/>\n<set>\n//Course.hbm.xml\n<set name=\"\"students table=\"students_course\" inverse=\"true\">\n <key column=\"course_id\"/>\n <many-to-many column=\"student_id\" class=\"org.napu.Student\"/>\n</set></pre>\n\n### 继承关系映射\n\n继承在对象模型中是is a(是一个)的关系,在关系模型中,实体之间只有has a(有一个)的关系。\n\nHibernate提供了3中继承映射的方法。\n<pre>//Singer.java\npublic class Singer{\n private Long id;\n private String name;\n private String region;\n private String description;\n pubic Singer(){}\n}\n//SingleSinger.java\npublic class SingleSinger extends Singer{\n private Character gender;\n public SingleSinger(){}\n}\n//Bands.java\npublic class Bands extends Singer{\n private String leader;\n public Bands(){}\n}</pre>\n1,整个继承层次一张表\n<pre>//Singer.hbm.xml\n<hibernate-mapping>\n <class name=\"org.napu.Singer\" table=\"singer\">\n <id name=\"id\" column=\"id\" type=\"long\"><generator class=\"native\"/></id>\n <discriminator column=\"type\" type=\"string\"/>\n <property name=\"name\"/>\n <property name=\"region\"/>\n <property name=\"description\"/>\n <subclass name=\"org.napu.SingleSinger\" discriminator-value=\"S\">\n <property name=\"gender\"/>\n </subclass>\n <subclass name=\"org.napu.Bands\" discriminator-value=\"B\">\n <property name=\"leader\"/>\n </subclass>\n </class>\n</hibernate-mapping></pre>\n2,每个子类一张表\n<pre><joined-subclass name=\"org.napu.SingleSinger\" table=\"single_singer\">\n <key column=\"singler_id\"/>\n <property name=\"gender\"/>\n</joined-subclass>\n...</pre>\n3,每个具体类一张表\n<pre><union-subclass name=\"org.napu.SingleSinger\" table=\"single_singer\">\n <property name=\"gender\"/>\n</union-subclass>\n...</pre>\n一些经验:\n\n* 如果不需要多态查询:使用每个具体类一张表。\n* 一定要使用多态查询:子类中的属性相对较少,使用每个层次一张表。\n* 子类中属性较多,使用每个子类一张表。\n* 简单的问题一般选择每个层次继承一张表,复杂案例一般选择每个子类一张表","slug":"Hibernate高级映射","published":1,"updated":"2015-12-02T04:39:35.621Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153z60062c0tjes089p7d"},{"title":"Hibernate 数据查询","id":"155","date":"2015-05-07T01:19:25.000Z","_content":"\nHQL(Hibernate Query Language, HQL),它是Hibernate的面向对象的查询语言。\n\n1,创建查询对象\n```\nQuery query = session.createQuery(\"from Dept\");\n```\n\n2,执行查询列出结果\n(1)列出所有的结果\n\n调用Query对象的list()方法可以返回所有结果的列表。\n```\nList<Dept> depts = query.list();\n\nfor(Dept dept:depts){}\n\n```\n\n(2)列出单个结果\n```\nQuery query = session.createQuery(\"from Dept where id=1\");\n\nquery.setMaxResults(1);\n\nDept dept = (Dept) query.uniqueResult();\n\n```\n\n(3)迭代访问结果\n```\nQuery query = session.createQuery(\"from Dept\");\n\nIterator<Dept> it = query.iterate();\n\nwhile(it.next()){}\n\n```\n\n3,HQL基本语法\n\n(1)选择要查询的持久化类\n```\nString hql = \"from Dept as d\"\n```\n\nDept为持久化类名。区分大小写.\n\n(2)投影查询\n\n与SQL语句类似,HQL可以只查询出某一个或某几个属性,用select关键字来指定查询的属性名。Select id,name from Dept;\n\n可以构造两个属性参数的构造函数。\n```\npublic DeptRow(Long id, String name){}\n\nSelect new DeptRow(id,name) from Dept;\n```\n\n(3)where 条件句\n\n* 比较运算:=、<、>、 =、等等\n* 范围运算:in、 not in、 between、 not between\n* 字符串模式匹配:like,\"%\" 代表任意长度的字符串,代表任意单个字符。\n* 逻辑运算符:and、or、not\n* is empty、is not empty\n* upper(s), lower(s),concat(s1,s2),substring(s,offset,length),trim(s),length(s),locate(search,s,offset),abs(n),sqrt(n),mod(dividend,divisor)求余数,size(c)返回集合元素的个数,current_date(),current_time(),current_timestamp(),year(d)month(d)day(d)hour(d)minute(d)second(d)\n\n(4)绑定查询参数\n\n动态绑定查询参数或者字符串拼接(又注入的安全问题)\n\n按照参数名字绑定,“:”\n```\nString hql = \"from Dept where id> :id and name like :likename\";\nList<Dept> depts = session.createQuery(hql).setLong(\"id\", new Long(inputId)).setString(\"likename\", \"%\"+inputName+\"%\").list();\n\n```\n按参数位置绑定,\"?\"\n```\nString hql = \"from Dept where id> ? and name like ?\";\nList<Dept> depts = session.createQuery(hql).setLong(0, new Long(inputId)).setString(1, \"%\"+inputName+\"%\").list();\n```\n(5)distinct过滤重复值\n\n(6)聚集函数\n\n* count()\n* avg()\n* sum()\n* max()\n* min()\n(7) order by 对结果排序\n\n默认是升序,关键字asc表示升序,desc表示降序。\n\n(8)group by对记录分组\n\n(9)having 对分组后数据进行条件过滤\n```\nString hql = \"select e.dept.name from Employee e group by e.dept having count(e)>1\"\n\n```\n4,分页查询\n\n当批量查询数据时,如果数据量非常大,怎么办?\n\n* setFistResult(int firstResult):设置从第几条数据开始查询\n* setMaxResults(int maxResult):设置每次查询的返回的最大对象数\n```\npublic static List<Employee> findEmployees(int pageNo, int pageSize){\n SessionFactory sessionFactory = new Configuration().configure().buildSessionFactory();\n Session session = sessionFactory.openSession();\n session.beginTransaction();\n String hql = \"from Employee\"\n List<Employee> empls = session.CreateQuery(hql).setFirstResult((pageNo-1)*pageSize).setMaxResults(pageSize).list();\n session.getTransaction().commit();\n session.close();\n return empls;\n}\n```\n5,批量修改和删除\n\nHibernate3中新增update 和delete语句。\n```\nQuery query = session.createQuery(\"delete Dept d where d.name like :likename\").setString(\"likename\",\"%三%\");\nint count = query.executeUpdate();\n```\n6,连接查询\n\n类似于SQL,支持连接查询\n```\ninner join(内连接):可简写为join。列出这些相关联的实体类中满足连接条件的对象。\nleft outer join(左连接):可简写为left join。不仅列出来这些相关联实体类中满足连接条件的对象,而且还包含连接左边的实体类中所有符合搜索条件(where 条件或者having 条件)\nright outer join(右连接):right join。不仅列出来这些相关联实体类中满足连接条件的对象,而且还包含连接右边的实体类中所有符合搜索条件(where 条件或者having 条件)\nfull join(全连接)\n```\n7,抓取连接查询\n\nfetch来做数据抓取,所谓抓取,是指从数据库加载一个对象的数据时,同时把它所关联的对象和集合的数据都一起加载出来,以便减少SQL语句的数据,从而提高查询效率。\n```\nString hql = \"FROM Dept d LEFT JOIN FETCH d.employees e WHERE d.name LIKE '%web%'\";\nList<Dept> list = session.createQuery(hql).list();\nSet<Dept> depts = new HashSet<Dept> (list);\nfor(Dept dept : depts){\nfor(Employee empl : dept.getEmployees()){\nempl.getLoginName();\n}\n}\n\n```\n8,子查询\n```\nString hql = \"FROM Dept d WHERE (SELECT COUNT(E) FROM d.employees e)>1\";\nList<Dept> list = session.createQuery(hql).list();\nfor(Dept dept : list){\ndept.getName;\n}\n```\n9,命名查询\n\n命名查询是指将HQL查询语句编写在映射文件里,在程序中通过Session的getNameQuery()方法来获取。\n```\n\n<hibernate-mapping>\n<class name=\"org.napu.Dept\"></class>\n<query name=\"findDeptsByCondition\">\n<![CDATA[from Dept d where d.name like :likename]]>\n</query>\n</hibernate-mapping>\nList<Dept> depts = session.getNamedQuery(\"findEdeptsByCondition\").setString(\"likeName\",\"%a%\").list();\n```\n\n## Criteria Queries\n\nCriteria叫标准化条件查询,它是一种比HQL更加面向对象的查询语言。QBC(Query By Criteria),特别适当在运行时才能创建查询条件的查询。程序开发时不知道,程序运行时才知道。\n\n### Native SQL Queries\n\n1,实体查询\n```\n\nString sql = \"SELECT * FROM dept WHERE id > :id limit 3\";\nList<Dept> depts = session.createSQLQuery(sql).addEntity(Dept.class).setLong(“id”,1).list();\nfor(Dept dept : depts){\ndept.getName();\n}\n\n//_____\nString sql = \"Select {d.*}, {e.*} FROM dept d JOIN employee e ON d.id = e.dept_id\";\nList list = session.CreateSQLQuery(sql).addEntity(\"d\",Dept.class).addEntity(\"e\",Employee.class).list();\nfor( Iterator it = list.iterator(); it.hasNext();){\n Object[] obj = (Object[]) iterator.next();\n Dept dept = (Dept)obj[0];\n Employee empl = (Employee) obj[1];\n}\n\n```\n2,标量查询\n\n将查询结果转化为标量值。.addScalar(\"countNum\",Hibernate.LONG)\n\n3,定义成命名查询来使用\n```\n\n<sql-query name=\"findDeptAndEmployee\">\n<![CDATA[Select {d.*}, {e.*} FROM dept d JOIN employee e ON d.id = e.dept_id]]>\n<return alias=\"d\" class=\"org.napu.Dept\"/>\n<return alias=\"e\" class=\"org.napu.Employee\"/>\n</sql-query>\n```\n\n### 调用存储过程\n\n1,编写过程\n```\ncreate procedure select_depts_by_likename(in likeName varchar(20))\nbegin\n select * from dept where name like likeName;\nend;\n```\n2,把过程映射为命名查询\n```\n<sql-query name=\"findDeptAndEmployee\">\n<return alias=\"d\" class=\"org.napu.Dept\">\n<return-property name=\"id\" column=\"id\"/>\n<return-property name=\"name\" column=\"name\"/>\n<return-property name=\"createdTime\" column=\"created_time\"/>\n</return>\n{call select_depts_by_likename(:likeName)}\n</sql-query>\n```\n3,调用过程\n```\nList<Dept> depts = session.getNamedQuery(\"findEdeptsByCondition\").setString(\"likeName\",\"%a%\").list();\n```\n","source":"_posts/Hibernate 数据查询.md","raw":"title: Hibernate 数据查询\ntags:\n - HQL\n - QBC\n - Query\n - stored procedure\nid: 155\ncategories:\n - Hibernate\ndate: 2015-05-07 09:19:25\n---\n\nHQL(Hibernate Query Language, HQL),它是Hibernate的面向对象的查询语言。\n\n1,创建查询对象\n```\nQuery query = session.createQuery(\"from Dept\");\n```\n\n2,执行查询列出结果\n(1)列出所有的结果\n\n调用Query对象的list()方法可以返回所有结果的列表。