Get into a rut early: Do the same processes the same way. Accumulate idioms. Standardize. The only difference (!) between Shakespeare and you was the size of his idiom list - not the size of his vocabulary. 1
[TOC]
到目前为止,我们所见的变量都只是标量(scalar):标量具有保存单一数据项的能力。
C 语言也支持聚合(aggregate)变量,这类变量可以存储一组数值。C 语言一共有两种聚合类型:数组(array)和 结构(structure)。
其中,数组是本节的主角。它只能存储相同类型的变量集合。
数组是含有多个数据值的数据结构,并且每个数据具有相同的数据类型。这些数据值称为元素(element)。
最简单的数组是一维数组。一维数组中的每个元素一个接一个的排列。
为了声明数组,需要指明数组元素的类型和数量。
int a[10];// 一个含有 10 个 int 类型变量的数组数组的元素可以是任意类型,数组的长度可以是任何**(整数)常量表达式**指定。
#define N 10
int a[N];但是不能使用变量(C89)
n = 10;
int a[n];尽管 C99 已经允许这种做法,但是,很多编译器并不完全支持 C99 。
对数组取下标(subscripting)或进行索引(indexing):为了取特定的数组元素,可以在写数组名的同时在后面加上一个用方括号围绕的整数值。
数组元素始终从 0 开始,所以长度为 n 的数组元素的索引时 0 ~ n - 1
例如,a 是含有 10 个元素的数组:
a[i]是左值,所以数组元素可以像不同变量一样使用:
a[0] = 1;
printf("%d\n", a[5]);
++a[i];许多程序包含的 for 循环都是为了对数组的每个元素执行一些操作。下面给出了长度为 N 的数组 a 的一些常见操作。
for(i = 0; i < N; i++){
a[i] = 0; // clears a
}
for(i = 0; i < N; i++){
scanf("%d", &a[i]); // reads data into a
}
for(i = 0; i < N; i++){
sum += a[i]; // sums the elements of a
}注意:在调用 scanf 函数读取数组元素时,就像对待普通变量一样,必须使用取地址符号 &
C 语言不要求检查下标的范围。当下标超出范围时,程序可能执行不可预知的行为。
数组下标可以是任何整数表达式:
a[i + j*10] = 0;
下标可以自增自减:
i = 0;
while(i < N)
printf("%d\n", a[i++]);i = 0 时进入循环,打印 a[0] 后 i 的值增加 1 ,这样不断重复;当 i = N - 1 时,打印 a[N - 1] 然后 i 的值加 1 变为 N 不满足 控制表达式 退出循环。
这类问题可以使用 VS 进行调试,从而判断数组下标的变化情况,如果你不会调试可以留言告诉我,不会的人多的话,我可以出一期教程。以后能调试解决的问题不再赘述。
使用自增自减运算符的时候一定要注意,如果这样子写:
i = 0;
while(i < N)
a[i] = b[i++]; // 访问并修改 i 的值,会导致未定义行为将自增自减从下标中移走即可:
for(i = 0; i < N; i++){
a[i] = b[i];
}要求录入一串数据,然后按反向顺序输出这些数:
Enter 10 numbers: 1 2 3 4 5
In reverse order: 5 4 3 2 1参考程序:
#include<stdio.h>
#define N 5
int main(void){
int a[N];
int i;
printf("Enter %d numbers: ", N);
for(i = 0; i < N; i++){
scanf("%d", &a[i]);
}
printf("In reverse order: ");
for(i = N - 1; i >= 0; i--){
printf("%d ", a[i]);
}
printf("\n");
return 0;
}这个程序使用宏的思想可以借鉴。
数组初始化(array initializer)
一般的初始化方法:
int a[5] = {1, 2, 3, 4, 5};如果初始化式子比数组短,那么剩余的元素被赋值为 0
int a[5] = {1, 2, 3};
// initial value of a is {1, 2, 3, 0, 0}利用这一特性,可以很容易的将数组全部初始化为 0:
int a[5] = {0};如果给定了数组的初始化式,可以省略数组长度:
int a[] = {1, 2, 3, 4, 5};编译器利用初始化式的长度来确定数组大小。数组仍有固定数量的元素。
