7/7
面向面经学习JAVASE
牛客网商汤一面
1.Java语言的特点
面向对象 (封装 继承 多态)
平台无关(JVM虚拟机)
可靠性 安全性 支持多线程(C++无内置多线程机制,JAVA内置
编译与解释并存
2.continue、break和return的区别
-
return :直接跳出当前的方法,返回到该调用的方法的语句处,继续执行
-
break:在循环体内结束整个循环过程
-
continue :结束本次的循环,直接进行下一次的循环
3.Java基本数据类型以及各自占多少字节
-
byte/8
-
char/16
-
short/16
-
int/32
-
float/32
-
long/64
-
double/64
-
boolean/~
boolean 只有两个值:true、false,可以使用 1 bit 来存储,但是具体大小没有明确规定。JVM 会在编译时期将 boolean 类型的数据转换为 int,使用 1 来表示 true,0 表示 false。JVM 支持 boolean 数组,但是是通过读写 byte 数组来实现的。
4.接口和抽象类的区别
- 接⼝的⽅法默认是 public ,所有⽅法在接⼝中不能有实现(Java 8 开始接⼝⽅法可以有默认 实现),⽽抽象类可以有⾮抽象的⽅法。
- 接⼝中除了 static 、 final 变量,不能有其他变量,⽽抽象类中则不⼀定。
- ⼀个类可以实现多个接⼝,但只能实现⼀个抽象类。接⼝⾃⼰本身可以通过 extends 关键 字扩展多个接⼝。
- 接⼝⽅法默认修饰符是 public ,抽象⽅法可以有 public 、 protected 和 default 这些修饰 符(抽象⽅法就是为了被重写所以不能使⽤ private 关键字修饰!)。
- 从设计层⾯来说,抽象是对类的抽象,是⼀种模板设计,⽽接⼝是对⾏为的抽象,是⼀种行为的规范。
总结⼀下 jdk7~jdk9 Java 中接⼝概念的变化(相关阅读): 1. 在 jdk 7 或更早版本中,接⼝⾥⾯只能有常量变量和抽象⽅法。这些接⼝⽅法必须由选择实 现接⼝的类实现。 2. jdk 8 的时候接⼝可以有默认⽅法和静态⽅法功能。 3. Jdk 9 在接⼝中引⼊了私有⽅法和私有静态⽅法。
5.创建线程的方式
1)继承Thread类创建线程
2)实现Runnable接口创建线程
3)使用Callable和Future创建线程
4)使用线程池例如用Executor框架
6.线程池的原理
首先:池化技术相⽐⼤家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个 思想的应⽤。池化技术的思想主要是为了减少每次获取资源的消耗,提⾼对资源的利⽤率
降低资源消耗。通过重复利⽤已创建的线程降低线程创建和销毁造成的消耗。 提⾼响应速度。当任务到达时,任务可以不需要的等到线程创建就能⽴即执⾏。 提⾼线程的可管理性。线程是稀缺资源,如果⽆限制的创建,不仅会消耗系统资源,还会降 低系统的稳定性,使⽤线程池可以进⾏统⼀的分配,调优和监控
execute方法
7.线程为什么调用start方法而不是直接调用run方法
首先通过对象.run()方法可以执行方法,但是不是使用的多线程的方式,就是一个普通的方法,要想实现多线程的方式,一定需要通过对象.start()方法。
private native void start0();start0 被标记成 native ,也就是本地方法,并不需要我们去实现或者了解,**为什么 start0() 会标记成 native? **
start() 方法调用 start0() 方法后,该线程并不一定会立马执行,只是将线程变成了可运行状态。具体什么时候执行,取决于 CPU ,由 CPU 统一调度。
我们又知道 Java 是跨平台的,可以在不同系统上运行,每个系统的 CPU 调度算法不一样,所以就需要做不同的处理,这件事情就只能交给 JVM 来实现了,start0() 方法自然就表标记成了 native。
最后,总结一下,Java 中实现真正的多线程是 start 中的 start0() 方法,run() 方法只是一个普通的方法。 认识 native 即 JNI,Java Native Interface
Java平台有个用户和本地C代码进行互操作的API,称为Java Native Interface (Java本地接口)。
native是与C++联合开发的时候用的!java自己开发不用的!