\n```\nList<Dept> depts = query.list();\n\nfor(Dept dept:depts){}\n\n```\n\n(2)列出单个结果\n```\nQuery query = session.createQuery(\"from Dept where id=1\");\n\nquery.setMaxResults(1);\n\nDept dept = (Dept) query.uniqueResult();\n\n```\n\n(3)迭代访问结果\n```\nQuery query = session.createQuery(\"from Dept\");\n\nIterator<Dept> it = query.iterate();\n\nwhile(it.next()){}\n\n```\n\n3,HQL基本语法\n\n(1)选择要查询的持久化类\n```\nString hql = \"from Dept as d\"\n```\n\nDept为持久化类名。区分大小写.\n\n(2)投影查询\n\n与SQL语句类似,HQL可以只查询出某一个或某几个属性,用select关键字来指定查询的属性名。Select id,name from Dept;\n\n可以构造两个属性参数的构造函数。\n```\npublic DeptRow(Long id, String name){}\n\nSelect new DeptRow(id,name) from Dept;\n```\n\n(3)where 条件句\n\n* 比较运算:=、<、>、 =、等等\n* 范围运算:in、 not in、 between、 not between\n* 字符串模式匹配:like,\"%\" 代表任意长度的字符串,代表任意单个字符。\n* 逻辑运算符:and、or、not\n* is empty、is not empty\n* upper(s), lower(s),concat(s1,s2),substring(s,offset,length),trim(s),length(s),locate(search,s,offset),abs(n),sqrt(n),mod(dividend,divisor)求余数,size(c)返回集合元素的个数,current_date(),current_time(),current_timestamp(),year(d)month(d)day(d)hour(d)minute(d)second(d)\n\n(4)绑定查询参数\n\n动态绑定查询参数或者字符串拼接(又注入的安全问题)\n\n按照参数名字绑定,“:”\n```\nString hql = \"from Dept where id> :id and name like :likename\";\nList<Dept> depts = session.createQuery(hql).setLong(\"id\", new Long(inputId)).setString(\"likename\", \"%\"+inputName+\"%\").list();\n\n```\n按参数位置绑定,\"?\"\n```\nString hql = \"from Dept where id> ? and name like ?\";\nList<Dept> depts = session.createQuery(hql).setLong(0, new Long(inputId)).setString(1, \"%\"+inputName+\"%\").list();\n```\n(5)distinct过滤重复值\n\n(6)聚集函数\n\n* count()\n* avg()\n* sum()\n* max()\n* min()\n(7) order by 对结果排序\n\n默认是升序,关键字asc表示升序,desc表示降序。\n\n(8)group by对记录分组\n\n(9)having 对分组后数据进行条件过滤\n```\nString hql = \"select e.dept.name from Employee e group by e.dept having count(e)>1\"\n\n```\n4,分页查询\n\n当批量查询数据时,如果数据量非常大,怎么办?\n\n* setFistResult(int firstResult):设置从第几条数据开始查询\n* setMaxResults(int maxResult):设置每次查询的返回的最大对象数\n```\npublic static List<Employee> findEmployees(int pageNo, int pageSize){\n SessionFactory sessionFactory = new Configuration().configure().buildSessionFactory();\n Session session = sessionFactory.openSession();\n session.beginTransaction();\n String hql = \"from Employee\"\n List<Employee> empls = session.CreateQuery(hql).setFirstResult((pageNo-1)*pageSize).setMaxResults(pageSize).list();\n session.getTransaction().commit();\n session.close();\n return empls;\n}\n```\n5,批量修改和删除\n\nHibernate3中新增update 和delete语句。\n```\nQuery query = session.createQuery(\"delete Dept d where d.name like :likename\").setString(\"likename\",\"%三%\");\nint count = query.executeUpdate();\n```\n6,连接查询\n\n类似于SQL,支持连接查询\n```\ninner join(内连接):可简写为join。列出这些相关联的实体类中满足连接条件的对象。\nleft outer join(左连接):可简写为left join。不仅列出来这些相关联实体类中满足连接条件的对象,而且还包含连接左边的实体类中所有符合搜索条件(where 条件或者having 条件)\nright outer join(右连接):right join。不仅列出来这些相关联实体类中满足连接条件的对象,而且还包含连接右边的实体类中所有符合搜索条件(where 条件或者having 条件)\nfull join(全连接)\n```\n7,抓取连接查询\n\nfetch来做数据抓取,所谓抓取,是指从数据库加载一个对象的数据时,同时把它所关联的对象和集合的数据都一起加载出来,以便减少SQL语句的数据,从而提高查询效率。\n```\nString hql = \"FROM Dept d LEFT JOIN FETCH d.employees e WHERE d.name LIKE '%web%'\";\nList<Dept> list = session.createQuery(hql).list();\nSet<Dept> depts = new HashSet<Dept> (list);\nfor(Dept dept : depts){\nfor(Employee empl : dept.getEmployees()){\nempl.getLoginName();\n}\n}\n\n```\n8,子查询\n```\nString hql = \"FROM Dept d WHERE (SELECT COUNT(E) FROM d.employees e)>1\";\nList<Dept> list = session.createQuery(hql).list();\nfor(Dept dept : list){\ndept.getName;\n}\n```\n9,命名查询\n\n命名查询是指将HQL查询语句编写在映射文件里,在程序中通过Session的getNameQuery()方法来获取。\n```\n\n<hibernate-mapping>\n<class name=\"org.napu.Dept\"></class>\n<query name=\"findDeptsByCondition\">\n<![CDATA[from Dept d where d.name like :likename]]>\n</query>\n</hibernate-mapping>\nList<Dept> depts = session.getNamedQuery(\"findEdeptsByCondition\").setString(\"likeName\",\"%a%\").list();\n```\n\n## Criteria Queries\n\nCriteria叫标准化条件查询,它是一种比HQL更加面向对象的查询语言。QBC(Query By Criteria),特别适当在运行时才能创建查询条件的查询。程序开发时不知道,程序运行时才知道。\n\n### Native SQL Queries\n\n1,实体查询\n```\n\nString sql = \"SELECT * FROM dept WHERE id > :id limit 3\";\nList<Dept> depts = session.createSQLQuery(sql).addEntity(Dept.class).setLong(“id”,1).list();\nfor(Dept dept : depts){\ndept.getName();\n}\n\n//_____\nString sql = \"Select {d.*}, {e.*} FROM dept d JOIN employee e ON d.id = e.dept_id\";\nList list = session.CreateSQLQuery(sql).addEntity(\"d\",Dept.class).addEntity(\"e\",Employee.class).list();\nfor( Iterator it = list.iterator(); it.hasNext();){\n Object[] obj = (Object[]) iterator.next();\n Dept dept = (Dept)obj[0];\n Employee empl = (Employee) obj[1];\n}\n\n```\n2,标量查询\n\n将查询结果转化为标量值。.addScalar(\"countNum\",Hibernate.LONG)\n\n3,定义成命名查询来使用\n```\n\n<sql-query name=\"findDeptAndEmployee\">\n<![CDATA[Select {d.*}, {e.*} FROM dept d JOIN employee e ON d.id = e.dept_id]]>\n<return alias=\"d\" class=\"org.napu.Dept\"/>\n<return alias=\"e\" class=\"org.napu.Employee\"/>\n</sql-query>\n```\n\n### 调用存储过程\n\n1,编写过程\n```\ncreate procedure select_depts_by_likename(in likeName varchar(20))\nbegin\n select * from dept where name like likeName;\nend;\n```\n2,把过程映射为命名查询\n```\n<sql-query name=\"findDeptAndEmployee\">\n<return alias=\"d\" class=\"org.napu.Dept\">\n<return-property name=\"id\" column=\"id\"/>\n<return-property name=\"name\" column=\"name\"/>\n<return-property name=\"createdTime\" column=\"created_time\"/>\n</return>\n{call select_depts_by_likename(:likeName)}\n</sql-query>\n```\n3,调用过程\n```\nList<Dept> depts = session.getNamedQuery(\"findEdeptsByCondition\").setString(\"likeName\",\"%a%\").list();\n```\n","slug":"Hibernate 数据查询","published":1,"updated":"2015-12-02T05:31:55.702Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153z90067c0tjmfrvq2i1"},{"title":"Hibernate 基本配置及操作","id":"135","date":"2015-05-04T01:14:14.000Z","_content":"\n### Hibernate 全局配置文件\n\n1,hibernate.properties;hibernate.cfg.xml;\n\nhibernate框架在启动的时候会在应用的ClassPath路径中查询有没有这两个文件,如果有则加载他们的配置参数。\n\n在hibernate.cfg.xml文件中,首先配置session-factory元素来指定一个SessionFactory的配置,\n<pre><hibernate-configuration>\n<session-factory>\n<property name=\"hibernate.dialect\">org.hibernate.dialect.MySQLDialect</property>\n</session-factory>\n</hibernate-configuration></pre>\n2, JDBC属性\n\n* hibernate.connection.url\n* hibernate.connection.driver_class\n* hibernate.connection.username\n* hibernate.connection.password\n* hibernate.connection.isolation:设置JDBC事务的隔离级别\n* hibernate.connection.batch_size:批量操作的记录数\n3,连接池属性\n\n通常要使用第三方的连接池技术。C3P0这个开源的连接池产品为例进行链接数据库参数的配置。\n<pre><property name=\"hibernate.c3p0.min_size\">5</property>\n<property name=\"hibernate.c3p0.max_size\">20</property>\n<property name=\"hibernate.c3p0.timeout\">1800</property>\n<property name=\"hibernate.c3p0.max_statement\">100</property></pre>\n4,缓存属性\n\n用来配置Hibernate使用的二级缓存策略。常用的配置如下:\n\n* hibernate.cache.provider_class:指定第三方的缓存提供类的名称。ehcache缓存插件可做为Hibernate的二级缓存提供者。org.hibernate.cache.EhCacheProvider\n* hibernate.cache.use_query_cache:指定是否开启Hibernate的查询缓存。可选值为false和true。默认为false。\n5,其他属性\n\n* hibernate.show_sql:指定是否把Hibernate运行时的SQL语句输出到控制台。\n* hibernate.format_sql:指定是否对Hibernate运行时产生的SQL语句进行格式化便于阅读。\n* hibernate.hbm2ddl.auto:指定应用程序在运行时,当产生SessionFactory实例时对是否自动检查数据库结构,或者将数据库schema的DDL导出到数据库。可选值:Validate(检查数据库结构),update(数据库结构发生变化时修改),create(将数据库schema的DDL导出到数据库),create_drop(在SessionFactory中实例创建时间数据schema的DDL导出到数据库,在SessionFactory被显示关闭时将数据库自动删除)。\n* hibernate.current_session_context_class:为当前Session指定一个策略。常用值:jta(当前Session根据JTA来跟踪和界定)、Thread(前Session通过当前执行的线程来跟踪和界定)\n\n### 对象关系映射文件\n\nHibernate的对象关系映射文件把面相对象中的实体类对象映射到数据库中的实体,把实体类之间的关联关系也映射到数据库中多个表之间的相互关系中。\n<pre>XML文件的起始行,指定XML的版本和编码方式\n<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n映射文件的所使用的DTD声明\n<!DOCTYPE hibernate-mapping PUBLIC\n \"-//Hibernate/Hibernate Mapping DTD 3.0//EN\"\n \"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd\">\n\n<!-- Hibernate对象关系映射文件的根元素 -->\n<hibernate-mapping>\n <!-- class元素用来定义一个持久化类及对应的数据库表 -->\n <class name=\"com.qiujy.domain.Account\" table=\"account\">\n <!-- \n id元素:指定每个持久化类的唯一标识(即对象标识符OID)到数据库表主键字段的映射 \n name属性:指定持久化类的OID名\n column属性:指定数据库表主键字段名。此属性的名和映射到数据库表的字段名相同时,可省略\n type属性:指定主键映射时所使用的Hibernate类型名。此属性的类型为基本数据类型和String类型时,可省略\n -->\n <id name=\"id\" column=\"id\" type=\"long\">\n <!-- generator元素:指定对象标识符的生成器名。\n native生成器把对象标识符值的生成工作交由底层数据库来完成\n -->\n <generator class=\"native\" />\n </id>\n <!-- \n property元素:指定持久化类的每一个要映射到数据库表的字段的属性的信息。\n name属性;指定持久化类中要映射到数据库表字段的属性名。\n column属性:指定对应的表的字段名。此属性的名和映射到数据库表的字段名相同时,可省略\n type属性:指定属性映射所使用的Hibernate类型名。