Contents
Databricks Runtimes are the set of core components that run on Databricks clusters. These components include general optimizations to Delta Lake and Apache Spark, as well as pre-installed libraries for R, Python, and Scala/Java. For instance, the Machine Learning Runtime has stable versions of XGBoost, Tensorflow, and Pytorch installed and configured to work out of the box. These components help make Databricks a platform to develop quickly, with minimal library setup and debugging required.
To learn more about what is in each runtime, it is worth reading the release notes for each version.
In addition to general optimizations included in DBR, there is also an optimization related to user defined functions in SparkR that is not available in open source.
User defined functions are a powerful way to scale out arbitrary R code using Spark. This process involves communicating R commands from the driver node to workers across the cluster using gapply(), dapply(), or spark.lapply(). However, during these communications a bottleneck is created when serializing and deserializing commands from the Spark process to R and vice versa. Performance suffers and the utility of UDFs is weakened. Here you can see the ser/deserialization operations to and from R on a worker node:
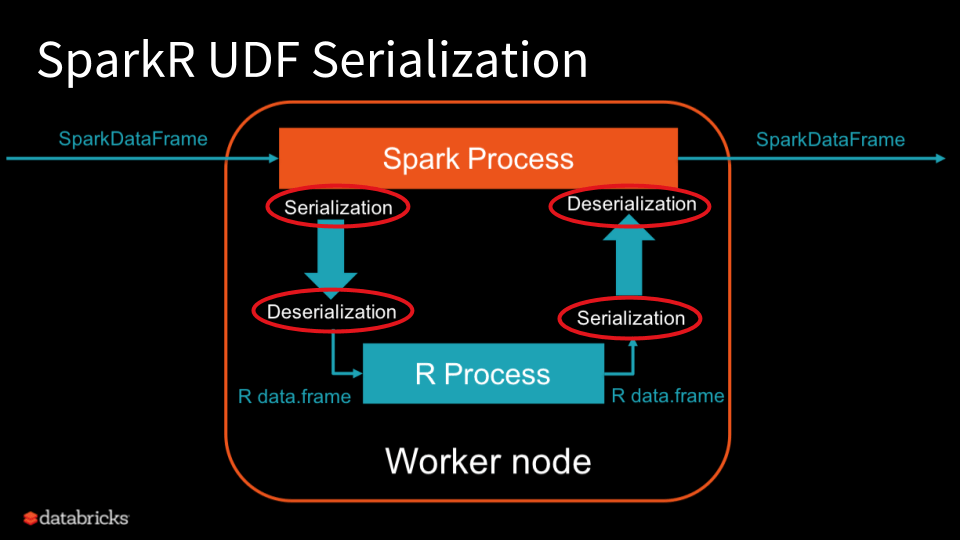
As described in the official blog post,
The data gets serialized twice and deserialized twice in total, all of which are row-wise. By vectorizing data serialization and deserialization in Databricks Runtime 4.3, we encode and decode all the values of a column at once. This eliminates the primary bottleneck which is row-wise serialization, and significantly improves SparkR’s UDF performance. Also, the benefit from the vectorization is more drastic for larger datasets.
Here is one example of the performance improvement over open source Spark using gapply():

More details can be found in the blog.
This optimization is similar to what can be achieved by enabling Apache Arrow for user defined functions with Spark and R. The difference is that as of this writing, the SparkR optimization in DBR works out of the box.
You can find the list of R packages included in a runtime by inspecting the release notes. Here is an example from DBR 5.5:
| Library | Version | Library | Version | Library | Version |
|---|---|---|---|---|---|
| abind | 1.4-5 | askpass | 1.1 | assertthat | 0.2.1 |
| backports | 1.1.3 | base | 3.6.0 | base64enc | 0.1-3 |
| BH | 1.69.0-1 | bit | 1.1-14 | bit64 | 0.9-7 |
| bitops | 1.0-6 | blob | 1.1.1 | boot | 1.3-20 |
| brew | 1.0-6 | callr | 3.2.0 | car | 3.0-2 |
| carData | 3.0-2 | caret | 6.0-82 | cellranger | 1.1.0 |
| chron | 2.3-53 | class | 7.3-15 | cli | 1.1.0 |
| clipr | 0.5.0 | clisymbols | 1.2.0 | cluster | 2.0.8 |
| codetools | 0.2-16 | colorspace | 1.4-1 | commonmark | 1.7 |
| compiler | 3.6.0 | config | 0.3 | crayon | 1.3.4 |
| curl | 3.3 | data.table | 1.12.0 | datasets | 3.6.0 |