native的意思就是通知操作系统, 这个函数你必须给我实现,因为我要使用。 所以native关键字的函数都是操作系统实现的, java只能调用。
Java无法直接访问到操作系统底层(如系统硬件等),为此Java使用native方法来扩展Java程序的功能。
8.ArrayList和LinkedList区别,是否都支持快速随机访问
ArrayList 基于动态数组实现,LinkedList 基于双向链表实现。ArrayList 和 LinkedList 的区别可以归结为数组和链表的区别:
- 数组支持随机访问,但插入删除的代价很高,需要移动大量元素;
- 链表不支持随机访问,但插入删除只需要改变指针。
LinkedList不支持高效的随机元素访问
9.说说HashMap
以JDK1.7为例
- 存储结构
内部包含了一个 Entry 类型的数组 table。Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。
- 拉链法 处理冲突
HashMap 允许插入键为 null 的键值对。但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对
- 扩容-基本原理
设 HashMap 的 table 长度为 M,需要存储的键值对数量为 N,如果哈希函数满足均匀性的要求,那么每条链表的长度大约为 N/M,因此查找的复杂度为 O(N/M)。
为了让查找的成本降低,应该使 N/M 尽可能小,因此需要保证 M 尽可能大,也就是说 table 要尽可能大。HashMap 采用动态扩容来根据当前的 N 值来调整 M 值,使得空间效率和时间效率都能得到保证。 4. 扩容后需要重新计算桶下标
-
计算数值容量
-
链表转红黑树
从JDK1.8开始,一个桶存储的链表长度大于等于 8 时会将链表转换为红黑树
10.HashMap是线程安全的吗?有什么线程安全的方法
HashMap 是线程不安全的。
-
JDK 1.7 HashMap 采用数组 + 链表的数据结构,多线程背景下,在数组扩容的时候,存在 Entry 链死循环和数据丢失问题。
-
JDK 1.8 HashMap 采用数组 + 链表 + 红黑二叉树的数据结构,优化了 1.7 中数组扩容的方案,解决了 Entry 链死循环和数据丢失问题。但是多线程背景下,put 方法存在数据覆盖的问题
Hashtable、ConcurrentHashMap、copyOnWriteArrayList是线程安全的。
HashTable 容器使用 synchronized 来保证线程安全,但在线程竞争激烈的情况下 HashTable 的效率非常低下。因为当一个线程访问 HashTable 的同步方法,其他线程也访问 HashTable 的同步方法时,会进入阻塞或轮询状态。如线程1使用 put 进行元素添加,线程2不但不能使用 put 方法添加元素,也不能使用 get 方法来获取元素,所以竞争越激烈效率越低
JDK 1.8 ConcurrentHashMap 采用数组 + 链表 + 红黑树的方式实现,结构基本上和 1.8 中的 HashMap 一样,不过大量的利用了 volatile,final,CAS 等 lock-free 技术来减少锁竞争对于性能的影响,从而保证线程安全性。
11.算法题:单词翻转(比如abc->cba),句子逆序(His name is Jack->Jack is name His)
双指针算法 left<right 句子逆序: 把整个句子翻转,然后把所有的单词翻转
12.字符串拼接的方式(String StringBuilder StringBuffer)
效率(用时短到长):StringBuilder < StringBuffer < concat < + < StringUtils.join
1)"+"是Java提供的一个语法糖,而使用+拼接的字符串,它将String转成了StringBuilder后,再使用StringBuilder.append进行处理。如果不是在循环体中进行字符串拼接的话,直接使用+就好了。
(2)concat方法,其实是new了一个新的String
(3)StringUtils.join也是通过StringBuilder来实现的
(4)StringBuffer在StringBuilder的基础上,做了同步处理,所以在耗时上会相对多一些。
(5)如果在并发场景中进行字符串拼接的话,要使用StringBuffer来替代StringBuilder。因为StringBuilder是线程不安全的,而StringBuffer是线程安全的
※ 区分【String str="HW"】和【String str=new String("HW")】
(1)字面量赋值方式 eg:String str = "Hello";
该种直接赋值的方法,JVM会去字符串常量池(String对象不可变)中寻找是否有equals("Hello")的String对象,如果有,就把该对象在字符串常量池中"Hello"的引用复制给字符串变量str,如若没有,就在堆中新建一个对象,同时把引用驻留在字符串常量池中,再把引用赋给字符串变量str。 用该方法创建字符串时,无论创建多少次,只要字符串的值(内容)相同,那么它们所指向的都是堆中的同一个对象。 该方法直接赋值给变量的字符串存放在常量池里 (2)new关键字创建新对象 eg:String str = new String("Hello");
利用new来创建字符串时,无论字符串常量池中是否有与当前值相同的对象引用,都会在堆中新开辟一块内存,创建一个新的对象。
注意:对字符串进行拼接操作,即做"+"运算的时候,分2种情况:
表达式右边是纯字符串常量,那么存放在常量池里面。eg:String str = "Hello" + "World"; 表达式右边如果存在字符串引用,也就是字符串对象的句柄,那么就存放在堆里面。eg:String str = str1 + str2;
13.用过哪些数据库(MySQL Redis)
