An outlier is a data point which is very far, somehow, from the rest of the data. They are often worrisome, but not always a problem.[1]
When we are doing regression modeling, in fact, we don’t really care about whether some data point is far from the rest of the data, but whether it breaks a pattern the rest of the data seems to follow.
An influential point is an outlier that greatly affects the slope of the regression line[2]


As you can see, some points can be particularly influential in the estimation of
On the other hand points which have extreme values of

If we are worried that outliers might be messing up our model, we would like to quantify how much the estimates change if we add or remove individual data points.
Fortunately, we can quantify this using only quantities we estimated on the complete data, especially the design matrix.
Let’s think about what happens with simple linear regression for a moment:
With a single real-valued predictor variable
$$\hat{\beta}{0} = \bar{y} - \hat{\beta}{1}\bar{x}$$
Let us turn this around. The fitted value at
$$\bar{y} = \hat{\beta}{0} + \hat{\beta}{1}\bar{x}$$
Suppose we had a data point, say the
- The regression line HAS to go through
$(\bar{x},\bar{y})$ never mind wheter$y_{i}$ is close to$\bar{y}$ or far way

If
- It has SOME influence because
$y_{i}$ is part of what we average to get$\bar{y}$ ,but that's not a lot of influence
Again, with SLR we know that:
The ratio between the sample covariance of X and Y and the sample variance of X. How does yi show up in this? It's
Notice that
- When
$x_{i} = \bar{x}$ ,$y_{i}$ doesn't actually matter at all to the slope. - If
$x_{i}$ is far from$\bar{x}$ , then$x_{i}=\bar{x}$ will contibute to the slope and its contribution will get bigger (whether positive or negative) as$x_{i}=\bar{x}$ grows. -
$y_{i}$ will also make a big contribution to the slope when$y_{i}-\bar{y}$ (unless, again$x_{i} = \bar{x}$ )
Let’s write a general formula for the predicted value, at an arbitrary point
$$\hat{m}(x) = \hat{\beta}{0} + \hat{\beta}{1}(x)$$
$$\hat{m}(x) = \bar{y} - \hat{\beta}{1}\bar{x} + \hat{\beta}{1}(x)$$
So, in words:
- The predicted value is always a weighted average of all the
$y_{i}$ - As
$x_{i}$ moves away from$\bar{x}$ ,$y_{i}$ gets more weight (possibly a large negative weight). When$x_{i} = \bar{x}$ ,$y_{i}$ only matters because it contributes to the global mean$\bar{y}$ (little leverage) - The weights on all data points increase in magnitude when the point
$x$ where we’re trying to predict is far from$\bar{x}$ .- If
$x =\bar{x}$ only$\bar{y}$ matters.
- If
All of this is still true of the fitted values at the original data points:
- if
$x_{i} = \bar{x}$ ,$y_{i}$ only matter for the fitt because it contributes to$\bar{y}$ - As
$x_{i}$ moves away from$\bar{x}$ , in either direction, it makes a bigger contribution to ALL the fitte values
Why is this happening? We get the coefficient estimates by minimizing the MSE which treats all data points equally:
But we’re not just using any old function
This has only two parameters, so we can’t change the predicted value to match each data point — altering the parameters to bring
By minimizing the over-all MSE with a linear function, we get two constraints
- First,
$\bar{y} = \hat{\beta_{0}} + \hat{\beta_{1}}\bar{x}$ - It makes the regression line insensitive to
$y_{i}$ values when$x_{i}$ is close to$\bar{x}$
- It makes the regression line insensitive to
- Second,
$\sum_{i}e_{i}(x_{i} - \bar{x}) = 0$ - It makes the regression line very sensitive to residuals when
$x_{i} - \bar{x}$ is big - When
$x_{i} - \bar{x}$ is large, a big residual$e_{i}$ far from 0 is harder to balance out than if$x_{i} - \bar{x}$ were smaller.
- It makes the regression line very sensitive to residuals when
To sum up
- Least squares estimation tries to bring all the predicted values closer to
$y_{i}$ , but it can’t match each data point at once, because the fitted values are all functions of the same coefficients. - If
$x_{i}$ is close to$\bar{x}$ ,$y_{i}$ makes little difference to the coefficients or fitted values — they’re pinned down by needing to go through the mean of the data. - As
$x_{i}$ moves away from$\bar{x}$ ,$y_{i} − \bar{y}$ makes a bigger and bigger impact on both the coefficients and on the fitted values.
