We need to always be aware of the assumptions of the model, since linear models are often applied to data for which they cannot work (i.e. asymmetric data)
Models checks can highlight the issues with linearity and homoschedasticity assumptions (among others). These can be (not always) solved by applying transformations of the target and/or of the predictors:
- Linearity
- When we plot the residuals against the predictor variable, we may see a curved or stepped pattern. This strongly suggests that the relationship between Y and X is not linear. At this point, it is often useful to fall back to, in fact, plotting the yi against the xi, and try to guess at the functional form of the curve.[1]
- One possible approach is to transform X (transformation of predictor variables) or Y (target transformation) to make the relationship linear.
- For homoskedasticity problems, transform Y to make the variance more constant
initech_fit <- lm(salary ~ years, data = initech)
summary(initech_fit)
Call:
lm(formula = salary ̃ years, data = initech)
Residuals:
Min 1Q Median 3Q Max
-57225 -18104 241 15589 91332
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5302 5750 0.922 0.359
years 8637 389 22.200 <2e-16 ***
---
...
Residual standard error: 27360 on 98 degrees of freedom
Multiple R-squared: 0.8341, Adjusted R-squared: 0.8324
F-statistic: 492.8 on 1 and 98 DF, p-value: < 2.2e-16It seems like a good model until we check the residuals

This is a typical problem of heteroskedasticity, when
For the assumptions made until now, we want to achieve constant variance
Instead, here we see the variance is a function of the mean
We choose and apply some invertible function to
A common variance stabilizing transformation when we see increasing variance in a fitted versus residuals plot is
Also, if the values of a variable range over more than one order of magnitude and the variable is strictly positive, then replacing the variable by its logarithm is likely to be helpful.
initech_fit_log <- lm(log(salary) ~ years, data = initech)
In the original scale of the data we have:
which has the errors entering the model in a multiplicative fashion.
Let's check the results
plot(salary ~ years, data = initech, col = "grey", pch = 20, cex = 1.5,
main = "Salaries at Initech, By Seniority")
curve(exp(initech_fit_log$coef[1] + initech_fit_log$coef[2] * x),
from = 0, to = 30, add = TRUE, col = "darkorange", lwd = 2)
And we check the residuals
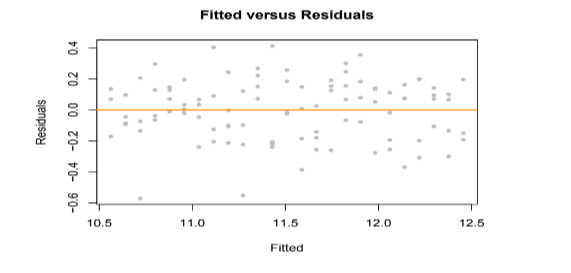
The fitted versus residuals plot looks much better. It appears the constant variance assumption is no longer violated, but we pay the price of having different model.
Let's compare errors
# Sigma^2 under the original model
sqrt(mean(resid(initech_fit) ˆ 2))
[1] 27080.16
# Sigma^2 under the log model
sqrt(mean(resid(initech_fit_log) ˆ 2))
[1] 0.1934907But wait, that isn’t fair, this difference is simply due to the different scales being used.
Since we changed the model, we also changed the scale of the data!
We cannot compare them like this, we need to rescale.
sqrt(mean((initech$salary - fitted(initech_fit)) ˆ 2))
[1] 27080.16
sqrt(mean((initech$salary - exp(fitted(initech_fit_log))) ˆ 2))
[1] 24280.36The transformed response is a linear combination of the predictors:
If we re-scale the data from a log scale back to the original scale of the data, we now have
The average salary increases
Comparing the RMSE using the original and transformed response, we also see that the log transformed model simply fits better, with a smaller average squared error
The model has changed, we are now considering
- Y's distribuiton is a log-Normal distribution, and we are merely modeling its transformation
$g(\mathbb{E}[X])$ . - We turned the additive model of the noise into a multiplicative model of the noise.
- It makes sense, since it takes into account the increasing error.
- Reinterpretation of the beta parameters :
- For each year
$x_{i}$ of experience (unit of measure) the median changes accordingly to$x_{i} \cdot \hat{\beta_{1}}$
- For each year
- Since the logarithm is a monotonic transformation, the median is the exponential of Y's log will be the same, in fact:
$\text{median}(\log(X)) = \log(\text{median}(X))$ - The expected value is not the same, in fact:
$\mathbb{E}[(g(X))] \neq g(\mathbb{E}[X])$ - The scale is different, we are modeling a different variable and back-transforming needs to be done with care.
If the data is negative, this cannot be applied!
In statistics, a power transform is a family of functions applied to create a monotonic transformation of data using power functions. It is a data transformation technique used to stabilize variance, make the data more normal distribution-like, improve the validity of measures of association (such as the Pearson correlation between variables), and for other data stabilization procedures.
Definition:
The power transformation is defined as a continuously varying function, with respect to the power parameter
$\lambda$ , in a piece-wise function form that makes it continuous at the point of singularity ($\lambda = 0$ ).
For data vectors
where:
is the geometric mean of the observations
The case for
The great statisticians G. E. P. Box and D. R. Cox introduced a family of transformations which includes powers of Y and taking the logarithm of Y, parameterized by a number
Idea: The transformation is defined for positive data only, so the possible remedy could be translating the data after to the positive domain by adding a constant.
It is important to remember that this family of transformations is just something that Box and Cox made up because it led to tractable math. There is absolutely no justification for it in probability theory, general considerations of mathematical modeling, or scientific theories.
There is also no reason to think that the correct model will be one where some transformation of Y is a linear function of the predictor variable plus Gaussian noise.
Estimating a Box-Cox transformation by maximum likelihood does not relieve us of the need to run all the diagnostic checks after the transformation. Even the best Box-Cox transformation may be utter rubbish.
We choose
-
$\lambda < 1$ for positively skewed data -
$\lambda > 1$ for negatively skewed data
The
where
- We need to estimate a linear model (and eventually re-iterate if we change the model)
- Choose the predictors
- We compute many
$\lambda$ values - We compute the likelihood of the transformation
- We choose the
$\lambda$ value that "stabilize" the values of Y, so that its variability is reduced. That is a$\lambda$ value that maximizes the function$\operatorname{L}(\lambda)$
This is implemented in R through the function boxcox in the package MASS. We then use the boxcox function to find the best transformation of the form considered by the Box-Cox method, and builds a confidence interval for the best lambda values.
We can build a
R will plot for us to help quickly select an appropriate
# Box-Cox transform
boxcox(initech_fit, plotit = TRUE)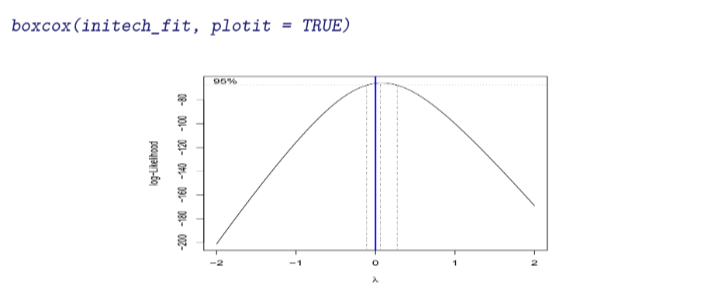
We often choose a ”nice” value from within the confidence interval, instead of the best value of
- Ex:
$\hat{\lambda} = 0.061$ , that truly maximizes the likelihood. In this case we choose$\lambda = 0$ , which takes us to the logarithmic function, very interpretable.