此属性的类型为基本数据类型和String类型时,可省略\n not-null属性:指定此属性映射到数据库表的字段值是否允许为值 \n -->\n <property name=\"loginname\" column=\"loginname\" type=\"string\" not-null=\"true\"/>\n <property name=\"password\" column=\"password\" type=\"string\" not-null=\"true\"/>\n <property name=\"email\" column=\"email\" type=\"string\"/>\n <!-- 属性类型为Date类型的必须要明确指定使用的Hibernate类型名 -->\n <property name=\"registrationTime\" column=\"registration_time\" type=\"timestamp\"/>\n </class>\n</hibernate-mapping></pre>\n1,映射持久化类\n\n在Hibernate对象关系映射文件中,使用class元素来映射持久化类到数据库表中\n\n* name:指定要映射的持久化类的名称\n* table:指定和此持久化类对应的数据库表名\n2,映射对象标识符\n\nHibernate中要求每一个持久化类都有一个对象标识符来唯一标识它的每一个实例。对象标识符的值是数据库表中行的主键。\n\n3,对象标识符生成方式\n\n可以通过ID元素的generator子元素,指定对象标识符的生成器。\n\n1. 代理对象标识符:在一个持久化类中添加一个没有业务意义的属性来作为对象标识符,这样应用程序的领域模型更具有扩展性。\n2. 自然对象标识符:由许多遗留的SQL数据模型使用了带有业务意义的主键组成。\n\n* 如果对象标识符的数据类型为整数型(Long,int,short)或对应的包装类型,为提高应用程序在不同数据库上的移植能力,建议使用native。\n* 如果对象标识符的数据类型的为字符串型,为提高应用程序的在不同数据库上的移植能力,建议用UUID。\n* 如果应用程序是先有数据库的物理模型后偶建立实体模型,且使用了自然主键,那么选择assigned.\n4,映射普通属性\n\n对象标识符,版本号,自定义数据类型属性以外的属性。通过class元素的property子元素来映射<property name=\"属性名\" column=\"列名称\" type=“映射属性”/>\n\n5,Hibernate映射的数据类型\n\n\n\n ","source":"_posts/Hibernate 基本配置及操作.md","raw":"title: Hibernate 基本配置及操作\ntags:\n - Configuration\n - Hibernate\nid: 135\ncategories:\n - Hibernate\ndate: 2015-05-04 09:14:14\n---\n\n### Hibernate 全局配置文件\n\n1,hibernate.properties;hibernate.cfg.xml;\n\nhibernate框架在启动的时候会在应用的ClassPath路径中查询有没有这两个文件,如果有则加载他们的配置参数。\n\n在hibernate.cfg.xml文件中,首先配置session-factory元素来指定一个SessionFactory的配置,\n<pre><hibernate-configuration>\n<session-factory>\n<property name=\"hibernate.dialect\">org.hibernate.dialect.MySQLDialect</property>\n</session-factory>\n</hibernate-configuration></pre>\n2, JDBC属性\n\n* hibernate.connection.url\n* hibernate.connection.driver_class\n* hibernate.connection.username\n* hibernate.connection.password\n* hibernate.connection.isolation:设置JDBC事务的隔离级别\n* hibernate.connection.batch_size:批量操作的记录数\n3,连接池属性\n\n通常要使用第三方的连接池技术。C3P0这个开源的连接池产品为例进行链接数据库参数的配置。\n<pre><property name=\"hibernate.c3p0.min_size\">5</property>\n<property name=\"hibernate.c3p0.max_size\">20</property>\n<property name=\"hibernate.c3p0.timeout\">1800</property>\n<property name=\"hibernate.c3p0.max_statement\">100</property></pre>\n4,缓存属性\n\n用来配置Hibernate使用的二级缓存策略。常用的配置如下:\n\n* hibernate.cache.provider_class:指定第三方的缓存提供类的名称。ehcache缓存插件可做为Hibernate的二级缓存提供者。org.hibernate.cache.EhCacheProvider\n* hibernate.cache.use_query_cache:指定是否开启Hibernate的查询缓存。可选值为false和true。默认为false。\n5,其他属性\n\n* hibernate.show_sql:指定是否把Hibernate运行时的SQL语句输出到控制台。\n* hibernate.format_sql:指定是否对Hibernate运行时产生的SQL语句进行格式化便于阅读。\n* hibernate.hbm2ddl.auto:指定应用程序在运行时,当产生SessionFactory实例时对是否自动检查数据库结构,或者将数据库schema的DDL导出到数据库。可选值:Validate(检查数据库结构),update(数据库结构发生变化时修改),create(将数据库schema的DDL导出到数据库),create_drop(在SessionFactory中实例创建时间数据schema的DDL导出到数据库,在SessionFactory被显示关闭时将数据库自动删除)。\n* hibernate.current_session_context_class:为当前Session指定一个策略。常用值:jta(当前Session根据JTA来跟踪和界定)、Thread(前Session通过当前执行的线程来跟踪和界定)\n\n### 对象关系映射文件\n\nHibernate的对象关系映射文件把面相对象中的实体类对象映射到数据库中的实体,把实体类之间的关联关系也映射到数据库中多个表之间的相互关系中。\n<pre>XML文件的起始行,指定XML的版本和编码方式\n<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n映射文件的所使用的DTD声明\n<!DOCTYPE hibernate-mapping PUBLIC\n \"-//Hibernate/Hibernate Mapping DTD 3.0//EN\"\n \"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd\">\n\n<!-- Hibernate对象关系映射文件的根元素 -->\n<hibernate-mapping>\n <!-- class元素用来定义一个持久化类及对应的数据库表 -->\n <class name=\"com.qiujy.domain.Account\" table=\"account\">\n <!-- \n id元素:指定每个持久化类的唯一标识(即对象标识符OID)到数据库表主键字段的映射 \n name属性:指定持久化类的OID名\n column属性:指定数据库表主键字段名。此属性的名和映射到数据库表的字段名相同时,可省略\n type属性:指定主键映射时所使用的Hibernate类型名。此属性的类型为基本数据类型和String类型时,可省略\n -->\n <id name=\"id\" column=\"id\" type=\"long\">\n <!-- generator元素:指定对象标识符的生成器名。\n native生成器把对象标识符值的生成工作交由底层数据库来完成\n -->\n <generator class=\"native\" />\n </id>\n <!-- \n property元素:指定持久化类的每一个要映射到数据库表的字段的属性的信息。\n name属性;指定持久化类中要映射到数据库表字段的属性名。\n column属性:指定对应的表的字段名。此属性的名和映射到数据库表的字段名相同时,可省略\n type属性:指定属性映射所使用的Hibernate类型名。此属性的类型为基本数据类型和String类型时,可省略\n not-null属性:指定此属性映射到数据库表的字段值是否允许为值 \n -->\n <property name=\"loginname\" column=\"loginname\" type=\"string\" not-null=\"true\"/>\n <property name=\"password\" column=\"password\" type=\"string\" not-null=\"true\"/>\n <property name=\"email\" column=\"email\" type=\"string\"/>\n <!-- 属性类型为Date类型的必须要明确指定使用的Hibernate类型名 -->\n <property name=\"registrationTime\" column=\"registration_time\" type=\"timestamp\"/>\n </class>\n</hibernate-mapping></pre>\n1,映射持久化类\n\n在Hibernate对象关系映射文件中,使用class元素来映射持久化类到数据库表中\n\n* name:指定要映射的持久化类的名称\n* table:指定和此持久化类对应的数据库表名\n2,映射对象标识符\n\nHibernate中要求每一个持久化类都有一个对象标识符来唯一标识它的每一个实例。对象标识符的值是数据库表中行的主键。\n\n3,对象标识符生成方式\n\n可以通过ID元素的generator子元素,指定对象标识符的生成器。\n\n1. 代理对象标识符:在一个持久化类中添加一个没有业务意义的属性来作为对象标识符,这样应用程序的领域模型更具有扩展性。\n2. 自然对象标识符:由许多遗留的SQL数据模型使用了带有业务意义的主键组成。\n\n* 如果对象标识符的数据类型为整数型(Long,int,short)或对应的包装类型,为提高应用程序在不同数据库上的移植能力,建议使用native。\n* 如果对象标识符的数据类型的为字符串型,为提高应用程序的在不同数据库上的移植能力,建议用UUID。\n* 如果应用程序是先有数据库的物理模型后偶建立实体模型,且使用了自然主键,那么选择assigned.\n4,映射普通属性\n\n对象标识符,版本号,自定义数据类型属性以外的属性。通过class元素的property子元素来映射<property name=\"属性名\" column=\"列名称\" type=“映射属性”/>\n\n5,Hibernate映射的数据类型\n\n\n\n ","slug":"Hibernate 基本配置及操作","published":1,"updated":"2015-12-02T04:39:35.620Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153zd006hc0tjdg8ahx2y"},{"title":"HashMap 和 HashTable的区别","id":"181","date":"2015-05-11T06:03:57.000Z","_content":"\n1,类的定义\n<pre>Public class Hashtable extends Dictionary implements Map, Cloneable, java.io.Serializable\n\nPublic class HashMap extends AbstractMap implements Map, Cloneable, Serializable</pre>\n可见Hashtable继承自Dictionary而HashMap继承自AbstractMap\n\nHashtable的put方法\n<pre>public synchronized V put(K key, V value){\n if(value == null){\n throws new NullPointerException();\n }\n Entry tab[] = table;\n int hash = key.hashCode();\n int index = (hash $ 0x7FFFFFFF)% tab.length;\n for(Entry e = tab[index]; e != null; e=e.next){\n if((e.hash == hash)&&e.key.equals(key)){\n V old = e.value;\n e.value = value;\n return old;\n }\n }\n modCount++;\n if(count >= threshold){\n rehash();\n tab = table;\n index = (hash & 0x7FFFFFFF) % tab.length;\n }\n Entry e = tab[index];\n tab[index] = new Entry(hash,key,value,e);\n count++;\n return null;\n}</pre>\n1,put方法时同步的\n\n2,方法不允许value==null\n\n3,方法调用了key的hashCode方法,如果key == null,会抛出空指针异常\n\nHashMap的put方法\n<pre>public V put(K key, V value){//#####\n if(key == null)//####\n return putForNullKey(value);\n int hash = hash(key.hashCode());\n int i = indexFor(hash, table.length);\n for(Entry e=table[i];e!=null; e=e.next){\n Object k;\n if(e.hash == hash && ((k = e.key)==key||key.equals(k))){\n V oldValue = e.value;\n e.value = value;\n e.recordAccess(this);\n return oldValue;\n }\n }\n modCount++;\n addEntry(hash, key, value, i);//###\n return null;\n}</pre>\n1,方法为非同步的\n\n2,方法允许key==null\n\n3,方法并没有对value值做任何调整,所以允许null\n<table>\n<tbody>\n<tr>\n<td></td>\n<td>HashMap</td>\n<td>HashTable</td>\n</tr>\n<tr>\n<td>父类</td>\n<td>AbstractMap</td>\n<td>Dictionary</td>\n</tr>\n<tr>\n<td>Value是否为空</td>\n<td>可为空</td>\n<td>不可</td>\n</tr>\n</tbody>\n</table>\nHashMap是HashTable的轻量级实现(非线程安全的实现),他们都完成了Map接口。\n\n主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于HashTable。\n\nHashMap把Hashtable的contains方法去掉,改成containsvalue和containsKey。因为contains方法容易让人引起误解。\n\nHashtable继承自Dictionary类,而HashMap是Map interface的接口。\n\n最大的不同是,Hashtable的方法时Synchronize的,而HashMap不是,在多线程访问Hashtable时,不需要自己为它的方法同步,而HashMap就必须为之提供同步Collection.synchronizedMap。\n\nHashtable和HashMap采用hash/rehash算法都大概一样,所以性能不会有很大的差异。","source":"_posts/HashMap 和 HashTable的区别.md","raw":"title: HashMap 和 HashTable的区别\ntags:\n - Hashmap\n - hashtable\nid: 181\ncategories:\n - Java\ndate: 2015-05-11 14:03:57\n---\n\n1,类的定义\n<pre>Public class Hashtable extends Dictionary implements Map, Cloneable, java.io.Serializable\n\nPublic class HashMap extends AbstractMap implements Map, Cloneable, Serializable</pre>\n可见Hashtable继承自Dictionary而HashMap继承自AbstractMap\n\nHashtable的put方法\n<pre>public synchronized V put(K key, V value){\n if(value == null){\n throws new NullPointerException();\n }\n Entry tab[] = table;\n int hash = key.hashCode();\n int index = (hash $ 0x7FFFFFFF)% tab.length;\n for(Entry e = tab[index]; e != null; e=e.next){\n if((e.hash == hash)&&e.key.equals(key)){\n V old = e.value;\n e.value = value;\n return old;\n }\n }\n modCount++;\n if(count >= threshold){\n rehash();\n tab = table;\n index = (hash & 0x7FFFFFFF) % tab.length;\n }\n Entry e = tab[index];\n tab[index] = new Entry(hash,key,value,e);\n count++;\n return null;\n}</pre>\n1,put方法时同步的\n\n2,方法不允许value==null\n\n3,方法调用了key的hashCode方法,如果key == null,会抛出空指针异常\n\nHashMap的put方法\n<pre>public V put(K key, V value){//#####\n if(key == null)//####\n return putForNullKey(value);\n int hash = hash(key.hashCode());\n int i = indexFor(hash, table.length);\n for(Entry e=table[i];e!