| DBI | 1.0.0 | dbplyr | 1.3.0 | desc | 1.2.0 |
| devtools | 2.0.1 | digest | 0.6.18 | doMC | 1.3.5 |
| dplyr | 0.8.0.1 | ellipsis | 0.1.0 | fansi | 0.4.0 |
| forcats | 0.4.0 | foreach | 1.4.4 | foreign | 0.8-71 |
| forge | 0.2.0 | fs | 1.2.7 | gbm | 2.1.5 |
| generics | 0.0.2 | ggplot2 | 3.1.0 | gh | 1.0.1 |
| git2r | 0.25.2 | glmnet | 2.0-16 | glue | 1.3.1 |
| gower | 0.2.0 | graphics | 3.6.0 | grDevices | 3.6.0 |
| grid | 3.6.0 | gridExtra | 2.3 | gsubfn | 0.7 |
| gtable | 0.3.0 | h2o | 3.22.1.1 | haven | 2.1.0 |
| hms | 0.4.2 | htmltools | 0.3.6 | htmlwidgets | 1.3 |
| httr | 1.4.0 | hwriter | 1.3.2 | hwriterPlus | 1.0-3 |
| ini | 0.3.1 | ipred | 0.9-8 | iterators | 1.0.10 |
| jsonlite | 1.6 | KernSmooth | 2.23-15 | labeling | 0.3 |
| lattice | 0.20-38 | lava | 1.6.5 | lazyeval | 0.2.2 |
| littler | 0.3.7 | lme4 | 1.1-21 | lubridate | 1.7.4 |
| magrittr | 1.5 | mapproj | 1.2.6 | maps | 3.3.0 |
| maptools | 0.9-5 | MASS | 7.3-51.1 | Matrix | 1.2-17 |
| MatrixModels | 0.4-1 | memoise | 1.1.0 | methods | 3.6.0 |
| mgcv | 1.8-28 | mime | 0.6 | minqa | 1.2.4 |
| ModelMetrics | 1.2.2 | munsell | 0.5.0 | mvtnorm | 1.0-10 |
| nlme | 3.1-140 | nloptr | 1.2.1 | nnet | 7.3-12 |
| numDeriv | 2016.8-1 | openssl | 1.3 | openxlsx | 4.1.0 |
| parallel | 3.6.0 | pbkrtest | 0.4-7 | pillar | 1.3.1 |
| pkgbuild | 1.0.3 | pkgconfig | 2.0.2 | pkgKitten | 0.1.4 |
| pkgload | 1.0.2 | plogr | 0.2.0 | plyr | 1.8.4 |
| praise | 1.0.0 | prettyunits | 1.0.2 | pROC | 1.14.0 |
| processx | 3.3.0 | prodlim | 2018.04.18 | progress | 1.2.0 |
| proto | 1.0.0 | ps | 1.3.0 | purrr | 0.3.2 |
| quantreg | 5.38 | R.methodsS3 | 1.7.1 | R.oo | 1.22.0 |
| R.utils | 2.8.0 | r2d3 | 0.2.3 | R6 | 2.4.0 |
| randomForest | 4.6-14 | rappdirs | 0.3.1 | rcmdcheck | 1.3.2 |
| RColorBrewer | 1.1-2 | Rcpp | 1.0.1 | RcppEigen | 0.3.3.5.0 |
| RcppRoll | 0.3.0 | RCurl | 1.95-4.12 | readr | 1.3.1 |
| readxl | 1.3.1 | recipes | 0.1.5 | rematch | 1.0.1 |
| remotes | 2.0.2 | reshape2 | 1.4.3 | rio | 0.5.16 |
| rlang | 0.3.3 | RODBC | 1.3-15 | roxygen2 | 6.1.1 |
| rpart | 4.1-15 | rprojroot | 1.3-2 | Rserve | 1.8-6 |
| RSQLite | 2.1.1 | rstudioapi | 0.10 | scales | 1.0.0 |
| sessioninfo | 1.1.1 | sp | 1.3-1 | sparklyr | 1.0.0 |
| SparkR | 2.4.4 | SparseM | 1.77 | spatial | 7.3-11 |
| splines | 3.6.0 | sqldf | 0.4-11 | SQUAREM | 2017.10-1 |
| statmod | 1.4.30 | stats | 3.6.0 | stats4 | 3.6.0 |
| stringi | 1.4.3 | stringr | 1.4.0 | survival | 2.43-3 |
| sys | 3.1 | tcltk | 3.6.0 | TeachingDemos | 2.10 |
| testthat | 2.0.1 | tibble | 2.1.1 | tidyr | 0.8.3 |
| tidyselect | 0.2.5 | timeDate | 3043.102 | tools | 3.6.0 |
| usethis | 1.4.0 | utf8 | 1.1.4 | utils | 3.6.0 |
| viridisLite | 0.3.0 | whisker | 0.3-2 | withr | 2.1.2 |
| xml2 | 1.2.0 | xopen | 1.0.0 | yaml | 2.2.0 |
| zip | 2.0.1 |
You can find the list of packages for various versions of DBR here:
For more information on package management for packages that do not already exist in Databricks Runtime, please see Developing on Databricks - Package Management.