14.MySQL事务的特性
15.写一个SQL(找出分数前五的学生姓名)
16.MySQL的索引有哪些类型
17.B+树索引的结构
支持等值查询和范围查询
18.使用索引查询一定会变快吗
19.Spring常见的注解
- @Component 组件,没有明确的角色
- @Service 在业务逻辑层使用(service层)
- @Repository 在数据访问层使用(dao层)
- @Controller 在展现层使用,控制器的声明(C)
20.@Transactional是做什么的?是不是加了这个注解事务一定生效?(不知道,面试官提醒涉及到代理可能会失效)
21.ES的原理,为什么会那么快
Elasticsearch 是一个基于 Lucene 的搜索引擎。它提供了具有 HTTP Web 界面和无架构 JSON 文档的分布式,多租户能力的全文搜索引擎。 Elasticsearch 是用 Java 开发的,根据 Apache 许可条款作为开源发布。
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
传统的检索方式是通过文章,逐个遍历找到对应关键词的位置。 倒排索引,是通过分词策略,形成了词和文章的映射关系表,也称倒排表,这种词典 + 映射表即为倒排索引。
其中词典中存储词元,倒排表中存储该词元在哪些文中出现的位置。 有了倒排索引,就能实现 O(1) 时间复杂度的效率检索文章了,极大的提高了检索效率。
加分项: 倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构。
Lucene 从 4+ 版本后开始大量使用的数据结构是 FST。FST 有两个优点: 1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间; 2)查询速度快。O(len(str)) 的查询时间复杂度。
22.Redis数据类型
| 数据类型 | 可以存储的值 | 操作 |
|---|---|---|
| STRING | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作 对整数和浮点数执行自增或者自减操作 |
| LIST | 列表 | 从两端压入或者弹出元素 对单个或者多个元素进行修剪, 只保留一个范围内的元素 |
| SET | 无序集合 | 添加、获取、移除单个元素 检查一个元素是否存在于集合中 计算交集、并集、差集 从集合里面随机获取元素 |
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对 获取所有键值对 检查某个键是否存在 |
| ZSET | 有序集合 | 添加、获取、删除元素 根据分值范围或者成员来获取元素 计算一个键的排名 |
23.算法题:只保留首字母和尾字母,中间显示除去首尾字母有多少个数字(如abc->a1c,abcd->a2d)
24.算法题:保留首字母和尾字母,数字保留在首字母后或尾字母前,返回一个字符串列表并分析时间复杂度与空间复杂度(如world->[w3d, w2ld, w1rld, wo2d, wor1d])
25.你用过哪些常见的Linux命令,如果要查看CPU或内存使用情况用什么命令(top),如果要在两台服务器之间拷贝文件用什么命令(scp)
26.反问环节
总的来说还是比较基础的,考察的面很广,但都不难,许愿二面
MySQL 默认的事务型存储引擎,只有在需要它不支持的特性时,才考虑使用其它存储引擎。
实现了四个标准的隔离级别,默认级别是可重复读(REPEATABLE READ)。在可重复读隔离级别下,通过多版本并发控制(MVCC)+ Next-Key Locking 防止幻影读。
主索引是聚簇索引,在索引中保存了数据,从而避免直接读取磁盘,因此对查询性能有很大的提升。
内部做了很多优化,包括从磁盘读取数据时采用的可预测性读、能够加快读操作并且自动创建的自适应哈希索引、能够加速插入操作的插入缓冲区等。
支持真正的在线热备份。其它存储引擎不支持在线热备份,要获取一致性视图需要停止对所有表的写入,而在读写混合场景中,停止写入可能也意味着停止读取。
不支持事务。
不支持行级锁,只能对整张表加锁,读取时会对需要读到的所有表加共享锁,写入时则对表加排它锁。但在表有读取操作的同时,也可以往表中插入新的记录,这被称为并发插入(CONCURRENT INSERT)。
可以手工或者自动执行检查和修复操作,但是和事务恢复以及崩溃恢复不同,可能导致一些数据丢失,而且修复操作是非常慢的。
- 事务:InnoDB 是事务型的,可以使用 Commit 和 Rollback 语句。
- 并发:MyISAM 只支持表级锁,而 InnoDB 还支持行级锁。
- 外键:InnoDB 支持外键。
- 备份:InnoDB 支持在线热备份。
- 崩溃恢复:MyISAM 崩溃后发生损坏的概率比 InnoDB 高很多,而且恢复的速度也更慢。
- 其它特性:MyISAM 支持压缩表和空间数据索引。
- 概念
NoSQL非关系型数据库,主要指那些非关系型的、分布式的,且一般不保证ACID的数据存储系统,主要代表MongoDB,Redis、CouchDB。
NoSQL提出了另一种理念,以键值来存储,且结构不稳定,每一个元组都可以有不一样的字段,这种就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,为了获取用户的不同信息,不需要像关系型数据库中,需要进行多表查询。仅仅需要根据key来取出对应的value值即可。
- 分类
非关系数据库大部分是开源的,实现比较简单,大都是针对一些特性的应用需求出现的。根据结构化方法和应用场景的不同,分为以下几类。
(1)面向高性能并发读写的key-value数据库
主要特点是具有极高的并发读写性能,例如Redis、Tokyo Cabint等。
(2)面向海量数据访问的面向文档数据库
特点是,可以在海量的数据库快速的查询数据。例如MongoDB以及CouchDB.