=null; e=e.next){\n Object k;\n if(e.hash == hash && ((k = e.key)==key||key.equals(k))){\n V oldValue = e.value;\n e.value = value;\n e.recordAccess(this);\n return oldValue;\n }\n }\n modCount++;\n addEntry(hash, key, value, i);//###\n return null;\n}</pre>\n1,方法为非同步的\n\n2,方法允许key==null\n\n3,方法并没有对value值做任何调整,所以允许null\n<table>\n<tbody>\n<tr>\n<td></td>\n<td>HashMap</td>\n<td>HashTable</td>\n</tr>\n<tr>\n<td>父类</td>\n<td>AbstractMap</td>\n<td>Dictionary</td>\n</tr>\n<tr>\n<td>Value是否为空</td>\n<td>可为空</td>\n<td>不可</td>\n</tr>\n</tbody>\n</table>\nHashMap是HashTable的轻量级实现(非线程安全的实现),他们都完成了Map接口。\n\n主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于HashTable。\n\nHashMap把Hashtable的contains方法去掉,改成containsvalue和containsKey。因为contains方法容易让人引起误解。\n\nHashtable继承自Dictionary类,而HashMap是Map interface的接口。\n\n最大的不同是,Hashtable的方法时Synchronize的,而HashMap不是,在多线程访问Hashtable时,不需要自己为它的方法同步,而HashMap就必须为之提供同步Collection.synchronizedMap。\n\nHashtable和HashMap采用hash/rehash算法都大概一样,所以性能不会有很大的差异。","slug":"HashMap 和 HashTable的区别","published":1,"updated":"2015-12-02T04:39:35.619Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153zf006mc0tj60ik8gyq"},{"title":"Abstract 与 Interface的区别","id":"190","date":"2015-05-12T18:43:38.000Z","_content":"\n1,abstract class 在Java语言中表示一种继承关系,一个类只能使用一次继承关系。但是一个类可以有多个实现的interface。\n\n2,在Abstract class中可以有自己的数据成员,也可以有非abstract的成员方法,而在interface中,只能够有静态的不能被修改的数据成员(必须是static final,不过在interface里面一般不定义数据成员),所有的成员方法都是abstract的。\n\n3,abstract class和interface所反映出的设计理念不同,其中abstract class表示的是“is - a”关系,interface表示的是“like - a”。\n\n4,实现抽象类和接口的类必须实现其中的所有方法。抽象类中可以有非抽象方法。接口中则不能实现方法。\n\n5,接口中定义的变量默认是public static final 型,且必须给其初值,所以实现类中不能重新定义,也不能改变变量。\n\n6,抽象类中的变量默认是friendly型,其值可以再子类中重新定义,也可以重新赋值。\n\n7,接口中的方法默认都是 public abstract 类型的。\n\n总结:\n\n* 接口体现的是一种设计规范,抽象类体现的是模板式设计。\n* 接口里的方法必须是public abstract抽象方法,抽象类里可以有方法实现。\n* 接口里不可以定义静态方法,抽象类可以。\n* 接口里的变量全部为静态常量,抽象类里可有普通变量。\n* 接口里不可以有构造函数和初始化块,抽象类里可以有。\n* 一个类可以实现多个接口,但只能集成一个抽象类。\n接口是一种非常有效的编程方法,它让对象的定义与实现分离,从而可以在不破坏现有应用程序的情况下使对象得以完善与进化。接口消除了实现继承的一个大问题,就是在对设 计实施后再对其进行更改时很可能对代码产生破坏。即使实现继承允许类从基类继承实现,在类首次发布时仍然会使我们不得不为设计做很多的抉择。如果原有的设想不正确,并非 总可以在以后的版本中对代码进行安全的更改。\n\n接口一旦被定义和接受,就必须保持不变,以保护为使用该接口而编写的应用程序。接口发布后,就不能对其进行更改。这是我们进行组件设计的一个重要原则,叫做‘接口不变性’。","source":"_posts/Abstract 与 Interface的区别.md","raw":"title: Abstract 与 Interface的区别\ntags:\n - Abstract\n - Interface\nid: 190\ncategories:\n - Java\ndate: 2015-05-13 02:43:38\n---\n\n1,abstract class 在Java语言中表示一种继承关系,一个类只能使用一次继承关系。但是一个类可以有多个实现的interface。\n\n2,在Abstract class中可以有自己的数据成员,也可以有非abstract的成员方法,而在interface中,只能够有静态的不能被修改的数据成员(必须是static final,不过在interface里面一般不定义数据成员),所有的成员方法都是abstract的。\n\n3,abstract class和interface所反映出的设计理念不同,其中abstract class表示的是“is - a”关系,interface表示的是“like - a”。\n\n4,实现抽象类和接口的类必须实现其中的所有方法。抽象类中可以有非抽象方法。接口中则不能实现方法。\n\n5,接口中定义的变量默认是public static final 型,且必须给其初值,所以实现类中不能重新定义,也不能改变变量。\n\n6,抽象类中的变量默认是friendly型,其值可以再子类中重新定义,也可以重新赋值。\n\n7,接口中的方法默认都是 public abstract 类型的。\n\n总结:\n\n* 接口体现的是一种设计规范,抽象类体现的是模板式设计。\n* 接口里的方法必须是public abstract抽象方法,抽象类里可以有方法实现。\n* 接口里不可以定义静态方法,抽象类可以。\n* 接口里的变量全部为静态常量,抽象类里可有普通变量。\n* 接口里不可以有构造函数和初始化块,抽象类里可以有。\n* 一个类可以实现多个接口,但只能集成一个抽象类。\n接口是一种非常有效的编程方法,它让对象的定义与实现分离,从而可以在不破坏现有应用程序的情况下使对象得以完善与进化。接口消除了实现继承的一个大问题,就是在对设 计实施后再对其进行更改时很可能对代码产生破坏。即使实现继承允许类从基类继承实现,在类首次发布时仍然会使我们不得不为设计做很多的抉择。如果原有的设想不正确,并非 总可以在以后的版本中对代码进行安全的更改。\n\n接口一旦被定义和接受,就必须保持不变,以保护为使用该接口而编写的应用程序。接口发布后,就不能对其进行更改。这是我们进行组件设计的一个重要原则,叫做‘接口不变性’。","slug":"Abstract 与 Interface的区别","published":1,"updated":"2015-12-02T04:39:35.619Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153zi006sc0tjm0erxekp"},{"title":"AIO","date":"2015-12-03T01:50:20.000Z","_content":"\n## AIO Programing\nNIO 2.0 引入了新的异步通道的概念,并提拱了异步文件通道和异步套接字通道的实现。异步通道通过两种方式获取操作结果。\n* 通过java.util.concurrent.Future类来表示异步操作的结果。\n* 在执行异步操作的时候传入一个java.nio.channel。\nCompletionHandler 接口的实现类作为操作完成的回调。\nNIO 2.0 的异步套接字通道是真正的异步非阻塞I/O,它对应UNIX网络编程中的时间驱动I/O(AIO),他不需要通过多路复用器Selector对应注册的通道进行轮询操作即可以实现异步读写。\n\n[Github](https://github.com/zhaohuizhang/java-nio-demo)\n","source":"_posts/AIO.md","raw":"title: AIO\ndate: 2015-12-03 09:50:20\ntags: NIO\n---\n\n## AIO Programing\nNIO 2.0 引入了新的异步通道的概念,并提拱了异步文件通道和异步套接字通道的实现。异步通道通过两种方式获取操作结果。\n* 通过java.util.concurrent.Future类来表示异步操作的结果。\n* 在执行异步操作的时候传入一个java.nio.channel。\nCompletionHandler 接口的实现类作为操作完成的回调。\nNIO 2.0 的异步套接字通道是真正的异步非阻塞I/O,它对应UNIX网络编程中的时间驱动I/O(AIO),他不需要通过多路复用器Selector对应注册的通道进行轮询操作即可以实现异步读写。\n\n[Github](https://github.com/zhaohuizhang/java-nio-demo)\n","slug":"AIO","published":1,"updated":"2015-12-03T09:35:38.726Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153zm006yc0tjtldfk22i"},{"title":"一切都是对象","id":"195","_content":"\n1,用句柄操作对象\n\n每种编程语言都有自己的数据处理方法。尽管将一切都看做对象,但操作的标识符实际是指向一个对象的“句柄”(handle),有的人将其称作“引用”,甚至一个“指针”。\n\n只是拥有一个句柄,并不表示必须有一个对象同它相连接。一种安全的做法,创建一个句柄时,都进行初始化。\n\n2,所有对象都必须创建\n\n创建句柄时,我们希望他同一个新的对象连接。new 关键字。\n\n2.1 保存的地方\n\n程序运行时,我们最好对数据保存的地方做到心中有数。有六个地方可以保存数据:\n\n(1)寄存器:最快的保存区,它位于处理器内部,然而寄存器的数量有限,所以寄存器根据需要有编译器分配。我们对此没有直接的控制权,,也不可能在自己的程序里找到寄存器存在的任何踪迹。\n\n(2)堆栈:驻留于常规RAM(随机访问存储)区域,可以通过它的“堆栈指针”获取处理的直接支持。堆栈指针若向下移,会创建新的内存;若向上移,则会释放这些内存。只是一种特别快。特别有效的数据保存方式,仅次于寄存器。创建程序时,Java编译器必须准确地知道堆栈内保存的所有数据的大小和存在时间。只是由于它必须生成相应的代码,以便移动指针。这一限制影响了程序的灵活性,所以尽管有些Java数据要保存在堆栈里--特别是对象句柄,但Java对象并不在其中。\n\n(3)堆:一种常用的内存池(也在RAM),其中保存了Java对象。和堆栈不同,“内存堆”或“堆”(Heap)最吸引人的地方在于知道要从堆里分配多少存储空间,也不必只掉存储的数据要在堆里存留多久。因此,用堆保存数据时会得到更大的灵活性。要求创建一个对象时,只需用new命令编制相应的代码即可。执行这些代码是,会在堆里自动进行数据的保存。在堆里分配存储空间要花掉更长时间。\n\n(4)静态存储:这儿的“静态”(static)是指“位于固定位置”(也在RAM中)。程序运行运行期间,静态存储的数据将随时等候调用。可用Static关键字支出一个对象的特定元素是静态的。但Java对象本身永远都不会置入静态存储空间。\n\n(5)常量存储:常数值通常直接至于应用程序代码内部。这样是安全的。因为他们永远都不会改变。有的常量是严格需要保护的,所以可考虑将它们置入只读存储器(ROM)。\n\n(6)非RAM存储:若数据完全独立于一个程序之外,在程序不运行时仍可存在,并在程序的控制范围之外。其中最主要的有两个\"流式对象\"和\"固定对象\",流式对象,对象会变成字节流,通常会发给另一台机器。对于固定对象,对象保存在磁盘中。\n\n2.2 特殊情况:主要类型\n\n基本数据类型,程序设计是要频繁的用到它们,之所以到特别对待,是由于用new创建对象并不是非常有效,因为new最为对象置于“堆”中。对于这些类型,Java采用了与C和C++相同的方法。也就是说,不用new创建变量,而是创建一个并非句柄的“自动”变量。这个变量容纳了具体的值,并置于堆栈中,能更高效的存取。\n\nJava决定了每种主要类型的大小。这些大小并不随着机器的结构的变化而变化。这种大小不可更改正式Java程序就有很强移植能力的原因之一。\n<table style=\"height:850px;\" border=\"\" width=\"567\">\n<tbody>\n<tr valign=\"TOP\">\n<th colspan=\"1\" rowspan=\"1\" valign=\"TOP\" width=\"76\">\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">主类型 </span>\n\n</div></th>\n<th colspan=\"1\" rowspan=\"1\" valign=\"TOP\" width=\"45\">\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">大小 </span>\n\n</div></th>\n<th colspan=\"1\" rowspan=\"1\" valign=\"TOP\" width=\"67\">\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">最小值 </span>\n\n</div></th>\n<th colspan=\"1\" rowspan=\"1\" valign=\"TOP\" width=\"77\">\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">最大值 </span>\n\n</div></th>\n<th colspan=\"1\" rowspan=\"1\" valign=\"TOP\" width=\"64\">\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">封装器类型</span>\n\n</div></th>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">boolean</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">1-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">–</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">–</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Boolean**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">char</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">16-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">Unicode 0</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">Unicode 2<sup>16</sup>- 1</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Character**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">byte </span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">8-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">-128</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">+127</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Byte**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">short</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">16-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">-2<sup>15</sup></span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">+2<sup>15</sup> – 