经常有这样的情况:数组中只有相对较少的元素需要进行显示的初始化,而其他元素可以进行默认赋值。
比如:
int a[10] = {0, 2, 0, 0, 0, 0, 0, 0, 2, 0};对于更大的数组,如果使用这种方式赋值,将是冗长而容易出错的。
C99 中的指定初始化可以用于解决这一问题:
int a[10] = {[1] = 2, [8] = 2};括号中的数组称为指示符。
注意:
-
赋值顺序不是问题。
int a[10] = {[8] = 2, [1] = 2};
写成这样也是 ok 的。
-
指示符必须是常量表达式。
-
如果待初始化的数组长度为 n ,那么指示符的取值为:[0, n-1];如果数组长度是省略的,指示符可以是任意非负数,编译器将根据最大的指示符推断出数组长度。
int a[] = {[10] = 10, [1] = 2, [8] = 2,};
最大的指示符为 10,数组长度为 11
-
初始化式中新旧方法可以混用
int a[10] = {1, 2, 3, [4] = 5, 6, 7, [9] = 9}; // a[0] = 1, a[1] = 2, a[2] = 3, a[4] = 5, a[5] = 6, a[6] = 7, a[9] = 9 其余都为 0
指示符后如果使用旧的方法初始化,那么初始化的元素应该紧邻指示符之后。
int a[] = { [9] = 9, 10, 11 };
数组 a 的元素个数为 12 个
如果新旧初始化方法混用,此时,数组 a 的大小就要看情况:如果最大的指示符后有旧的初始化方法,那么数组长度应该加上直到下一个指示符前的所有元素个数。
检查数中是否有出现多于 1 次的数字。
1 )判断是否存在重复出现的数字。
2)输出所有重复出现的数字。
参考答案:
1)
#include<stdio.h>
#include<stdbool.h>
int main(void) {
bool digit_seen[10] = { false };
int digit;
unsigned int n;
printf("Enter a number: ");
scanf("%u", &n);
// 求整数每一位:先 % 在 /
while (n > 0) {
digit = n % 10;
n /= 10;
if (digit_seen[digit] == true) {
break;
}
digit_seen[digit] = true;
}
// n > 0 说明 while 循环是 break 退出的,所以就有重复数字
if (n > 0) {
printf("Repeated digit\n");
}
else {
printf("No repeated digit\n");
}
return 0;
}2)
#include<stdio.h>
int main(void) {
int digit_seen[10] = { 0 };
int digit;
unsigned int n;
printf("Enter a number: ");
scanf("%u", &n);
while (n > 0) {
digit = n % 10;
n /= 10;
digit_seen[digit] += 1;// 计算每个数字出现的次数
}
for (int i = 0; i < 10; i++) {
if (digit_seen[i] > 1) { // 多于 1 次视为重复
printf("%d ", i);
}
}
return 0;
}对于第一个程序,如果你的编译器不支持头 <stdbool.h>,你可以自己定义宏,这个我们之前说过。或者就用 0 1 也可以。
int a[10];
printf("%zu", sizeof(a));数组的大小是数组每个元素大小的总和,也就是:数组元素个数 x 数组数据类型的大小
上例数组大小为 4 x 10 = 40 (int 大小为 4 的机器上)。
也可以用 sizeof 计算数组元素的大小:
int a[10];
printf("%zu", sizeof(a[0]));
// 4此外还有我们经常使用的:**计算数组长度:**用数组的大小除以每个元素的大小
int a[] = {1, 2, 3};
printf("%zu", sizeof(a) / sizeof(a[0]));细心的你可能已经发现,为什么我用的 printf 的转换说明都是 %zu 这是因为 sizeof 的返回值类型是 size_t 类型(unsigned int),%zu 是专门为这种类型设置的转换说明。
所以,有时候当你这样写程序时,可能会有报错:
for(int i = 0; i < sizeof(a) / sizeof(a[0]); i++){
...
}这时因为 i 和 sizeof(a) / sizeof(a[0]) 类型不一样,可以强制类型转换一下:
for(int i = 0; i < (int)sizeof(a) / sizeof(a[0]); i++){
...