If we worry that some point isn’t falling on the same regression line as the others, we’re really worrying that including it will throw off our estimate of the line.
This is going to be a concern either when
We should also be worried if the residual values are too big (particularly when they correspond to values with large
However, when asking what’s “too big”, we need to take into account the fact that the model will try harder to fit some points than others. A big residual at a point of high leverage is more of a red flag than an equal-sized residual at point with little influence.
All of this also holds for multiple regression models where things become more complicated because of the high dimensionality (harder to know when
Recall that our least-squares coefficient estimator is:
from which we get our fitted values as:
with the design matrix
$$\frac{\partial \hat{\beta}{k}}{\partial y{i}} = ((X^{T}X)^{-1}X^{T})_{ki}$$
and
$$\frac{\partial \hat{m}{k}}{\partial y{i}} = H_{ii}$$
Comment:
- If
$y_{i}$ were different, it would change the estimates for all the coefficients and for all the fitted values. - The rate at which the
$k^{th}$ coefficient or fitted value changes is given by the kith entry in these matrices — matrices which, notice, are completely defined by the design matrix$X$ . Plus we need to consider the interactions, the collinearity etc...
$H_{ii}$ is the influence of$y_{i}$ on its own fitted value; it tells us how much of$\hat{m_{i}}$ is just$y_{i}$
This turns out to be a key quantity in looking for outliers, so we’ll give it a special name, the leverage
Once again, the leverage of the
Because the general linear regression model doesn’t assume anything about the distribution of the predictors, other than that they’re not collinear, we can’t say definitely that some values of the leverage break model assumptions, or even are very unlikely under the model assumptions.
But we can say some things about the leverage.
The trace of a matrix
$A$ ,$\operatorname{tr}(A)$ is defined to be the sum of elements on the main diagonal (from the upper left to the lower right) of A.
- The trace is only defined for a square matrix (n × n).
Let's consider some aspects:
- The trace of the design matrix equals to the sum of its diagonal entries;
- The diagonal entries are the
$i$ leverages!
- The diagonal entries are the
- At the same time it is equal to the number
$p$ of coefficients we estimate - Therefore, the trace of the design matrix is the sum of each point’s leverage and is equal to p, the number of regression coefficients.
This represents the typical value, the leverage of a point
We don’t expect every point to have exactly the same leverage, but if some points have much more than others, the regression function is going to be pulled towards fitting the high-leverage points, and the function will tend to ignore the low-leverage points.
Notice one curious feature of the leverage is, and of the hat matrix in general, is that it doesn’t care what we are regressing on the predictor variables. The values of the leverage only depend on
To sum up:
- The leverage of a data point just depends on the value of the predictors there
- It increases as the point moves away from the mean of the predictors.
- It increases more if the difference is along low-variance coordinates, and less for differences along high-variance coordinates.
When we are in a low dimensional space is easier to think in 2D, an influential point is something that does not follow the trend and impacts our estimates. However, when translating the same concept in a dimension that is higher than 3D, it is hard to notice.
We return once more to the hat matrix. The residuals, too, depend only on the hat matrix:
We know that the residuals vary randomly with the noise, so let’s re-write this in terms of the noise:
Since
If we also assume that the noise is Gaussian, the residuals are Gaussian, with the stated mean and variance. What does this imply for the residual at the
$$Var[e_{i}]= \sigma^{2}(I-H){ii} = \sigma^{2}(1-H{ii})$$
In other words: the bigger the leverage of a point
Previously, when we looked at the residuals, we expected them to all be of roughly the same magnitude. This rests on the leverages
The usual way to do this is through the standardized or studentized residuals
Why “studentized”? Because we’re dividing by an estimate of the standard error, just like in “Student’s” t-test for differences in means
- The distribution here is however not quite a t-distribution, because, while
$e_{i}$ has a Gaussian distribution and$\hat{\sigma}$ is the square root of a$\chi^{2}$ distributed variable,$e_{i}$ is actually used in computing$\hat{\sigma}$ , hence they’re not statistically independent. - Rather,
$\frac{r_{i}^{2}}{n-p-1} \thicksim \beta(\frac{1}{2}, \frac{1}{2}(n-p-2))$ This gives us studentized residuals which all have the same distribution, and that distribution does approach a Gaussian as$n \rightarrow \inf$ with$p$ fixed.
All of the residual plots we’ve done before can also be done with the studentized residuals. In particular, the studentized residuals should look flat, with constant variance, when plotted against the fitted values or the predictors.
Indeed the plots we get when applying plot to an lm object in R are based ont eh Standardzed residuals, which can be obtained using rstandard
In defining the Leave-one-out cross validation (LOOCV) we considered what would be our estimate of
To recap a bit, the design matrix is a
This in turn would lead to a new fitted value:
$$\hat{y_{\text{[i]}}} = \hat{m}{[i]} =\hat{m}^{(-i)}(x{i}) = \frac{(Hy){i}-H{ii}y_{i}}{1-H_{ii}}$$
Basically, this is saying we can take the old fitted value, and then subtract off the part of it which came from having included the observation yj in the first place. Because each row of the hat matrix has to add up to 1, we need to include the denominator
Now we can define,
That is, this is how far off the model’s prediction of
Leaving out the data point
A little work says that:
Fortunately, we can compute this without having to actually re-run the regression:
Omitting point
How big a change is this? It’s natural (by this point!) to use the squared length of the difference vector,
To make this more comparable across data sets, it’s conventional to divide this by
As usual, there is a simplified formula, which evades having to re-fit the regression:
The total influence of a point over all the fitted values grows with both its leverage
This tells us how much the estimate
- If large, the information is influent
- However what we do not know is the reason!
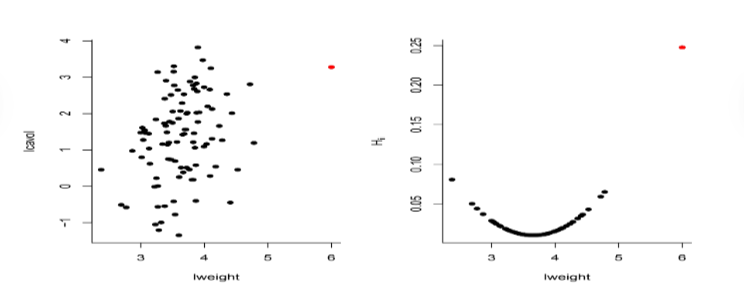
The data stars contains information on the log of the surface temperature and the log of the light intensity of 47 stars in the star cluster CYG OB1, which is in the direction of Cygnus.
data(star, package = "faraway")
plot(star)
fit_star <- lm(light ̃ temp, data = star)
It is evident we have a strong presence of outliers.
plot(star[,"temp"], hatvalues(fit_star), pch = 16)
It is interesting to see that the points close to the mean have leverage equal to 0
par(mfrow=c(2,2)); plot(fit_star)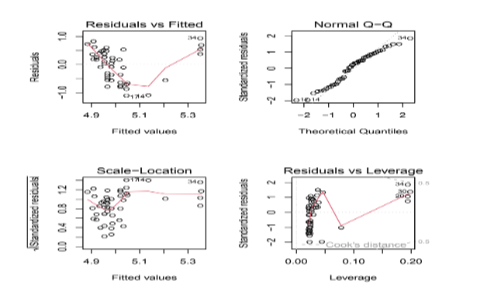
Let's see what is happeing
- Residuals vs Fitted: Highlights the functional form and over/under estimations
- we find a structural form in the model, which is not a good sign ❌
- QQ-plot: Highlights the assumption of normality
- It is looking good
- Scale-Location: Highlights the assumption of homoskedasticity
- It is not looking too bad
- Residual vs Leverage: Highlights influence points
- If any point in this plot falls outside of Cook’s distance (the red dashed lines) then it is considered to be an influential observation.
- The four points in the top-right corner seem a bit problematic ❌ and they have a large Cook's distance.
Let's analyze this last one.
plot(star[,"temp"], cooks.distance(fit_star), pch = 16)
Fitted lines with (black line) and without giant stars (red line), the influential points
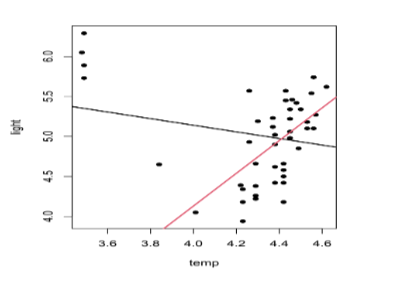
- Automatic detection of influential points can be useful to find points which are problematic
- Sometimes these methods help us identify data recording issues or problematic measurement and we can discard the points or give them less weight
- But sometime they are the symptom of something more complicated going on in the process: need to question what is the origin of these outlying points
- There may be some sub-populations that behave differently, which are not specified.