1</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Short<sup>1</sup>**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">int</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">32-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">-2<sup>31</sup></span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">+2<sup>31</sup> – 1</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Integer**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">long</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">64-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">-2<sup>63</sup></span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">+2<sup>63</sup> – 1</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Long**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">float</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">32-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">IEEE754</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">IEEE754</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Float**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">double</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">64-bit </span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">IEEE754</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">IEEE754</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Double**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">void</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">–</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">–</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">–</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Void**<sup>1</sup></span>\n\n</div></td>\n</tr>\n</tbody>\n</table>\n数值类型全都是有符号(正负号)的,所以不必费劲寻找没有符号的类型。\n\n主数据类型也拥有自己的“封装器”(wrapper)类。\n\nCharacter C = new Character(‘x’);\n\n高精度数字:BigInteger,BigDecimal。只是必须使用方法调用,不能使用运算符。此外,由于牵涉更多,所以运算速度会慢一些。我们牺牲了速度,但换来了精度。\n\nBigInteger支持任意精度的整数。也就是说,我们可精确表示任意大小的整数值,同时在运算过程中不会丢失任何信息。\nBigDecimal支持任意精度的定点数字。例如,可用它进行精确的币值计算。\n\n2.3 Java数据组\n\n几乎所有的编程语言都支持数组。Java的一项主要设计目标就是安全性。一个Java程序可以保证被初始化而且不可在它的范围之外访问。由于系统自动进行范围检查,所以必然要付出一些代价;针对每个数组,以及在运行期间对索引的校验,都会造成少量的内存开销。但由此换回的是更高的安全性,以及更高的工作效率。\n\n创建对象数组时,实际创建的是一个句柄数组。而且每个句柄都会自动初始化成一个特殊值,并带有自己的关键字:null(空)。一旦Java看到Null,就知道该句柄并未指向一个对象。正式使用前,必须为每个句柄都分配一个对象。正式使用前,必须为每个句柄都分配一个对象。\n\n3,绝对不要清除对象\n\n3.1 作用域\n\n大多数程序设计语言都提供了“作用域”(Scope)的概念。对于在作用域里定义的名字,作用域同时决定了它的“可见性”以及“存在时间”。在C,C++和Java里,作用域是由花括号的位置决定的。\n\n由于Java是一种形式自由的语言,所以额外的空格、制表位以及回车都不会对结果程序造成影响。\n\n3.2 对象的作用域\n\nJava对象不具备与主类型一样的存在时间。用new关键字创建一个Java对象的时候,它会超出作用域的范围之外。所以假若使用下面这段代码:\n\n{\nString s = new String(\"a string\");\n} /* 作用域的终点 */\n\n那么句柄s会在作用域的终点处消失。然而,s指向的String对象依然占据着内存空间。在上面这段代码里,我们没有办法访问对象,因为指向它的唯一一个句柄已超出了作用域的边界。\n\nJava有一个特别的“垃圾收集器”,它会查找用new创建的所有对象,并辨别其中哪些不再被引用。随后,它会自动释放由那些闲置对象占据的内存,以便能由新对象使用。这意味着我们根本不必操心内存的回收问题。只需简单地创建对象,一旦不再需要它们,它们就会自动离去。这样做可防止在C++里很常见的一个编程问题:由于程序员忘记释放内存造成的“内存溢出”。\n\n4,新建数据类型:类\n\n4.1 字段和方法\n\n定义一个类时(我们在Java里的全部工作就是定义类、制作那些类的对象以及将消息发给那些对象),可在自己的类里设置两种类型的元素:数据成员(有时也叫“字段”)以及成员函数(通常叫“方法”)。其中,数据成员是一种对象(通过它的句柄与其通信),可以为任何类型。它也可以是主类型(并不是句柄)之一。如果是指向对象的一个句柄,则必须初始化那个句柄,用一种名为“构建器”(第4章会对此详述)的特殊函数将其与一个实际对象连接起来(就象早先看到的那样,使用new关键字)。但若是一种主类型,则可在类定义位置直接初始化(正如后面会看到的那样,句柄亦可在定义位置初始化)。\n每个对象都为自己的数据成员保有存储空间;数据成员不会在对象之间共享。下面是定义了一些数据成员的类示例:\n<pre>class DataOnly{\n int t;\n float f;\n boolean b;\n}\nDataOnly d = new DataOnly();\n</pre>\n1\\. 主成员的默认值\n\n若某个主数据类型属于一个类成员,那么即使不明确(显式)进行初始化,也可以保证它们获得一个默认值。\n\n主类型 默认值\n\nBoolean false\nChar '0000'(null)\nbyte (byte) 0\nshort (short) 0\nint 0\nlong 0L\nfloat 0.0f\ndouble 0.0d\n\n一旦将变量作为类成员使用,就要特别注意由Java分配的默认值。这样做可保证主类型的成员变量肯定得到了初始化(C++不具备这一功能),可有效遏止多种相关的编程错误。然而,这种保证却并不适用于“局部”变量——那些变量并非一个类的字段。所以,假若在一个函数定义中写入下述代码:\nint x;\n那么x会得到一些随机值(这与C和C++是一样的),不会自动初始化成零。我们责任是在正式使用x前分配一个适当的值。如果忘记,就会得到一条编译期错误,告诉我们变量可能尚未初始化。这种处理正是Java优于C++的表现之一。许多C++编译器会对变量未初始化发出警告,但在Java里却是错误。\n\n5,方法、自变量和返回值\n\n迄今为止,我们一直用“函数”(Function)这个词指代一个已命名的子例程。但在Java里,更常用的一个词却是“方法”(Method),代表“完成某事的途径”。尽管它们表达的实际是同一个意思,但从现在开始,本书将一直使用“方法”,而不是“函数”。\nJava的“方法”决定了一个对象能够接收的消息。通过本节的学习,大家会知道方法的定义有多么简单!\n方法的基本组成部分包括名字、自变量、返回类型以及主体。下面便是它最基本的形式:\n<pre>返回类型 方法名( /* 自变量列表*/ ) {/* 方法主体 */}</pre>\n返回类型是指调用方法之后返回的数值类型。显然,方法名的作用是对具体的方法进行标识和引用。自变量列表列出了想传递给方法的信息类型和名称。\nJava的方法只能作为类的一部分创建。只能针对某个对象调用一个方法(注释③),而且那个对象必须能够执行那个方法调用。若试图为一个对象调用错误的方法,就会在编译期得到一条出错消息。为一个对象调用方法时,需要先列出对象的名字,在后面跟上一个句点,再跟上方法名以及它的参数列表。亦即“对象名.方法名(自变量1,自变量2,自变量3...)。举个例子来说,假设我们有一个方法名叫f(),它没有自变量,返回的是类型为int的一个值。那么,假设有一个名为a的对象,可为其调用方法f(),则代码如下:\nint x = a.f();\n返回值的类型必须兼容x的类型。\n\n“向对象发送一条消息”,消息是f(),而对象是a。\n\n5.1 自变量列表\n\n自变量列表规定了我们传送给方法的是什么信息。正如大家或许已猜到的那样,这些信息——如同Java内其他任何东西——采用的都是对象的形式。因此,我们必须在自变量列表里指定要传递的对象类型,以及每个对象的名字。正如在Java其他地方处理对象时一样,我们实际传递的是“句柄”(注释④)。然而,句柄的类型必须正确。倘若希望自变量是一个“字串”,那么传递的必须是一个字串。\n\n④:对于前面提及的“特殊”数据类型boolean,char,byte,short,int,long,,float以及double来说是一个例外。但在传递对象时,通常都是指传递指向对象的句柄。\n<pre>int storage(String s) {\nreturn s.length() * 2;\n}</pre>\n这个方法告诉我们需要多少字节才能容纳一个特定字串里的信息(字串里的每个字符都是16位,或者说2个字节、长整数,以便提供对Unicode字符的支持)。自变量的类型为String,而且叫作s。一旦将s传递给方法,就可将它当作其他对象一样处理(可向其发送消息)。在这里,我们调用的是length()方法,它是String的方法之一。该方法返回的是一个字串里的字符数。\n通过上面的例子,也可以了解return关键字的运用。它主要做两件事情。首先,它意味着“离开方法,我已完工了”。其次,假设方法生成了一个值,则那个值紧接在return语句的后面。在这种情况下,返回值是通过计算表达式“s.length()*2”而产生的。\n<pre>boolean flag() { return true; }\nfloat naturalLogBase() { return 2.718; }\nvoid nothing() { return; }\nvoid nothing2() {}</pre>\n若返回类型为void,则return关键字唯一的作用就是退出方法。所以一旦抵达方法末尾,该关键字便不需要了。可在任何地方从一个方法返回。但假设已指定了一种非void的返回类型,那么无论从何地返回,编译器都会确保我们返回的是正确的类型。\n到此为止,大家或许已得到了这样的一个印象:一个程序只是一系列对象的集合,它们的方法将其他对象作为自己的自变量使用,而且将消息发给那些对象。这种说法大体正确,但通过以后的学习,大家还会知道如何在一个方法里作出决策,做一些更细致的基层工作。至于这一章,只需理解消息传送就足够了。\n\n6,构建Java程序\n\n6.1 名字的可见性\n\n反转域名,软件包都是由小写字母为标准。\n\nJava的这种机制意味着所有文件都自动存在于自己的命名空间里,而且一个文件里的每个类都自动获得一个独一无二的标识符。所以不必学习特殊的语言知识来解决这个问题。\n\n6.2 使用其他组件\n\nimport\n\n6.3 static关键字\n\n一旦将什么东西设为“static”,数据或方法就不会同这个类的任何对象实例联系到一起。\n\n一个static作用于一个字段来说,对于一个类来说只有一份存储空间,而非static字段则是对每个对象有一个存储空间。Static方法的一个重要的作用是在不创建任何对象的前提下就可以调用它。\n\nstatic通常负责看护与其隶属同一个类型的实例群。\n\n7,第一个Java程序\n\n有一个特定的类会自定导入到每一个Java文件中:java.lang。\n<pre>import java.util.*;\n\npublic class HelloDate{\n public static void main(String[] args){\n System.out.println(\"Hello world\");\n System.out.println(new Date());\n }\n}</pre>\ns","source":"_drafts/一切都是对象.md","raw":"title: 一切都是对象\nid: 195\ncategories:\n - Java\ntags:\n---\n\n1,用句柄操作对象\n\n每种编程语言都有自己的数据处理方法。尽管将一切都看做对象,但操作的标识符实际是指向一个对象的“句柄”(handle),有的人将其称作“引用”,甚至一个“指针”。\n\n只是拥有一个句柄,并不表示必须有一个对象同它相连接。一种安全的做法,创建一个句柄时,都进行初始化。\n\n2,所有对象都必须创建\n\n创建句柄时,我们希望他同一个新的对象连接。new 关键字。\n\n2.1 保存的地方\n\n程序运行时,我们最好对数据保存的地方做到心中有数。有六个地方可以保存数据:\n\n(1)寄存器:最快的保存区,它位于处理器内部,然而寄存器的数量有限,所以寄存器根据需要有编译器分配。我们对此没有直接的控制权,,也不可能在自己的程序里找到寄存器存在的任何踪迹。\n\n(2)堆栈:驻留于常规RAM(随机访问存储)区域,可以通过它的“堆栈指针”获取处理的直接支持。堆栈指针若向下移,会创建新的内存;若向上移,则会释放这些内存。只是一种特别快。特别有效的数据保存方式,仅次于寄存器。创建程序时,Java编译器必须准确地知道堆栈内保存的所有数据的大小和存在时间。只是由于它必须生成相应的代码,以便移动指针。这一限制影响了程序的灵活性,所以尽管有些Java数据要保存在堆栈里--特别是对象句柄,但Java对象并不在其中。\n\n(3)堆:一种常用的内存池(也在RAM),其中保存了Java对象。和堆栈不同,“内存堆”或“堆”(Heap)最吸引人的地方在于知道要从堆里分配多少存储空间,也不必只掉存储的数据要在堆里存留多久。因此,用堆保存数据时会得到更大的灵活性。要求创建一个对象时,只需用new命令编制相应的代码即可。执行这些代码是,会在堆里自动进行数据的保存。在堆里分配存储空间要花掉更长时间。\n\n(4)静态存储:这儿的“静态”(static)是指“位于固定位置”(也在RAM中)。程序运行运行期间,静态存储的数据将随时等候调用。可用Static关键字支出一个对象的特定元素是静态的。但Java对象本身永远都不会置入静态存储空间。\n\n(5)常量存储:常数值通常直接至于应用程序代码内部。这样是安全的。因为他们永远都不会改变。有的常量是严格需要保护的,所以可考虑将它们置入只读存储器(ROM)。\n\n(6)非RAM存储:若数据完全独立于一个程序之外,在程序不运行时仍可存在,并在程序的控制范围之外。其中最主要的有两个\"流式对象\"和\"固定对象\",流式对象,对象会变成字节流,通常会发给另一台机器。对于固定对象,对象保存在磁盘中。\n\n2.2 特殊情况:主要类型\n\n基本数据类型,程序设计是要频繁的用到它们,之所以到特别对待,是由于用new创建对象并不是非常有效,因为new最为对象置于“堆”中。对于这些类型,Java采用了与C和C++相同的方法。也就是说,不用new创建变量,而是创建一个并非句柄的“自动”变量。这个变量容纳了具体的值,并置于堆栈中,能更高效的存取。\n\nJava决定了每种主要类型的大小。这些大小并不随着机器的结构的变化而变化。这种大小不可更改正式Java程序就有很强移植能力的原因之一。