}如果你嫌麻烦,可以使用宏定义数组长度,但是如果两个数组大小不一样,你就要定义两个宏。
这时候我们可以使用带参数的宏:
#define ARRAY_LENGTH(a) (int)sizeof(a) / sizeof(a[0])
int b[5];
printf("%d", ARRAY_LENGTH(b));如果不懂,也没有关系,后面我们会详细讲解。
编写一个程序显示一个表格。这个表格显示了几年时间内 100 美元投资在不同利率下的价值。用户输入利率和要投资的年数。投资总价值一年算一次,表格将显示输入的利率和紧随其后的 4 个更高的利率下投资的总价值。程序会话如下:
Enter intrest rate: 6
Enter number of years: 2
Years 6% 7% 8% 9% 10%
1 106.00 107.00 108.00 109.00 110.00
2 112.36 114.49 116.64 118.81 121.00第一行用一个 for 语句来显示。
我们在计算第一年的价值的时候将结果存放到数组中,然后使用数组中的结果继续计算下一年的价值。
在这一过程中我们将需要两个 for 语句,一个控制年份,一个控制不同的利率。
程序示例:
#include<stdio.h>
#define NUM_RATES (int)sizeof(value) / sizeof(value[0])
#define INITIAL_BALANCE 100.00
int main(void) {
int rate;
int year;
double value[5];
printf("Enter intrest rate: ");
scanf("%d", &rate);
printf("Enter number of years: ");
scanf("%d", &year);
printf("\nYears");
for (int i = 0; i < NUM_RATES; i++) {
printf("%7d%%", rate + i);
value[i] = INITIAL_BALANCE; // 初始化
}
printf("\n");
for (int i = 0; i < year; i++) {
printf("%3d ", i); // 补空格,让第一行和下面的行对齐
for (int j = 0; j < NUM_RATES; j++) {
value[j] += value[j] * (rate + j) / 100; // 注意这里不要写错
printf("%8.2f", value[j]);
}
printf("\n");
}
return 0;
}数组可以有任意维数。不过多维数组我们一般只使用二维数组。
二维数组的声明:
int a[3][3];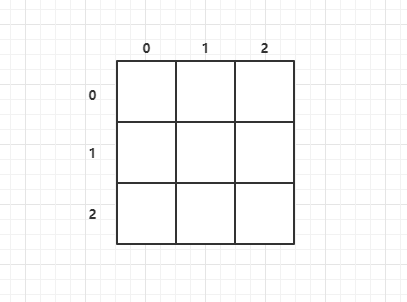
a[i][j]访问的时 第 i 行 第 j 列的元素。
虽然我们以表格的形式显示二维数组,但是实际上它们在计算机的内存中是按照行主序线性存储的,也就是从第 0 行开始。
所以上面的数组实际是这样存储的:
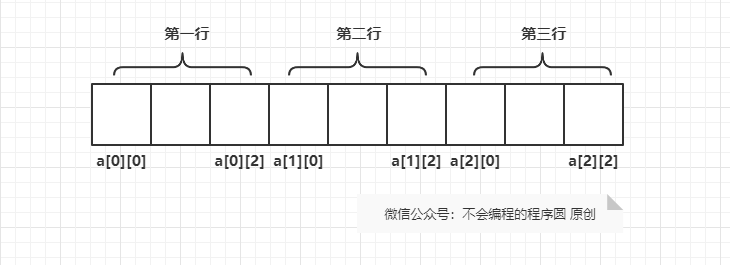
基于这个特性,我们一般用嵌套的 for 循环遍历二维数组:
int a[3][3];
for(int row = 0; row < 3; row++){
for(int col = 0; col < 3; col++){
a[row][col] = 0;
}
}嵌套的一维数组初始化式:
int a[3][3] = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
};缺省:
int a[3][3] = {
{1},
{2, 3}
}我们只初始化了第 1 行第 1 个元素,第 2 行第 1,2 个元素,其余的元素初始化为 0
甚至可以不写内层的大括号:
int a[3][3] = {
1, 2, 3,
4, 5, 6,
7, 8, 9
};一旦编译器填满一行,就开始填充下一行。
试思考,如果这样初始化二维数组,结果会是怎样:
int a[3][3] = {
1,
2, 3,
};第一行被初始化为 1,2,3 其余都为 0
C99 的指定初始化对多维数组也有效。例如:
int a[3][3]{
[0][0] = 0,
[1][1] = 1,
}像通常一样,没有指定值的元素默认置 0
多维数组的初始化可以省去第一维(二位数组中的行),其他维度不能省略。
int a[][3] = { {0}, {0}, {0} };用
