diff --git a/docs/source/ja/_toctree.yml b/docs/source/ja/_toctree.yml
index 5515e1b6811..9766571c6b8 100644
--- a/docs/source/ja/_toctree.yml
+++ b/docs/source/ja/_toctree.yml
@@ -284,6 +284,14 @@
title: CamemBERT
- local: model_doc/canine
title: CANINE
+ - local: model_doc/codegen
+ title: CodeGen
+ - local: model_doc/code_llama
+ title: CodeLlama
+ - local: model_doc/convbert
+ title: ConvBERT
+ - local: model_doc/cpm
+ title: CPM
title: 文章モデル
- isExpanded: false
sections:
@@ -291,6 +299,12 @@
title: BEiT
- local: model_doc/bit
title: BiT
+ - local: model_doc/conditional_detr
+ title: Conditional DETR
+ - local: model_doc/convnext
+ title: ConvNeXT
+ - local: model_doc/convnextv2
+ title: ConvNeXTV2
title: ビジョンモデル
- isExpanded: false
sections:
@@ -317,6 +331,12 @@
title: BROS
- local: model_doc/chinese_clip
title: Chinese-CLIP
+ - local: model_doc/clip
+ title: CLIP
+ - local: model_doc/clipseg
+ title: CLIPSeg
+ - local: model_doc/clvp
+ title: CLVP
title: マルチモーダルモデル
- isExpanded: false
sections:
diff --git a/docs/source/ja/model_doc/clip.md b/docs/source/ja/model_doc/clip.md
new file mode 100644
index 00000000000..741d240b0ce
--- /dev/null
+++ b/docs/source/ja/model_doc/clip.md
@@ -0,0 +1,220 @@
+
+
+# CLIP
+
+## Overview
+
+CLIP モデルは、Alec Radford、Jong Wook Kim、Chris Hallacy、Aditya Ramesh、Gabriel Goh Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) で提案されました。
+サンディニ・アガルワル、ギリッシュ・サストリー、アマンダ・アスケル、パメラ・ミシュキン、ジャック・クラーク、グレッチェン・クルーガー、イリヤ・サツケヴァー。クリップ
+(Contrastive Language-Image Pre-Training) は、さまざまな (画像、テキスト) ペアでトレーニングされたニューラル ネットワークです。かもね
+直接最適化することなく、与えられた画像から最も関連性の高いテキスト スニペットを予測するように自然言語で指示されます。
+GPT-2 および 3 のゼロショット機能と同様に、タスクに対して。
+
+論文の要約は次のとおりです。
+
+*最先端のコンピューター ビジョン システムは、あらかじめ定められたオブジェクト カテゴリの固定セットを予測するようにトレーニングされています。これ
+制限された形式の監視では、指定するために追加のラベル付きデータが必要となるため、一般性と使いやすさが制限されます。
+その他の視覚的なコンセプト。画像に関する生のテキストから直接学習することは、
+より広範な監督源。どのキャプションが表示されるかを予測するという単純な事前トレーニング タスクが有効であることを示します。
+400 のデータセットで SOTA 画像表現を最初から学習するための効率的かつスケーラブルな方法はどの画像ですか
+インターネットから収集された数百万の(画像、テキスト)ペア。事前トレーニング後、自然言語を使用して参照します。
+視覚的な概念を学習し(または新しい概念を説明し)、下流のタスクへのモデルのゼロショット転送を可能にします。私たちは勉強します
+30 を超えるさまざまな既存のコンピューター ビジョン データセットでタスクをまたがってベンチマークを行うことにより、このアプローチのパフォーマンスを評価します。
+OCR、ビデオ内のアクション認識、地理的位置特定、およびさまざまな種類のきめ細かいオブジェクト分類など。の
+モデルはほとんどのタスクに簡単に移行でき、多くの場合、必要がなくても完全に監視されたベースラインと競合します。
+データセット固有のトレーニングに適しています。たとえば、ImageNet ゼロショットではオリジナルの ResNet-50 の精度と一致します。
+トレーニングに使用された 128 万のトレーニング サンプルを使用する必要はありません。コードをリリースし、事前トレーニング済み
+モデルの重みはこの https URL で確認できます。*
+
+このモデルは [valhalla](https://huggingface.co/valhalla) によって提供されました。元のコードは [ここ](https://github.com/openai/CLIP) にあります。
+
+## Usage tips and example
+
+CLIP は、マルチモーダルなビジョンおよび言語モデルです。画像とテキストの類似性やゼロショット画像に使用できます。
+分類。 CLIP は、ViT のようなトランスフォーマーを使用して視覚的特徴を取得し、因果言語モデルを使用してテキストを取得します
+特徴。次に、テキストと視覚の両方の特徴が、同じ次元の潜在空間に投影されます。ドット
+投影された画像とテキストの特徴間の積が同様のスコアとして使用されます。
+
+画像を Transformer エンコーダに供給するために、各画像は固定サイズの重複しないパッチのシーケンスに分割されます。
+これらは線形に埋め込まれます。 [CLS] トークンは、イメージ全体の表現として機能するために追加されます。作家たち
+また、絶対位置埋め込みを追加し、結果として得られるベクトルのシーケンスを標準の Transformer エンコーダに供給します。
+[`CLIPImageProcessor`] を使用して、モデルの画像のサイズ変更 (または再スケール) および正規化を行うことができます。
+
+[`CLIPTokenizer`] はテキストのエンコードに使用されます。 [`CLIPProcessor`] はラップします
+[`CLIPImageProcessor`] と [`CLIPTokenizer`] を両方の単一インスタンスに統合
+テキストをエンコードして画像を準備します。次の例は、次のメソッドを使用して画像とテキストの類似性スコアを取得する方法を示しています。
+[`CLIPProcessor`] と [`CLIPModel`]。
+
+```python
+>>> from PIL import Image
+>>> import requests
+
+>>> from transformers import CLIPProcessor, CLIPModel
+
+>>> model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
+>>> processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
+
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
+```
+
+## Resources
+
+CLIP を使い始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- [リモート センシング (衛星) 画像とキャプションを使用した CLIP の微調整](https://huggingface.co/blog/fine-tune-clip-rsicd)、[RSICD データセット] を使用して CLIP を微調整する方法に関するブログ投稿(https://github.com/201528014227051/RSICD_optimal) と、データ拡張によるパフォーマンスの変化の比較。
+- この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/contrastive-image-text) は、プレ- [COCO データセット](https://cocodataset.org/#home) を使用してトレーニングされたビジョンおよびテキスト エンコーダー。
+
+
+
+- 画像キャプションのビーム検索による推論に事前トレーニング済み CLIP を使用する方法に関する [ノートブック](https://colab.research.google.com/drive/1tuoAC5F4sC7qid56Z0ap-stR3rwdk0ZV?usp=sharing)。 🌎
+
+**画像検索**
+
+- 事前トレーニングされた CLIP を使用した画像検索と MRR (平均相互ランク) スコアの計算に関する [ノートブック](https://colab.research.google.com/drive/1bLVwVKpAndpEDHqjzxVPr_9nGrSbuOQd?usp=sharing)。 🌎
+- 画像の取得と類似性スコアの表示に関する [ノートブック](https://colab.research.google.com/github/deep-diver/image_search_with_natural_language/blob/main/notebooks/Image_Search_CLIP.ipynb)。 🌎
+- 多言語 CLIP を使用して画像とテキストを同じベクトル空間にマッピングする方法に関する [ノートブック](https://colab.research.google.com/drive/1xO-wC_m_GNzgjIBQ4a4znvQkvDoZJvH4?usp=sharing)。 🌎
+- を使用してセマンティック イメージ検索で CLIP を実行する方法に関する [ノートブック](https://colab.research.google.com/github/vivien000/clip-demo/blob/master/clip.ipynb#scrollTo=uzdFhRGqiWkR) [Unsplash](https://unsplash.com) および [TMBD](https://www.themoviedb.org/) データセット。 🌎
+
+**説明可能性**
+
+- 入力トークンと画像セグメントの類似性を視覚化する方法に関する [ノートブック](https://colab.research.google.com/github/hila-chefer/Transformer-MM-Explainability/blob/main/CLIP_explainability.ipynb)。 🌎
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。
+リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## CLIPConfig
+
+[[autodoc]] CLIPConfig
+ - from_text_vision_configs
+
+## CLIPTextConfig
+
+[[autodoc]] CLIPTextConfig
+
+## CLIPVisionConfig
+
+[[autodoc]] CLIPVisionConfig
+
+## CLIPTokenizer
+
+[[autodoc]] CLIPTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CLIPTokenizerFast
+
+[[autodoc]] CLIPTokenizerFast
+
+## CLIPImageProcessor
+
+[[autodoc]] CLIPImageProcessor
+ - preprocess
+
+## CLIPFeatureExtractor
+
+[[autodoc]] CLIPFeatureExtractor
+
+## CLIPProcessor
+
+[[autodoc]] CLIPProcessor
+
+
+
+