\n<table style=\"height:850px;\" border=\"\" width=\"567\">\n<tbody>\n<tr valign=\"TOP\">\n<th colspan=\"1\" rowspan=\"1\" valign=\"TOP\" width=\"76\">\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">主类型 </span>\n\n</div></th>\n<th colspan=\"1\" rowspan=\"1\" valign=\"TOP\" width=\"45\">\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">大小 </span>\n\n</div></th>\n<th colspan=\"1\" rowspan=\"1\" valign=\"TOP\" width=\"67\">\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">最小值 </span>\n\n</div></th>\n<th colspan=\"1\" rowspan=\"1\" valign=\"TOP\" width=\"77\">\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">最大值 </span>\n\n</div></th>\n<th colspan=\"1\" rowspan=\"1\" valign=\"TOP\" width=\"64\">\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">封装器类型</span>\n\n</div></th>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">boolean</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">1-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">–</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">–</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Boolean**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">char</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">16-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">Unicode 0</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">Unicode 2<sup>16</sup>- 1</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Character**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">byte </span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">8-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">-128</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">+127</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Byte**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">short</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">16-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">-2<sup>15</sup></span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">+2<sup>15</sup> – 1</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Short<sup>1</sup>**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">int</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">32-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">-2<sup>31</sup></span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">+2<sup>31</sup> – 1</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Integer**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">long</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">64-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">-2<sup>63</sup></span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">+2<sup>63</sup> – 1</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Long**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">float</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">32-bit</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">IEEE754</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">IEEE754</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Float**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">double</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">64-bit </span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">IEEE754</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">IEEE754</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Double**</span>\n\n</div></td>\n</tr>\n<tr valign=\"TOP\">\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">void</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">–</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">–</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">–</span>\n\n</div></td>\n<td>\n<div align=\"LEFT\">\n\n<span style=\"font-family:Georgia;\">**Void**<sup>1</sup></span>\n\n</div></td>\n</tr>\n</tbody>\n</table>\n数值类型全都是有符号(正负号)的,所以不必费劲寻找没有符号的类型。\n\n主数据类型也拥有自己的“封装器”(wrapper)类。\n\nCharacter C = new Character(‘x’);\n\n高精度数字:BigInteger,BigDecimal。只是必须使用方法调用,不能使用运算符。此外,由于牵涉更多,所以运算速度会慢一些。我们牺牲了速度,但换来了精度。\n\nBigInteger支持任意精度的整数。也就是说,我们可精确表示任意大小的整数值,同时在运算过程中不会丢失任何信息。\nBigDecimal支持任意精度的定点数字。例如,可用它进行精确的币值计算。\n\n2.3 Java数据组\n\n几乎所有的编程语言都支持数组。Java的一项主要设计目标就是安全性。一个Java程序可以保证被初始化而且不可在它的范围之外访问。由于系统自动进行范围检查,所以必然要付出一些代价;针对每个数组,以及在运行期间对索引的校验,都会造成少量的内存开销。但由此换回的是更高的安全性,以及更高的工作效率。\n\n创建对象数组时,实际创建的是一个句柄数组。而且每个句柄都会自动初始化成一个特殊值,并带有自己的关键字:null(空)。一旦Java看到Null,就知道该句柄并未指向一个对象。正式使用前,必须为每个句柄都分配一个对象。正式使用前,必须为每个句柄都分配一个对象。\n\n3,绝对不要清除对象\n\n3.1 作用域\n\n大多数程序设计语言都提供了“作用域”(Scope)的概念。对于在作用域里定义的名字,作用域同时决定了它的“可见性”以及“存在时间”。在C,C++和Java里,作用域是由花括号的位置决定的。\n\n由于Java是一种形式自由的语言,所以额外的空格、制表位以及回车都不会对结果程序造成影响。\n\n3.2 对象的作用域\n\nJava对象不具备与主类型一样的存在时间。用new关键字创建一个Java对象的时候,它会超出作用域的范围之外。所以假若使用下面这段代码:\n\n{\nString s = new String(\"a string\");\n} /* 作用域的终点 */\n\n那么句柄s会在作用域的终点处消失。然而,s指向的String对象依然占据着内存空间。在上面这段代码里,我们没有办法访问对象,因为指向它的唯一一个句柄已超出了作用域的边界。\n\nJava有一个特别的“垃圾收集器”,它会查找用new创建的所有对象,并辨别其中哪些不再被引用。随后,它会自动释放由那些闲置对象占据的内存,以便能由新对象使用。这意味着我们根本不必操心内存的回收问题。只需简单地创建对象,一旦不再需要它们,它们就会自动离去。这样做可防止在C++里很常见的一个编程问题:由于程序员忘记释放内存造成的“内存溢出”。\n\n4,新建数据类型:类\n\n4.1 字段和方法\n\n定义一个类时(我们在Java里的全部工作就是定义类、制作那些类的对象以及将消息发给那些对象),可在自己的类里设置两种类型的元素:数据成员(有时也叫“字段”)以及成员函数(通常叫“方法”)。其中,数据成员是一种对象(通过它的句柄与其通信),可以为任何类型。它也可以是主类型(并不是句柄)之一。如果是指向对象的一个句柄,则必须初始化那个句柄,用一种名为“构建器”(第4章会对此详述)的特殊函数将其与一个实际对象连接起来(就象早先看到的那样,使用new关键字)。但若是一种主类型,则可在类定义位置直接初始化(正如后面会看到的那样,句柄亦可在定义位置初始化)。\n每个对象都为自己的数据成员保有存储空间;数据成员不会在对象之间共享。下面是定义了一些数据成员的类示例:\n<pre>class DataOnly{\n int t;\n float f;\n boolean b;\n}\nDataOnly d = new DataOnly();\n</pre>\n1\\. 主成员的默认值\n\n若某个主数据类型属于一个类成员,那么即使不明确(显式)进行初始化,也可以保证它们获得一个默认值。\n\n主类型 默认值\n\nBoolean false\nChar '0000'(null)\nbyte (byte) 0\nshort (short) 0\nint 0\nlong 0L\nfloat 0.0f\ndouble 0.0d\n\n一旦将变量作为类成员使用,就要特别注意由Java分配的默认值。这样做可保证主类型的成员变量肯定得到了初始化(C++不具备这一功能),可有效遏止多种相关的编程错误。然而,这种保证却并不适用于“局部”变量——那些变量并非一个类的字段。所以,假若在一个函数定义中写入下述代码:\nint x;\n那么x会得到一些随机值(这与C和C++是一样的),不会自动初始化成零。我们责任是在正式使用x前分配一个适当的值。如果忘记,就会得到一条编译期错误,告诉我们变量可能尚未初始化。这种处理正是Java优于C++的表现之一。许多C++编译器会对变量未初始化发出警告,但在Java里却是错误。\n\n5,方法、自变量和返回值\n\n迄今为止,我们一直用“函数”(Function)这个词指代一个已命名的子例程。但在Java里,更常用的一个词却是“方法”(Method),代表“完成某事的途径”。尽管它们表达的实际是同一个意思,但从现在开始,本书将一直使用“方法”,而不是“函数”。\nJava的“方法”决定了一个对象能够接收的消息。通过本节的学习,大家会知道方法的定义有多么简单!\n方法的基本组成部分包括名字、自变量、返回类型以及主体。下面便是它最基本的形式:\n<pre>返回类型 方法名( /* 自变量列表*/ ) {/* 方法主体 */}</pre>\n返回类型是指调用方法之后返回的数值类型。显然,方法名的作用是对具体的方法进行标识和引用。自变量列表列出了想传递给方法的信息类型和名称。\nJava的方法只能作为类的一部分创建。只能针对某个对象调用一个方法(注释③),而且那个对象必须能够执行那个方法调用。若试图为一个对象调用错误的方法,就会在编译期得到一条出错消息。为一个对象调用方法时,需要先列出对象的名字,在后面跟上一个句点,再跟上方法名以及它的参数列表。亦即“对象名.方法名(自变量1,自变量2,自变量3...)。举个例子来说,假设我们有一个方法名叫f(),它没有自变量,返回的是类型为int的一个值。那么,假设有一个名为a的对象,可为其调用方法f(),则代码如下:\nint x = a.f();\n返回值的类型必须兼容x的类型。\n\n“向对象发送一条消息”,消息是f(),而对象是a。\n\n5.1 自变量列表\n\n自变量列表规定了我们传送给方法的是什么信息。正如大家或许已猜到的那样,这些信息——如同Java内其他任何东西——采用的都是对象的形式。因此,我们必须在自变量列表里指定要传递的对象类型,以及每个对象的名字。正如在Java其他地方处理对象时一样,我们实际传递的是“句柄”(注释④)。然而,句柄的类型必须正确。倘若希望自变量是一个“字串”,那么传递的必须是一个字串。\n\n④:对于前面提及的“特殊”数据类型boolean,char,byte,short,int,long,,float以及double来说是一个例外。但在传递对象时,通常都是指传递指向对象的句柄。\n<pre>int storage(String s) {\nreturn s.length() * 2;\n}</pre>\n这个方法告诉我们需要多少字节才能容纳一个特定字串里的信息(字串里的每个字符都是16位,或者说2个字节、长整数,以便提供对Unicode字符的支持)。自变量的类型为String,而且叫作s。一旦将s传递给方法,就可将它当作其他对象一样处理(可向其发送消息)。在这里,我们调用的是length()方法,它是String的方法之一。该方法返回的是一个字串里的字符数。\n通过上面的例子,也可以了解return关键字的运用。它主要做两件事情。首先,它意味着“离开方法,我已完工了”。其次,假设方法生成了一个值,则那个值紧接在return语句的后面。在这种情况下,返回值是通过计算表达式“s.length()*2”而产生的。\n<pre>boolean flag() { return true; }\nfloat naturalLogBase() { return 2.718; }\nvoid nothing() { return; }\nvoid nothing2() {}</pre>\n若返回类型为void,则return关键字唯一的作用就是退出方法。所以一旦抵达方法末尾,该关键字便不需要了。可在任何地方从一个方法返回。但假设已指定了一种非void的返回类型,那么无论从何地返回,编译器都会确保我们返回的是正确的类型。\n到此为止,大家或许已得到了这样的一个印象:一个程序只是一系列对象的集合,它们的方法将其他对象作为自己的自变量使用,而且将消息发给那些对象。这种说法大体正确,但通过以后的学习,大家还会知道如何在一个方法里作出决策,做一些更细致的基层工作。至于这一章,只需理解消息传送就足够了。\n\n6,构建Java程序\n\n6.1 名字的可见性\n\n反转域名,软件包都是由小写字母为标准。\n\nJava的这种机制意味着所有文件都自动存在于自己的命名空间里,而且一个文件里的每个类都自动获得一个独一无二的标识符。所以不必学习特殊的语言知识来解决这个问题。\n\n6.2 使用其他组件\n\nimport\n\n6.3 static关键字\n\n一旦将什么东西设为“static”,数据或方法就不会同这个类的任何对象实例联系到一起。\n\n一个static作用于一个字段来说,对于一个类来说只有一份存储空间,而非static字段则是对每个对象有一个存储空间。Static方法的一个重要的作用是在不创建任何对象的前提下就可以调用它。\n\nstatic通常负责看护与其隶属同一个类型的实例群。\n\n7,第一个Java程序\n\n有一个特定的类会自定导入到每一个Java文件中:java.lang。\n<pre>import java.util.