本文是对CAP定理的简介、证明以及思考。其中理论证明部分主要来自于对Gilbert与Lynch的两篇论文(《Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services》 和 《Perspectives on the CAP Theorem》)的理解。
CAP是一致性(Consistency)、可用性(Availability)以及分区容忍性(Partition Tolerance)的首字母缩写,而CAP定理要说明的是,针对这三种特性,一个分布式系统,同时只能满足两个。在分布式环境中,系统大都通过网络链接,彼此之间存在分区,所以分区容忍性往往是所处的现实基础,这个定理也可以这么说,在一个容易出现错误的分布式环境中,无法同时满足一致性和可用性。
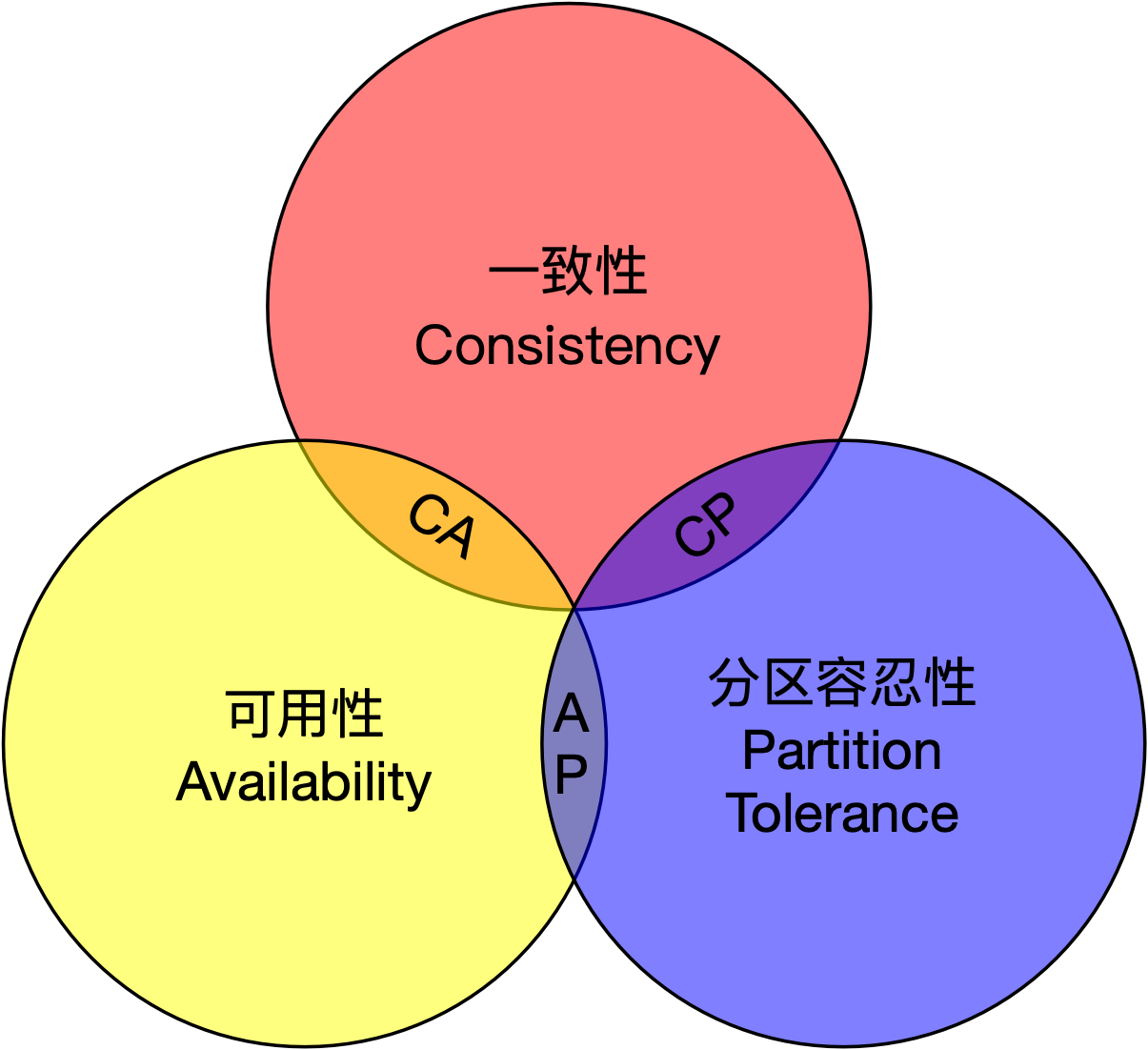
由于三者不可得兼,而分区容忍性无法避免,所以业界既有很多CP和AP选择的分布式系统,比如:BASE思想(所谓软状态,最终一致性)就是AP的一种成功实践。
针对三种特性,分别做一些解释。
一致性(Consistency),表示分布式系统的不同分区的数据副本之间是一致的,这么定义有些严格,宽泛的讲,从外部请求这个分布式系统,能够有一致的存取和访问结果,先进行存储,后进行读取能够读到最新的值。如果由于分区的存在,导致分区之间数据不一致,这样一致性就无法兑现,但通过数据同步使得数据在一段延迟后重新一致,这种情况可以称之为最终一致性或者瞬时不一致。
可用性(Avaiability),表示分布式系统在任何时刻都能够提供服务的能力。如果分布式系统能够在理论上满足任何时刻可以提供服务,那么这个分布式系统具备良好的可用性。如果由于分区的存在,导致系统从整体上看,有稳定性风险,那么该分布式系统的可用性是不足的。
分区容忍性(Partition Tolerance),表示分布式系统多个分区(或者副本)之间能够封闭运行,可以在一个分区出现通信问题或者分区之间存在通信问题的情况下,系统对外表现工作良好。如果一个分布式系统,能够在分区或者分区之间通信不稳定的情况下稳定工作,那么表明该系统具备良好的分区容忍性。