+## CLIPModel
+
+[[autodoc]] CLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPTextModel
+
+[[autodoc]] CLIPTextModel
+ - forward
+
+## CLIPTextModelWithProjection
+
+[[autodoc]] CLIPTextModelWithProjection
+ - forward
+
+## CLIPVisionModelWithProjection
+
+[[autodoc]] CLIPVisionModelWithProjection
+ - forward
+
+## CLIPVisionModel
+
+[[autodoc]] CLIPVisionModel
+ - forward
+
+
+
+
+## TFCLIPModel
+
+[[autodoc]] TFCLIPModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFCLIPTextModel
+
+[[autodoc]] TFCLIPTextModel
+ - call
+
+## TFCLIPVisionModel
+
+[[autodoc]] TFCLIPVisionModel
+ - call
+
+
+
+
+## FlaxCLIPModel
+
+[[autodoc]] FlaxCLIPModel
+ - __call__
+ - get_text_features
+ - get_image_features
+
+## FlaxCLIPTextModel
+
+[[autodoc]] FlaxCLIPTextModel
+ - __call__
+
+## FlaxCLIPTextModelWithProjection
+
+[[autodoc]] FlaxCLIPTextModelWithProjection
+ - __call__
+
+## FlaxCLIPVisionModel
+
+[[autodoc]] FlaxCLIPVisionModel
+ - __call__
+
+
+
diff --git a/docs/source/ja/model_doc/clipseg.md b/docs/source/ja/model_doc/clipseg.md
new file mode 100644
index 00000000000..c8bdb0a0e47
--- /dev/null
+++ b/docs/source/ja/model_doc/clipseg.md
@@ -0,0 +1,104 @@
+
+
+# CLIPSeg
+
+## Overview
+
+CLIPSeg モデルは、Timo Lüddecke, Alexander Ecker によって [Image Segmentation using Text and Image Prompts](https://arxiv.org/abs/2112.10003) で提案されました。
+そしてアレクサンダー・エッカー。 CLIPSeg は、ゼロショットおよびワンショット画像セグメンテーションのために、凍結された [CLIP](clip) モデルの上に最小限のデコーダを追加します。
+
+論文の要約は次のとおりです。
+
+*画像のセグメンテーションは通常、トレーニングによって解決されます。
+オブジェクト クラスの固定セットのモデル。後で追加のクラスやより複雑なクエリを組み込むとコストがかかります
+これらの式を含むデータセットでモデルを再トレーニングする必要があるためです。ここでシステムを提案します
+任意の情報に基づいて画像セグメンテーションを生成できます。
+テスト時にプロンプトが表示されます。プロンプトはテキストまたは
+画像。このアプローチにより、統一されたモデルを作成できます。
+3 つの一般的なセグメンテーション タスクについて (1 回トレーニング済み)
+参照式のセグメンテーション、ゼロショット セグメンテーション、ワンショット セグメンテーションという明確な課題が伴います。
+CLIP モデルをバックボーンとして構築し、これをトランスベースのデコーダで拡張して、高密度なデータ通信を可能にします。
+予測。の拡張バージョンでトレーニングした後、
+PhraseCut データセット、私たちのシステムは、フリーテキスト プロンプトまたは
+クエリを表す追加の画像。後者の画像ベースのプロンプトのさまざまなバリエーションを詳細に分析します。
+この新しいハイブリッド入力により、動的適応が可能になります。
+前述の 3 つのセグメンテーション タスクのみですが、
+テキストまたは画像をクエリするバイナリ セグメンテーション タスクに
+定式化することができる。最後に、システムがうまく適応していることがわかりました
+アフォーダンスまたはプロパティを含む一般化されたクエリ*
+
+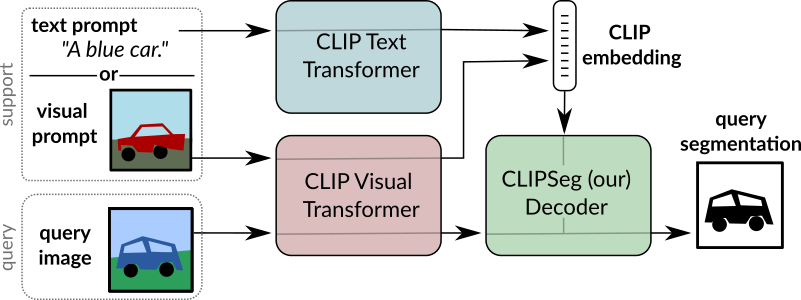 +
+ CLIPSeg の概要。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/timojl/clipseg) にあります。
+
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] は、[`CLIPSegModel`] の上にデコーダを追加します。後者は [`CLIPModel`] と同じです。
+- [`CLIPSegForImageSegmentation`] は、テスト時に任意のプロンプトに基づいて画像セグメンテーションを生成できます。プロンプトはテキストのいずれかです
+(`input_ids` としてモデルに提供される) または画像 (`conditional_pixel_values` としてモデルに提供される)。カスタムを提供することもできます
+条件付き埋め込み (`conditional_embeddings`としてモデルに提供されます)。
+
+## Resources
+
+CLIPSeg の使用を開始するのに役立つ、公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+- [CLIPSeg を使用したゼロショット画像セグメンテーション](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/CLIPSeg/Zero_shot_image_segmentation_with_CLIPSeg.ipynb) を説明するノートブック。
+
+## CLIPSegConfig
+
+[[autodoc]] CLIPSegConfig
+ - from_text_vision_configs
+
+## CLIPSegTextConfig
+
+[[autodoc]] CLIPSegTextConfig
+
+## CLIPSegVisionConfig
+
+[[autodoc]] CLIPSegVisionConfig
+
+## CLIPSegProcessor
+
+[[autodoc]] CLIPSegProcessor
+
+## CLIPSegModel
+
+[[autodoc]] CLIPSegModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPSegTextModel
+
+[[autodoc]] CLIPSegTextModel
+ - forward
+
+## CLIPSegVisionModel
+
+[[autodoc]] CLIPSegVisionModel
+ - forward
+
+## CLIPSegForImageSegmentation
+
+[[autodoc]] CLIPSegForImageSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/clvp.md b/docs/source/ja/model_doc/clvp.md
new file mode 100644
index 00000000000..0803f5e027c
--- /dev/null
+++ b/docs/source/ja/model_doc/clvp.md
@@ -0,0 +1,123 @@
+
+
+# CLVP
+
+## Overview
+
+CLVP (Contrastive Language-Voice Pretrained Transformer) モデルは、James Betker によって [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) で提案されました。
+
+論文の要約は次のとおりです。
+
+*近年、画像生成の分野は自己回帰変換器と DDPM の応用によって革命を起こしています。これらのアプローチは、画像生成のプロセスを段階的な確率的プロセスとしてモデル化し、大量のコンピューティングとデータを活用して画像の分布を学習します。パフォーマンスを向上させるこの方法論は、画像に限定される必要はありません。この論文では、画像生成ドメインの進歩を音声合成に適用する方法について説明します。その結果、表現力豊かなマルチ音声テキスト読み上げシステムである TorToise が誕生しました。
+
+
+このモデルは [Susnato Dhar](https://huggingface.co/susnato) によって提供されました。
+元のコードは [ここ](https://github.com/neonbjb/tortoise-tts) にあります。
+
+## Usage tips
+
+1. CLVP は Tortoise TTS モデルの不可欠な部分です。
+2. CLVP を使用して、生成されたさまざまな音声候補を提供されたテキストと比較することができ、最良の音声トークンが拡散モデルに転送されます。
+3. Tortoise の使用には、[`ClvpModelForConditionalGeneration.generate()`] メソッドの使用を強くお勧めします。
+4. 16 kHz を期待する他のオーディオ モデルとは対照的に、CLVP モデルはオーディオが 22.05 kHz でサンプリングされることを期待していることに注意してください。
+
+## Brief Explanation:
+
+- [`ClvpTokenizer`] はテキスト入力をトークン化し、[`ClvpFeatureExtractor`] は目的のオーディオからログ メル スペクトログラムを抽出します。
+- [`ClvpConditioningEncoder`] は、これらのテキスト トークンとオーディオ表現を取得し、テキストとオーディオに基づいて条件付けされた埋め込みに変換します。
+- [`ClvpForCausalLM`] は、これらの埋め込みを使用して複数の音声候補を生成します。
+- 各音声候補は音声エンコーダ ([`ClvpEncoder`]) を通過してベクトル表現に変換され、テキスト エンコーダ ([`ClvpEncoder`]) はテキスト トークンを同じ潜在空間に変換します。
+- 最後に、各音声ベクトルをテキスト ベクトルと比較して、どの音声ベクトルがテキスト ベクトルに最も類似しているかを確認します。
+- [`ClvpModelForConditionalGeneration.generate()`] は、上記のすべてのロジックを 1 つのメソッドに圧縮します。
+
+例 :
+
+```python
+>>> import datasets
+>>> from transformers import ClvpProcessor, ClvpModelForConditionalGeneration
+
+>>> # Define the Text and Load the Audio (We are taking an audio example from HuggingFace Hub using `datasets` library).
+>>> text = "This is an example text."
+
+>>> ds = datasets.load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> ds = ds.cast_column("audio", datasets.Audio(sampling_rate=22050))
+>>> sample = ds[0]["audio"]
+
+>>> # Define processor and model.
+>>> processor = ClvpProcessor.from_pretrained("susnato/clvp_dev")
+>>> model = ClvpModelForConditionalGeneration.from_pretrained("susnato/clvp_dev")
+
+>>> # Generate processor output and model output.