*;\n\npublic class HelloDate{\n public static void main(String[] args){\n System.out.println(\"Hello world\");\n System.out.println(new Date());\n }\n}</pre>\ns","slug":"一切都是对象","published":0,"date":"2015-12-02T04:39:35.619Z","updated":"2015-12-02T04:39:35.619Z","comments":1,"layout":"post","photos":[],"link":"","_id":"cilt153zp0070c0tjjyq7vs5b"}],"PostAsset":[],"PostCategory":[{"post_id":"cilt153tm0000c0tjm80br6r7","category_id":"cilt153tu0001c0tjhfqe7p89","_id":"cilt153u70004c0tjmv3gyi9u"},{"post_id":"cilt153um0009c0tjhd0j3n1e","category_id":"cilt153un000ac0tj1u77u9vu","_id":"cilt153ur000fc0tjhdm2bt4s"},{"post_id":"cilt153ux000kc0tj8szyziuk","category_id":"cilt153uy000lc0tj9ljzdf3g","_id":"cilt153v2000oc0tjsdhd1uas"},{"post_id":"cilt153v6000pc0tjellzbkh8","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153va000tc0tjggiq57gi"},{"post_id":"cilt153vb000uc0tjy78l19cm","category_id":"cilt153tu0001c0tjhfqe7p89","_id":"cilt153vd000vc0tj3okb413v"},{"post_id":"cilt153vg0010c0tj0u5mckaw","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153vi0011c0tj6m1zo0bj"},{"post_id":"cilt153vm0014c0tjbsk9ns59","category_id":"cilt153vo0015c0tjoomlsji8","_id":"cilt153vq0018c0tjzefxyzqc"},{"post_id":"cilt153vs001bc0tjtdpu045s","category_id":"cilt153vo0015c0tjoomlsji8","_id":"cilt153vt001cc0tjzykpx0yi"},{"post_id":"cilt153vv001gc0tjfqn2yaeh","category_id":"cilt153vo0015c0tjoomlsji8","_id":"cilt153vw001hc0tj4tpmvpdk"},{"post_id":"cilt153vy001lc0tjcngee3c5","category_id":"cilt153vo0015c0tjoomlsji8","_id":"cilt153vz001mc0tj732ojx9l"},{"post_id":"cilt153w2001sc0tj0onkw57r","category_id":"cilt153w3001tc0tjys9xot3s","_id":"cilt153w4001uc0tj1wusv9ap"},{"post_id":"cilt153w5001vc0tjxs9cp28z","category_id":"cilt153w7001wc0tj5d6nivhw","_id":"cilt153w90020c0tjgc0ib5uc"},{"post_id":"cilt153wc0024c0tjjkwspgan","category_id":"cilt153w7001wc0tj5d6nivhw","_id":"cilt153wd0025c0tjnbr3pvq3"},{"post_id":"cilt153wf002ac0tjpf4la3j1","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153wg002bc0tjdj9enqol"},{"post_id":"cilt153wo002lc0tj7ebu0pkt","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153wo002mc0tjs4sz2ia3"},{"post_id":"cilt153wq002nc0tj4aqmiyc1","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153wr002oc0tjmtvoypwj"},{"post_id":"cilt153x00030c0tjnji0fzpo","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153x10031c0tjctajh6it"},{"post_id":"cilt153x40035c0tjn0nveav1","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153x50036c0tjtiuvhpom"},{"post_id":"cilt153x60037c0tjm55j25qm","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153x70038c0tjnej2222e"},{"post_id":"cilt153xa003ec0tjpf9d1sbo","category_id":"cilt153xb003fc0tjvdcum0d1","_id":"cilt153xc003ic0tj9oxmbwfu"},{"post_id":"cilt153xe003kc0tjfly9vy31","category_id":"cilt153xg003lc0tj1dzagn04","_id":"cilt153xg003mc0tj9u4nmmvz"},{"post_id":"cilt153xi003nc0tjs1cc3b4w","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153xk003oc0tjigo1o848"},{"post_id":"cilt153xp003tc0tjc3fqx62t","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153xq003uc0tj57l6q81q"},{"post_id":"cilt153xu0041c0tj2phh3t2x","category_id":"cilt153xu0042c0tjukwsqgih","_id":"cilt153xv0045c0tjolgouyxp"},{"post_id":"cilt153xw0046c0tjy8kvnxdx","category_id":"cilt153vo0015c0tjoomlsji8","_id":"cilt153xy0047c0tjrgrfpf2o"},{"post_id":"cilt153y0004bc0tjhlkkcj12","category_id":"cilt153vo0015c0tjoomlsji8","_id":"cilt153y1004cc0tjpcu9g5lj"},{"post_id":"cilt153y2004gc0tje3k6542s","category_id":"cilt153vo0015c0tjoomlsji8","_id":"cilt153y3004hc0tjvxs0k187"},{"post_id":"cilt153y5004lc0tj15jkrh3o","category_id":"cilt153vo0015c0tjoomlsji8","_id":"cilt153y6004mc0tj7iv5h1hh"},{"post_id":"cilt153yb004tc0tjmze0mv4g","category_id":"cilt153w7001wc0tj5d6nivhw","_id":"cilt153yc004uc0tjbsgx9hxx"},{"post_id":"cilt153yh0056c0tj57sgq6qs","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153yi0057c0tjd983ar14"},{"post_id":"cilt153yj005cc0tjuufgjlx1","category_id":"cilt153w7001wc0tj5d6nivhw","_id":"cilt153yk005dc0tjrwr78phc"},{"post_id":"cilt153yn005ic0tjp5s98c69","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153yo005jc0tj6e3l1d8u"},{"post_id":"cilt153yw005uc0tjfugudirl","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153yy005vc0tjtpv4vkrk"},{"post_id":"cilt153yz005wc0tjputioah2","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153z0005xc0tjtq17foe0"},{"post_id":"cilt153z60062c0tjes089p7d","category_id":"cilt153tu0001c0tjhfqe7p89","_id":"cilt153z70063c0tj3zg2hnd0"},{"post_id":"cilt153z90067c0tjmfrvq2i1","category_id":"cilt153tu0001c0tjhfqe7p89","_id":"cilt153za0068c0tjmi1882r3"},{"post_id":"cilt153zd006hc0tjdg8ahx2y","category_id":"cilt153tu0001c0tjhfqe7p89","_id":"cilt153ze006ic0tjdvrpv8ha"},{"post_id":"cilt153zf006mc0tj60ik8gyq","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153zg006nc0tjlxn1g13j"},{"post_id":"cilt153zi006sc0tjm0erxekp","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153zk006tc0tj8tv76zpn"},{"post_id":"cilt153zp0070c0tjjyq7vs5b","category_id":"cilt153v9000qc0tj1xryp40m","_id":"cilt153zq0071c0tjjc1182w4"}],"PostTag":[{"post_id":"cilt153tm0000c0tjm80br6r7","tag_id":"cilt153tu0002c0tjpipq4d7u","_id":"cilt153u80005c0tjonam60bb"},{"post_id":"cilt153tm0000c0tjm80br6r7","tag_id":"cilt153tx0003c0tjd7kxap9f","_id":"cilt153u90006c0tjen88mybj"},{"post_id":"cilt153um0009c0tjhd0j3n1e","tag_id":"cilt153uo000bc0tjhahnbxyi","_id":"cilt153ur000gc0tjkqb4owh3"},{"post_id":"cilt153um0009c0tjhd0j3n1e","tag_id":"cilt153up000cc0tjpbqn1czw","_id":"cilt153us000hc0tjpr719zo3"},{"post_id":"cilt153um0009c0tjhd0j3n1e","tag_id":"cilt153up000dc0tjnlwpxzz2","_id":"cilt153ut000ic0tjqb9vemj4"},{"post_id":"cilt153um0009c0tjhd0j3n1e","tag_id":"cilt153up000ec0tjxl3o4i6o","_id":"cilt153ut000jc0tj5w5uk0ep"},{"post_id":"cilt153ux000kc0tj8szyziuk","tag_id":"cilt153uz000mc0tjvq6qz462","_id":"cilt153v1000nc0tjb08zrm0p"},{"post_id":"cilt153v6000pc0tjellzbkh8","tag_id":"cilt153v9000rc0tjnzaj3r6p","_id":"cilt153v9000sc0tjvjb4fphw"},{"post_id":"cilt153vb000uc0tjy78l19cm","tag_id":"cilt153vd000wc0tjjxz3e2uq","_id":"cilt153ve000yc0tj9iwnpv81"},{"post_id":"cilt153vb000uc0tjy78l19cm","tag_id":"cilt153ve000xc0tjdhj1r68c","_id":"cilt153ve000zc0tj0b2r9gd8"},{"post_id":"cilt153vg0010c0tj0u5mckaw","tag_id":"cilt153vj0012c0tj9olenht7","_id":"cilt153vk0013c0tjs7x7pmw9"},{"post_id":"cilt153vm0014c0tjbsk9ns59","tag_id":"cilt153vo0016c0tjnwljpqbl","_id":"cilt153vr0019c0tjphdmme3w"},{"post_id":"cilt153vm0014c0tjbsk9ns59","tag_id":"cilt153vp0017c0tj5xl5g60u","_id":"cilt153vr001ac0tjqvz0jpi5"},{"post_id":"cilt153vs001bc0tjtdpu045s","tag_id":"cilt153vt001dc0tj2leemi51","_id":"cilt153vu001ec0tjp1jsfm6o"},{"post_id":"cilt153vs001bc0tjtdpu045s","tag_id":"cilt153vo0016c0tjnwljpqbl","_id":"cilt153vu001fc0tj6rre75l2"},{"post_id":"cilt153vv001gc0tjfqn2yaeh","tag_id":"cilt153vw001ic0tjwl1qkka0","_id":"cilt153vw001jc0tjxudwbrrj"},{"post_id":"cilt153vv001gc0tjfqn2yaeh","tag_id":"cilt153vo0016c0tjnwljpqbl","_id":"cilt153vw001kc0tjfyvfplle"},{"post_id":"cilt153vy001lc0tjcngee3c5","tag_id":"cilt153vo0016c0tjnwljpqbl","_id":"cilt153w0001pc0tj9dpz8y21"},{"post_id":"cilt153vy001lc0tjcngee3c5","tag_id":"cilt153vz001nc0tjidam134b","_id":"cilt153w1001qc0tjc2fttdfk"},{"post_id":"cilt153vy001lc0tjcngee3c5","tag_id":"cilt153vz001oc0tjbif7c6p5","_id":"cilt153w1001rc0tj3crrcvk3"},{"post_id":"cilt153w5001vc0tjxs9cp28z","tag_id":"cilt153w8001xc0tj0x7g2awa","_id":"cilt153w90021c0tjhbpx8qsd"},{"post_id":"cilt153w5001vc0tjxs9cp28z","tag_id":"cilt153w8001yc0tj0nfgr6cw","_id":"cilt153w90022c0tjff5meazb"},{"post_id":"cilt153w5001vc0tjxs9cp28z","tag_id":"cilt153w8001zc0tjtf2l1k30","_id":"cilt153w90023c0tjeuwlpyk6"},{"post_id":"cilt153wc0024c0tjjkwspgan","tag_id":"cilt153wd0026c0tj9m33q6ge","_id":"cilt153we0028c0tjp2lkxmp8"},{"post_id":"cilt153wc0024c0tjjkwspgan","tag_id":"cilt153we0027c0tjjt2sbxqp","_id":"cilt153we0029c0tjcac61u15"},{"post_id":"cilt153wf002ac0tjpf4la3j1","tag_id":"cilt153wg002cc0tjc95qgv2u","_id":"cilt153wh002fc0tj0o6eccqn"},{"post_id":"cilt153wf002ac0tjpf4la3j1","tag_id":"cilt153wh002dc0tjlq9uw2yl","_id":"cilt153wi002gc0tj366wm3r3"},{"post_id":"cilt153wf002ac0tjpf4la3j1","tag_id":"cilt153wh002ec0tjrhysjtec","_id":"cilt153wi002hc0tjeynorzsq"},{"post_id":"cilt153wk002ic0tjko7nnifq","tag_id":"cilt153wm002jc0tjo6dnuwwv","_id":"cilt153wm002kc0tjvwae4bhb"},{"post_id":"cilt153wq002nc0tj4aqmiyc1","tag_id":"cilt153wr002pc0tjlqtfqb7m","_id":"cilt153wr002qc0tjo5avqyd4"},{"post_id":"cilt153wt002rc0tjulh9w1qc","tag_id":"cilt153wu002sc0tjrvod7ef9","_id":"cilt153wu002tc0tjkpodur7b"},{"post_id":"cilt153wv002uc0tjcmxta03d","tag_id":"cilt153ww002vc0tjolgde6fg","_id":"cilt153wx002wc0tj7f7nh3zz"},{"post_id":"cilt153wy002xc0tjn6l7ulhg","tag_id":"cilt153wz002yc0tjv0dm2w5y","_id":"cilt153wz002zc0tj9tji9q94"},{"post_id":"cilt153x00030c0tjnji0fzpo","tag_id":"cilt153x10032c0tjwef0ao3g","_id":"cilt153x20033c0tjjsp1zhom"},{"post_id":"cilt153x00030c0tjnji0fzpo","tag_id":"cilt153wh002dc0tjlq9uw2yl","_id":"cilt153x20034c0tj49xwrv06"},{"post_id":"cilt153x60037c0tjm55j25qm","tag_id":"cilt153x70039c0tjhkn490t5","_id":"cilt153x7003ac0tjn022zzs1"},{"post_id":"cilt153x8003bc0tjvh748tx4","tag_id":"cilt153x9003cc0tj069wa1xc","_id":"cilt153x9003dc0tjwcn3hbyw"},{"post_id":"cilt153xa003ec0tjpf9d1sbo","tag_id":"cilt153xb003gc0tjl3ucy5wf","_id":"cilt153xc003hc0tjg5edo4zi"},{"post_id":"cilt153xa003ec0tjpf9d1sbo","tag_id":"cilt153wd0026c0tj9m33q6ge","_id":"cilt153xd003jc0tjgm37p4xb"},{"post_id":"cilt153xi003nc0tjs1cc3b4w","tag_id":"cilt153wh002dc0tjlq9uw2yl","_id":"cilt153xl003pc0tj13