在2000年的分布式计算原理会议(PODC)上,Brewer提出了一个猜想:对一个Web服务,是无法同时保证一致性、可用性和分区容忍性的。MIT的Lynch等人针对这个猜想做了详细的论证和分析,一定程度上形式化证明了该猜想,并基于该猜想,探讨了分布式环境下,如何能够更实际的认识、面对和处理这三者之间的关系。
定理1. 在一个异步网络模型的分布式系统中,是无法同时保证可用性和一致性的。
在异步网络模型下的分布式系统,各节点没有时钟协调,仅通过收到远程消息并进行本地计算来完成工作。异步网络模型的特点是被动的接受消息并处理,而结果也通过消息进行传递,这个过程可能存在消息的丢失或者消息(由于投递而)延迟。简单可以把它理解为一个完全有异步消息连接的分布式系统,各个节点如同一个个的任务,不断的消费消息,并产生消息,异步网络的效率高,但是相对可靠性差,原因就是没有过多的约束来强化可靠性。
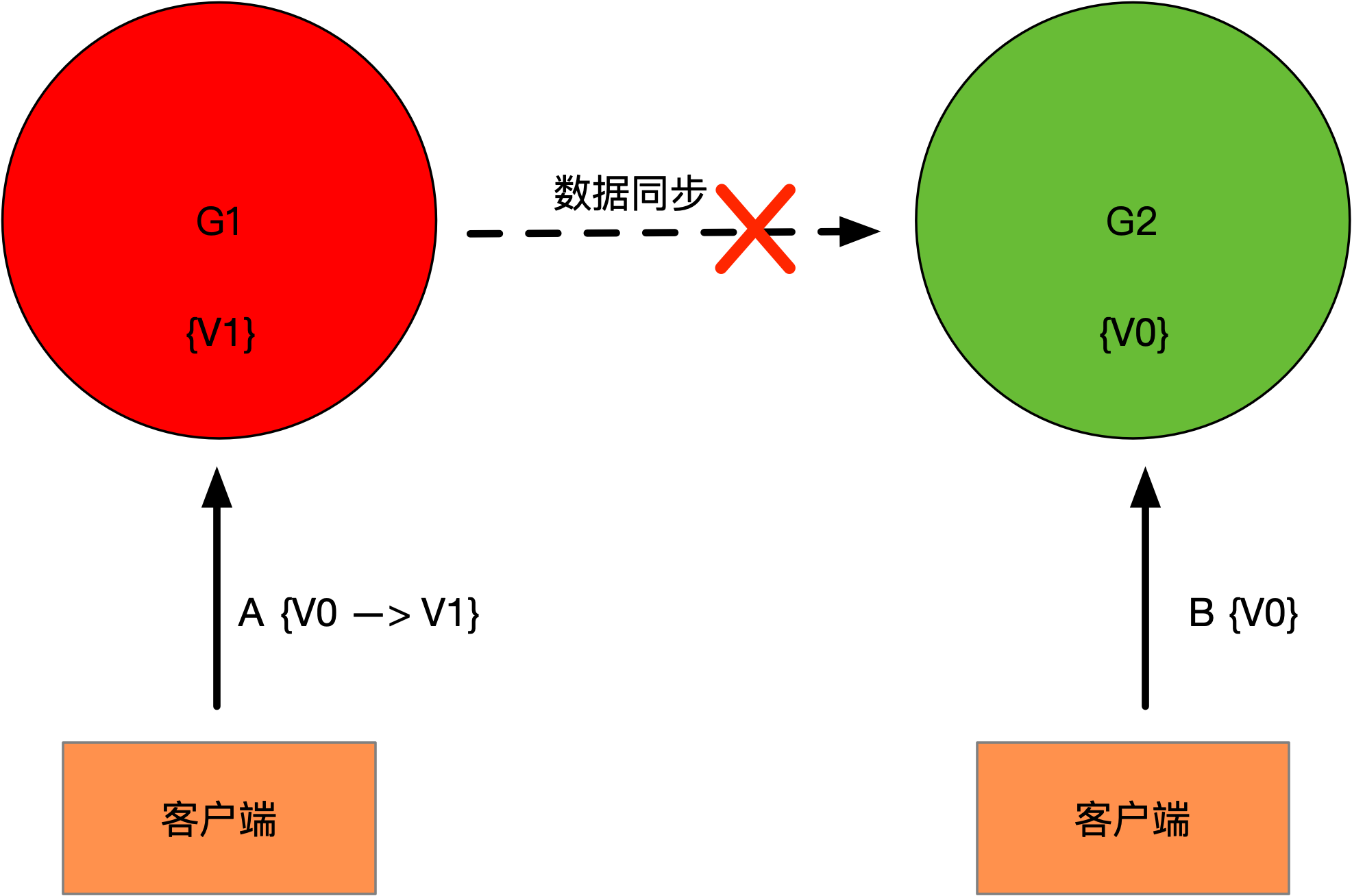
证明:使用反证法。假定存在一个算法,在异步网络的不同的节点 {G1, G2},能够同时满足CAP特性,其中G1和G2保存的数据为初始值V0。假定存在两个操作,其中:操作A,写请求G1,将V0改为V1;操作B,读请求G2,获取值。操作A先于操作B,由于当前算法满足CAP,所以操作B获取到的值是V1。由于G1和G2之间是异步网络,G1和G2之间的数据同步消息存在丢失和延迟,操作B返回的值很有可能还是V0,这样实际情况就违反了一致性,因此不存在有类似算法在异步网络模型的分布式系统中,同时满足CAP特性。证明的参考过程如下图所示:
通过证明可以看出,在异步网络模型下,CAP特性无法同时满足,但是做到其中两个,还是可以的。如果选择CP,那么被交换的就是A,通过消息传递时的相互确认,能够确保一致性得以保证,特别是建立在分布式锁或者分布式多写方案上的数据存储服务,大都属于CP类型。当然它们对于A的交换并不是视而不见,而是通过一些备份的手段加以保障,比如:一主多备的方式,来提升一定可用性,避免长时间的宕机,这种模式一般叫做CP+高可用。如果选择CA,那么被交换的就是P,这样就在一个中心化系统结构下,是比较容易做到CA的,在局域网中运作的系统,往往就是这种,比如:局域网中部署一个MySQL实例,处于同一局域网的应用服务对其进行访问。如果选择AP,那么被交换的就是C,一个高可靠和能够分区的分布式系统是很有价值的,比如:Web服务中的缓存(或者CDN),这种选择并不是对于一致性放任不管,而是允许弱一致性,或者说在一段时间后数据一定会在不同分区形成一致,这就是我们常说的最终一致性。