+>>> processor_output = processor(raw_speech=sample["array"], sampling_rate=sample["sampling_rate"], text=text, return_tensors="pt")
+>>> generated_output = model.generate(**processor_output)
+```
+
+
+## ClvpConfig
+
+[[autodoc]] ClvpConfig
+ - from_sub_model_configs
+
+## ClvpEncoderConfig
+
+[[autodoc]] ClvpEncoderConfig
+
+## ClvpDecoderConfig
+
+[[autodoc]] ClvpDecoderConfig
+
+## ClvpTokenizer
+
+[[autodoc]] ClvpTokenizer
+ - save_vocabulary
+
+## ClvpFeatureExtractor
+
+[[autodoc]] ClvpFeatureExtractor
+ - __call__
+
+## ClvpProcessor
+
+[[autodoc]] ClvpProcessor
+ - __call__
+ - decode
+ - batch_decode
+
+## ClvpModelForConditionalGeneration
+
+[[autodoc]] ClvpModelForConditionalGeneration
+ - forward
+ - generate
+ - get_text_features
+ - get_speech_features
+
+## ClvpForCausalLM
+
+[[autodoc]] ClvpForCausalLM
+
+## ClvpModel
+
+[[autodoc]] ClvpModel
+
+## ClvpEncoder
+
+[[autodoc]] ClvpEncoder
+
+## ClvpDecoder
+
+[[autodoc]] ClvpDecoder
+
diff --git a/docs/source/ja/model_doc/code_llama.md b/docs/source/ja/model_doc/code_llama.md
new file mode 100644
index 00000000000..4ba345b8d7b
--- /dev/null
+++ b/docs/source/ja/model_doc/code_llama.md
@@ -0,0 +1,125 @@
+
+
+# CodeLlama
+
+## Overview
+
+Code Llama モデルはによって [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) で提案されました。 Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
+論文の要約は次のとおりです。
+
+*私たちは Code Llama をリリースします。これは Llama 2 に基づくコードの大規模言語モデル ファミリであり、オープン モデルの中で最先端のパフォーマンス、埋め込み機能、大規模な入力コンテキストのサポート、プログラミング タスクのゼロショット命令追従機能を提供します。 。幅広いアプリケーションをカバーするための複数のフレーバーを提供しています。基盤モデル (Code Llama)、Python 特化 (Code Llama - Python)、およびそれぞれ 7B、13B、および 34B パラメーターを備えた命令追従モデル (Code Llama - Instruct) です。すべてのモデルは 16,000 トークンのシーケンスでトレーニングされ、最大 100,000 トークンの入力で改善が見られます。 7B および 13B コード ラマとコード ラマ - 命令バリアントは、周囲のコンテンツに基づいた埋め込みをサポートします。 Code Llama は、いくつかのコード ベンチマークでオープン モデルの中で最先端のパフォーマンスに達し、HumanEval と MBPP でそれぞれ最大 53% と 55% のスコアを獲得しました。特に、Code Llama - Python 7B は HumanEval および MBPP 上で Llama 2 70B よりも優れたパフォーマンスを示し、すべてのモデルは MultiPL-E 上で公開されている他のすべてのモデルよりも優れています。私たちは、研究と商業利用の両方を許可する寛容なライセンスに基づいて Code Llama をリリースしています。*
+
+すべての Code Llama モデル チェックポイントを [こちら](https://huggingface.co/models?search=code_llama) で確認し、[codellama org](https://huggingface.co/codellama) で正式にリリースされたチェックポイントを確認してください。
+
+このモデルは [ArthurZucker](https://huggingface.co/ArthurZ) によって提供されました。著者のオリジナルのコードは [こちら](https://github.com/facebookresearch/llama) にあります。
+
+## Usage tips and examples
+
+
+
+Code Llama のベースとなる`Llama2`ファミリー モデルは、`bfloat16`を使用してトレーニングされましたが、元の推論では`float16`を使用します。さまざまな精度を見てみましょう。
+
+* `float32`: モデルの初期化に関する PyTorch の規約では、モデルの重みがどの `dtype` で格納されたかに関係なく、モデルを `float32` にロードします。 「transformers」も、PyTorch との一貫性を保つためにこの規則に従っています。これはデフォルトで選択されます。 `AutoModel` API でストレージの重み付けタイプを使用してチェックポイントのロードをキャストする場合は、`torch_dtype="auto"` を指定する必要があります。 `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`。
+* `bfloat16`: コード Llama はこの精度でトレーニングされているため、さらなるトレーニングや微調整に使用することをお勧めします。
+* `float16`: この精度を使用して推論を実行することをお勧めします。通常は `bfloat16` より高速であり、評価メトリクスには `bfloat16` と比べて明らかな低下が見られないためです。 bfloat16 を使用して推論を実行することもできます。微調整後、float16 と bfloat16 の両方で推論結果を確認することをお勧めします。
+
+上で述べたように、モデルを初期化するときに `torch_dtype="auto"` を使用しない限り、ストレージの重みの `dtype` はほとんど無関係です。その理由は、モデルが最初にダウンロードされ (オンラインのチェックポイントの `dtype` を使用)、次に `torch` のデフォルトの `dtype` にキャストされるためです (`torch.float32` になります)。指定された `torch_dtype` がある場合は、代わりにそれが使用されます。
+
+
+
+チップ:
+- 充填タスクはすぐにサポートされます。入力を埋めたい場所には `tokenizer.fill_token` を使用する必要があります。
+- モデル変換スクリプトは、`Llama2` ファミリの場合と同じです。
+
+使用例は次のとおりです。
+
+```bash
+python src/transformers/models/llama/convert_llama_weights_to_hf.py \
+ --input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
+```
+
+スクリプトを実行するには、(最大のバージョンであっても) float16 精度でモデル全体をホストするのに十分な CPU RAM が必要であることに注意してください。
+いくつかのチェックポイントがあり、それぞれにモデルの各重みの一部が含まれているため、すべてを RAM にロードする必要があります)。
+
+変換後、モデルとトークナイザーは次の方法でロードできます。
+
+```python
+>>> from transformers import LlamaForCausalLM, CodeLlamaTokenizer
+
+>>> tokenizer = CodeLlamaTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
+>>> model = LlamaForCausalLM.from_pretrained("codellama/CodeLlama-7b-hf")
+>>> PROMPT = '''def remove_non_ascii(s: str) -> str:
+ """
+ return result
+'''
+>>> input_ids = tokenizer(PROMPT, return_tensors="pt")["input_ids"]
+>>> generated_ids = model.generate(input_ids, max_new_tokens=128)
+
+>>> filling = tokenizer.batch_decode(generated_ids[:, input_ids.shape[1]:], skip_special_tokens = True)[0]
+>>> print(PROMPT.replace("", filling))
+def remove_non_ascii(s: str) -> str:
+ """ Remove non-ASCII characters from a string.
+
+ Args:
+ s: The string to remove non-ASCII characters from.
+
+ Returns:
+ The string with non-ASCII characters removed.
+ """
+ result = ""
+ for c in s:
+ if ord(c) < 128:
+ result += c
+ return result
+```
+
+塗りつぶされた部分だけが必要な場合:
+
+```python
+>>> from transformers import pipeline
+>>> import torch
+
+>>> generator = pipeline("text-generation",model="codellama/CodeLlama-7b-hf",torch_dtype=torch.float16, device_map="auto")
+>>> generator('def remove_non_ascii(s: str) -> str:\n """ \n return result', max_new_tokens = 128, return_type = 1)
+```
+
+内部では、トークナイザーが [`` によって自動的に分割](https://huggingface.co/docs/transformers/main/model_doc/code_llama#transformers.CodeLlamaTokenizer.fill_token) して、[ に続く書式設定された入力文字列を作成します。オリジナルのトレーニング パターン](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402)。これは、パターンを自分で準備するよりも堅牢です。トークンの接着など、デバッグが非常に難しい落とし穴を回避できます。このモデルまたは他のモデルに必要な CPU および GPU メモリの量を確認するには、その値を決定するのに役立つ [この計算ツール](https://huggingface.co/spaces/hf-accelerate/model-memory-usage) を試してください。
+
+LLaMA トークナイザーは、[sentencepiece](https://github.com/google/sentencepiece) に基づく BPE モデルです。センテンスピースの癖の 1 つは、シーケンスをデコードするときに、最初のトークンが単語の先頭 (例: 「Banana」) である場合、トークナイザーは文字列の先頭にプレフィックス スペースを追加しないことです。
+
+
+
+コード Llama は、`Llama2` モデルと同じアーキテクチャを持っています。API リファレンスについては、[Llama2 のドキュメント ページ](llama2) を参照してください。
+以下の Code Llama トークナイザーのリファレンスを見つけてください。
+
+
+## CodeLlamaTokenizer
+
+[[autodoc]] CodeLlamaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CodeLlamaTokenizerFast
+
+[[autodoc]] CodeLlamaTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - update_post_processor
+ - save_vocabulary
diff --git a/docs/source/ja/model_doc/codegen.md b/docs/source/ja/model_doc/codegen.md
new file mode 100644
index 00000000000..78caefe0433
--- /dev/null
+++ b/docs/source/ja/model_doc/codegen.md
@@ -0,0 +1,90 @@
+
+
+# CodeGen
+
+## Overview
+
+
+CodeGen モデルは、[A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) で Erik Nijkamp、Bo Pang、林宏明、Lifu Tu、Huan Wang、Yingbo Zhou、Silvio Savarese、Caiming Xiong およびカイミン・ションさん。
+
+CodeGen は、[The Pile](https://pile.eleuther.ai/)、BigQuery、BigPython で順次トレーニングされたプログラム合成用の自己回帰言語モデルです。
+
+論文の要約は次のとおりです。
+
