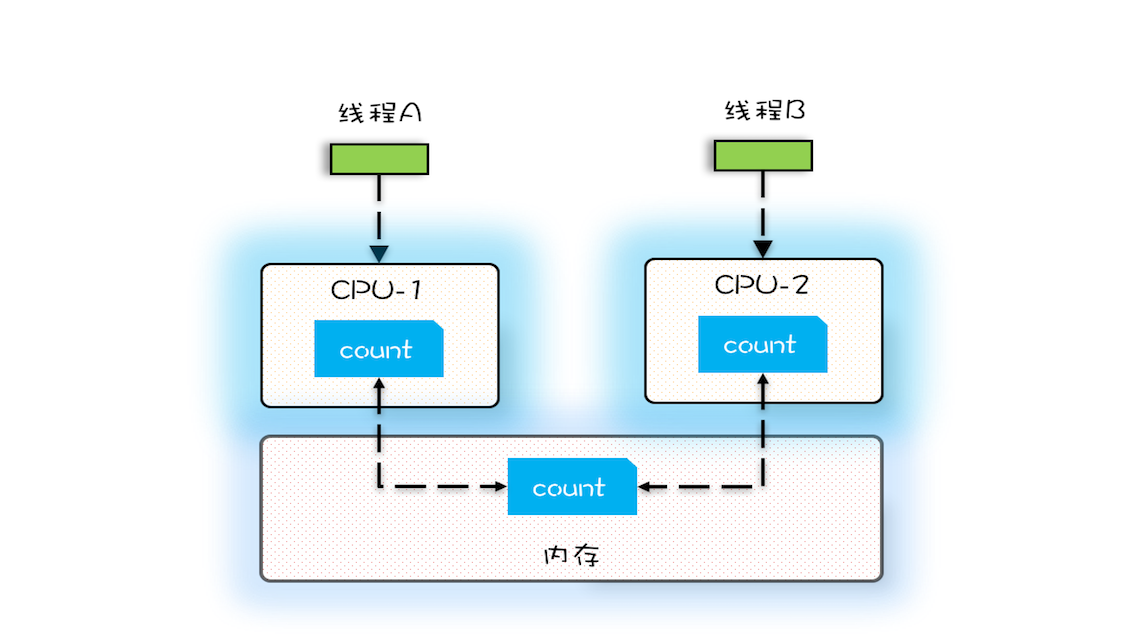
- 可见性: 缓存导致的可见性问题 多核cpu下 cpu缓存与内存的一致性不能保证。
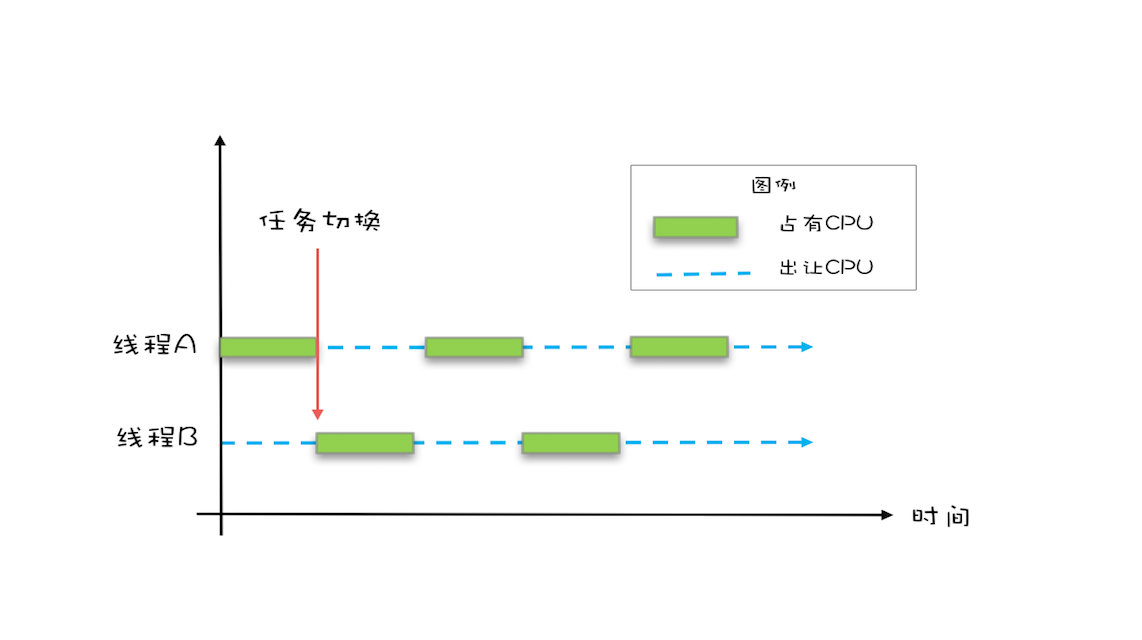
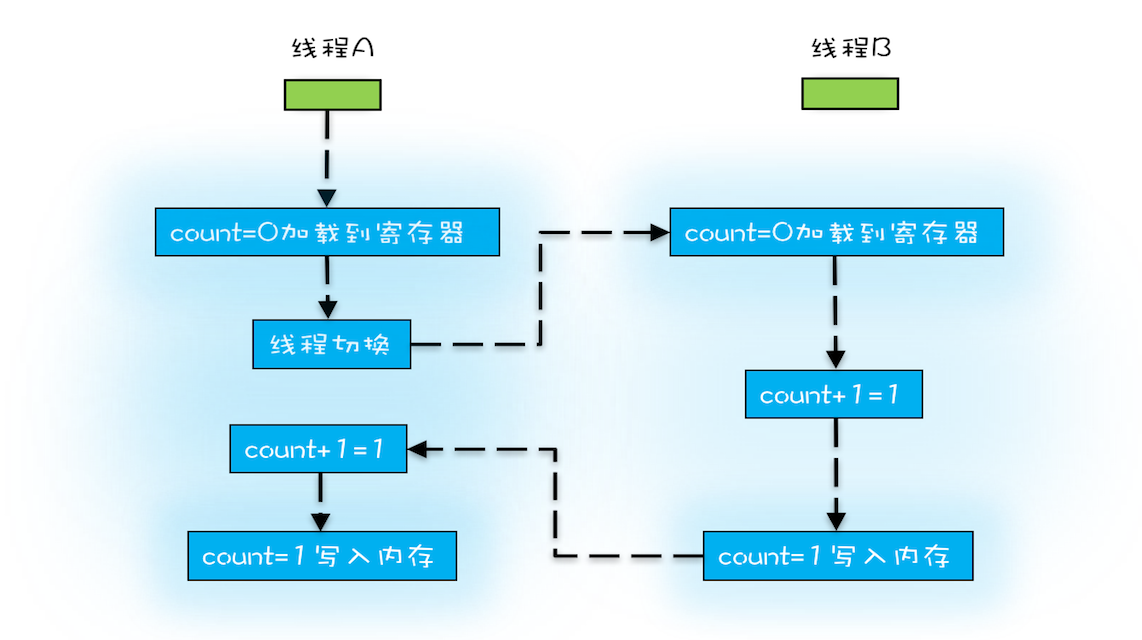
- 原子性: 线程切换带来的原子性问题 由于cpu速度太快 为了更好的利用cpu操作系统带来了线程切换 时间片:
线程切换
- 有序性: 编译优化带来的有序性问题 由于java是高级语言 所以通常一条语句代表多条 指令。编译器为了性能有时会更改程序中语句的先后顺序或者指令的先后顺序。这同样是 违背我们正常逻辑的行为。
例如:
我们以为的 new 操作应该是:
1、分配一块内存 M;
2、在内存 M 上初始化 Singleton 对象;
3、然后 M 的地址赋值给 instance 变量。
但是实际上优化后的执行路径却是这样的:
1、分配一块内存 M;
2、将 M 的地址赋值给 instance 变量;
3、最后在内存 M 上初始化 Singleton 对象。
-
概念阐述:
Java内存模型是个很复杂的规范 可以理解为,Java内存模型规范了JVM如何提供按需禁用缓存 和编译优化的方法。具体来说,这些方法包括 volatile、synchronized 和 final三个关键字, 以及六项 Happens-Before 规则。 -
