Video content contains complex and dynamic visual features that can traverse spatially over time. Methods to generate descriptions of video content should therefore incorporate both spatial and temporal features. We propose a novel architecture using LSTM with spatio-temporal attention to capture important information in the video content while predicting the caption and show that it achieves good results on the MSRVTT data set.
The video captioning task consists of producing a variable length description of the content in a given video. For the purpose of this task videos are usually represented as a sequence of frames which are processed in different ways to produce a caption. In order to describe the content of the video it is important to understand the spatial and temporal interaction between the components of the frames present in the video. We propose a novel architecture which uses an LSTM to track the interaction between the important objects present in the image frames by attending over the subregions of the frames at every time step. Later, while predicting the caption we attend over the hidden states of the tracking LSTM temporally to identify the important clips present in the whole video. Our model is able to attend to the subregions of the important frames present in the video while predicting each word of the caption achieving results that are better than the baseline model.
Several architectures have been proposed for the task of video captioning. Venugopalan et. al. [2014] trained an LSTM on video-sentence pairs, by averaging the CNN feature vectors of the frames in the video and passing them to every time step of a LSTM to predict the caption. Venugopalan et. al. [2015] trained a network that learned to associate video frames to a sequence of words and generate descriptions of the video content using a sequence-to-sequence LSTM to first encode the video frames represented by CNN feature vectors and optical flow measures and send this encoding to a decoder that produces a description of the video content. Yao et. al. [2015] used spatial-temporal 3-D convolutional neural network (3-D CNN) to represent the short temporal dynamics of videos and a LSTM to perform soft attention on the global temporal structure in the video. Du et. Al. [2018] note that 3-D convolution has high training complexity and may require massive training sets. They also propose a compact spatio-temporal attention module used for action recognition. Most techniques for video captioning use maximum likelihood to maximize the probability of the true word at step t in the caption given the true word at step t-1. However, at test time the true word at step t-1 is usually not known. Ranzato et. al. [2015] propose using REINFORCE to directly optimize non-differentiable metric scores and Wang et. al. [2017] implement hierarchical reinforcement learning with a "high-level manager" and a "low-level" worker to address both local and global temporal resolution, along with temporal attention, to achieve state-of-the-art results on the MSRVTT video captioning task. Pasunuru and Bansa [2017] also achieve state-of-the-art on MSRVTT using multi-task learning, combining temporal attention based LSTM model for the video captioning task with unsupervised video prediction and entailment generation.
To address the spatial and temporal dynamics of video content, we introduce a novel architecture that uses LSTM to perform spatio-temporal tracking of important objects or actors within each video frame. The architecture is described in Figure 1.