by45x9"},{"post_id":"cilt153xm003qc0tjnuljqpbf","tag_id":"cilt153xo003rc0tjuehzrsz7","_id":"cilt153xo003sc0tjrzajip3n"},{"post_id":"cilt153xp003tc0tjc3fqx62t","tag_id":"cilt153xq003vc0tjixhvyzdb","_id":"cilt153xs003yc0tj86nrg9dx"},{"post_id":"cilt153xp003tc0tjc3fqx62t","tag_id":"cilt153xr003wc0tjcrshpos9","_id":"cilt153xs003zc0tjrqai94de"},{"post_id":"cilt153xp003tc0tjc3fqx62t","tag_id":"cilt153xs003xc0tjmcehta59","_id":"cilt153xt0040c0tjig9t7qoy"},{"post_id":"cilt153xu0041c0tj2phh3t2x","tag_id":"cilt153xv0043c0tjgwaghsig","_id":"cilt153xv0044c0tjuyskz1bf"},{"post_id":"cilt153xw0046c0tjy8kvnxdx","tag_id":"cilt153xy0048c0tjnfq20m09","_id":"cilt153xz0049c0tj3w2adj8b"},{"post_id":"cilt153xw0046c0tjy8kvnxdx","tag_id":"cilt153vo0016c0tjnwljpqbl","_id":"cilt153xz004ac0tjc4nlnwi9"},{"post_id":"cilt153y0004bc0tjhlkkcj12","tag_id":"cilt153vo0016c0tjnwljpqbl","_id":"cilt153y1004ec0tjcjff400n"},{"post_id":"cilt153y0004bc0tjhlkkcj12","tag_id":"cilt153y1004dc0tjcr9753gx","_id":"cilt153y1004fc0tjhnfx21mm"},{"post_id":"cilt153y2004gc0tje3k6542s","tag_id":"cilt153vo0016c0tjnwljpqbl","_id":"cilt153y4004jc0tjll140je1"},{"post_id":"cilt153y2004gc0tje3k6542s","tag_id":"cilt153y4004ic0tjq1hykq5s","_id":"cilt153y4004kc0tjs12l2kl0"},{"post_id":"cilt153y5004lc0tj15jkrh3o","tag_id":"cilt153vo0016c0tjnwljpqbl","_id":"cilt153y8004oc0tj45kmv3nb"},{"post_id":"cilt153y5004lc0tj15jkrh3o","tag_id":"cilt153y7004nc0tjpdpbl6ij","_id":"cilt153y8004pc0tjjpmihyqj"},{"post_id":"cilt153y9004qc0tjjk0i9kcm","tag_id":"cilt153ya004rc0tjqrxnbq7f","_id":"cilt153yb004sc0tjxhyi7m46"},{"post_id":"cilt153yb004tc0tjmze0mv4g","tag_id":"cilt153yc004vc0tj4bwat815","_id":"cilt153ye0050c0tjtwz12yzd"},{"post_id":"cilt153yb004tc0tjmze0mv4g","tag_id":"cilt153up000cc0tjpbqn1czw","_id":"cilt153yf0051c0tjbwucwujf"},{"post_id":"cilt153yb004tc0tjmze0mv4g","tag_id":"cilt153yd004wc0tjxdx47z4y","_id":"cilt153yf0052c0tjh4dsc9fa"},{"post_id":"cilt153yb004tc0tjmze0mv4g","tag_id":"cilt153yd004xc0tjnwdqj4lh","_id":"cilt153yf0053c0tjzsnx0x9g"},{"post_id":"cilt153yb004tc0tjmze0mv4g","tag_id":"cilt153yd004yc0tjpxwfhx0n","_id":"cilt153yf0054c0tj0o4sncj0"},{"post_id":"cilt153yb004tc0tjmze0mv4g","tag_id":"cilt153ye004zc0tjnltxyxr0","_id":"cilt153yg0055c0tj9bqitlkm"},{"post_id":"cilt153yh0056c0tj57sgq6qs","tag_id":"cilt153yi0058c0tje92yyrtt","_id":"cilt153yi005ac0tjj5yvv13t"},{"post_id":"cilt153yh0056c0tj57sgq6qs","tag_id":"cilt153yi0059c0tjhzs98mc6","_id":"cilt153yj005bc0tj67b5uh94"},{"post_id":"cilt153yj005cc0tjuufgjlx1","tag_id":"cilt153yk005ec0tjcno8ae3q","_id":"cilt153yl005gc0tjf0icls0l"},{"post_id":"cilt153yj005cc0tjuufgjlx1","tag_id":"cilt153yl005fc0tjgr9chplp","_id":"cilt153ym005hc0tjd1mbcfid"},{"post_id":"cilt153yn005ic0tjp5s98c69","tag_id":"cilt153vd000wc0tjjxz3e2uq","_id":"cilt153yp005lc0tjh7yfqg0m"},{"post_id":"cilt153yn005ic0tjp5s98c69","tag_id":"cilt153yp005kc0tj35jpg8s2","_id":"cilt153yp005mc0tjhm7r65ti"},{"post_id":"cilt153yq005nc0tju2kopxp5","tag_id":"cilt153ys005oc0tjtvwq5o3q","_id":"cilt153ys005pc0tjp7kv7rax"},{"post_id":"cilt153yt005qc0tjnlh2xv8c","tag_id":"cilt153ys005oc0tjtvwq5o3q","_id":"cilt153yu005rc0tjwkwcntue"},{"post_id":"cilt153yu005sc0tji5u1cacq","tag_id":"cilt153ys005oc0tjtvwq5o3q","_id":"cilt153yv005tc0tjxku9drzj"},{"post_id":"cilt153z1005yc0tjrf76wpw6","tag_id":"cilt153ys005oc0tjtvwq5o3q","_id":"cilt153z3005zc0tjxwoobzzf"},{"post_id":"cilt153z40060c0tjw4flbmvg","tag_id":"cilt153ys005oc0tjtvwq5o3q","_id":"cilt153z50061c0tjh5wzd1p4"},{"post_id":"cilt153z60062c0tjes089p7d","tag_id":"cilt153vd000wc0tjjxz3e2uq","_id":"cilt153z80065c0tjqz7oq0wm"},{"post_id":"cilt153z60062c0tjes089p7d","tag_id":"cilt153z70064c0tjyf9itrzo","_id":"cilt153z80066c0tjdif785ba"},{"post_id":"cilt153z90067c0tjmfrvq2i1","tag_id":"cilt153za0069c0tjxd9jzbj7","_id":"cilt153zc006dc0tj8t2byi9o"},{"post_id":"cilt153z90067c0tjmfrvq2i1","tag_id":"cilt153zb006ac0tjnt7dpzd4","_id":"cilt153zc006ec0tjaviz0ch0"},{"post_id":"cilt153z90067c0tjmfrvq2i1","tag_id":"cilt153zb006bc0tjw452ax3g","_id":"cilt153zc006fc0tjemf4bbo9"},{"post_id":"cilt153z90067c0tjmfrvq2i1","tag_id":"cilt153zb006cc0tj00sr366j","_id":"cilt153zc006gc0tjml3u12k6"},{"post_id":"cilt153zd006hc0tjdg8ahx2y","tag_id":"cilt153ze006jc0tjr08w1fyf","_id":"cilt153ze006kc0tjxp3xq3g6"},{"post_id":"cilt153zd006hc0tjdg8ahx2y","tag_id":"cilt153vd000wc0tjjxz3e2uq","_id":"cilt153zf006lc0tjwzyiyrn8"},{"post_id":"cilt153zf006mc0tj60ik8gyq","tag_id":"cilt153zg006oc0tjlnwfvco5","_id":"cilt153zh006qc0tjn2tjahwv"},{"post_id":"cilt153zf006mc0tj60ik8gyq","tag_id":"cilt153zh006pc0tj4tzbfnfx","_id":"cilt153zh006rc0tjn4od42li"},{"post_id":"cilt153zi006sc0tjm0erxekp","tag_id":"cilt153zl006uc0tjqrl3cqtb","_id":"cilt153zm006wc0tjwzn4l6zx"},{"post_id":"cilt153zi006sc0tjm0erxekp","tag_id":"cilt153zl006vc0tj64fptcct","_id":"cilt153zm006xc0tj1uopupi8"},{"post_id":"cilt153zm006yc0tjtldfk22i","tag_id":"cilt153ys005oc0tjtvwq5o3q","_id":"cilt153zo006zc0tjj9xx8wze"}],"Tag":[{"name":"并发访问控制","_id":"cilt153tu0002c0tjpipq4d7u"},{"name":"事务","_id":"cilt153tx0003c0tjd7kxap9f"},{"name":"Bloom Filter","_id":"cilt153uo000bc0tjhahnbxyi"},{"name":"网络爬虫","_id":"cilt153up000cc0tjpbqn1czw"},{"name":"python-rq","_id":"cilt153up000dc0tjnlwpxzz2"},{"name":"分布式爬虫","_id":"cilt153up000ec0tjxl3o4i6o"},{"name":"SVN","_id":"cilt153uz000mc0tjvq6qz462"},{"name":"Deadlock","_id":"cilt153v9000rc0tjnzaj3r6p"},{"name":"Hibernate","_id":"cilt153vd000wc0tjjxz3e2uq"},{"name":"Session","_id":"cilt153ve000xc0tjdhj1r68c"},{"name":"OOP","_id":"cilt153vj0012c0tj9olenht7"},{"name":"struts","_id":"cilt153vo0016c0tjnwljpqbl"},{"name":"Tiles","_id":"cilt153vp0017c0tj5xl5g60u"},{"name":"Login","_id":"cilt153vt001dc0tj2leemi51"},{"name":"component","_id":"cilt153vw001ic0tjwl1qkka0"},{"name":"Tokens","_id":"cilt153vz001nc0tjidam134b"},{"name":"中文乱码","_id":"cilt153vz001oc0tjbif7c6p5"},{"name":"crawler","_id":"cilt153w8001xc0tj0x7g2awa"},{"name":"mongodb","_id":"cilt153w8001yc0tj0nfgr6cw"},{"name":"Scrapy","_id":"cilt153w8001zc0tjtf2l1k30"},{"name":"python","_id":"cilt153wd0026c0tj9m33q6ge"},{"name":"srcapy","_id":"cilt153we0027c0tjjt2sbxqp"},{"name":"concurrent","_id":"cilt153wg002cc0tjc95qgv2u"},{"name":"java","_id":"cilt153wh002dc0tjlq9uw2yl"},{"name":"multiThread","_id":"cilt153wh002ec0tjrhysjtec"},{"name":"markdown","_id":"cilt153wm002jc0tjo6dnuwwv"},{"name":"Exception","_id":"cilt153wr002pc0tjlqtfqb7m"},{"name":"Java","_id":"cilt153wu002sc0tjrvod7ef9"},{"name":"javaIO","_id":"cilt153ww002vc0tjolgde6fg"},{"name":"JavaIO","_id":"cilt153wz002yc0tjv0dm2w5y"},{"name":"Collections","_id":"cilt153x10032c0tjwef0ao3g"},{"name":"Duplicate from Array","_id":"cilt153x70039c0tjhkn490t5"},{"name":"Hexo","_id":"cilt153x9003cc0tj069wa1xc"},{"name":"Flask migrate","_id":"cilt153xb003gc0tjl3ucy5wf"},{"name":"Linux","_id":"cilt153xo003rc0tjuehzrsz7"},{"name":"DTD","_id":"cilt153xq003vc0tjixhvyzdb"},{"name":"Schema","_id":"cilt153xr003wc0tjcrshpos9"},{"name":"XML","_id":"cilt153xs003xc0tjmcehta59"},{"name":"Sublime Text2 Plugins install","_id":"cilt153xv0043c0tjgwaghsig"},{"name":"MVC","_id":"cilt153xy0048c0tjnfq20m09"},{"name":"Tag","_id":"cilt153y1004dc0tjcr9753gx"},{"name":"work principal","_id":"cilt153y4004ic0tjq1hykq5s"},{"name":"Validation","_id":"cilt153y7004nc0tjpdpbl6ij"},{"name":"Java-Singleton","_id":"cilt153ya004rc0tjqrxnbq7f"},{"name":"科学计算","_id":"cilt153yc004vc0tj4bwat815"},{"name":"全栈工程师","_id":"cilt153yd004wc0tjxdx47z4y"},{"name":"数据挖掘","_id":"cilt153yd004xc0tjnwdqj4lh"},{"name":"文本处理","_id":"cilt153yd004yc0tjpxwfhx0n"},{"name":"机器学习","_id":"cilt153ye004zc0tjnltxyxr0"},{"name":"Classpath","_id":"cilt153yi0058c0tje92yyrtt"},{"name":"Path","_id":"cilt153yi0059c0tjhzs98mc6"},{"name":"python yield","_id":"cilt153yk005ec0tjcno8ae3q"},{"name":"study","_id":"cilt153yl005fc0tjgr9chplp"},{"name":"ORM","_id":"cilt153yp005kc0tj35jpg8s2"},{"name":"NIO","_id":"cilt153ys005oc0tjtvwq5o3q"},{"name":"对象映射","_id":"cilt153z70064c0tjyf9itrzo"},{"name":"HQL","_id":"cilt153za0069c0tjxd9jzbj7"},{"name":"QBC","_id":"cilt153zb006ac0tjnt7dpzd4"},{"name":"Query","_id":"cilt153zb006bc0tjw452ax3g"},{"name":"stored procedure","_id":"cilt153zb006cc0tj00sr366j"},{"name":"Configuration","_id":"cilt153ze006jc0tjr08w1fyf"},{"name":"Hashmap","_id":"cilt153zg006oc0tjlnwfvco5"},{"name":"hashtable","_id":"cilt153zh006pc0tj4tzbfnfx"},{"name":"Abstract","_id":"cilt153zl006uc0tjqrl3cqtb"},{"name":"Interface","_id":"cilt153zl006vc0tj64fptcct"}]}}