+*プログラム合成は、与えられた問題仕様の解決策としてコンピューター プログラムを生成することを目的としています。我々は、大規模な言語モデルを介した会話型プログラム合成アプローチを提案します。これは、従来のアプローチで直面した広大なプログラム空間とユーザーの意図の仕様を検索するという課題に対処します。私たちの新しいアプローチでは、仕様とプログラムを作成するプロセスを、ユーザーとシステムの間の複数回の対話として捉えます。これはプログラム合成をシーケンス予測問題として扱い、仕様が自然言語で表現され、目的のプログラムが条件付きでサンプリングされます。私たちは、自然言語とプログラミング言語のデータに基づいて、CodeGen と呼ばれる大規模な言語モデルのファミリーをトレーニングします。データの監視が弱く、データ サイズとモデル サイズが拡大すると、単純な自己回帰言語モデリングから会話能力が生まれます。会話型プログラム合成におけるモデルの動作を研究するために、マルチターン プログラミング ベンチマーク (MTPB) を開発します。このベンチマークでは、各問題を解決するには、ユーザーとモデル間のマルチターン会話を介したマルチステップ合成が必要です。私たちの調査結果は、会話機能の出現と、提案されている会話プログラム合成パラダイムの有効性を示しています。さらに、私たちのモデル CodeGen (TPU-v4 でトレーニングされた最大 16B パラメーターを含む) は、HumanEval ベンチマークで OpenAI の Codex を上回ります。私たちはチェックポイントを含むトレーニング ライブラリ JaxFormer をオープン ソースのコントリビューションとして利用できるようにしています: [この https URL](https://github.com/salesforce/codegen)*。
+
+このモデルは [林 宏明](https://huggingface.co/rooa) によって寄稿されました。
+元のコードは [ここ](https://github.com/salesforce/codegen) にあります。
+
+## Checkpoint Naming
+
+* CodeGen モデル [チェックポイント](https://huggingface.co/models?other=codegen) は、可変サイズのさまざまな事前トレーニング データで利用できます。
+* 形式は「Salesforce/codegen-{size}-{data}」です。ここで、
+ * `size`: `350M`、`2B`、`6B`、`16B`
+ * `data`:
+ * `nl`: パイルで事前トレーニング済み
+ * `multi`: `nl` で初期化され、複数のプログラミング言語データでさらに事前トレーニングされます。
+ * `mono`: `multi` で初期化され、Python データでさらに事前トレーニングされます。
+* たとえば、`Salesforce/codegen-350M-mono` は、Pile、複数のプログラミング言語、および Python で順次事前トレーニングされた 3 億 5,000 万のパラメーターのチェックポイントを提供します。
+
+## Usage example
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> checkpoint = "Salesforce/codegen-350M-mono"
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+>>> text = "def hello_world():"
+
+>>> completion = model.generate(**tokenizer(text, return_tensors="pt"))
+
+>>> print(tokenizer.decode(completion[0]))
+def hello_world():
+ print("Hello World")
+
+hello_world()
+```
+
+## Resources
+
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+
+## CodeGenConfig
+
+[[autodoc]] CodeGenConfig
+ - all
+
+## CodeGenTokenizer
+
+[[autodoc]] CodeGenTokenizer
+ - save_vocabulary
+
+## CodeGenTokenizerFast
+
+[[autodoc]] CodeGenTokenizerFast
+
+## CodeGenModel
+
+[[autodoc]] CodeGenModel
+ - forward
+
+## CodeGenForCausalLM
+
+[[autodoc]] CodeGenForCausalLM
+ - forward
diff --git a/docs/source/ja/model_doc/conditional_detr.md b/docs/source/ja/model_doc/conditional_detr.md
new file mode 100644
index 00000000000..4ef09f0b6d8
--- /dev/null
+++ b/docs/source/ja/model_doc/conditional_detr.md
@@ -0,0 +1,75 @@
+
+
+# Conditional DETR
+
+## Overview
+
+条件付き DETR モデルは、[Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) で Depu Meng、Xiaokang Chen、Zejia Fan、Gang Zeng、Houqiang Li、Yuhui Yuan、Lei Sun, Jingdong Wang によって提案されました。王京東。条件付き DETR は、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを提供します。条件付き DETR は DETR よりも 6.7 倍から 10 倍速く収束します。
+
+論文の要約は次のとおりです。
+
+*最近開発された DETR アプローチは、トランスフォーマー エンコーダーおよびデコーダー アーキテクチャを物体検出に適用し、有望なパフォーマンスを実現します。この論文では、トレーニングの収束が遅いという重要な問題を扱い、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを紹介します。私たちのアプローチは、DETR におけるクロスアテンションが 4 つの四肢の位置特定とボックスの予測にコンテンツの埋め込みに大きく依存しているため、高品質のコンテンツの埋め込みの必要性が高まり、トレーニングの難易度が高くなるという点に動機づけられています。条件付き DETR と呼ばれる私たちのアプローチは、デコーダーのマルチヘッド クロスアテンションのためにデコーダーの埋め込みから条件付きの空間クエリを学習します。利点は、条件付き空間クエリを通じて、各クロスアテンション ヘッドが、個別の領域 (たとえば、1 つのオブジェクトの端またはオブジェクト ボックス内の領域) を含むバンドに注目できることです。これにより、オブジェクト分類とボックス回帰のための個別の領域をローカライズするための空間範囲が狭まり、コンテンツの埋め込みへの依存が緩和され、トレーニングが容易になります。実験結果は、条件付き DETR がバックボーン R50 および R101 で 6.7 倍速く収束し、より強力なバックボーン DC5-R50 および DC5-R101 で 10 倍速く収束することを示しています。コードは https://github.com/Atten4Vis/ConditionalDETR で入手できます。*
+
+
+
+ CLIPSeg の概要。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/timojl/clipseg) にあります。
+
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] は、[`CLIPSegModel`] の上にデコーダを追加します。後者は [`CLIPModel`] と同じです。
+- [`CLIPSegForImageSegmentation`] は、テスト時に任意のプロンプトに基づいて画像セグメンテーションを生成できます。プロンプトはテキストのいずれかです
+(`input_ids` としてモデルに提供される) または画像 (`conditional_pixel_values` としてモデルに提供される)。カスタムを提供することもできます
+条件付き埋め込み (`conditional_embeddings`としてモデルに提供されます)。
+
+## Resources
+
+CLIPSeg の使用を開始するのに役立つ、公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+- [CLIPSeg を使用したゼロショット画像セグメンテーション](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/CLIPSeg/Zero_shot_image_segmentation_with_CLIPSeg.ipynb) を説明するノートブック。
+
+## CLIPSegConfig
+
+[[autodoc]] CLIPSegConfig
+ - from_text_vision_configs
+
+## CLIPSegTextConfig
+
+[[autodoc]] CLIPSegTextConfig
+
+## CLIPSegVisionConfig
+
+[[autodoc]] CLIPSegVisionConfig
+
+## CLIPSegProcessor
+
+[[autodoc]] CLIPSegProcessor
+
+## CLIPSegModel
+
+[[autodoc]] CLIPSegModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPSegTextModel
+
+[[autodoc]] CLIPSegTextModel
+ - forward
+
+## CLIPSegVisionModel
+
+[[autodoc]] CLIPSegVisionModel
+ - forward
+
+## CLIPSegForImageSegmentation
+
+[[autodoc]] CLIPSegForImageSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/clvp.md b/docs/source/ja/model_doc/clvp.md
new file mode 100644
index 00000000000..0803f5e027c
--- /dev/null
+++ b/docs/source/ja/model_doc/clvp.md
@@ -0,0 +1,123 @@
+
+
+# CLVP
+
+## Overview
+
+CLVP (Contrastive Language-Voice Pretrained Transformer) モデルは、James Betker によって [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) で提案されました。
+
+論文の要約は次のとおりです。
+
+*近年、画像生成の分野は自己回帰変換器と DDPM の応用によって革命を起こしています。これらのアプローチは、画像生成のプロセスを段階的な確率的プロセスとしてモデル化し、大量のコンピューティングとデータを活用して画像の分布を学習します。パフォーマンスを向上させるこの方法論は、画像に限定される必要はありません。この論文では、画像生成ドメインの進歩を音声合成に適用する方法について説明します。その結果、表現力豊かなマルチ音声テキスト読み上げシステムである TorToise が誕生しました。
+
+
+このモデルは [Susnato Dhar](https://huggingface.co/susnato) によって提供されました。
+元のコードは [ここ](https://github.com/neonbjb/tortoise-tts) にあります。
+
+## Usage tips
+
+1. CLVP は Tortoise TTS モデルの不可欠な部分です。
+2. CLVP を使用して、生成されたさまざまな音声候補を提供されたテキストと比較することができ、最良の音声トークンが拡散モデルに転送されます。
+3. Tortoise の使用には、[`ClvpModelForConditionalGeneration.generate()`] メソッドの使用を強くお勧めします。
+4. 16 kHz を期待する他のオーディオ モデルとは対照的に、CLVP モデルはオーディオが 22.05 kHz でサンプリングされることを期待していることに注意してください。
+
+## Brief Explanation:
+
+- [`ClvpTokenizer`] はテキスト入力をトークン化し、[`ClvpFeatureExtractor`] は目的のオーディオからログ メル スペクトログラムを抽出します。
+- [`ClvpConditioningEncoder`] は、これらのテキスト トークンとオーディオ表現を取得し、テキストとオーディオに基づいて条件付けされた埋め込みに変換します。
+- [`ClvpForCausalLM`] は、これらの埋め込みを使用して複数の音声候補を生成します。
+- 各音声候補は音声エンコーダ ([`ClvpEncoder`]) を通過してベクトル表現に変換され、テキスト エンコーダ ([`ClvpEncoder`]) はテキスト トークンを同じ潜在空間に変換します。
+- 最後に、各音声ベクトルをテキスト ベクトルと比較して、どの音声ベクトルがテキスト ベクトルに最も類似しているかを確認します。
+- [`ClvpModelForConditionalGeneration.generate()`] は、上記のすべてのロジックを 1 つのメソッドに圧縮します。
+
+例 :
+
+```python
+>>> import datasets
+>>> from transformers import ClvpProcessor, ClvpModelForConditionalGeneration
+
+>>> # Define the Text and Load the Audio (We are taking an audio example from HuggingFace Hub using `datasets` library).
+>>> text = "This is an example text."
+
+>>> ds = datasets.load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> ds = ds.cast_column("audio", datasets.Audio(sampling_rate=22050))
+>>> sample = ds[0]["audio"]
+
+>>> # Define processor and model.
+>>> processor = ClvpProcessor.from_pretrained("susnato/clvp_dev")
+>>> model = ClvpModelForConditionalGeneration.from_pretrained("susnato/clvp_dev")
+
+>>> # Generate processor output and model output.
+>>> processor_output = processor(raw_speech=sample["array"], sampling_rate=sample["sampling_rate"], text=text, return_tensors="pt")
+>>> generated_output = model.generate(**processor_output)
+```
+
+
+## ClvpConfig
+
+[[autodoc]] ClvpConfig
+ - from_sub_model_configs
+
+## ClvpEncoderConfig
+
+[[autodoc]] ClvpEncoderConfig
+
+## ClvpDecoderConfig
+
+[[autodoc]] ClvpDecoderConfig
+
+## ClvpTokenizer
+
+[[autodoc]] ClvpTokenizer
+ - save_vocabulary
+
+## ClvpFeatureExtractor
+
+[[autodoc]] ClvpFeatureExtractor
+ - __call__
+
+## ClvpProcessor
+
+[[autodoc]] ClvpProcessor
+ - __call__
+ - decode
+ - batch_decode
+
+## ClvpModelForConditionalGeneration
+
+[[autodoc]] ClvpModelForConditionalGeneration
+ - forward
+ - generate
+ - get_text_features
+ - get_speech_features
+
+## ClvpForCausalLM
+
+[[autodoc]] ClvpForCausalLM
+
+## ClvpModel
+
+[[autodoc]] ClvpModel
+
+## ClvpEncoder
+
+[[autodoc]] ClvpEncoder
+
+## ClvpDecoder
+
+[[autodoc]] ClvpDecoder
+
diff --git a/docs/source/ja/model_doc/code_llama.md b/docs/source/ja/model_doc/code_llama.md
new file mode 100644
index 00000000000..4ba345b8d7b
--- /dev/null
+++ b/docs/source/ja/model_doc/code_llama.md
@@ -0,0 +1,125 @@
+
+
+# CodeLlama
+
+## Overview
+
+Code Llama モデルはによって [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) で提案されました。 Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
+論文の要約は次のとおりです。
+
+*私たちは Code Llama をリリースします。これは Llama 2 に基づくコードの大規模言語モデル ファミリであり、オープン モデルの中で最先端のパフォーマンス、埋め込み機能、大規模な入力コンテキストのサポート、プログラミング タスクのゼロショット命令追従機能を提供します。 。幅広いアプリケーションをカバーするための複数のフレーバーを提供しています。基盤モデル (Code Llama)、Python 特化 (Code Llama - Python)、およびそれぞれ 7B、13B、および 34B パラメーターを備えた命令追従モデル (Code Llama - Instruct) です。すべてのモデルは 16,000 トークンのシーケンスでトレーニングされ、最大 100,000 トークンの入力で改善が見られます。 7B および 13B コード ラマとコード ラマ - 命令バリアントは、周囲のコンテンツに基づいた埋め込みをサポートします。 Code Llama は、いくつかのコード ベンチマークでオープン モデルの中で最先端のパフォーマンスに達し、HumanEval と MBPP でそれぞれ最大 53% と 55% のスコアを獲得しました。特に、Code Llama - Python 7B は HumanEval および MBPP 上で Llama 2 70B よりも優れたパフォーマンスを示し、すべてのモデルは MultiPL-E 上で公開されている他のすべてのモデルよりも優れています。私たちは、研究と商業利用の両方を許可する寛容なライセンスに基づいて Code Llama をリリースしています。*
+
+すべての Code Llama モデル チェックポイントを [こちら](https://huggingface.co/models?search=code_llama) で確認し、[codellama org](https://huggingface.co/codellama) で正式にリリースされたチェックポイントを確認してください。
+
+このモデルは [ArthurZucker](https://huggingface.co/ArthurZ) によって提供されました。著者のオリジナルのコードは [こちら](https://github.com/facebookresearch/llama) にあります。
+
+## Usage tips and examples
+
+
+
+Code Llama のベースとなる`Llama2`ファミリー モデルは、`bfloat16`を使用してトレーニングされましたが、元の推論では`float16`を使用します。さまざまな精度を見てみましょう。
+
+* `float32`: モデルの初期化に関する PyTorch の規約では、モデルの重みがどの `dtype` で格納されたかに関係なく、モデルを `float32` にロードします。 「transformers」も、PyTorch との一貫性を保つためにこの規則に従っています。これはデフォルトで選択されます。 `AutoModel` API でストレージの重み付けタイプを使用してチェックポイントのロードをキャストする場合は、`torch_dtype="auto"` を指定する必要があります。 `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`。
+* `bfloat16`: コード Llama はこの精度でトレーニングされているため、さらなるトレーニングや微調整に使用することをお勧めします。
+* `float16`: この精度を使用して推論を実行することをお勧めします。通常は `bfloat16` より高速であり、評価メトリクスには `bfloat16` と比べて明らかな低下が見られないためです。 bfloat16 を使用して推論を実行することもできます。微調整後、float16 と bfloat16 の両方で推論結果を確認することをお勧めします。
+
+上で述べたように、モデルを初期化するときに `torch_dtype="auto"` を使用しない限り、ストレージの重みの `dtype` はほとんど無関係です。その理由は、モデルが最初にダウンロードされ (オンラインのチェックポイントの `dtype` を使用)、次に `torch` のデフォルトの `dtype` にキャストされるためです (`torch.float32` になります)。指定された `torch_dtype` がある場合は、代わりにそれが使用されます。
+
+
+
+チップ:
+- 充填タスクはすぐにサポートされます。入力を埋めたい場所には `tokenizer.fill_token` を使用する必要があります。
+- モデル変換スクリプトは、`Llama2` ファミリの場合と同じです。
+
+使用例は次のとおりです。
+
+```bash
+python src/transformers/models/llama/convert_llama_weights_to_hf.py \
+ --input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
+```
+
+スクリプトを実行するには、(最大のバージョンであっても) float16 精度でモデル全体をホストするのに十分な CPU RAM が必要であることに注意してください。
+いくつかのチェックポイントがあり、それぞれにモデルの各重みの一部が含まれているため、すべてを RAM にロードする必要があります)。
+
+変換後、モデルとトークナイザーは次の方法でロードできます。
+
+```python
+>>> from transformers import LlamaForCausalLM, CodeLlamaTokenizer
+
+>>> tokenizer = CodeLlamaTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
+>>> model = LlamaForCausalLM.from_pretrained("codellama/CodeLlama-7b-hf")
+>>> PROMPT = '''def remove_non_ascii(s: str) -> str:
+ """
+ return result
+'''
+>>> input_ids = tokenizer(PROMPT, return_tensors="pt")["input_ids"]
+>>> generated_ids = model.generate(input_ids, max_new_tokens=128)
+
+>>> filling = tokenizer.batch_decode(generated_ids[:, input_ids.shape[1]:], skip_special_tokens = True)[0]
+>>> print(PROMPT.replace("", filling))
+def remove_non_ascii(s: str) -> str:
+ """ Remove non-ASCII characters from a string.
+
+ Args:
+ s: The string to remove non-ASCII characters from.
+
+ Returns:
+ The string with non-ASCII characters removed.
+ """
+ result = ""
+ for c in s:
+ if ord(c) < 128:
+ result += c
+ return result
+```
+
+塗りつぶされた部分だけが必要な場合:
+
+```python
+>>> from transformers import pipeline
+>>> import torch
+
+>>> generator = pipeline("text-generation",model="codellama/CodeLlama-7b-hf",torch_dtype=torch.float16, device_map="auto")
+>>> generator('def remove_non_ascii(s: str) -> str:\n """ \n return result', max_new_tokens = 128, return_type = 1)
+```
+
+内部では、トークナイザーが [`` によって自動的に分割](https://huggingface.co/docs/transformers/main/model_doc/code_llama#transformers.CodeLlamaTokenizer.fill_token) して、[ に続く書式設定された入力文字列を作成します。オリジナルのトレーニング パターン](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402)。これは、パターンを自分で準備するよりも堅牢です。トークンの接着など、デバッグが非常に難しい落とし穴を回避できます。このモデルまたは他のモデルに必要な CPU および GPU メモリの量を確認するには、その値を決定するのに役立つ [この計算ツール](https://huggingface.co/spaces/hf-accelerate/model-memory-usage) を試してください。
+
+LLaMA トークナイザーは、[sentencepiece](https://github.com/google/sentencepiece) に基づく BPE モデルです。センテンスピースの癖の 1 つは、シーケンスをデコードするときに、最初のトークンが単語の先頭 (例: 「Banana」) である場合、トークナイザーは文字列の先頭にプレフィックス スペースを追加しないことです。
+
+
+
+コード Llama は、`Llama2` モデルと同じアーキテクチャを持っています。API リファレンスについては、[Llama2 のドキュメント ページ](llama2) を参照してください。
+以下の Code Llama トークナイザーのリファレンスを見つけてください。
+
+
+## CodeLlamaTokenizer
+
+[[autodoc]] CodeLlamaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CodeLlamaTokenizerFast
+
+[[autodoc]] CodeLlamaTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - update_post_processor
+ - save_vocabulary
diff --git a/docs/source/ja/model_doc/codegen.md b/docs/source/ja/model_doc/codegen.md
new file mode 100644
index 00000000000..78caefe0433
--- /dev/null
+++ b/docs/source/ja/model_doc/codegen.md
@@ -0,0 +1,90 @@
+
+
+# CodeGen
+
+## Overview
+
+
+CodeGen モデルは、[A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) で Erik Nijkamp、Bo Pang、林宏明、Lifu Tu、Huan Wang、Yingbo Zhou、Silvio Savarese、Caiming Xiong およびカイミン・ションさん。
+
+CodeGen は、[The Pile](https://pile.eleuther.ai/)、BigQuery、BigPython で順次トレーニングされたプログラム合成用の自己回帰言語モデルです。
+
+論文の要約は次のとおりです。
+
+*プログラム合成は、与えられた問題仕様の解決策としてコンピューター プログラムを生成することを目的としています。我々は、大規模な言語モデルを介した会話型プログラム合成アプローチを提案します。これは、従来のアプローチで直面した広大なプログラム空間とユーザーの意図の仕様を検索するという課題に対処します。私たちの新しいアプローチでは、仕様とプログラムを作成するプロセスを、ユーザーとシステムの間の複数回の対話として捉えます。これはプログラム合成をシーケンス予測問題として扱い、仕様が自然言語で表現され、目的のプログラムが条件付きでサンプリングされます。私たちは、自然言語とプログラミング言語のデータに基づいて、CodeGen と呼ばれる大規模な言語モデルのファミリーをトレーニングします。データの監視が弱く、データ サイズとモデル サイズが拡大すると、単純な自己回帰言語モデリングから会話能力が生まれます。会話型プログラム合成におけるモデルの動作を研究するために、マルチターン プログラミング ベンチマーク (MTPB) を開発します。このベンチマークでは、各問題を解決するには、ユーザーとモデル間のマルチターン会話を介したマルチステップ合成が必要です。私たちの調査結果は、会話機能の出現と、提案されている会話プログラム合成パラダイムの有効性を示しています。さらに、私たちのモデル CodeGen (TPU-v4 でトレーニングされた最大 16B パラメーターを含む) は、HumanEval ベンチマークで OpenAI の Codex を上回ります。私たちはチェックポイントを含むトレーニング ライブラリ JaxFormer をオープン ソースのコントリビューションとして利用できるようにしています: [この https URL](https://github.com/salesforce/codegen)*。