(3)面向可拓展的分布式数据库
解决的主要问题是传统数据库的扩展性上的缺陷。
- 缺点
但是由于Nosql约束少,所以也不能够像sql那样提供where字段属性的查询。因此适合存储较为简单的数据。有一些不能够持久化数据,所以需要和关系型数据库结合。
- 存储
Sql通常以数据库表的形式存储,例如存储用户信息,SQL中增加外部关系的话,需要在原表中增加一个外键,来关联外部数据表。如下:
NoSql采用key-value的形式存储
- 事务
SQL中如果多张表需要同批次被更新,即如果其中一张表更新失败的话,其他表也不会更新成功。这种场景可以通过事务来控制,可以在所有命令完成之后,再统一提交事务。在Nosql中没有事务这个概念,每一个数据集都是原子级别的。
- 数据表 VS 数据集
关系型是表格型的,存储在数据表的行和列中。彼此关联,容易提取。而非关系型是大块存储在一起。
- 预定义结构 VS 动态结构
在sql中,必须定义好地段和表结构之后,才能够添加数据,例如定义表的主键、索引、外键等。表结构可以在定义之后更新,但是如果有比较大的结构变更,就会变的比较复杂。
在Nosql数据库中,数据可以在任何时候任何地方添加。不需要预先定义。
- 存储规范 VS 存储代码
关系型数据库为了规范性,把数据分配成为最小的逻辑表来存储避免重复,获得精简的空间利用。但是多个表之间的关系限制,多表管理就有点复杂。
当然精简的存储可以节约宝贵的数据存储,但是现在随着社会的发展,磁盘上付出的代价是微不足知道的。
非关系型是平面数据集合中,数据经常可以重复,单个数据库很少被分开,而是存储成为一个整体,这种整块读取数据效率更高。
- 纵向拓展 VS 横向拓展
为了支持更多的并发量,SQL数据采用纵向扩展,提高处理能力,通过提高计算机性能来提高处理能力。
NoSql通过横向拓展,非关系型数据库天然是分布式的,所以可以通过集群来实现负载均衡。
在查找时,从上层指针开始查找,找到对应的区间之后再到下一层去查找。下图演示了查找 22 的过程。
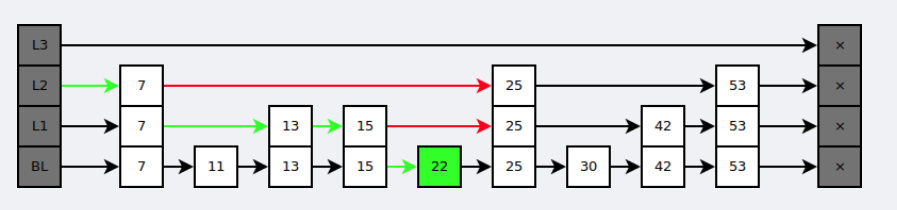
与红黑树等平衡树相比,跳跃表具有以下优点:
- 插入速度非常快速,因为不需要进行旋转等操作来维护平衡性;
- 更容易实现;
- 支持无锁操作。
RDB 快照和 AOF 日志
单例不安全 因为有反射
使用枚举 反射不能破坏枚举