定理2. 在一个部分同步网络模型的分布式系统中,是无法同时保证可用性和一致性的。
部分同步网络模型下的分布式系统,各个节点拥有一个时钟,时钟之间没有同步,是各个节点私有的,只是跳动频率一致,这点看起来仿佛比异步网络模型没有强多少,但是在实际功能上还是比异步网络模型要多一些。比如:部分同步网络由于节点时钟的存在,就可以知道发送一个消息后,如果多长时间没有回执,那么就可以判定这个消息可能无效,而异步网络模型无法做到这点。在部分同步网络模型下,可以实现确定性的请求和应答机制,以及随之而来的,“无效”的请求和应答机制(也就是调用超时,对方可能没有收到,判定当次请求无效)。
证明方式同异步网络模型类似,都是由于通信的不可靠性,在部分同步网络模型的分布式系统中,不存在一个算法同时满足CAP特性。
在部分同步网络模型下,传输约束高于异步网络模型,可以做到有条件的弱一致性,这个有条件表示的是可预期的延迟。由于该网络模型下能够确定消息传输的确定性,因此在一段(或者说可以预知的)时间延迟下,能够在P的前提下达成C。当然A也是可以做到的,因为在分区的节点之间,一个节点的访问,不会要求其他节点强参与,这样就做到了A。C是要求所有节点的数据能够一致,这点在部分同步网络模型下,分布式系统节点之间数据完成同步传输的操作(一般是同步消息传递)是可以预期的,所谓预期就是可预知时间的延迟,也就是说能够建立一个在特定时长后可以保证数据一致性的(弱一致性)分布式系统。
分区容忍性需要考虑不同分区之间是无法访问的。一般意义上,分布式系统都会有P,那么在分布式系统中剩下的就是C和A选择哪个了。如果是TDDL(淘宝分布式数据访问层)类似的系统,多个原子数据库之间不能相互访问,那么就剩下C和A的选择了,目前看选择了C。
一致性在不同的场景上,实际上有不同的要求,有强弱的区别。按照不同的场景,从服务的角度看一致性,如下表所示:
| 服务类型 | 描述 | 场景 |
|---|---|---|
| 不重要的服务 | 在服务集群中,节点之间不需要通信,它们只是只读的返回信息 | 地址服务或者一些元知识服务,这种服务对于一致性的要求就很低,在一定程度上会避免落入CAP的矛盾选择中 |