+
+このモデルは [林 宏明](https://huggingface.co/rooa) によって寄稿されました。
+元のコードは [ここ](https://github.com/salesforce/codegen) にあります。
+
+## Checkpoint Naming
+
+* CodeGen モデル [チェックポイント](https://huggingface.co/models?other=codegen) は、可変サイズのさまざまな事前トレーニング データで利用できます。
+* 形式は「Salesforce/codegen-{size}-{data}」です。ここで、
+ * `size`: `350M`、`2B`、`6B`、`16B`
+ * `data`:
+ * `nl`: パイルで事前トレーニング済み
+ * `multi`: `nl` で初期化され、複数のプログラミング言語データでさらに事前トレーニングされます。
+ * `mono`: `multi` で初期化され、Python データでさらに事前トレーニングされます。
+* たとえば、`Salesforce/codegen-350M-mono` は、Pile、複数のプログラミング言語、および Python で順次事前トレーニングされた 3 億 5,000 万のパラメーターのチェックポイントを提供します。
+
+## Usage example
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> checkpoint = "Salesforce/codegen-350M-mono"
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+>>> text = "def hello_world():"
+
+>>> completion = model.generate(**tokenizer(text, return_tensors="pt"))
+
+>>> print(tokenizer.decode(completion[0]))
+def hello_world():
+ print("Hello World")
+
+hello_world()
+```
+
+## Resources
+
+- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
+
+## CodeGenConfig
+
+[[autodoc]] CodeGenConfig
+ - all
+
+## CodeGenTokenizer
+
+[[autodoc]] CodeGenTokenizer
+ - save_vocabulary
+
+## CodeGenTokenizerFast
+
+[[autodoc]] CodeGenTokenizerFast
+
+## CodeGenModel
+
+[[autodoc]] CodeGenModel
+ - forward
+
+## CodeGenForCausalLM
+
+[[autodoc]] CodeGenForCausalLM
+ - forward
diff --git a/docs/source/ja/model_doc/conditional_detr.md b/docs/source/ja/model_doc/conditional_detr.md
new file mode 100644
index 00000000000..4ef09f0b6d8
--- /dev/null
+++ b/docs/source/ja/model_doc/conditional_detr.md
@@ -0,0 +1,75 @@
+
+
+# Conditional DETR
+
+## Overview
+
+条件付き DETR モデルは、[Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) で Depu Meng、Xiaokang Chen、Zejia Fan、Gang Zeng、Houqiang Li、Yuhui Yuan、Lei Sun, Jingdong Wang によって提案されました。王京東。条件付き DETR は、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを提供します。条件付き DETR は DETR よりも 6.7 倍から 10 倍速く収束します。
+
+論文の要約は次のとおりです。
+
+*最近開発された DETR アプローチは、トランスフォーマー エンコーダーおよびデコーダー アーキテクチャを物体検出に適用し、有望なパフォーマンスを実現します。この論文では、トレーニングの収束が遅いという重要な問題を扱い、高速 DETR トレーニングのための条件付きクロスアテンション メカニズムを紹介します。私たちのアプローチは、DETR におけるクロスアテンションが 4 つの四肢の位置特定とボックスの予測にコンテンツの埋め込みに大きく依存しているため、高品質のコンテンツの埋め込みの必要性が高まり、トレーニングの難易度が高くなるという点に動機づけられています。条件付き DETR と呼ばれる私たちのアプローチは、デコーダーのマルチヘッド クロスアテンションのためにデコーダーの埋め込みから条件付きの空間クエリを学習します。利点は、条件付き空間クエリを通じて、各クロスアテンション ヘッドが、個別の領域 (たとえば、1 つのオブジェクトの端またはオブジェクト ボックス内の領域) を含むバンドに注目できることです。これにより、オブジェクト分類とボックス回帰のための個別の領域をローカライズするための空間範囲が狭まり、コンテンツの埋め込みへの依存が緩和され、トレーニングが容易になります。実験結果は、条件付き DETR がバックボーン R50 および R101 で 6.7 倍速く収束し、より強力なバックボーン DC5-R50 および DC5-R101 で 10 倍速く収束することを示しています。コードは https://github.com/Atten4Vis/ConditionalDETR で入手できます。*
+
+ +
+ 条件付き DETR は、元の DETR に比べてはるかに速い収束を示します。 元の論文から引用。
+
+このモデルは [DepuMeng](https://huggingface.co/DepuMeng) によって寄稿されました。元のコードは [ここ](https://github.com/Atten4Vis/ConditionalDETR) にあります。
+
+## Resources
+
+- [オブジェクト検出タスクガイド](../tasks/object_detection)
+
+## ConditionalDetrConfig
+
+[[autodoc]] ConditionalDetrConfig
+
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+ - preprocess
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrFeatureExtractor
+
+[[autodoc]] ConditionalDetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrModel
+
+[[autodoc]] ConditionalDetrModel
+ - forward
+
+## ConditionalDetrForObjectDetection
+
+[[autodoc]] ConditionalDetrForObjectDetection
+ - forward
+
+## ConditionalDetrForSegmentation
+
+[[autodoc]] ConditionalDetrForSegmentation
+ - forward
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/convbert.md b/docs/source/ja/model_doc/convbert.md
new file mode 100644
index 00000000000..5d15f86c513
--- /dev/null
+++ b/docs/source/ja/model_doc/convbert.md
@@ -0,0 +1,145 @@
+
+
+# ConvBERT
+
+
+
+## Overview
+
+ConvBERT モデルは、[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) で Zihang Jiang、Weihao Yu、Daquan Zhou、Yunpeng Chen、Jiashi Feng、Shuicheng Yan によって提案されました。
+やん。
+
+論文の要約は次のとおりです。
+
+*BERT やそのバリアントなどの事前トレーニング済み言語モデルは、最近、さまざまな環境で目覚ましいパフォーマンスを達成しています。
+自然言語理解タスク。ただし、BERT はグローバルな自己注意ブロックに大きく依存しているため、問題が発生します。
+メモリ使用量と計算コストが大きくなります。すべての注意が入力シーケンス全体に対してクエリを実行しますが、
+グローバルな観点からアテンション マップを生成すると、一部のヘッドはローカルな依存関係のみを学習する必要があることがわかります。
+これは、計算の冗長性が存在することを意味します。したがって、我々は、新しいスパンベースの動的畳み込みを提案します。
+これらのセルフアテンション ヘッドを置き換えて、ローカルの依存関係を直接モデル化します。新しいコンボリューションヘッドと、
+自己注意の頭を休め、グローバルとローカルの両方の状況でより効率的な新しい混合注意ブロックを形成します
+学ぶ。この混合注意設計を BERT に装備し、ConvBERT モデルを構築します。実験でわかったことは、
+ConvBERT は、トレーニング コストが低く、さまざまな下流タスクにおいて BERT およびその亜種よりも大幅に優れたパフォーマンスを発揮します。
+モデルパラメータが少なくなります。注目すべきことに、ConvBERTbase モデルは 86.4 GLUE スコアを達成し、ELECTRAbase よりも 0.7 高いのに対し、
+トレーニングコストは 1/4 未満です。コードと事前トレーニングされたモデルがリリースされます。*
+
+このモデルは、[abhishek](https://huggingface.co/abhishek) によって提供されました。オリジナルの実装が見つかります
+ここ: https://github.com/yitu-opensource/ConvBert
+
+## Usage tips
+
+ConvBERT トレーニングのヒントは BERT のヒントと似ています。使用上のヒントについては、[BERT ドキュメント](bert) を参照してください。
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## ConvBertConfig
+
+[[autodoc]] ConvBertConfig
+
+## ConvBertTokenizer
+
+[[autodoc]] ConvBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## ConvBertTokenizerFast
+
+[[autodoc]] ConvBertTokenizerFast
+
+
+
+
+## ConvBertModel
+
+[[autodoc]] ConvBertModel
+ - forward
+
+## ConvBertForMaskedLM
+
+[[autodoc]] ConvBertForMaskedLM
+ - forward
+
+## ConvBertForSequenceClassification
+
+[[autodoc]] ConvBertForSequenceClassification
+ - forward
+
+## ConvBertForMultipleChoice
+
+[[autodoc]] ConvBertForMultipleChoice
+ - forward
+
+## ConvBertForTokenClassification
+
+[[autodoc]] ConvBertForTokenClassification
+ - forward
+
+## ConvBertForQuestionAnswering
+
+[[autodoc]] ConvBertForQuestionAnswering
+ - forward
+
+
+
+
+## TFConvBertModel
+
+[[autodoc]] TFConvBertModel
+ - call
+
+## TFConvBertForMaskedLM
+
+[[autodoc]] TFConvBertForMaskedLM
+ - call
+
+## TFConvBertForSequenceClassification
+
+[[autodoc]] TFConvBertForSequenceClassification
+ - call
+
+## TFConvBertForMultipleChoice
+
+[[autodoc]] TFConvBertForMultipleChoice
+ - call
+
+## TFConvBertForTokenClassification
+
+[[autodoc]] TFConvBertForTokenClassification
+ - call
+
+## TFConvBertForQuestionAnswering
+
+[[autodoc]] TFConvBertForQuestionAnswering
+ - call
+
+
+
diff --git a/docs/source/ja/model_doc/convnext.md b/docs/source/ja/model_doc/convnext.md
new file mode 100644
index 00000000000..4386a7df8ce
--- /dev/null
+++ b/docs/source/ja/model_doc/convnext.md
@@ -0,0 +1,94 @@
+
+
+# ConvNeXT
+
+## Overview
+
+ConvNeXT モデルは、[A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) で Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell、Saining Xie によって提案されました。
+ConvNeXT は、ビジョン トランスフォーマーの設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、ビジョン トランスフォーマーよりも優れたパフォーマンスを発揮すると主張しています。
+
+論文の要約は次のとおりです。
+
+*視覚認識の「狂騒の 20 年代」は、最先端の画像分類モデルとして ConvNet にすぐに取って代わられた Vision Transformers (ViT) の導入から始まりました。
+一方、バニラ ViT は、オブジェクト検出やセマンティック セグメンテーションなどの一般的なコンピューター ビジョン タスクに適用すると困難に直面します。階層型トランスフォーマーです
+(Swin Transformers など) は、いくつかの ConvNet の以前の機能を再導入し、Transformers を汎用ビジョン バックボーンとして実用的に可能にし、幅広い環境で顕著なパフォーマンスを実証しました。