Figure 1: The proposed Spatio-Temporal LSTM Network. LSTM1 and LSTM3 unroll over the length of the sentence, while LSTM2 unrolls over the length of the video. LSTM2 applies spatial attention over the frames of the video at every time step picking the most important objects in the frame. Hidden state of LSTM2 is initialized with ht, the hidden state of LSTM1, which contains information of the caption generated so far. We predict the next word of the caption using the hidden state of LSTM3, by picking out the most important frames using temporal attention over the hidden states of LSTM2, which contains representation of the important objects in each frame.
In the architecture above zt is the word predicted by the model at step t, ht is the hidden state of the LSTM1 at step t, V = V1, V2…Vn are the feature vectors of the n frames in the video obtained from the last convolutional layer of ResNet152, thus Vi = 512 x 7 x 7 for all frames in the video. We use average pooling of filter size 4 to bring them down to 512 x 2 x 2 to reduce the size of the features so that they fit in CPU memory, we can add deconvolutional layers to bring back the spatial dimensions of the video frames.
Given that, each frame is now represented using spatial features, we apply spatial attention to pick the most important spatial regions of frames for predicting the next word in the caption. The resulting features describing the frames are given as input to LSTM2. The temporal attention module picks the important frames in the temporal dimension that are most relevant for predicting the next word. We predict the next word in the caption, zt+1, by attending over the hidden states of LSTM2, , concatenated with ht passed by LSTM1.
We unroll LSTM1 and LSTM3 over the length of the sentence, while LSTM2 unrolls over the length of the video at every time step of LSTM1 and LSTM3 forming a grid like structure.
That is, in each time step of the caption sequence, the hidden state of the LSTM2, is initialized with the current hidden state of LSTM1 ht which contains information of the caption generated so far. Using this information, the LSTM2 then unrolls over the length of the video where at each time step of the video we use its hidden state to attend over the spatial CNN features, picking the important features to track in that frame. Finally the third LSTM3 uses attention over all of the hidden states of the LSTM2, which contains the spatio-temporal information of the features in the video, to pick the important features that are useful for predicting the next word.
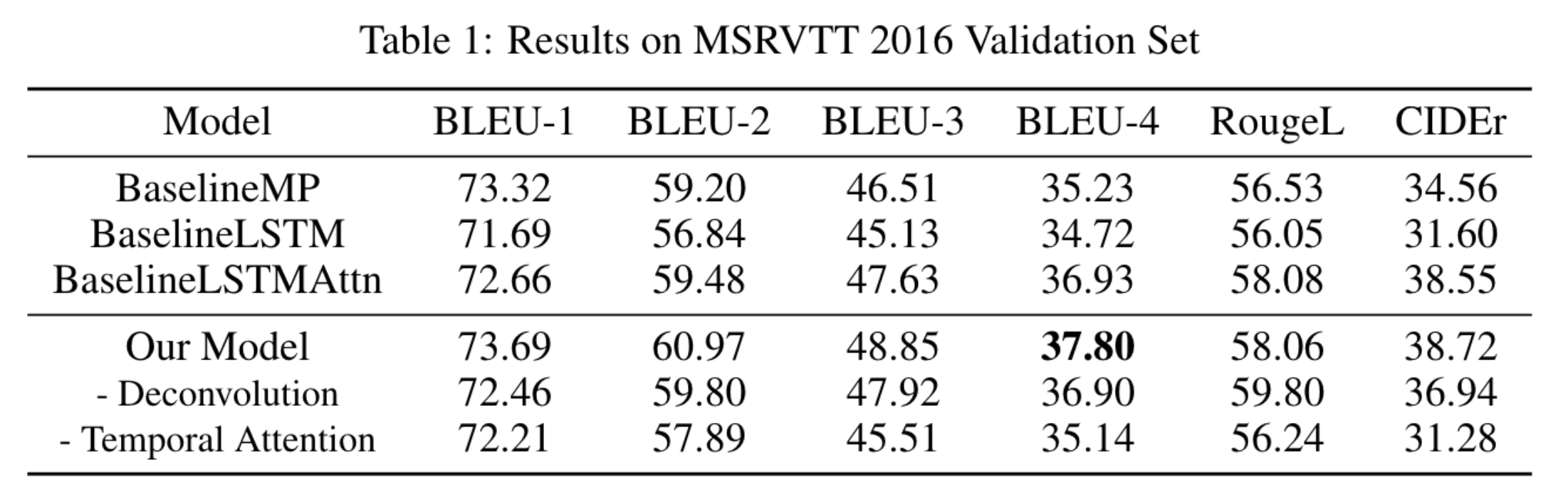
Our baseline model will follow Venugopalan[2014] which uses mean pooling over the CNN features of video frames V as input to each step of the decoder LSTM along with the previous word predicted. We call this model BaselineMP. The baseline model achieves reasonably high performance on the MSRVTT dataset as shown in Table~\ref{results-table}. Our second baseline consists of an encoder LSTM which takes the sequence of the video frames as input to get a video representation that is used to initialize the decoder hidden state for predicting the caption. Our third baseline consists of a decoder that attends to the hidden states of the LSTM encoder described above while predicting every word of the caption. We name our second and third models BaselineLSTM, BaselineLSTMAttn respectively. The video features for our baseline model are taken from the last layer of the Resnet model which is of size 1000 x 1 x 1. Our proposed model uses features from the last convolutional layer of the Resnet model having size 512 x 7 x 7. We use average pooling to bring down the spatial dimension to 512 X 2 X 2 because of CPU memory constraints. The hidden size of the LSTMs in our proposed model is 256 and we use a dropout of 0.3 between the layers. Our implementation of the architecture described in section 1.2, reached top-10 performance on BLEU@4 on the MSRVTT 2016 data set. We have also reported the results for the current state of the art model on this task which uses an ensemble of five different models. The single model accuracy is not known.

Through experimentation we determine that using high quality feature extraction for video frames is crucial to the success of our video captioning system. We build models using video features extracted with Alexnet, Resnet18, and Resnet152. We have observed that Resnet152 works best emphasizing the importance of better features.
We have examined if our LSTM attention model attends to important spatial regions of the frames present in the video while predicting the caption. To do so we visualize the temporal attention weights of the frames in the video which demonstrate the ability of the model to pick important frames and the spatial attention weights over each frame to identity important objects in a given frame. Figure 2 shows the attention results while predicting the caption 'a man is driving a car'. We have observed that indeed our LSTM model attends to relevant frames and sub-regions of frames tracking the spatio-temporal relation between objects in the video while predicting each word in the caption.

Figure 2: showing the spatio-temporal attention weights. For each predicted word, highlighted in red, we include the important video frames, as determined by temporal attention, in the order they appear in the video. The temporal attention module weights are shown in bottom left corner in white. For each frame we have identified the important spatial regions picked by the spatial attention module and show the attention probabilities for those regions.
Our proposed architecture achieves good results on the MSRVTT data set and analysis of the attention modules support that our model learns spatio-temporal features of video frames. Our current implementation can be improved in several ways. First, due to memory constraints, we have performed average pooling to reduce the spatial dimension of our video features, instead we can use higher spatial dimension for video features with out average pooling to represent objects better. In this work we implement greedy search during caption generation and expect that using beam search can improve our models performance. Lastly, by examining the MSRVTT dataset we find that most videos just require a single frame to predict the caption and our model does not gain any advantage in solving this task.
