Huge memory usage by retention policy #10453
Comments
|
@aslobodskoy-fiksu which index are you using? |
|
@e-dard I don't see such huge spikes anymore but overall memory consumption doesn't look great. |
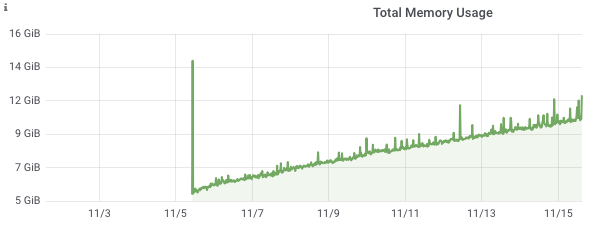
|
I've switched influxdb to tsi1. The spikes are not so high but general trend of memory consumption doesn't look fine |

|
Hi, I tried to troubleshoot the same issue with retention policy. I switched to tsi1 (removed everything from the db before that) and now have very similar simptoms, memory usage is increasing. I'll be very grateful for any relevant suggestion. Influxdb 1.7.3 is running in docker swarm, as a service. Data is stored on aws ebs gp2 volume. pprof: pprof heap top: pprof allocs top: Logs are all the same: Looks like the issue is in func (p *LimitedBytes) Get(sz int) which makes no sence as it's a part of utility package. |

|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
This issue has been automatically closed because it has not had recent activity. Please reopen if this issue is still important to you. Thank you for your contributions. |
|
Is this issue got fixed? Total memory is 30GB. |

|
@Dileep-Dora my suspicion there is that you're running the |
|
Influxdb is crashing my VMM server every 6h - 24h. I suspected that memory runs out and this seems to be the case. This problem happens since I had the bad idea to upgrade to v1.7.x, the more I upgrade the less longer it works. So I changed the config file from TSM to TSI started following command...
After 5h not one single index folder was created... I checked it by... I know you guys put a lot of effort in this DB, but I want to avoid to become an influxDB expert, before it works without OOM |
|
@lobocobra sorry to hear you're having problems. Those sorts of questions seem like they would be better answered on the community forum, rather than the issue tracker. https://community.influxdata.com/ |
|
thanks for the response. I understand.... I isolated the issue by moving influxdb to a new virtual server... guess what server crashed after a while. In 1.6.4 I had never such problems. I guess I have simply to find out how to downgrade influxdb and then I will wait until the bug was found and solved, before I upgrade again. Some examples... |
|
@lobocobra |
|
@lobocobra @positron96 |
Well, I downgraded to 1.7.1 and disabled TSI, it already helped remove disk usage spikes and RAM consumption is some 50-80 mb less (quite a lot on 512 mb server). Here is transition from 1.7.9 to 1.7.1 and disabling TSI: |

|
@positron96 Here are the steps I did to downgrade, it might help others: Here how to re-index.... (only neded for ts1) Memory usage went down from 1.1GB to 340 MB. |
|
Is this still an issue for people? My influx db memory usage increases steadily over the course of 72h (approx.) until it basically incapacitates the server it is running on. I wonder if there is a more recent fix for this? |
System info: Official docker image 1.6.4-alpine
Steps to reproduce:
Actual behavior: Huge memory consumption

Additional info:
PS
With 1.6.3 we got little bit another behaviour. Once per week (shard group duration 7 days) it was running extremely long(2-3 hours), continuously consume memory and crashes because of OOM.
The text was updated successfully, but these errors were encountered: