(explanation[explained_class_index], data_item)
```
-### Text and image usage examples
+### Text and image usage
+Examples
+
Lets illustrate the template above with *textual* data. The data item of interest is a sentence being (a part of) a movie review and the model has been trained to classify reviews into positive and negative sentiment classes.
We are intersted which words are contributing positively (red) and which - negatively (blue) towards the model's desicion to classify the review as positive and we would like to use the *LIME* explainer:
@@ -182,32 +186,35 @@ plt.show()
 +
+
Images
| Dataset | Description | Examples | Generation |
| :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :----------------------------------------------------------------------------------------------------------------------------------------------------- | :----------------------------------------------------------------------------------------------------------------------------------------------------- |
@@ -215,29 +222,38 @@ DIANNA comes with simple datasets. Their main goal is to provide intuitive insig
| [Simple Geometric (circles and triangles)](https://doi.org/10.5281/zenodo.5012824)  | Images of circles and triangles for 2-class geometric shape classificaiton. The shapes of varying size and orientation and the background have varying uniform gray levels. |
| Images of circles and triangles for 2-class geometric shape classificaiton. The shapes of varying size and orientation and the background have varying uniform gray levels. |  | [Simple geometric shapes dataset generation](https://github.com/dianna-ai/dianna-exploration/tree/main/example_data/dataset_preparation/geometric_shapes) |
| [Simple Scientific (LeafSnap30)](https://zenodo.org/record/5061353/)
| [Simple geometric shapes dataset generation](https://github.com/dianna-ai/dianna-exploration/tree/main/example_data/dataset_preparation/geometric_shapes) |
| [Simple Scientific (LeafSnap30)](https://zenodo.org/record/5061353/)  | Color images of tree leaves - a 30-class post-processed subset from the LeafSnap dataset for automatic identification of North American tree species. |
| Color images of tree leaves - a 30-class post-processed subset from the LeafSnap dataset for automatic identification of North American tree species. |  | [LeafSnap30 dataset generation](https://github.com/dianna-ai/dianna-exploration/blob/main/example_data/dataset_preparation/LeafSnap/) |
-### Text
+
| [LeafSnap30 dataset generation](https://github.com/dianna-ai/dianna-exploration/blob/main/example_data/dataset_preparation/LeafSnap/) |
-### Text
+Text
+
| Dataset | Description | Examples | Generation |
| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :---------------------------------------------------------------------------- | :--------------------------------------------------------------- | :------------------------------------------------------------------ |
| [Stanford sentiment treebank](https://nlp.stanford.edu/sentiment/index.html)  | Dataset for predicting the sentiment, positive or negative, of movie reviews. | _This movie was actually neither that funny, nor super witty._ | [Sentiment treebank](https://nlp.stanford.edu/sentiment/treebank.html) |
+| [EU-law statements](https://zenodo.org/records/8200000)
| Dataset for predicting the sentiment, positive or negative, of movie reviews. | _This movie was actually neither that funny, nor super witty._ | [Sentiment treebank](https://nlp.stanford.edu/sentiment/treebank.html) |
+| [EU-law statements](https://zenodo.org/records/8200000)  | Reproducibility data for a quantitative study on EU legislation. | _A Member State wishing to grant exemptions referred to in paragraph 6 shall notify the Council in writing_ | [EU legislation strictness analysis](https://github.com/nature-of-eu-rules/eu-legislation-strictness-analysis) |
+
| Reproducibility data for a quantitative study on EU legislation. | _A Member State wishing to grant exemptions referred to in paragraph 6 shall notify the Council in writing_ | [EU legislation strictness analysis](https://github.com/nature-of-eu-rules/eu-legislation-strictness-analysis) |
+
Time series
+
| Dataset | Description | Examples | Generation |
| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------------------------------------------------------------------------------------------- | :--------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------ |
| [Coffee dataset](https://www.timeseriesclassification.com/description.php?Dataset=Coffee)  | Food spectographs time series dataset for a two class problem to distinguish between Robusta and Arabica coffee beans. |
| Food spectographs time series dataset for a two class problem to distinguish between Robusta and Arabica coffee beans. | 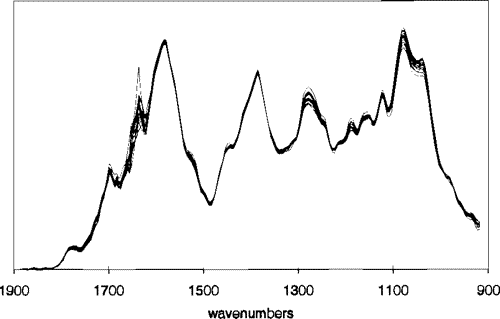 | [data source](https://github.com/QIBChemometrics/Benchtop-NMR-Coffee-Survey) |
| [Weather dataset](https://zenodo.org/record/7525955)
| [data source](https://github.com/QIBChemometrics/Benchtop-NMR-Coffee-Survey) |
| [Weather dataset](https://zenodo.org/record/7525955)  | The light version of the weather prediciton dataset, which contains daily observations (89 features) for 11 European locations through the years 2000 to 2010. |
| The light version of the weather prediciton dataset, which contains daily observations (89 features) for 11 European locations through the years 2000 to 2010. |  | [data source](https://github.com/florian-huber/weather_prediction_dataset) |
-### Tabular
+
| [data source](https://github.com/florian-huber/weather_prediction_dataset) |
-### Tabular
+
Tabular
+
| Dataset | Description | Examples | Generation |
| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------------------------------------------------------------------------------------------- | :--------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------ |
| [Pengiun dataset](https://www.kaggle.com/code/parulpandey/penguin-dataset-the-new-iris)  | Palmer Archipelago (Antarctica) penguin dataset is a great intro dataset for data exploration & visualization similar to the famous Iris dataset. |
| Palmer Archipelago (Antarctica) penguin dataset is a great intro dataset for data exploration & visualization similar to the famous Iris dataset. |  | [data source](https://github.com/allisonhorst/palmerpenguins) |
| [Weather dataset](https://zenodo.org/record/7525955) | The light version of the weather prediciton dataset, which contains daily observations (89 features) for 11 European locations through the years 2000 to 2010. | | [data source](https://github.com/florian-huber/weather_prediction_dataset) |
| [Land atmosphere dataset](https://zenodo.org/records/12623257)
| [data source](https://github.com/allisonhorst/palmerpenguins) |
| [Weather dataset](https://zenodo.org/record/7525955) | The light version of the weather prediciton dataset, which contains daily observations (89 features) for 11 European locations through the years 2000 to 2010. | | [data source](https://github.com/florian-huber/weather_prediction_dataset) |
| [Land atmosphere dataset](https://zenodo.org/records/12623257)  | It contains land-atmosphere variables and latent heat flux (LEtot) simulated by STEMMUS-SCOPE (soil-plant model), version 1.5.0, over 19 Fluxnet sites and for the year 2014 with hourly intervals. |