+さまざまな視覚タスク。ただし、このようなハイブリッド アプローチの有効性は、依然として、固有の誘導性ではなく、トランスフォーマーの本質的な優位性によるところが大きいと考えられています。
+畳み込みのバイアス。この作業では、設計空間を再検討し、純粋な ConvNet が達成できる限界をテストします。標準 ResNet を設計に向けて徐々に「最新化」します。
+ビジョン Transformer の概要を確認し、途中でパフォーマンスの違いに寄与するいくつかの重要なコンポーネントを発見します。この調査の結果は、純粋な ConvNet モデルのファミリーです。
+ConvNextと呼ばれます。 ConvNeXts は完全に標準の ConvNet モジュールから構築されており、精度と拡張性の点で Transformers と有利に競合し、87.8% の ImageNet トップ 1 精度を達成しています。
+標準 ConvNet のシンプルさと効率を維持しながら、COCO 検出と ADE20K セグメンテーションでは Swin Transformers よりも優れたパフォーマンスを発揮します。*
+
+
+
+ 条件付き DETR は、元の DETR に比べてはるかに速い収束を示します。 元の論文から引用。
+
+このモデルは [DepuMeng](https://huggingface.co/DepuMeng) によって寄稿されました。元のコードは [ここ](https://github.com/Atten4Vis/ConditionalDETR) にあります。
+
+## Resources
+
+- [オブジェクト検出タスクガイド](../tasks/object_detection)
+
+## ConditionalDetrConfig
+
+[[autodoc]] ConditionalDetrConfig
+
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+ - preprocess
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrFeatureExtractor
+
+[[autodoc]] ConditionalDetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrModel
+
+[[autodoc]] ConditionalDetrModel
+ - forward
+
+## ConditionalDetrForObjectDetection
+
+[[autodoc]] ConditionalDetrForObjectDetection
+ - forward
+
+## ConditionalDetrForSegmentation
+
+[[autodoc]] ConditionalDetrForSegmentation
+ - forward
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/convbert.md b/docs/source/ja/model_doc/convbert.md
new file mode 100644
index 00000000000..5d15f86c513
--- /dev/null
+++ b/docs/source/ja/model_doc/convbert.md
@@ -0,0 +1,145 @@
+
+
+# ConvBERT
+
+
+
+## Overview
+
+ConvBERT モデルは、[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) で Zihang Jiang、Weihao Yu、Daquan Zhou、Yunpeng Chen、Jiashi Feng、Shuicheng Yan によって提案されました。
+やん。
+
+論文の要約は次のとおりです。
+
+*BERT やそのバリアントなどの事前トレーニング済み言語モデルは、最近、さまざまな環境で目覚ましいパフォーマンスを達成しています。
+自然言語理解タスク。ただし、BERT はグローバルな自己注意ブロックに大きく依存しているため、問題が発生します。
+メモリ使用量と計算コストが大きくなります。すべての注意が入力シーケンス全体に対してクエリを実行しますが、
+グローバルな観点からアテンション マップを生成すると、一部のヘッドはローカルな依存関係のみを学習する必要があることがわかります。
+これは、計算の冗長性が存在することを意味します。したがって、我々は、新しいスパンベースの動的畳み込みを提案します。
+これらのセルフアテンション ヘッドを置き換えて、ローカルの依存関係を直接モデル化します。新しいコンボリューションヘッドと、
+自己注意の頭を休め、グローバルとローカルの両方の状況でより効率的な新しい混合注意ブロックを形成します
+学ぶ。この混合注意設計を BERT に装備し、ConvBERT モデルを構築します。実験でわかったことは、
+ConvBERT は、トレーニング コストが低く、さまざまな下流タスクにおいて BERT およびその亜種よりも大幅に優れたパフォーマンスを発揮します。
+モデルパラメータが少なくなります。注目すべきことに、ConvBERTbase モデルは 86.4 GLUE スコアを達成し、ELECTRAbase よりも 0.7 高いのに対し、
+トレーニングコストは 1/4 未満です。コードと事前トレーニングされたモデルがリリースされます。*
+
+このモデルは、[abhishek](https://huggingface.co/abhishek) によって提供されました。オリジナルの実装が見つかります
+ここ: https://github.com/yitu-opensource/ConvBert
+
+## Usage tips
+
+ConvBERT トレーニングのヒントは BERT のヒントと似ています。使用上のヒントについては、[BERT ドキュメント](bert) を参照してください。
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## ConvBertConfig
+
+[[autodoc]] ConvBertConfig
+
+## ConvBertTokenizer
+
+[[autodoc]] ConvBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## ConvBertTokenizerFast
+
+[[autodoc]] ConvBertTokenizerFast
+
+
+
+
+## ConvBertModel
+
+[[autodoc]] ConvBertModel
+ - forward
+
+## ConvBertForMaskedLM
+
+[[autodoc]] ConvBertForMaskedLM
+ - forward
+
+## ConvBertForSequenceClassification
+
+[[autodoc]] ConvBertForSequenceClassification
+ - forward
+
+## ConvBertForMultipleChoice
+
+[[autodoc]] ConvBertForMultipleChoice
+ - forward
+
+## ConvBertForTokenClassification
+
+[[autodoc]] ConvBertForTokenClassification
+ - forward
+
+## ConvBertForQuestionAnswering
+
+[[autodoc]] ConvBertForQuestionAnswering
+ - forward
+
+
+
+
+## TFConvBertModel
+
+[[autodoc]] TFConvBertModel
+ - call
+
+## TFConvBertForMaskedLM
+
+[[autodoc]] TFConvBertForMaskedLM
+ - call
+
+## TFConvBertForSequenceClassification
+
+[[autodoc]] TFConvBertForSequenceClassification
+ - call
+
+## TFConvBertForMultipleChoice
+
+[[autodoc]] TFConvBertForMultipleChoice
+ - call
+
+## TFConvBertForTokenClassification
+
+[[autodoc]] TFConvBertForTokenClassification
+ - call
+
+## TFConvBertForQuestionAnswering
+
+[[autodoc]] TFConvBertForQuestionAnswering
+ - call
+
+
+
diff --git a/docs/source/ja/model_doc/convnext.md b/docs/source/ja/model_doc/convnext.md
new file mode 100644
index 00000000000..4386a7df8ce
--- /dev/null
+++ b/docs/source/ja/model_doc/convnext.md
@@ -0,0 +1,94 @@
+
+
+# ConvNeXT
+
+## Overview
+
+ConvNeXT モデルは、[A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) で Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell、Saining Xie によって提案されました。
+ConvNeXT は、ビジョン トランスフォーマーの設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、ビジョン トランスフォーマーよりも優れたパフォーマンスを発揮すると主張しています。
+
+論文の要約は次のとおりです。
+
+*視覚認識の「狂騒の 20 年代」は、最先端の画像分類モデルとして ConvNet にすぐに取って代わられた Vision Transformers (ViT) の導入から始まりました。
+一方、バニラ ViT は、オブジェクト検出やセマンティック セグメンテーションなどの一般的なコンピューター ビジョン タスクに適用すると困難に直面します。階層型トランスフォーマーです
+(Swin Transformers など) は、いくつかの ConvNet の以前の機能を再導入し、Transformers を汎用ビジョン バックボーンとして実用的に可能にし、幅広い環境で顕著なパフォーマンスを実証しました。
+さまざまな視覚タスク。ただし、このようなハイブリッド アプローチの有効性は、依然として、固有の誘導性ではなく、トランスフォーマーの本質的な優位性によるところが大きいと考えられています。
+畳み込みのバイアス。この作業では、設計空間を再検討し、純粋な ConvNet が達成できる限界をテストします。標準 ResNet を設計に向けて徐々に「最新化」します。
+ビジョン Transformer の概要を確認し、途中でパフォーマンスの違いに寄与するいくつかの重要なコンポーネントを発見します。この調査の結果は、純粋な ConvNet モデルのファミリーです。
+ConvNextと呼ばれます。 ConvNeXts は完全に標準の ConvNet モジュールから構築されており、精度と拡張性の点で Transformers と有利に競合し、87.8% の ImageNet トップ 1 精度を達成しています。
+標準 ConvNet のシンプルさと効率を維持しながら、COCO 検出と ADE20K セグメンテーションでは Swin Transformers よりも優れたパフォーマンスを発揮します。*
+
+ +
+ ConvNeXT アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。 TensorFlow バージョンのモデルは [ariG23498](https://github.com/ariG23498) によって提供されました。
+[gante](https://github.com/gante)、および [sayakpaul](https://github.com/sayakpaul) (同等の貢献)。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt) にあります。
+
+## Resources
+
+ConvNeXT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+
+
+- [`ConvNextForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+- 参照: [画像分類タスク ガイド](../tasks/image_classification)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## ConvNextConfig
+
+[[autodoc]] ConvNextConfig
+
+## ConvNextFeatureExtractor
+
+[[autodoc]] ConvNextFeatureExtractor
+
+## ConvNextImageProcessor
+
+[[autodoc]] ConvNextImageProcessor
+ - preprocess
+
+
+
+
+## ConvNextModel
+
+[[autodoc]] ConvNextModel
+ - forward
+
+## ConvNextForImageClassification
+
+[[autodoc]] ConvNextForImageClassification
+ - forward
+
+
+
+
+## TFConvNextModel
+
+[[autodoc]] TFConvNextModel
+ - call
+
+## TFConvNextForImageClassification
+
+[[autodoc]] TFConvNextForImageClassification
+ - call
+
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/convnextv2.md b/docs/source/ja/model_doc/convnextv2.md
new file mode 100644
index 00000000000..9e4d54df24b
--- /dev/null
+++ b/docs/source/ja/model_doc/convnextv2.md
@@ -0,0 +1,68 @@
+
+
+# ConvNeXt V2
+
+## Overview
+
+ConvNeXt V2 モデルは、Sanghyun Woo、Shobhik Debnath、Ronghang Hu、Xinlei Chen、Zhuang Liu, In So Kweon, Saining Xie. によって [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) で提案されました。
+ConvNeXt V2 は、Vision Transformers の設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、[ConvNeXT](convnext) の後継です。
+
+論文の要約は次のとおりです。
+