Happens-Before 规则
- 程序的顺序性: 同一个线程中,按照程序的顺序,前面的操作Happen-Before于后续的任意操作 ,既程序前面对某个变量的操作对后续操作可见。
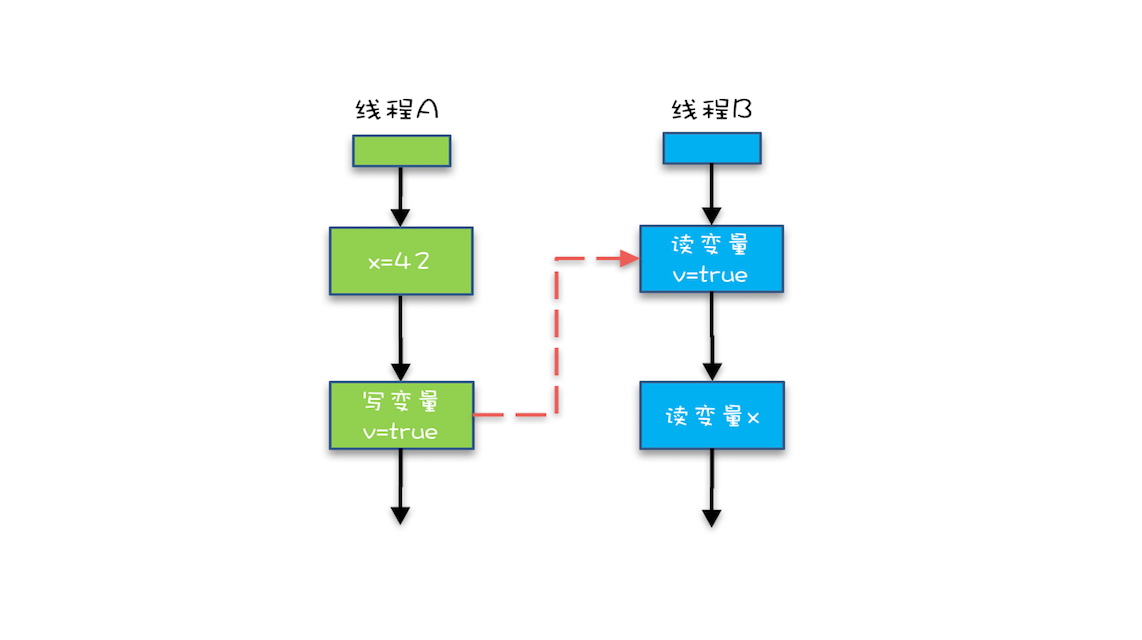
- volatile 变量规则: 对一个volatile变量的写操作Happen-Before于后续对这个volatile变量的读操作
- 传递性: 如果 A Happen-Before B,B Happen-Before C ,那么A Happen-Before C。
如下图: - 管程中锁的规则 :对一个锁的的解锁Happen-Before于后续对这个锁的加锁。
java里的管程指的就是synchronized,synchronized 是 Java 里对管程的实现。
所以结合规则 4——管程中锁的规则,可以这样理解:假设 x 的初始值是 10,线程 A 执行完代码块后 x 的值会变成 12(执行完自动释放锁), 线程 B 进入代码块时,能够看到线程 A 对 x 的写操作,也就是线程 B 能够看到 x==12。这个也是符合我们直觉的。
synchronized (this) { //此处自动加锁 // x是共享变量,初始值=10 if (this.x < 12) { this.x = 12; } } //此处自动解锁 - 线程 start() 规则:指主线程 A 启动子线程 B后,子线程B能够看到主线程在启动子线程 B(即 调用子线程 start()方法) 之前的操作
Thread B = new Thread(()->{ // 主线程调用B.start()之前 // 所有对共享变量的修改,此处皆可见 // 此例中,var==77 }); // 此处对共享变量var修改 var = 77; // 主线程启动子线程 B.start(); - 线程join()规则 :指主线程 A 等待 子线程 B 完成(主线程通过调用子线程join()方法实现)
当子线程 B 完成后( 主线程 A 中 join()方法返回 ),主线程能够看到子线程的操作。所谓的“看到”,指的是对共享变量的操作。
参考下面代码:Thread B = new Thread(()->{ // 此处对共享变量var修改 var = 66; }); // 例如此处对共享变量修改, // 则这个修改结果对线程B可见 // 主线程启动子线程 B.start(); B.join() // 子线程所有对共享变量的修改 // 在主线程调用B.join()之后皆可见 // 此例中,var==66