| 弱一致性服务 | 在分布式服务中,更加看重可用性,一致性最终会达成 | AP类型的存储服务,比如:分布式缓存服务 |
| 简单服务 | 提供了简单操作的一致性保证 | CP类型的存储服务,比如:HBase、MongoDB |
| 复杂服务 | 有复杂的分布式协调或者事务语义的服务,也可能是多个简单服务或其他类型服务的叠加 |
在分区一定会存在的分布式环境中,对于分区,有以下若干模式,如下表所示:
| 分区模式 | 描述 | 场景 |
|---|---|---|
| 数据分区 | 从数据类型下手,不同的数据类型对于一致性要求是不一样的,在不同的数据类型对应的系统设计时,根据它的实际场景,考量取舍 | 在一个电商系统中,购物车和商品这两个数据类型(或者说支撑它们的分布式系统),对于一致性的要求一定是不同的,商品对于一致性的要求比购物车低。因此商品系统可以多考虑缓存技术,而购物车系统需要关注CP类的存储 |
| 操作分区 | 根据操作维度进行分区,对于数据的不同访问方法,提供不同的一致性和可用性保证,使整个系统对外表现更好 | 对于数据的更改,需要做到一致性,而数据的某些读取场景,可能不需要那么实时,这种常见的场景就是分布式缓存和关系数据库的组合,对于写,直接作用于数据库,它是强一致性的,但是读,往往先经过缓存,这时可用性会得到保证 |
| 用户分区 | 按照用户的地理位置或者相关的业务逻辑,将用户数据分散在不同的分区中,使用户能够就近分区访问,提升访问效率 | CDN服务就是一个用户分区的例子,用户访问Web服务,系统会根据用户的地理位置,将用户对于资源获取的请求转派到离用户更近的区域网络,从而使用户获得更好的访问体验 |
| 层次分区 | 多个分布式系统会组成一个整体,但是不同的系统提供的功能和层次都是不一样的,根据系统的层次来进行分区 | 不同的分布式系统会组成一个统一的整体,就像一颗树,根节点变化少,而叶子节点离用户近,不同的层次的节点对一致性和可用性有不同的倾向性 |
一致性和可用性存在矛盾,在分布式环境(也就是存在分区)的前提下,分区已经成为既定事实,因为分区间的通信是不能保证绝对意义的可靠,因此:
(1)如果看重一致性,那么就要求多个分区之间的数据在更新时强一致,解法就是在更新时锁定多个分区,这就会导致可用性降低;
(2)如果保证可用性,就必须做到多个分区之间的更新不相互耦合,唯一可以想到的是异步进行更新,那么结果就是一致性不被满足。