+*アーキテクチャの改善と表現学習フレームワークの改善により、視覚認識の分野は 2020 年代初頭に急速な近代化とパフォーマンスの向上を実現しました。たとえば、ConvNeXt に代表される最新の ConvNet は、さまざまなシナリオで強力なパフォーマンスを実証しています。これらのモデルはもともと ImageNet ラベルを使用した教師あり学習用に設計されましたが、マスク オートエンコーダー (MAE) などの自己教師あり学習手法からも潜在的に恩恵を受けることができます。ただし、これら 2 つのアプローチを単純に組み合わせると、パフォーマンスが標準以下になることがわかりました。この論文では、完全畳み込みマスク オートエンコーダ フレームワークと、チャネル間の機能競合を強化するために ConvNeXt アーキテクチャに追加できる新しい Global Response Normalization (GRN) 層を提案します。この自己教師あり学習手法とアーキテクチャの改善の共同設計により、ConvNeXt V2 と呼ばれる新しいモデル ファミリが誕生しました。これにより、ImageNet 分類、COCO 検出、ADE20K セグメンテーションなどのさまざまな認識ベンチマークにおける純粋な ConvNet のパフォーマンスが大幅に向上します。また、ImageNet でトップ 1 の精度 76.7% を誇る効率的な 370 万パラメータの Atto モデルから、最先端の 88.9% を達成する 650M Huge モデルまで、さまざまなサイズの事前トレーニング済み ConvNeXt V2 モデルも提供しています。公開トレーニング データのみを使用した精度*。
+
+
+
+ ConvNeXT アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。 TensorFlow バージョンのモデルは [ariG23498](https://github.com/ariG23498) によって提供されました。
+[gante](https://github.com/gante)、および [sayakpaul](https://github.com/sayakpaul) (同等の貢献)。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt) にあります。
+
+## Resources
+
+ConvNeXT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+
+
+- [`ConvNextForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+- 参照: [画像分類タスク ガイド](../tasks/image_classification)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## ConvNextConfig
+
+[[autodoc]] ConvNextConfig
+
+## ConvNextFeatureExtractor
+
+[[autodoc]] ConvNextFeatureExtractor
+
+## ConvNextImageProcessor
+
+[[autodoc]] ConvNextImageProcessor
+ - preprocess
+
+
+
+
+## ConvNextModel
+
+[[autodoc]] ConvNextModel
+ - forward
+
+## ConvNextForImageClassification
+
+[[autodoc]] ConvNextForImageClassification
+ - forward
+
+
+
+
+## TFConvNextModel
+
+[[autodoc]] TFConvNextModel
+ - call
+
+## TFConvNextForImageClassification
+
+[[autodoc]] TFConvNextForImageClassification
+ - call
+
+
+
\ No newline at end of file
diff --git a/docs/source/ja/model_doc/convnextv2.md b/docs/source/ja/model_doc/convnextv2.md
new file mode 100644
index 00000000000..9e4d54df24b
--- /dev/null
+++ b/docs/source/ja/model_doc/convnextv2.md
@@ -0,0 +1,68 @@
+
+
+# ConvNeXt V2
+
+## Overview
+
+ConvNeXt V2 モデルは、Sanghyun Woo、Shobhik Debnath、Ronghang Hu、Xinlei Chen、Zhuang Liu, In So Kweon, Saining Xie. によって [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) で提案されました。
+ConvNeXt V2 は、Vision Transformers の設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、[ConvNeXT](convnext) の後継です。
+
+論文の要約は次のとおりです。
+
+*アーキテクチャの改善と表現学習フレームワークの改善により、視覚認識の分野は 2020 年代初頭に急速な近代化とパフォーマンスの向上を実現しました。たとえば、ConvNeXt に代表される最新の ConvNet は、さまざまなシナリオで強力なパフォーマンスを実証しています。これらのモデルはもともと ImageNet ラベルを使用した教師あり学習用に設計されましたが、マスク オートエンコーダー (MAE) などの自己教師あり学習手法からも潜在的に恩恵を受けることができます。ただし、これら 2 つのアプローチを単純に組み合わせると、パフォーマンスが標準以下になることがわかりました。この論文では、完全畳み込みマスク オートエンコーダ フレームワークと、チャネル間の機能競合を強化するために ConvNeXt アーキテクチャに追加できる新しい Global Response Normalization (GRN) 層を提案します。この自己教師あり学習手法とアーキテクチャの改善の共同設計により、ConvNeXt V2 と呼ばれる新しいモデル ファミリが誕生しました。これにより、ImageNet 分類、COCO 検出、ADE20K セグメンテーションなどのさまざまな認識ベンチマークにおける純粋な ConvNet のパフォーマンスが大幅に向上します。また、ImageNet でトップ 1 の精度 76.7% を誇る効率的な 370 万パラメータの Atto モデルから、最先端の 88.9% を達成する 650M Huge モデルまで、さまざまなサイズの事前トレーニング済み ConvNeXt V2 モデルも提供しています。公開トレーニング データのみを使用した精度*。
+
+ +
+ ConvNeXt V2 アーキテクチャ。 元の論文から抜粋。
+
+このモデルは [adirik](https://huggingface.co/adirik) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt-V2) にあります。
+
+## Resources
+
+ConvNeXt V2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+
+
+- [`ConvNextV2ForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## ConvNextV2Config
+
+[[autodoc]] ConvNextV2Config
+
+## ConvNextV2Model
+
+[[autodoc]] ConvNextV2Model
+ - forward
+
+## ConvNextV2ForImageClassification
+
+[[autodoc]] ConvNextV2ForImageClassification
+ - forward
+
+## TFConvNextV2Model
+
+[[autodoc]] TFConvNextV2Model
+ - call
+
+
+## TFConvNextV2ForImageClassification
+
+[[autodoc]] TFConvNextV2ForImageClassification
+ - call
diff --git a/docs/source/ja/model_doc/cpm.md b/docs/source/ja/model_doc/cpm.md
new file mode 100644
index 00000000000..9776f676844
--- /dev/null
+++ b/docs/source/ja/model_doc/cpm.md
@@ -0,0 +1,54 @@
+
+
+# CPM
+
+## Overview
+
+CPM モデルは、Zhengyan Zhang、Xu Han、Hao Zhou、Pei Ke、Yuxian Gu によって [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) で提案されました。葉徳明、秦裕佳、
+Yusheng Su、Haozhe Ji、Jian Guan、Fanchao Qi、Xiaozi Wang、Yanan Zheng、Guoyang Zeng、Huanqi Cao、Shengqi Chen、
+Daixuan Li、Zhenbo Sun、Zhiyuan Liu、Minlie Huang、Wentao Han、Jie Tang、Juanzi Li、Xiaoyan Zhu、Maosong Sun。
+
+論文の要約は次のとおりです。
+
+*事前トレーニングされた言語モデル (PLM) は、さまざまな下流の NLP タスクに有益であることが証明されています。最近ではGPT-3、
+1,750億個のパラメータと570GBの学習データを備え、数回の撮影(1枚でも)の容量で大きな注目を集めました
+ゼロショット)学習。ただし、GPT-3 を適用して中国語の NLP タスクに対処することは依然として困難です。
+GPT-3 の言語は主に英語であり、パラメーターは公開されていません。この技術レポートでは、
+大規模な中国語トレーニング データに対する生成的事前トレーニングを備えた中国語事前トレーニング済み言語モデル (CPM)。最高に
+私たちの知識の限りでは、26 億のパラメータと 100GB の中国語トレーニング データを備えた CPM は、事前トレーニングされた中国語としては最大のものです。
+言語モデルは、会話、エッセイの作成、
+クローゼテストと言語理解。広範な実験により、CPM が多くの環境で優れたパフォーマンスを達成できることが実証されています。
+少数ショット (ゼロショットでも) 学習の設定での NLP タスク。*
+
+このモデルは [canwenxu](https://huggingface.co/canwenxu) によって提供されました。オリジナルの実装が見つかります
+ここ: https://github.com/TsinghuaAI/CPM-Generate
+
+
+
+
+CPM のアーキテクチャは、トークン化方法を除いて GPT-2 と同じです。詳細については、[GPT-2 ドキュメント](gpt2) を参照してください。
+API リファレンス情報。
+
+
+
+## CpmTokenizer
+
+[[autodoc]] CpmTokenizer
+
+## CpmTokenizerFast
+
+[[autodoc]] CpmTokenizerFast
+
+ ConvNeXt V2 アーキテクチャ。 元の論文から抜粋。
+
+このモデルは [adirik](https://huggingface.co/adirik) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt-V2) にあります。
+
+## Resources
+
+ConvNeXt V2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+
+
+- [`ConvNextV2ForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## ConvNextV2Config
+
+[[autodoc]] ConvNextV2Config
+
+## ConvNextV2Model
+
+[[autodoc]] ConvNextV2Model
+ - forward
+
+## ConvNextV2ForImageClassification
+
+[[autodoc]] ConvNextV2ForImageClassification
+ - forward
+
+## TFConvNextV2Model
+
+[[autodoc]] TFConvNextV2Model
+ - call
+
+
+## TFConvNextV2ForImageClassification
+
+[[autodoc]] TFConvNextV2ForImageClassification
+ - call
diff --git a/docs/source/ja/model_doc/cpm.md b/docs/source/ja/model_doc/cpm.md
new file mode 100644
index 00000000000..9776f676844
--- /dev/null
+++ b/docs/source/ja/model_doc/cpm.md
@@ -0,0 +1,54 @@
+
+
+# CPM
+
+## Overview
+
+CPM モデルは、Zhengyan Zhang、Xu Han、Hao Zhou、Pei Ke、Yuxian Gu によって [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) で提案されました。葉徳明、秦裕佳、
+Yusheng Su、Haozhe Ji、Jian Guan、Fanchao Qi、Xiaozi Wang、Yanan Zheng、Guoyang Zeng、Huanqi Cao、Shengqi Chen、
+Daixuan Li、Zhenbo Sun、Zhiyuan Liu、Minlie Huang、Wentao Han、Jie Tang、Juanzi Li、Xiaoyan Zhu、Maosong Sun。
+
+論文の要約は次のとおりです。
+
+*事前トレーニングされた言語モデル (PLM) は、さまざまな下流の NLP タスクに有益であることが証明されています。最近ではGPT-3、
+1,750億個のパラメータと570GBの学習データを備え、数回の撮影(1枚でも)の容量で大きな注目を集めました
+ゼロショット)学習。ただし、GPT-3 を適用して中国語の NLP タスクに対処することは依然として困難です。
+GPT-3 の言語は主に英語であり、パラメーターは公開されていません。この技術レポートでは、
+大規模な中国語トレーニング データに対する生成的事前トレーニングを備えた中国語事前トレーニング済み言語モデル (CPM)。最高に
+私たちの知識の限りでは、26 億のパラメータと 100GB の中国語トレーニング データを備えた CPM は、事前トレーニングされた中国語としては最大のものです。
+言語モデルは、会話、エッセイの作成、
+クローゼテストと言語理解。広範な実験により、CPM が多くの環境で優れたパフォーマンスを達成できることが実証されています。
+少数ショット (ゼロショットでも) 学習の設定での NLP タスク。*
+
+このモデルは [canwenxu](https://huggingface.co/canwenxu) によって提供されました。オリジナルの実装が見つかります
+ここ: https://github.com/TsinghuaAI/CPM-Generate
+
+
+
+
+CPM のアーキテクチャは、トークン化方法を除いて GPT-2 と同じです。詳細については、[GPT-2 ドキュメント](gpt2) を参照してください。
+API リファレンス情報。
+
+
+
+## CpmTokenizer
+
+[[autodoc]] CpmTokenizer
+
+## CpmTokenizerFast
+
+[[autodoc]] CpmTokenizerFast