| It contains land-atmosphere variables and latent heat flux (LEtot) simulated by STEMMUS-SCOPE (soil-plant model), version 1.5.0, over 19 Fluxnet sites and for the year 2014 with hourly intervals. | 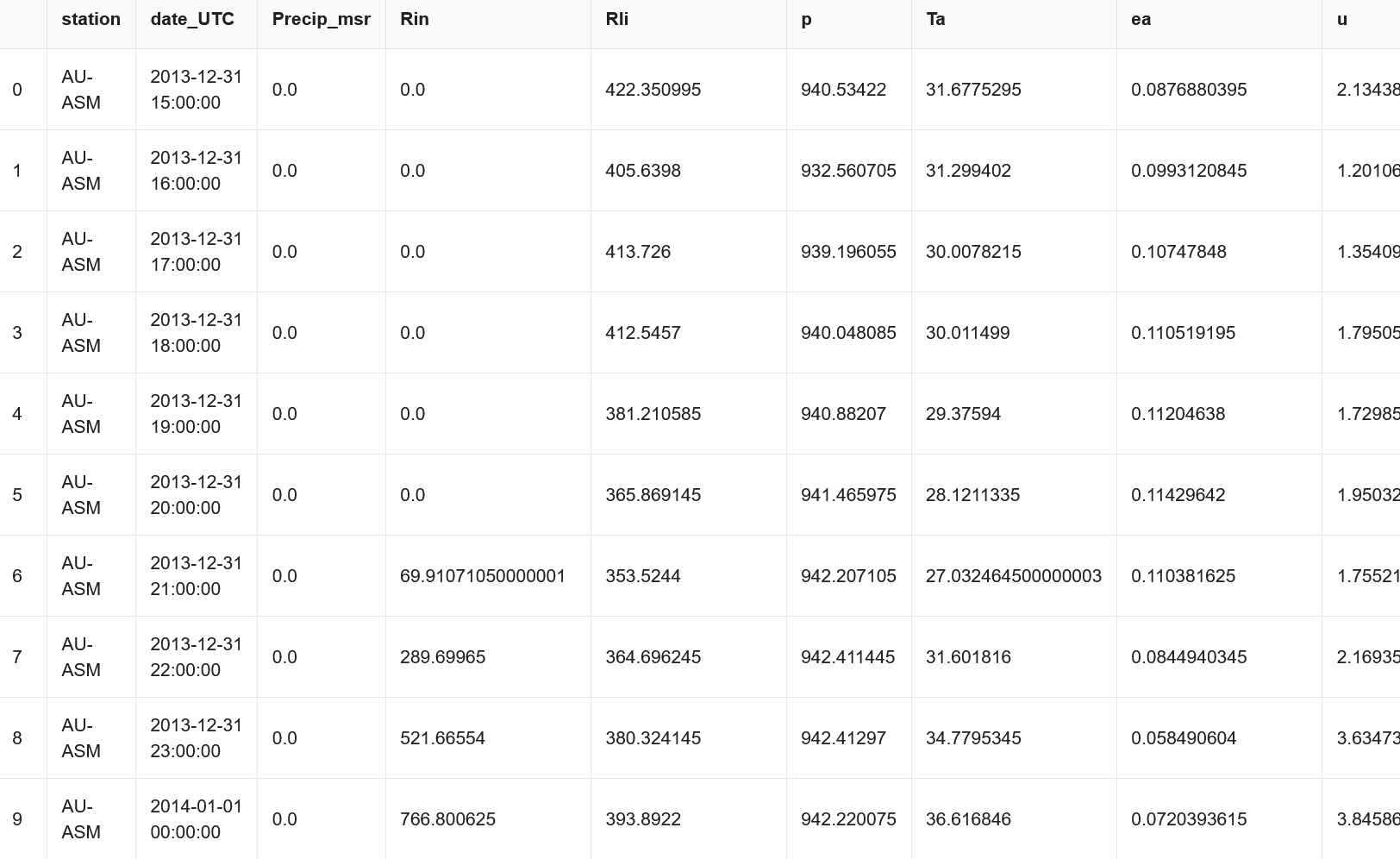 | [data source](https://zenodo.org/records/12623257) |
-## ONNX model
+
| [data source](https://zenodo.org/records/12623257) |
-## ONNX model
+
Images
| Models | Generation |
| :-------------------------------------------------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| [Binary MNIST model](https://zenodo.org/record/5907177) | [Binary MNIST model generation](https://github.com/dianna-ai/dianna-exploration/blob/main/example_data/model_generation/MNIST/generate_model_binary.ipynb) |
| [Simple Geometric model](https://zenodo.org/deposit/5907059) | [Simple geometric shapes model generation](https://github.com/dianna-ai/dianna-exploration/blob/main/example_data/model_generation/geometric_shapes/generate_model.ipynb) |
| [Simple Scientific model](https://zenodo.org/record/5907196) | [LeafSnap30 model generation](https://github.com/dianna-ai/dianna-exploration/blob/main/example_data/model_generation/LeafSnap/generate_model.ipynb) |
+Text
| Models | Generation |
|:---------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Movie reviews model](https://zenodo.org/record/5910598) | [Stanford sentiment treebank model generation](https://github.com/dianna-ai/dianna-exploration/blob/main/example_data/model_generation/movie_reviews/generate_model.ipynb) |
| [Regalatory statement classifier](https://zenodo.org/record/8200001) | [EU-law regulatory-statement-classification](https://github.com/nature-of-eu-rules/regulatory-statement-classification) |
-### Time series
+Time series
| Models | Generation |
| :-------------------------------------------------------- | :---------------------------------------------------------------------------------------------------------------------------------------------------------------- |
@@ -273,7 +292,9 @@ And here are links to notebooks showing how we created our models on the benchma
| [Season prediction model](https://zenodo.org/record/7543883) | [Season prediction model generation](https://github.com/dianna-ai/dianna-exploration/blob/main/example_data/model_generation/season_prediction/generate_model.ipynb) |
| [Fast Radio Burst classification model](https://zenodo.org/records/10656614) | [Fast Radio Burst classification model generation](https://doi.org/10.3847/1538-3881/aae649) |
-### Tabular
+Tabular
| Models | Generation |
| :-------------------------------------------------------- | :---------------------------------------------------------------------------------------------------------------------------------------------------------------- |
@@ -281,6 +302,7 @@ And here are links to notebooks showing how we created our models on the benchma
| [Sunshine hours prediction model (regression)](https://zenodo.org/records/10580833) | [Sunshine hours prediction model generation](https://github.com/dianna-ai/dianna-exploration/blob/main/example_data/model_generation/sunshine_prediction/generate_model.ipynb) |
| [Latent heat flux prediction model (regression)](https://zenodo.org/records/12623257) | [Latent heat flux prediction model](doi:10.5281/zenodo.12623256/stemmus_scope_emulator_model_LEtot.onnx) |
+ ) can be used for explanation of ONNX models trained for the tasks and datasets presented in several (marked with ) of the DIANNA [tutorials](../../tutorials/README.md).
+The dashboard shows the visual explanation of a models' decision on a selected data item by a selected XAI method (explainer). Results of different explainers can be compared, as well as explanations of the top predicted labels.
To open the dashboard, you can install dianna via `pip install -e '.[dashboard]'` and run:
@@ -21,26 +19,8 @@ Open the link on which the app is running. Note that you are running the dashboa
## How to use the dashboard
-The dashboard will automatically open in the welcome page tab. In the sidebar you can open the image or text pages.
-
-### Images
-
-- Click on select image and select an image saved on your computer for which you want the DIANNA explanation.
-- Click on select model and select your trained model used for the prediction and explanation.
-- Click on select labels and select a text file containing the labels of your trained model. Labels should be separated by line breaks in the file, no other separators should be used. Make sure that both the labels and ordering of the labels is correct in correspondence to your trained model.
-- Check the XAI methods you want to use, multiple methods can be used at the same time for comparison.
-- Your image explanation will start loading.
-
-Additionally, you can:
-- Select the number of top results you which to show the explanation for, i.e. if you use 2, the dashboard will show not only the explanation for the main prediction for the selected image, but also for the second most likely prediction.
-- Set the method specific settings to the selected XAI methods. If you don't change these, the default values are used.
-
-### Text
-
-- Input the text you want to use in the "Input string" box. Press enter to update the explanation.
-- Click on select model and select your trained model used for the prediction and explanation.
-- Click on select labels and select a text file containing the labels of your trained model. Labels should be separated by line breaks in the file, no other separators should be used. Make sure that both the labels and ordering of the labels is correct in correspondence to your trained model.
-- Check the XAI methods you want to use, multiple methods can be used at the same time for comparison.
-- Your image explanation will start loading.
+This [video](https://youtu.be/9VM5acip2s8) shows you how to use the DIANNA dashboard for some of the [tutorials](../../tutorials/README.md#summary-of-all-tutorials) to interactively explore the use cases from some of DIANNA's .
+Similarly, you can use it with your own data, models and lables.
-Additionally, you can set the method specific settings to the selected XAI methods. If you don't change these, the default values are used.
+--------------------------------------------------------------------------
+
diff --git a/dianna/data/Diana_goddess.png b/dianna/data/Diana_goddess.png
new file mode 100644
index 00000000..37329890
Binary files /dev/null and b/dianna/data/Diana_goddess.png differ
diff --git a/setup.cfg b/setup.cfg
index 81798c4e..215c344d 100644
--- a/setup.cfg
+++ b/setup.cfg
@@ -115,7 +115,7 @@ notebooks =
torchvision
ipywidgets
freetype-py
- transformers
+ transformers<4.46.0
xgboost
[options.entry_points]
diff --git a/tutorials/README.md b/tutorials/README.md
index 9890ce6c..35c08940 100644
--- a/tutorials/README.md
+++ b/tutorials/README.md
@@ -16,7 +16,7 @@ pip install .[notebooks]
### Datasets and Tasks
-#### Illustrative (Simple)
+
) can be used for explanation of ONNX models trained for the tasks and datasets presented in several (marked with ) of the DIANNA [tutorials](../../tutorials/README.md).
+The dashboard shows the visual explanation of a models' decision on a selected data item by a selected XAI method (explainer). Results of different explainers can be compared, as well as explanations of the top predicted labels.
To open the dashboard, you can install dianna via `pip install -e '.[dashboard]'` and run:
@@ -21,26 +19,8 @@ Open the link on which the app is running. Note that you are running the dashboa
## How to use the dashboard
-The dashboard will automatically open in the welcome page tab. In the sidebar you can open the image or text pages.
-
-### Images
-
-- Click on select image and select an image saved on your computer for which you want the DIANNA explanation.
-- Click on select model and select your trained model used for the prediction and explanation.
-- Click on select labels and select a text file containing the labels of your trained model. Labels should be separated by line breaks in the file, no other separators should be used. Make sure that both the labels and ordering of the labels is correct in correspondence to your trained model.
-- Check the XAI methods you want to use, multiple methods can be used at the same time for comparison.
-- Your image explanation will start loading.
-
-Additionally, you can:
-- Select the number of top results you which to show the explanation for, i.e. if you use 2, the dashboard will show not only the explanation for the main prediction for the selected image, but also for the second most likely prediction.
-- Set the method specific settings to the selected XAI methods. If you don't change these, the default values are used.
-
-### Text
-
-- Input the text you want to use in the "Input string" box. Press enter to update the explanation.
-- Click on select model and select your trained model used for the prediction and explanation.
-- Click on select labels and select a text file containing the labels of your trained model. Labels should be separated by line breaks in the file, no other separators should be used. Make sure that both the labels and ordering of the labels is correct in correspondence to your trained model.
-- Check the XAI methods you want to use, multiple methods can be used at the same time for comparison.
-- Your image explanation will start loading.
+This [video](https://youtu.be/9VM5acip2s8) shows you how to use the DIANNA dashboard for some of the [tutorials](../../tutorials/README.md#summary-of-all-tutorials) to interactively explore the use cases from some of DIANNA's .
+Similarly, you can use it with your own data, models and lables.
-Additionally, you can set the method specific settings to the selected XAI methods. If you don't change these, the default values are used.
+--------------------------------------------------------------------------
+
diff --git a/dianna/data/Diana_goddess.png b/dianna/data/Diana_goddess.png
new file mode 100644
index 00000000..37329890
Binary files /dev/null and b/dianna/data/Diana_goddess.png differ
diff --git a/setup.cfg b/setup.cfg
index 81798c4e..215c344d 100644
--- a/setup.cfg
+++ b/setup.cfg
@@ -115,7 +115,7 @@ notebooks =
torchvision
ipywidgets
freetype-py
- transformers
+ transformers<4.46.0
xgboost
[options.entry_points]
diff --git a/tutorials/README.md b/tutorials/README.md
index 9890ce6c..35c08940 100644
--- a/tutorials/README.md
+++ b/tutorials/README.md
@@ -16,7 +16,7 @@ pip install .[notebooks]
### Datasets and Tasks
-#### Illustrative (Simple)
+Illustrative (Simple)
|*Data modality*|Dataset| *Task* |Logo|
|:------------|:------|:----------------------------------------------------------------------|:----|
@@ -28,46 +28,57 @@ pip install .[notebooks]
| | [Weather dataset](https://zenodo.org/record/7525955) | Binary *classification* (warm/cold season) of temperature time-series ||
|*Tabular*| [Penguin dataset](https://www.kaggle.com/code/parulpandey/penguin-dataset-the-new-iris)| $3$ penguin spicies (Adele, Chinstrap, Gentoo) *classificaiton* | | |
| | [Weather dataset](https://zenodo.org/record/7525955) | Next day sunshine hours prediction (*regression*) | |
+Scientific use-cases
+
|*Data modality*|Dataset|*Task*|Logo|
|:------------|:------|:---|:----|
|*Images*|[Simple Scientific (LeafSnap30)](https://zenodo.org/record/5061353/)| $30$ tree species leaves *classification* |  |
-|*Text*| [EU-law statements](https://zenodo.org/records/8200001) | Regulatory or non-regulatory *classification* | |
+|*Text*| [EU-law statements](https://zenodo.org/records/8200000) | Regulatory or non-regulatory *classification* | |
|*Timeseries* | Fast Radio Burst (FRB) dataset (not publicly available) | Binary *classificaiton* of Fast Radio Burst (FRB) timeseries data : noise or a real FRB. |
|
-|*Text*| [EU-law statements](https://zenodo.org/records/8200001) | Regulatory or non-regulatory *classification* | |
+|*Text*| [EU-law statements](https://zenodo.org/records/8200000) | Regulatory or non-regulatory *classification* | |
|*Timeseries* | Fast Radio Burst (FRB) dataset (not publicly available) | Binary *classificaiton* of Fast Radio Burst (FRB) timeseries data : noise or a real FRB. |  |
|*Tabular*| [Land atmosphere dataset](https://zenodo.org/records/12623257)| Prediction of "latent heat flux" (*regression*). The random forest model is used as an [emulator](https://github.com/EcoExtreML/Emulator) to replace the physical model [STEMMUS_SCOPE](https://github.com/EcoExtreML/STEMMUS_SCOPE) to predict global maps of latent heat flux. | |
+
|
|*Tabular*| [Land atmosphere dataset](https://zenodo.org/records/12623257)| Prediction of "latent heat flux" (*regression*). The random forest model is used as an [emulator](https://github.com/EcoExtreML/Emulator) to replace the physical model [STEMMUS_SCOPE](https://github.com/EcoExtreML/STEMMUS_SCOPE) to predict global maps of latent heat flux. | |
+Illustrative (Simple)
+
|*Modality* \ Method|RISE|[LIME](https://youtu.be/d6j6bofhj2M)|Kernel[SHAP](https://youtu.be/9haIOplEIGM)|
|:-----|:---|:---|:---|
-|*Images*|[ ](./explainers/RISE/rise_mnist.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_mnist.ipynb) | | [](./explainers/KernelSHAP/kernelshap_mnist.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_mnist.ipynb) |
+|*Images*|[](./explainers/RISE/rise_mnist.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_mnist.ipynb) | | [](./explainers/KernelSHAP/kernelshap_mnist.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_mnist.ipynb) |
| | [
](./explainers/RISE/rise_mnist.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_mnist.ipynb) | | [](./explainers/KernelSHAP/kernelshap_mnist.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_mnist.ipynb) |
+|*Images*|[](./explainers/RISE/rise_mnist.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_mnist.ipynb) | | [](./explainers/KernelSHAP/kernelshap_mnist.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_mnist.ipynb) |
| | [ ](./explainers/RISE/rise_imagenet.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_imagenet.ipynb) | | [
](./explainers/RISE/rise_imagenet.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_imagenet.ipynb) | | [ ](./explainers/KernelSHAP/kernelshap_geometric_shapes.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_geometric_shapes.ipynb)|
-|*Text* |[
](./explainers/KernelSHAP/kernelshap_geometric_shapes.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_geometric_shapes.ipynb)|
-|*Text* |[ ](./explainers/RISE/rise_text.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_text.ipynb) |[](./explainers/LIME/lime_text.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_text.ipynb) |[]()|
-| *Time series*| [
](./explainers/RISE/rise_text.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_text.ipynb) |[](./explainers/LIME/lime_text.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_text.ipynb) |[]()|
-| *Time series*| [ ](./explainers/RISE/rise_timeseries_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_timeseries_weather.ipynb)| [](./explainers/LIME/lime_timeseries_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_timeseries_weather.ipynb)| |
+|*Text* |[](./explainers/RISE/rise_text.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_text.ipynb) |[](./explainers/LIME/lime_text.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_text.ipynb) |[]()|
+| *Time series*| [](./explainers/RISE/rise_timeseries_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_timeseries_weather.ipynb) | [](./explainers/LIME/lime_timeseries_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_timeseries_weather.ipynb) | |
| | | [
](./explainers/RISE/rise_timeseries_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_timeseries_weather.ipynb)| [](./explainers/LIME/lime_timeseries_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_timeseries_weather.ipynb)| |
+|*Text* |[](./explainers/RISE/rise_text.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_text.ipynb) |[](./explainers/LIME/lime_text.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_text.ipynb) |[]()|
+| *Time series*| [](./explainers/RISE/rise_timeseries_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_timeseries_weather.ipynb) | [](./explainers/LIME/lime_timeseries_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_timeseries_weather.ipynb) | |
| | | [ ](./explainers/LIME/lime_timeseries_coffee.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_timeseries_coffee.ipynb) | |
-| *Tabular* | [](./explainers/RISE/rise_tabular_penguin.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_tabular_penguin.ipynb) | [](./explainers/LIME/lime_tabular_penguin.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_tabular_penguin.ipynb) |[](./explainers/KernelSHAP/kernelshap_tabular_penguin.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_penguin.ipynb) |
-| | | [](./explainers/LIME/lime_tabular_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_weather.ipynb)|[](./explainers/KernelSHAP/kernelshap_tabular_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_weather.ipynb) |
+| *Tabular* | [](./explainers/RISE/rise_tabular_penguin.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_tabular_penguin.ipynb) | [](./explainers/LIME/lime_tabular_penguin.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_tabular_penguin.ipynb) |[](./explainers/KernelSHAP/kernelshap_tabular_penguin.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_penguin.ipynb) |
+| | | [](./explainers/LIME/lime_tabular_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_weather.ipynb) |[](./explainers/KernelSHAP/kernelshap_tabular_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_weather.ipynb) |
To learn more about how we aproach the masking for time-series data, please read our [Masking time-series for XAI](https://blog.esciencecenter.nl/masking-time-series-for-explainable-ai-90247ac252b4) blog-post.
+
](./explainers/LIME/lime_timeseries_coffee.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_timeseries_coffee.ipynb) | |
-| *Tabular* | [](./explainers/RISE/rise_tabular_penguin.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_tabular_penguin.ipynb) | [](./explainers/LIME/lime_tabular_penguin.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_tabular_penguin.ipynb) |[](./explainers/KernelSHAP/kernelshap_tabular_penguin.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_penguin.ipynb) |
-| | | [](./explainers/LIME/lime_tabular_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_weather.ipynb)|[](./explainers/KernelSHAP/kernelshap_tabular_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_weather.ipynb) |
+| *Tabular* | [](./explainers/RISE/rise_tabular_penguin.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_tabular_penguin.ipynb) | [](./explainers/LIME/lime_tabular_penguin.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_tabular_penguin.ipynb) |[](./explainers/KernelSHAP/kernelshap_tabular_penguin.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_penguin.ipynb) |
+| | | [](./explainers/LIME/lime_tabular_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_weather.ipynb) |[](./explainers/KernelSHAP/kernelshap_tabular_weather.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_weather.ipynb) |
To learn more about how we aproach the masking for time-series data, please read our [Masking time-series for XAI](https://blog.esciencecenter.nl/masking-time-series-for-explainable-ai-90247ac252b4) blog-post.
+Scientific use-cases
| *Modality* \ Method |RISE| [LIME](https://youtu.be/d6j6bofhj2M) |Kernel[SHAP](https://youtu.be/9haIOplEIGM)|
|:--------------------|:---|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---|
| *Images* | | [](./explainers/LIME/lime_images.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_images.ipynb) ||
-| | | [](./explainers/RISE/rise_timeseries_frb.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_timeseries_frb.ipynb) | |
-| *Text* | | [](./explainers/LIME/lime_text_eulaw.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_text_eulaw.ipynb) | |
-| *Time series* | [](./explainers/RISE/rise_timeseries_frb.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_timeseries_frb.ipynb) | |
+| *Text* | | [](./explainers/LIME/lime_text_eulaw.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/LIME/lime_text_eulaw.ipynb) | |
+| *Time series* | [](./explainers/RISE/rise_timeseries_frb.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/RISE/rise_timeseries_frb.ipynb) | |
| *Tabular* | | |[](./explainers/KernelSHAP/kernelshap_tabular_land_atmosphere.ipynb) or [](https://colab.research.google.com/github/dianna-ai/dianna/blob/main/tutorials/explainers/KernelSHAP/kernelshap_tabular_land_atmosphere.ipynb)|
+Settings per explainer
+
The XAI methods (explainers) are sensitive to the choice of their hyperparameters! In this [master Thesis](https://staff.fnwi.uva.nl/a.s.z.belloum/MSctheses/MScthesis_Willem_van_der_Spec.pdf), this sensitivity is researched and useful conclusions are drawn.
The default hyperparameters used in DIANNA for each explainer as well as the choices for some tutorials and their data modality (*i* - images, *txt* - text, *ts* - time series and *tab* - tabular) are given in the tables below.
Also the main conclusions (🠊) from the thesis (on images and text) about the hyperparameters effect are listed.
@@ -101,6 +112,9 @@ Also the main conclusions (🠊) from the thesis (on images and text) about the
| $n_{segments}$ | **$100$** |$200$ |$200$ |default |
| $sigma$ | **$0$** | default | default | default|
+
🠊 The most crucial parameter is the nubmer of super-pixels $n_{segments}$. Higher values led to higher sensitivity, however that observaiton was dependant on the evaluaiton metric.
🠊 Regularization had only a marginal detrimental effect, the best results were obtained using no regularization (no smoothing, $sigma = 0$) or least squares regression.
+
+