const修饰的数组,数组元素无法被改写(只读)。
const char bin_chars[] = {'0','1'};下面这个程序说明了二维数组和常量数组的用法。
要求:
程序负责发一副标准纸牌。每张标准指派都有一个花色(梅花,方块,红桃,黑桃)和一个点数(2 ~ 10, J, Q, K, A)。用户需要指明发多少张牌:
Enter number of cards in hand: 5
Your card(s): S8 SA D7 H8 SK**程序说明: **
-
创建两个常量数组,分别放置 4 中花色 和 13 个点数
-
程序要可以生成 随机数 。我们需要三个函数:
time <time.h>
srand <stdlib.h>
rand <stdlib.h>
这三个函数组合就可以完成这一功能,原理在我另一篇文章:【随机数发生器】 中讲解过。
-
生成的随机数必须在:0 ~ 3 和 0 ~ 13 之间:
只需要让
rand() % 4那么随机数就在 0 ~ 3 之间,另一个同理。 -
两次拿到的牌不能是一样的。创建一个 bool 类型的数组,开始时全部初始化 false。每次拿到两个随机数后,如果数组对应的值为 false 那么将该元素置为 true 然后将此牌“发”给用户;否则,重新生成随机数。
参考程序:
#include<stdio.h>
#include<time.h>
#include<stdbool.h>
#include<stdlib.h>
#define NUM_SUIT 4
#define NUM_RANK 13
int main(void) {
int suit, rank, num_cards;
const char suit_code[] = {'H', 'D', 'C', 'S'}; // heart红桃 diamand方片 club梅花 spade黑桃
const char rank_code[] = { '2', '3', '4', '5', '6', '7', '8', '9', 'T', 'J', 'Q', 'K', 'A' };
bool in_hand[NUM_SUIT][NUM_RANK] = { false };
srand((unsigned)time(NULL));
printf("Enter number of cards in hand: ");
scanf("%d", &num_cards);
printf("Your card(s): ");
while (num_cards > 0) {
suit = rand() % NUM_SUIT;
rank = rand() % NUM_RANK;
if (!in_hand[suit][rank]) {
in_hand[suit][rank] = true;
num_cards--;
printf("%c%c ", suit_code[suit], rank_code[rank]);
}
}
printf("\n");
return 0;
}前面我们说到,数组变量的长度必须用常量表达式进行定义。但是 C99 中,可以使用变量作为数组长度。
例如:
scanf("%d", &n);
int a[n];变长数组(variable-length array,简称VLA):变长数组的长度时程序执行时计算的,而不是在编译时计算的。
如果不用变长数组,我们需要指定一个固定的长度。往往我们必须要给足大小,避免数组太小存放不下,导致程序出错。如果某一次程序只需要很少的空间,那么势必会造成巨大的内存浪费。
VS 2019 不换其他的编译器的情况下,是不支持 C99 这一特性的。所以,当时我写程序的时候,往往会开辟一个比较大的数组,每次都感觉很呆板。
作为开始学习的新手,建议就用 define 定义的宏来规定数组长度,这样使得程序更加易度和专业。
如果你学有余力,那么可以去学习一下动态内存分配函数 ,使用malloc来达到程序运行时创建合适大小的数组。我的文章也写过多次动态内存分配函数,有兴趣可以去看看。
变长数组的限制:
- 没有静态存储期限
- 不能初始化
变长数组常见于除了 main 函数以外的其他函数。对于函数 f 而言,变长数组最大的优势就是每次调用 f 时 数组的长度可以不同。
参考资料:《C Primer Plus》《C语言程序设计:现代方法》
Footnotes
-
早立规矩:同样方式做的同样处理。积累固定用法(idiom)。标准化。你和莎士比亚的唯一区别是成语(idiom)量——不是词汇量 Epigrams on Programming 编程警句 ↩