面对这种矛盾,如果设计一个分布式数据存储系统,通过混合数据源来完成对业务需求的支持,比如:MySQL+MongoDB,利用MySQL的事务性来支持安全的写,使用MongoDB来满足复杂场景的读,数据会从MySQL向MongoDB同步。
混合数据源的方案已经使得该系统至少包含两个节点,因此分区已经成为现实,或者说在分布式系统中,往往分区容忍性是必须具备的,那么这个系统就要在一致性或者可用性中做选择了:
(1)如果选择一致性,这就要求所有的变更在多个节点(MySQL和MongoDB)中是一致的,这时会使用分布式事务来保障不同节点的数据一致性,但是节点之间的网络可能存在问题,导致整体的访问出现错误,导致可用性无法完全兑现;
(2)如果选择可用性,可以看出当MySQL发生数据变更后,会从网络同步变更到MongoDB,一般会选择消息系统,如果网络出现问题,将会在下次恢复时完成同步。虽然数据在一个时刻(或一瞬),存在短暂的不一致,无法兑现一致性,但是用户的访问的可用性能够得到保证。当然如果选择可用性,也就是AP模式,对于数据同步,可以考虑提升硬件的支持,比如:多条网线连接等方式。
在CAP定理的限定下,许多开发者仍在通过各自的努力,在不同的场景下减少CAP定理带来的麻烦,而基本思路都是在P成立的基础上,看是做到C或A,或者说侧重C或A:
(1)尽力而为的可用性,即CP类型。这种设计往往在是在一个数据中心中提供稳定的服务,如果要跨数据中心,将会导致其可用性严重下降。CP类型并不是表示对可用性不看重,以谷歌的分布式锁服务Chubby为例,Chubby集群包括若干节点,只要超过半数能够正常工作,那么Chubby就能提供稳定的服务。可以看到,只要一个数据中心中过半数的Chubby节点承认了本次请求,就认为请求被许可,而可用性也得到了最大限度的提升;
(2)尽力而为的一致性,即AP类型。在某些场景下,牺牲可用性是不可取的,用户需要立刻看到响应,比如:用户在请求一个网页,需要快速的获得响应页面,纵使它的数据可能不那么实时。AP类型常见的使用场景是缓存服务,在互联网这种读远远大于写的场景里,缓存服务被大量使用,缓存服务会缓存用户数据。用户实时数据往往存储在关系数据库中,缓存服务能够提供给前端更快速响应的同时,还大大提升了可用性,虽然数据的一致性会有挑战,但可以通过过期时间来做到用户数据的最终一致性。